
はじめに
こんにちは。Analyticsチームに所属する五十嵐です。 2024年も早くもクリスマス・イブですね。 2024年、ニーリーではデータ基盤の整備が進み、Park Direct事業のさまざまなデータを統合し分析する環境が整ってきました。 nealle-dev.hatenablog.com こうした取り組みの中で、データ基盤で集計したデータをPark DirectのDBに転送しアプリケーション側で活用してもらう、いわゆるリバースETLの運用が始まっています。 本記事では、ニーリーのデータ基盤におけるリバースETLについて簡単にご紹介しようと思います。
ちなみに、登場するテーブル定義やデータ転送設定は仮のものです。
リバースETL導入の背景
まず、リバースETLを運用することになった背景について簡単にご紹介します。 きっかけはPark Directの管理画面でユーザーに有用な指標を可視化して提示する機能を開発するプロジェクトでした*1。 このプロジェクトでアプリケーションのDBで指標を算出する際に以下のような課題が浮き彫りになりました。
- 一部の指標は大量のデータを集計するためクエリ実行時の負荷が高くなり、かつ実行時間が許容できないほど長くなる
- 指標の算出に利用するテーブルがmutableなため過去の集計値の正確性を保証できない
これらの課題を解決するためにデータ基盤上で集計した値をアプリケーション側で利用するという流れになり、 データ転送の方法についていくつかの案を検討した結果、最終的にTROCCOを利用したリバースETLを採用することになりました。 理由として
- 通常のETLで実績がありデータ転送部分を使い慣れているTROCCOに任せられる
- 通信の経路が増えないので新しくセキュリティの懸念事項が増えない
- マネージドサービス上で全て解決するのでアプリケーション開発のフローに大きな変更がない
といったことが挙げられます。
概要
さっそく概観を確認していきましょう。下記にリバースETLの全体図を示します。
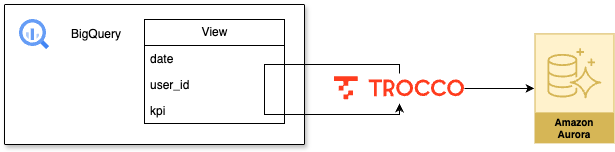
BigQueryに蓄積されているデータから集計用のView(DM)を作成し、それをTROCCOでPark DirectのDBに転送するというとてもシンプルな構成になっています。 わかりやすいですね😊
詳細
ここからはどのようにリバースETLを実現しているかを事例に沿って見ていきたいと思います。くどいようですがテーブルスキーマや構成などは簡略化した仮のものです。
要件
要件の例を示します。
| 項目 | 詳細 |
|---|---|
| 集計対象 | contractsテーブル(日次でパーティションされたヒストリカルデータが蓄積されている) |
| 集計項目 | 毎日のユーザー別新規契約数 |
| 基準日のカラム | contract_date |
| 集計条件 | パーティションの日付がcontract_dateと等しい |
| 集計期間 | 直近の30日 |
| 更新頻度 | 毎日1回 |
| 転送先 | Park DirectのDB(AWS Aurora PostreSQL)のテーブルdaily_contracts_report |
| その他の条件 | データ転送先のテーブルはアプリケーションのMigrationツールで管理する |
また、転送先のテーブルスキーマは下記のようになります。
CREATE TABLE "public"."daily_contracts_report" ( id int8 NOT NULL, base_date DATE NOT NULL, user_id int4 NOT NULL, contract_count int4 NOT NULL, PRIMARY KEY ("id") );
BigQuery
まずはBigQueryでデータマートを作成します。 下に示すように契約情報が入ったcontractsテーブルがBigQuery上にヒストリカルデータとして蓄積されているとします。
SELECT pt_date. -- パーティション対象の日付 , user_id -- ユーザー識別子 , contract_date -- 契約日 FROM project.dataset.contracts LIMIT 10
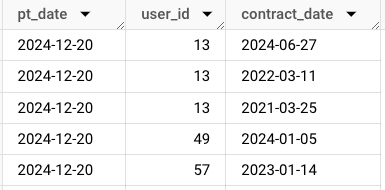
このテーブルを要件の集計条件通りにSQLで集計しv_daily_contracts_reportという名前でViewとして保存します。
この時、転送先テーブルとカラム名を一致させます。
WITH target_records AS ( SELECT pt_date , user_id , contract_date FROM `project.dataset.contracts` WHERE -- パーティションの日付で過去30日分を取得する pt_date BETWEEN DATE_SUB(CURRENT_DATE(), INTERVAL 30 DAY) AND CURRENT_DATE() ) , daily_contract_counts AS ( SELECT pt_date , user_id -- 元のcontracsテーブルがmutableなので基準日とパーティションの日付を一致させて正確な集計を行う , COUNTIF(contract_date = pt_date) AS contract_count FROM target_records GROUP BY pt_date, user_id ) SELECT -- 転送先テーブルのカラム名に準拠する pt_date as base_date , user_id , contract_count FROM daily_contract_counts ORDER BY pt_date , user_id ;
以上でBigQueryでの作業は完了です。
TROCCO
次にデータ転送です。 ニーリーではETLツールとして TROCCO を利用しています。 TROCCOの詳細な説明は省略しますが、データ転送やデータマート、ワークフローの管理をマネージドで行える便利なサービスです。 今回の例では運用の効率化のため次の2種類のデータ転送設定を作成します。
- 初期化転送設定:初回転送や集計項目の変更時に最新の30日分のすべてのデータを転送するための設定
- 日次転送設定:日々のデータ更新を反映するための設定
それぞれの役割を見ていきましょう。
初期化転送設定
こちらの転送設定の用途は、集計項目の追加、変更、削除が発生した場合にTROCCOの管理画面から手動で実行し、テーブルのレコードをすべて洗い替えます。 データを取得するクエリは先ほど作成したBQ上のViewからただSELECTするだけになります。
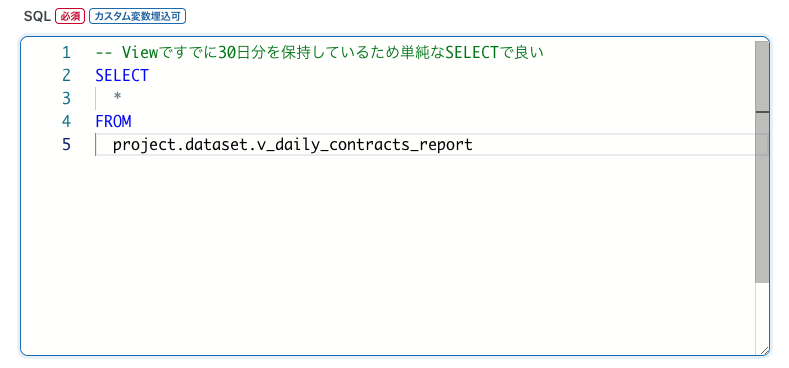
また、洗い替えですので当然ながら一度テーブルのデータがすべて削除されます。具体的にはデータロード前に実行するクエリにTRUNCATE TABLEを実行するSQLを入力します。*2

TROCCOの転送先: PostgreSQLの転送モードには「TRUNCATE INSERT」が存在します。しかしこのモードは実際にはTRUNCATE TABLEではなくDELETEを実行した後にINSERTをするので、大量のデータを洗い替えるケースには不向きなので上記のような設定をしています。
初期化の設定は以上です。 実際の運用で集計項目の変更が生じた場合などには、アプリケーション側のMigrationが完了した後にこの転送設定を実行し、データを初期化するというフローになります。
日次転送設定
こちらは日々最新のデータに更新するために使用されます。TROCCOのワークフローに組み込まれるため毎日決まった時間に実行されます。 必要なデータは最新のレコードのみですので、データを取得するクエリは下記の通りです。

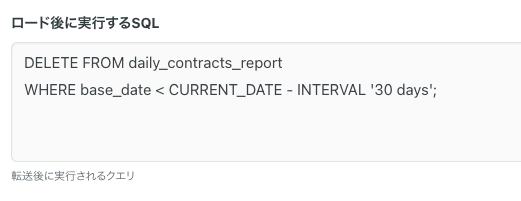
また、この設定に関しては転送先で保持するレコードを30日分にするために、データロード後に実行するクエリに30日を過ぎたレコードを削除するSQLを指定します。
ワークフローに追加
最後に日次転送設定をワークフローに追加します。*3
以上で設定については完了です。 実際に一ヶ月ほど運用していますが、今のところデータ転送に関わる障害も発生せず安定稼働しています。 また、新規テーブル(KPI)追加の対応についても低コストで対応できています。
終わりに
思いの外長くなりましたが、本記事ではニーリーにおけるリバースETLの取り組みについてご紹介しました。 テーブルの構造などは簡略化した仮のものを例示していますが、全体の構成などはほぼそのまま商用で利用しています。 ただし本記事ではネットワークの構成は説明を省略しています。 ネットワーク周りの構成、設定に関してはSREチームに大変お世話になったことをここに記します。🙇
最後になりますがAnalyticsチームは現在も絶賛採用中です。ご興味をもっていただけた方は、お気軽にカジュアル面談にお申し込みください!
それでは2025年も皆さんにとっていい年でありますように!*4
*1:エンジニアが事業に染み出す組織の中で、PdMはどう動くべきか?で触れている「分析レポート機能」です。
*2:接続に利用するDBユーザーに転送先テーブルのTRUCNATE権限を持つよう設定しておきます。
*3:執筆者の気力が途切れたため雑になっていますが、TROCCOのワークフロー作成は容易に利用できUIも素晴らしいです。
*4:あとチケット取れたからギャラガー兄弟がライブ前に喧嘩しませんように🥺
