
はじめに
Park Directでは利用者が駐車場契約の申し込みをキャンセルする時に理由を自由記述形式で入力してもらっています。なぜなら、サービスの改善や顧客満足度向上に不可欠な情報だからです。 また、 キャンセル理由をカテゴリに分類することで、
- 傾向の把握: どんな理由でキャンセルが多いのか具体的な傾向を数字で把握する
- 課題の特定: サービスやプロダクトの改善点、顧客サポートの強化すべき点を明確にする
- 優先順位付け: 影響の大きいキャンセル理由から優先的に施策を講じる
- 施策の効果測定: 改善施策がキャンセル率にどう影響したか、カテゴリ別に測定できる
が行いやすくなります。
しかし、自由記述形式で記録された大量のキャンセル理由を一つ一つ手作業で分類するのは大変な労力ですよね。 今回はBigQueryでこの課題を効率的に解決する方法について考えていきます。
生成AIに分類させる
今回ご紹介する方法は、みんな大好き生成AIに解決してもらおうという方法です。 BigQuery MLのML.GENERATE_TEXT関数を利用すると、Googleの生成AIモデル(Geminiなど)に直接テキストを渡し、その内容に基づいて分類を行わせることができます。 今回はコンソール上で設定を進めていきます。早速やっていきましょう。
データセット
今回は下記のようなデータセットとテーブルをテスト用に作成しました。 testというデータセットに、シンプルにキャンセル理由のみを持つテーブルcancel_reasonsを作成しています。 (データはテスト用に作成したものなのでもちろん本物ではありません。)

接続設定を作成する
ますはBigQueryからVertex AIへの接続設定を作成します。 基本的には
こちらのリンク先の手順に従うのみです。

今回は上の画像のように設定しました。

左側のナビゲーションに接続情報が表示され、クリックすると詳細情報が表示されます。 詳細情報にはサービスアカウントIDがあるので、IAMと管理へ移動し、そのサービスアカウントに「Vertex AI ユーザー」のロールを付与します。

データセットにモデルを作成する
次はデータセット内にモデルを作成します。 残念ながら現時点(2025年6月)では利用できるGeminiのモデルはリージョンごとに異なっており、「asia-northeast1」だと1.5までとなっています。 早く2.5が利用できるようになると良いですね。

作成方法としては下記のようなクエリをBigQueryコンソールで実行すればOKです。
CREATE OR REPLACE MODEL `test.reason_classifier_gemini` -- 作成するモデル名をここで指定する REMOTE WITH CONNECTION `asia-northeast1.vertex_gemini_connection` -- 先ほど作成した接続IDで[ローケーション.接続ID]の形式を指定する OPTIONS (endpoint = 'gemini-1.5-pro-002'); -- Vertex AIで利用するモデルを指定する。
左側のナビゲーションにモデルが表示されていれば成功です。

以上でモデルの作成は完了です。
カテゴリをつけるようにGeminiにお願いする
さあ準備は整いました。あとはお願いするだけです。 クエリを書いて実行しましょう。
SELECT reason , JSON_EXTRACT_SCALAR(ml_generate_text_result, '$.candidates[0].content.parts[0].text') as category -- APIが返してくるJSONを見てパスで指定する。 , prompt FROM ML.GENERATE_TEXT( MODEL `test.reason_classifier_gemini`, ( SELECT reason, CONCAT( '指定するキャンセル理由を、以下のカテゴリの中から最も適切なもの一つに分類してください。なお出力はカテゴリ名のみにしてください。', 'カテゴリ: [別の駐車場が見つかった, 顧客都合でのキャンセル, ParkDirectの対応に不信感, 区画を変更したい, その他] ', 'キャンセル理由: "', reason, '"' ) AS prompt FROM `test.cancel_reasons` ), STRUCT( 0.0 AS temperature, -- 生成のランダム性を制御します。低いほど決まった出力をしやすくなります。再現性を担保したいので今回は0.0にしています。 100 AS max_output_tokens -- 出力されるトークン数の上限を制御します。今回は100もいらないと思いますが念の為。 ) );
さあ結果はどうなるか。
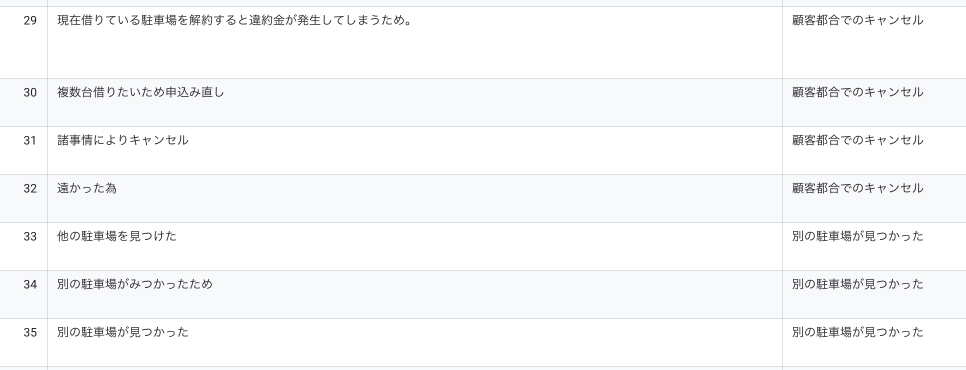
正確にカテゴリがついているように見えますね。ざっとですが100件ほどの全データを確認しまして、9割のレコードは人の目で見ても納得のいくカテゴリがついているように思いました。 完全に主観ですが、以前自分で頑張ってPythonをゴリゴリ書いてカテゴリを付与したものよりだいぶ精度が良い気がします。
おまけ
ちなみにカテゴリを指定せずに分類をお願いすると下記のようになります。

プロンプト部分は改善の余地あり、というかただやりたいことを言っているだけなのであまりいい例ではないかもしれませんが、先に指定なしでカテゴリ分類を行い、その結果からカテゴリ指定して分類してもらうといった手法が良いかもしれません。
プロンプト部分
SELECT reason, CONCAT( '指定するキャンセル理由にカテゴリをつけてください。なお出力はカテゴリ名のみにしてください。' 'キャンセル理由: "', reason, '"' ) AS prompt FROM `dev_test.cancel_reasons`
まとめ
ここまで見てきたように、BigQuery からGeminiを利用すれば高精度なカテゴリ分類がお手軽に行えます。 特に生成 AI ならではのメリットとして柔軟性の高さを感じました。 分類したいカテゴリの種類を増やしたり、定義を変更したりする場合でも、プロンプトの内容を少し修正するだけで対応できそうです。 また、データが増えるほど手動でのカテゴリ付与は辛くなっていくのでこのような手法が有効であると感じました。 もちろん、大規模なデータに対する利用を検討する際には料金面を考慮に入れる必要があるので、dbtなどを利用してデータマート化し、差分だけを分類して更新していく方が良いでしょう。
最後に
表題に Part 1とつけたので、次回はVector Search Indexを活用した分類方法を模索していきたいと思います。
唐突ですがニーリーでは一緒に働く仲間を募集中です!「ちょっと話を聞いてみたいかも」そんな軽い気持ちでも大歓迎です。ぜひカジュアル面談にお越しください!
