「自動車ユーザー」とは言いましたが、例えば『Park Direct』はtoB側のユーザーとして不動産管理会社様や駐車場オーナーの方もいますし、『Park Direct for Business』では企業が保有する法人車を管理する従業員の方もいます。
さらに、当然モビリティに隣接するドメインにも拡大を目指しているので、これらを考慮すると「1億人」と言っても差し支えない規模になると思います。
ニーリーは、2019年にローンチした月極駐車場オンライン契約サービス「Park Direct」をメインプロダクトとして事業を伸ばして来ましたが、2021年には法人向けサービスとして「Park Direct for Business」を、そして昨年2025年には1日単位で駐車場予約ができるサービス「ワンデイパーク」の提供を開始し、今まさにマルチプロダクトの波が来ています。
月極駐車場とのシームレスな連携、急激な成長に耐えうる設計、コストと体験の両立。ワンデイパークには、複雑な問題が山積しています。 Park Directという巨大な既存システムの制約と向き合いながら、いかにシンプルで拡張性の高い新システムを構築するか。 リアルな駐車場というアセットを、いかにソフトウェアで柔軟に、かつ堅牢に制御するか。この複雑な問題を解くことこそが、エンジニアとしての腕の見せ所です。事業に直結する複雑な問題を解決して、ビジネスの成長を自分たちが牽引するのはとてもワクワクします。
# Create memory file
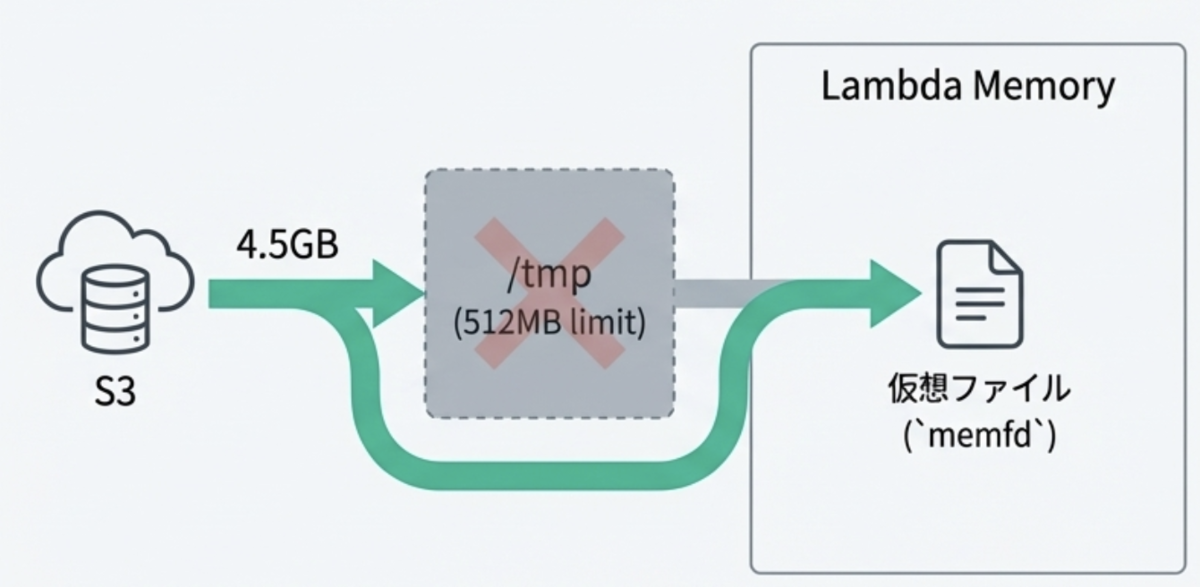
fd = create_memfd()
# Pre-allocate the full file sizetry:
os.ftruncate(fd, file_size)
exceptOSErroras e:
logger.error(f"Failed to allocate {file_size/1024/1024:.2f}MB in memory: {e}")
cleanup_fd(fd)
raiseRuntimeError(f"Not enough memory to load model of size {file_size/1024/1024:.2f}MB")
# Calculate parts for parallel download
parts = []
for start inrange(0, file_size, chunk_size):
end = min(start + chunk_size - 1, file_size - 1)
parts.append({'start': start, 'end': end})
logger.info(f"Downloading {file_size/1024/1024:.2f}MB in {len(parts)} parts")
# Download parts concurrently using ThreadPoolExecutor
download_func = partial(download_part, s3, bucket, key, fd)
with ThreadPoolExecutor(max_workers=multiprocessing.cpu_count()) as executor:
executor.map(download_func, parts)
# Create a path that can be used to access the file
fd_path = f"/proc/self/fd/{fd}"return fd, fd_path
次なる目標は、LLMチャットなどに不可欠な「レスポンスのストリーミング」の実現です。
re:Inventセッションでは「Lambda Web Adapter + FastAPI」というアーキテクチャが紹介されていました。これはLambda内でWebサーバーを動かし、Lambda Function URLs経由でストリーミングを実現するものです。
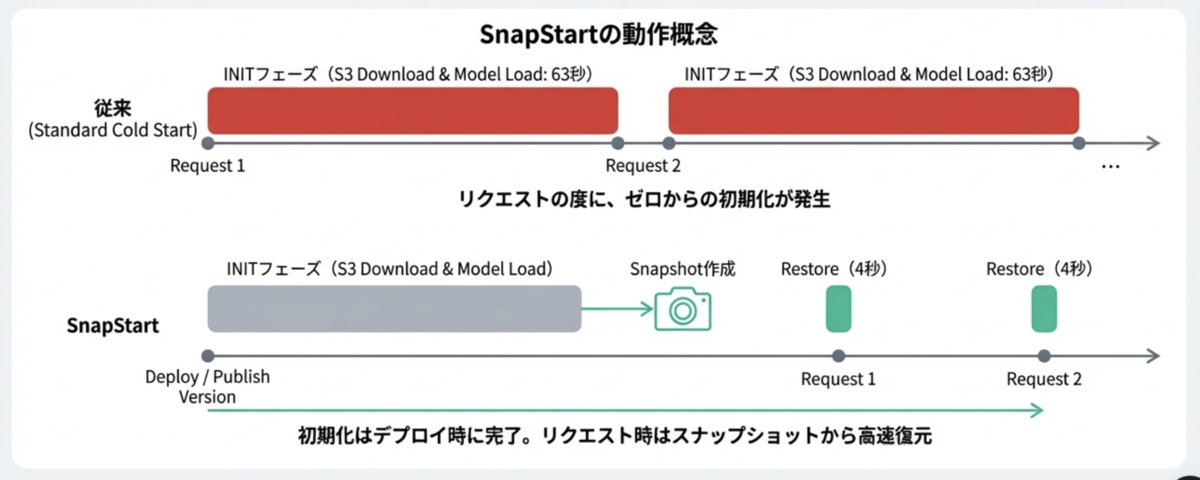
Lambda内でLLMの回答生成が完了するまでバッファリングすることなく、逐次回答していくことにより、結果として最初の1トークン目がクライアントに届くまでの時間(TTFT[^Time To First Tokenの略])を、Warm Start時には 1~3秒 ほどまで短縮することに実現しました🎉
Lambda Web Adapterは、PythonランタイムのLambdaでFastAPIなどの標準的なWebアプリケーションフレームワークを動かすための非常に強力なツールであり、ストリーミング以外にも様々なユースケースが考えられる
ちなみに余談ですが、本セッションの登壇者はLWAの開発者でもありました。
「Pythonランタイムは、今のところ応答ストリーミングを公式にはサポートしていません。幸いなことに、私が作成したLambda Web Adapterというツールがあります。」はウケました(会場もウケてた)。
いやー本当に良い経験をしました。チョークトークに参加して良かったとしみじみ思います。