はじめに
この記事はBPaaS/AI+BPO Advent Calendar 2025 22日目の記事です。
サクセスエンジニアとして働いている増田です。
サクセスエンジニアってなんだ?
と興味を持たれた方はぜひこちらの記事を読んでください。
日々の業務では、社内ツールの開発やデータ変換システムの構築、業務設計や自動化などに取り組んでいます。
最近はAIを活用したワークフローの構築にも挑戦していますが、正直なところ、まだ大きな成果が出ているわけではありません。ただ、その過程で「自動化やAIワークフローを機能させるためには、その前段階のデータ整備が重要だ」という実感を強く持つようになりました。
本記事では、私が自動化基盤として導入した「プロダクト外にデータを集約する」というアプローチについて、その背景と考え方、そしてメリット・デメリットを共有します。
業務で起きがちな問題
自動化やAIを業務に導入しようとしたとき、まず直面するのは「データがどこにあるのか」という問題です。そして、いざワークフローを組もうとすると、データの取得、処理、書き戻し——それぞれのステップがボトルネックになっていきます。
多くの現場では、担当者ごとにエクセルやスプレッドシートが作られ、似たようなデータがあちこちに散らばっています。「最新版はどれ?」「このデータ、あのシートと合ってる?」といった確認作業が日常化しているのではないでしょうか。
エクセルやスプレッドシートは、世界一簡単にデータベースを作れるツールです。誰でも使えますし、どんな業務にも対応できる柔軟性を持っています。だからこそ、気づけば「XXX台帳」「XXXマスター」といったファイルがあちこちに生まれていきます。
しかし、これらを自動化やAIワークフローに組み込もうとすると、途端に難しくなります。
データの取得——まず、どのファイルのどのシートを見ればいいのかを特定しなければなりません。同じような情報が複数の場所にあると、どれが正しいのか判断するロジックが必要になります。スプレッドシートのAPIは存在しますが、セル範囲の指定やシート構造への依存など、ちょっとした構造の変更で壊れやすい連携になりがちです。
処理——複数のシートやファイルからデータを集めて突合する必要が出てきます。人間なら目で見て「あ、これとこれは同じだな」と判断できますが、プログラムにはそれが難しい。表記揺れや微妙なフォーマットの違いを吸収するコードが膨らんでいきます。
書き戻し——処理結果をどこに保存するかも曖昧になります。元のシートに書き戻すのか、別のシートに出力するのか。複数の場所に同じ情報があると、一箇所だけ更新して整合性が崩れる事故も起きます。
私も何度もこれに苦しめられてきました。結局、スプレッドシートをハブにしたワークフローは、作るたびに個別対応が増え、メンテナンスコストが膨らんでいきます。
この状態で自動化やAIを導入しようとしても、うまくいきません。だからこそ、自動化やAI活用の前に「情報源の集約」が大前提になります。では、情報源の集約とは具体的にどうあるべきなのでしょうか。
SSOTの理想と現実
情報源の集約といえば、SSOT(Single Source of Truth)という考え方があります。「信頼できる唯一の情報源」という意味で、あるデータについて参照すべき場所を一つに定めるという原則です。
理想を言えば、SSOTはプロダクトのデータベース内に集約されているべきです。プロダクトが業務のすべてをカバーし、必要なデータはすべてそこにある。これが最も整合性を保ちやすい形です。
しかし現実はそう簡単ではありません。
業務は常に変化します。
新しい業務フローが生まれ、既存のフローも改善され続ける。
一方で、プロダクトの開発には色々な要因で時間がかかることがあります。
プロダクトは顧客に見えている面でもあります。データ構造の変更やスキーマの追加は、既存機能への影響を慎重に検討しなければなりません。場合によっては、業務上は必要だとわかっていても、影響範囲の大きさから変更を決断できないケースもあります。
このように業務の変化スピードとプロダクト開発のスピードには、どうしてもギャップが生まれます。
このギャップをどう埋めるか。私が選んだのは「プロダクト外に業務特化のデータベースを持つ」というアプローチでした。
Scoped SSOTという考え方
このアプローチを説明するにあたって、ちょうどいい言葉が見つからなかったのですが、今日風呂に入っていたら「Scoped SSOT」という言葉を思いつきました。造語です。
Scoped SSOTとは、「特定の業務スコープにおける唯一の情報源」という考え方です。
厳密に言えば、プロダクトDBの外に別のデータベースを持つ時点で、「Single」ではなくなります。情報源が複数存在すれば、矛盾が生じるリスクがある。これはSSOTの本質に反しています。
しかし、スコープを明確に区切ることで、この問題を緩和できます。ポイントは「プロダクトDBに存在しないデータ」と「プロダクトDBから同期するデータ」を分けて考えることです。
たとえば、プロダクトで管理していないクライアントごとの設定値やデフォルト値。「このクライアントへの請求書はPDFではなくエクセルで送る」「連絡はメールではなく電話優先」「月末は担当者が忙しいので連絡を避ける」といった情報です。プロダクトの機能としては存在しないが、業務を回すうえでは必要な情報。これらはそもそもプロダクトDBに存在しないので、業務特化DBに持っていても矛盾のしようがありません。業務特化DBがそのままSSOTになります。
一方で、プロダクトDBにも存在するデータを業務特化DBでも扱う場合は、同期の仕組みで整合性を担保する必要があります。
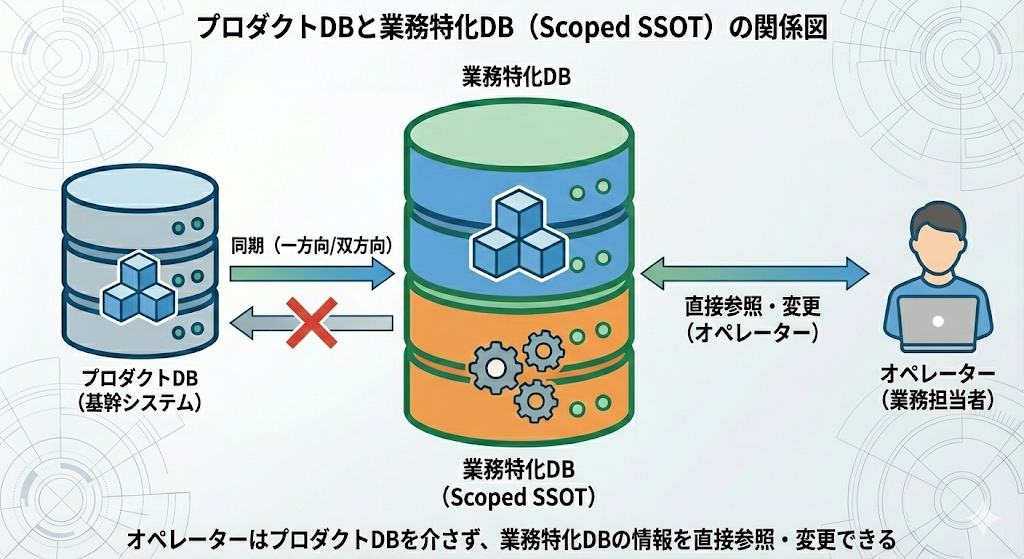
この棲み分けができると、なぜ作業者は迷わなくなるのか。
身近な例で考えてみます。会社全体の情報は社内ポータルにあるけれど、自分のチームの業務に必要な情報だけが一つのNotionページにまとまっている状態を想像してください。日常業務ではそのNotionだけ見ればいい。社内ポータルを毎回探し回る必要がない。
Scoped SSOTも同じです。「この業務に必要な情報は、ここに全部ある」という場所を作る。プロダクトDBから必要なデータは同期されているし、プロダクトにない業務固有の情報もここにある。だから作業者は一箇所だけ見ればいいし、自動化やAIも参照・更新すべき場所が一つに定まる。
では、このScoped SSOTを実現するために、どんなツールを選ぶべきでしょうか。
技術選定の観点
Scoped SSOTとして業務特化DBを構築するなら、どんなツールを選ぶべきか。私が重視しているポイントは3つあります。
1. スキーマ変更の容易性
試行錯誤ができることが重要です。カラムの追加や型の変更が、画面上の操作だけで完結するか。マイグレーションスクリプトを書かなくても済むか。この手軽さが、改善のスピードに直結します。
2. APIの充実度
自動化やAIワークフローと連携するには、APIでデータを読み書きできることが必須です。REST APIがあるか、認証は扱いやすいか、レートリミットは十分か。また、Webhookに対応していると、データ更新をトリガーにした処理も組みやすくなります。
3. UIの使いやすさ
エンジニアだけでなく、業務担当者がデータを参照・編集することが基本になります。スプレッドシートに近い操作感で扱えると、導入のハードルが下がります。
4. 扱えるデータタイプの豊富さ
業務において扱うデータのタイプは様々です。画像データや動画データから緯度経度の情報など、様々なデータのタイプにサポートしており、制約をシステム的につけれることは業務難易度を下げたりデータクオリティを担保する上で重要になります。
これらを踏まえて、選択肢になりうるツールをいくつか挙げます。
スキーマ変更の容易性、API、UIのバランスが良い。連携サービスも豊富。ただし、SaaS系は行数に制限があることがデメリットです。数千〜数万行なら問題ありませんが、大規模なデータを扱う場合は注意が必要です。
オープンソースでセルフホスティングが可能。データを自社管理したい場合や、行数制限を回避したい場合の選択肢。Airtableに似たUIを持ちながら、自由度が高い。
私はNocoDBを採用しました。
理由は、データ保存ポリシーの都合でセルフホスティングが必要だったことと、扱うデータ量が大きかったことです。現在100万行以上のデータを格納していますが、パフォーマンス的には許容できる範囲で運用できています。
基盤となるツールが決まれば、次は実際にどう活用するかです。
自動化・AIワークフローへの応用
Scoped SSOTとして基盤を整えていたことで、自動化やAIワークフローへの応用がスムーズになりました。
自動化やAIに仕事を任せるとき、必要なのは大きく3つです。
- 必要な情報を渡せること
- 結果を書き戻せること
- 試行錯誤できること
まず、情報を渡す部分。AIに何かを判断させたり生成させたりするには、必要なコンテキストを渡す必要があります。情報が一箇所に集約されていれば、「このテーブルのこのレコードを渡せばいい」とシンプルになります。あちこちから情報をかき集める必要がない。
次に、結果を書き戻す部分。AIの出力を業務に反映させるには、どこかに保存する必要があります。書き戻す先が明確であれば、ワークフローの設計もシンプルになります。
そして、試行錯誤の部分。ここが意外と重要です。
AIに最適なデータ構造は、一回で正解を導き出すことは難しいです。どういう形式で情報を渡せば精度が上がるのか、どういうフィールドを追加すれば判断しやすくなるのか。やってみないとわからないことが多い。
プロダクトDBでこの試行錯誤をするのは難しい。スキーマ変更の影響が大きいし、そもそも気軽に変更できない。しかし、業務特化DBであればスキーマ変更は容易です。「この項目を追加してみよう」「この形式に変えてみよう」といった試行錯誤がすぐにできる。
自動化やAI活用においてはこの柔軟性が大きな武器になります。
ただし、当然ながらこのアプローチには見過ごせないリスクもあります。
メリットとリスク
ここまでScoped SSOTの考え方と導入について書いてきましたが、銀の弾丸ではありません。メリットとリスクの両方を理解したうえで判断すべきです。
メリット
柔軟性とスピード
プロダクトの開発サイクルに縛られず、業務の変化に素早く対応できます。スキーマ変更も気軽にできるので、試行錯誤しながら最適な形を探れます。
自動化・AI活用の基盤
情報が集約されていることで、自動化やAIワークフローの構築がシンプルになります。どこから読んで、どこに書くかが明確になる。
プロダクトへの知見還元
業務特化DBで試行錯誤した結果、「この情報はプロダクトで管理すべきだ」という知見がたまっていきます。業務が洗練されてから、その構造をプロダクトに還元できる。いきなりプロダクトに組み込むよりも、失敗のリスクが低くなります。
リスク
捨てられなくなるリスク
「数年で捨てる覚悟」と言っても、実際には難しいことが多い。ワークフローが依存し始め、「このDBがないと業務が回らない」状態になりがちです。気づけば、本来プロダクトに還元すべきものが、いつまでも外に残り続ける。
これを防ぐには、導入時に「どうなったらプロダクトに移すか」「どうなったら廃止するか」というトリガーを決めておくことが重要です。
同期コスト
プロダクトDBに存在するデータを業務特化DBでも扱う場合、同期の仕組みが必要になります。このコストは「簡単に同期できる」と軽く見積もると痛い目を見ます。
まず、継続的なメンテナンスが発生します。プロダクトのスキーマは開発とともに変化します。カラムの追加、型の変更、テーブル構造の見直し。これらの変更を検知し、業務特化DB側の構造やマッピングを追従させ続けなければなりません。
また、データの整合性を担保するためのテストも厚くする必要があります。同期処理が正しく動いているか、データの欠損や重複が起きていないか、型変換でおかしなことになっていないか。本番運用を続ける限り、このテストとモニタリングは必要です。
データ連携パターンの選択
同期の実装方法には大きく2つのパターンがあります。
ETL連携(DB to DB)
プロダクトDBから直接データを抽出し、変換して業務特化DBにロードする方式です。速度面や安定性では圧倒的に優位です。大量データの同期も効率的に行えます。
ただし、AirtableやNocoDBのようなツールを業務特化DBとして使う場合、純粋なDBとは構造が異なります。リレーションの扱い方や、特殊なフィールドタイプなど、単純なSQLでは対応できない部分があり、ETLパイプラインの構築が複雑になることがあります。
API連携
プロダクトが提供するAPIを経由してデータを読み書きする方式です。ETLに比べると速度面では劣りますが、メリットもあります。
APIを経由することで、プロダクト側で定義されたモデルベースのバリデーションを通せます。つまり、不正なデータを業務特化DB側から書き戻してしまうリスクを軽減できる。プロダクトDBに直接書き込むより安全です。
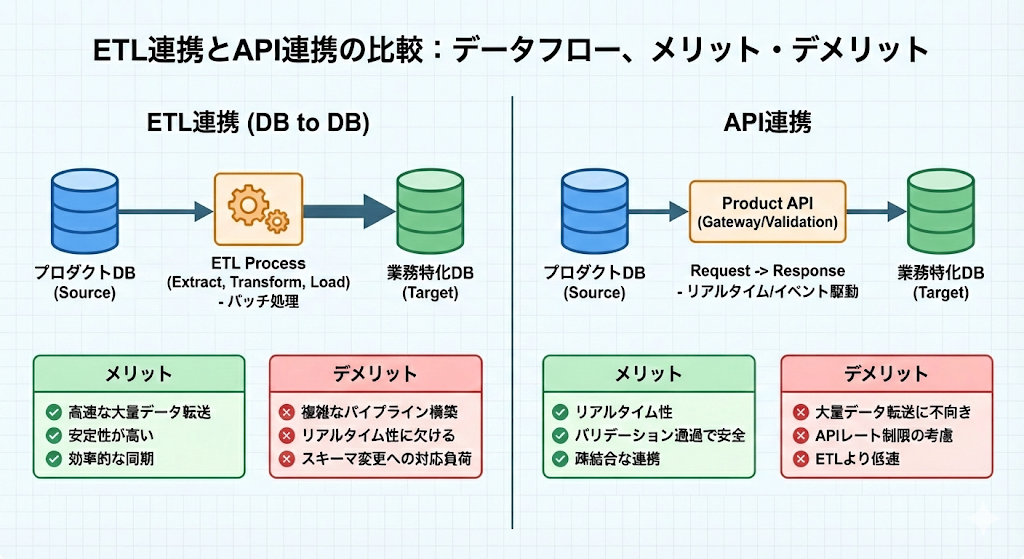
どちらを選ぶかは、データ量、更新頻度、整合性の要件によって変わります。場合によっては両方を組み合わせることもあります。
構造の柔軟性 vs 変換の柔軟性
業務特化DBの構造を柔軟にするアプローチの他に、「正規化されたきれいなSSOTを持ち、AIへの変換は軽量な変換レイヤーで吸収する」という考え方もあります。構造を変えるのではなく、変換を変える。
どちらが正解かは状況次第です。ただ、業務特化DBの構造を柔軟にしすぎると、それ自体がカオスになるリスクもある。この選択肢は頭に入れておくべきです。
まとめ
本記事では、自動化やAIワークフローの基盤として「Scoped SSOT」という考え方を紹介しました。
業務ではエクセルやスプレッドシートが乱立し、情報が散らばりがちです。この状態では自動化もAI活用もうまくいかない。だから情報源の集約が大前提になります。
理想はプロダクトDBにすべてを集約することですが、現実には業務変化のスピードとプロダクト開発のスピードにギャップがある。さらに、プロダクトは顧客に影響する面でもあり、気軽に変更できない。
そこで、プロダクト外に業務特化DBを持つという選択肢が出てきます。スコープを区切り、「この業務においてはここだけ見ればいい」という状態を作る。これがScoped SSOTです。
この基盤があることで、自動化ワークフローはシンプルになり、AIへの応用もスムーズになります。情報の取り出しと書き戻しが一箇所で完結し、試行錯誤もしやすい。
ただし、銀の弾丸ではありません。捨てられなくなるリスク、同期コスト、構造をどこまで柔軟にするかという判断。これらを理解したうえで導入すべきです。
正直なところ、私もまだ試行錯誤の途中です。AIワークフローで大きな成果が出ているわけではありません。ただ、基盤を整えておいたことで、少なくとも「どこから手をつければいいかわからない」という状態にはなっていません。
もし同じような課題を抱えている方がいれば、Scoped SSOTという考え方が何かのヒントになれば幸いです。
