数多くの登壇の中でも特に興味深かったのが、「コードベースの特性がAI導入効果に与える影響」についての議論だ。モノリポかマルチリポ(ポリリポ)かといった分散度合い、そして複雑性や規模が、AIによる生産性向上をいかに阻害、あるいは促進するのか。
本稿では、そこから得た洞察を整理し、コードベースとAI導入効果の関係について、深く掘り下げてみたい。
🎧 本記事のAI音声解説版をポッドキャストで公開中
【ご視聴時の注意点】AI生成解説のため、内容には一部、原文から逸脱した軽微な誤りや、不自然な表現が含まれる可能性があります。大筋の理解には役立ちますが、詳細や正確な情報については、引き続き本ブログ記事をご確認ください。
- リポジトリの分散度合い(モノリポとマルチリポ)
- コードベースの状態(グリーンフィールド/ブラウンフィールドと低複雑度/高複雑度)
- コードベースの規模
- さいごに: 「人間にとって良い環境は、AIにとっても良い」
- 参考文献
リポジトリの分散度合い(モノリポとマルチリポ)
AIコーディングエージェントの普及に伴い、改めてモノリポの優位性が注目されている。その理由は、全ソースコードが一箇所に集約されている方が、AIにとってコンテキストの断絶が起きにくく、生成物の精度が向上しやすいからである。各モデルが有するコンテキストウィンドウの拡大も、追い風になっているのだろう。
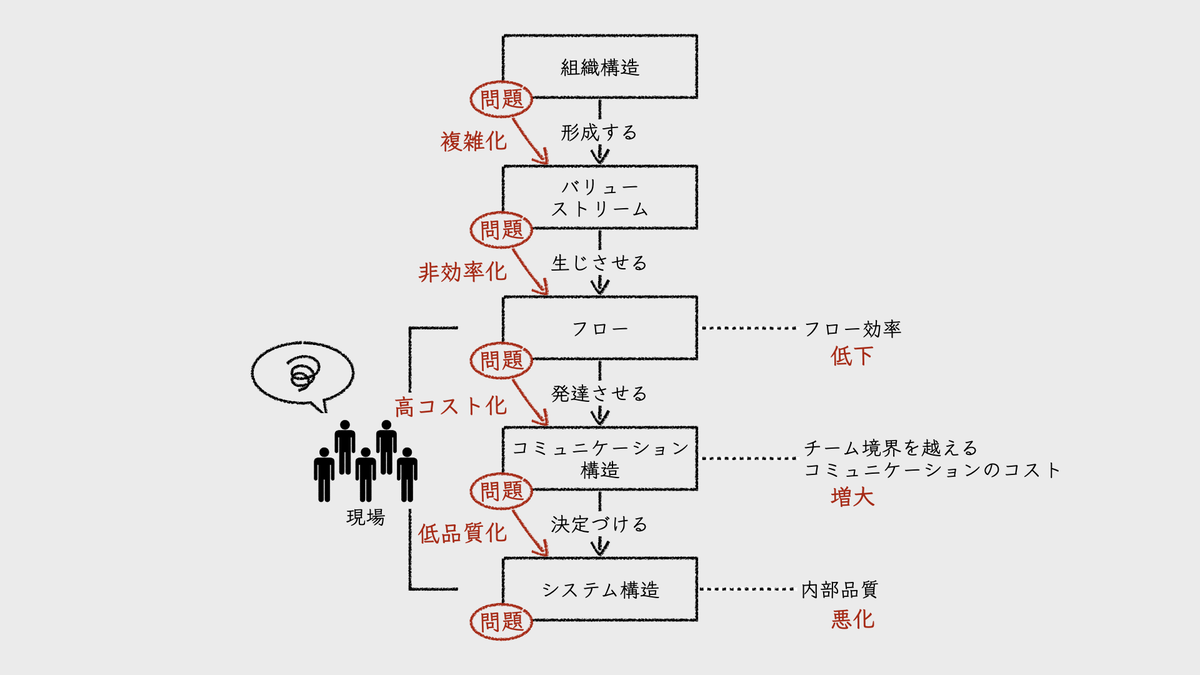
もともとリポジトリ戦略は、ソフトウェアアーキテクチャや組織構造と密接な関係にある。
シンプルなモノリスから、FEとBEの分離、そしてクラウド登場以降に進んだマイクロサービスを始めとする分散アーキテクチャへ。その過程で、リポジトリも分割統治──マルチリポ化が進んだ。
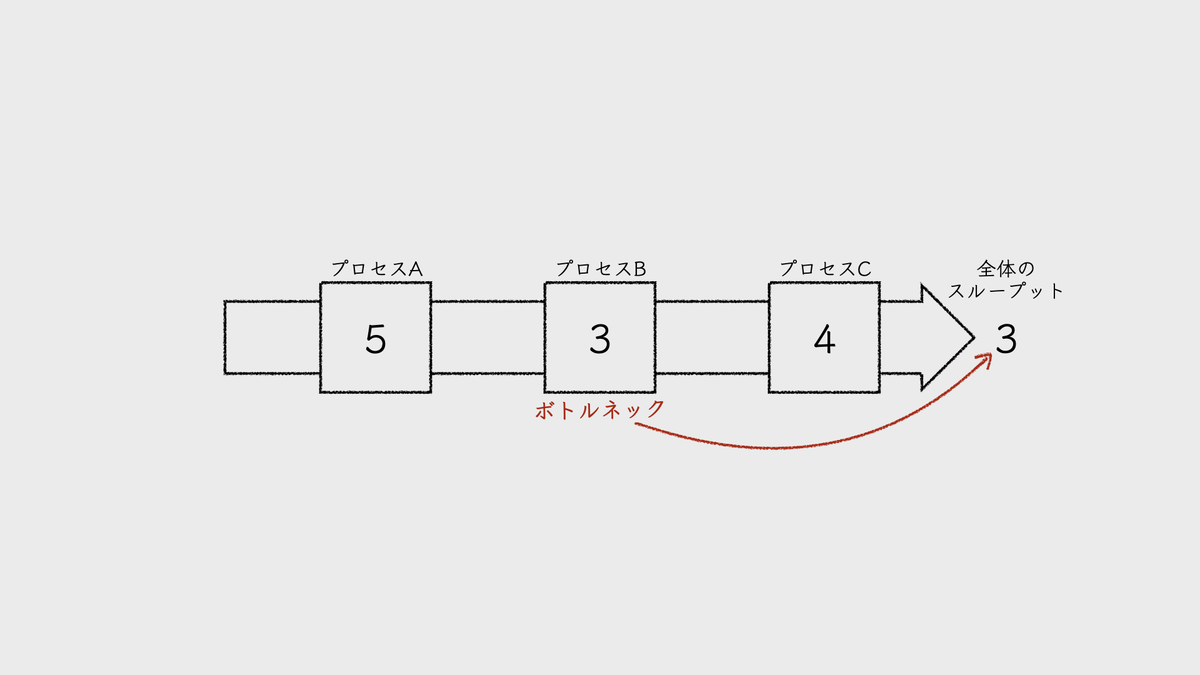
複数チームでのソフトウェア開発では、何らかの境界でソフトウェアをコンポーネント分割し、マルチリポによるチーム単位での分割統治を選択する利点は大いにあった。
しかし、AIエージェントの登場がこの前提を揺るがしている。単なるコード補完の域を超え、リポジトリ全体を俯瞰して複雑なタスクを遂行するエージェントにとって、マルチリポによる物理的な境界は「コンテキストの壁」として機能してしまう。
モノリポの方がAI導入効果が高まるのであれば、リポジトリ戦略を転換すべきかもしれない──。マルチリポで開発を続けてきた組織にとっても、そんな考えがふと頭によぎる。
とは言え、リポジトリの移行は低コストではない。単なる「感覚」ではなく、客観的なインパクトを知る必要がある。
そもそもモノリポかマルチリポかの選択は、従来からトレードオフの関係にあった*1。そこに新たな変数として「AI導入効果」が加わった今、その影響をどこまで考慮すべきか。この問いに対し、JellyfishがOpenAIと提携して行った調査結果を紹介していたのが、Nick Arcolanoの登壇である*2。
【調査結果】分散度が高まるほどAI導入効果は減衰する
Arcolanoが解説した調査では、リポジトリの分散度合いが、AI導入によるPR数増加にどの程度の影響を与えるかに焦点をあてている。*3
分散度合いは、「集約型(centralized)」から「バランス型(balanced)」「分散型(distributed)」「高度分散型(highly distributed)」の4段階に分けられている。そのうえで、各セグメントにおいて、AI導入率が未導入(0%)から完全導入(100%)に移行することでPR数が何倍になるかの増加率を数値化している。
結果は、次の通りとなった。
| 分散度合い | 1人あたりのPR数 | 増加率 |
|---|---|---|
| 集約型 | 2.7 | 3.9倍 |
| バランス型 | 3.1 | 4.1倍 |
| 分散型 | 3.9 | 2.1倍 |
| 高度分散型 | 5.3 | - |
出典: Nick Arcolano(Jellyfish)「What Data from 20m Pull Requests Reveal About AI Transformation」AI Engineer, 2025年11月25日, 14:32~ (動画内のグラフをもとに筆者が作成)
まず、表を見て驚くのは、分散度が高いほどPR数が多くなっている点だが、「マルチリポの方が生産性が高い」ということではない。これは、一機能の開発で複数のリポジトリに変更が波及しているという、マルチリポの構造的問題に過ぎない。
特筆すべきは、AI導入による「増加率」の顕著な差だ。集約型やバランス型では約4倍という劇的な効果が得られているのに対し、分散型ではその半分にとどまる。さらに「高度分散型」に至っては、AI導入とPR数の変化に相関が見られず、むしろ微減の傾向さえ確認された。
もちろん、PR数の増加がそのまま生産性の向上を意味するわけではない。スタンフォードのYegor Denisov-Blanchの示す、ある企業のcommitベースのデータでは、AI導入によって「手戻り(rework)」が増加する傾向も見て取れる*4。
しかし、目安にはなる。先述のcommitベースのデータからも、AI導入以降、機能追加(added)が増加傾向を示しているからだ。

出典: Yegor Denisov-Blanch (Stanford)「Does AI Actually Boost Developer Productivity? (100k Devs Study)」AI Engineer, 2025年7月24日, 9:09~ (動画内のグラフをもとに筆者が作成)
【洞察】リポジトリの境界はAIにとってのコンテキストの壁である
Arcolanoは、AIコーディングエージェントが分散型のリポジトリ戦略を得意としない理由を、リポジトリ間の関係性が記述されていないことにある、と指摘している*5。
シニアエンジニアの脳内にのみ存在するリポジトリの関係図に、AIはアクセスできない。それがコンテキストの欠落となって、ハルシネーションを誘発し、生成物の品質を低下させる。
AI時代におけるモノリポの真価は、その圧倒的な「視野」と「操作範囲」の広さにある。コードが地続きのコンテキストとして存在することで、AIは全体最適に基づいた分析を行い、コンポーネントを横断するアトミックな変更を一括で完結できる。*6。
対照的に、マルチリポ構成はAIに「情報の断片」を用いた個別作業を強いる。リポジトリ間の整合性を保つための調整コストが、AI本来のスピードを相殺してしまうのだ。
この構図は、人間にとっても同様だ。同時に扱うリポジトリが増えるほど開発は煩雑になる。コンテキストウィンドウならぬ、脳内のワーキングメモリが飽和し、認知負荷が増大する。
そもそも、単一の機能改修で常に複数リポジトリへの変更を強いられるなら、“チームがソフトウェアを分割統治している” 状態とは言い難い。マルチリポの利点を活かせていないのだ。
それはおそらく、ソフトウェアアーキテクチャの問題だろう。リポジトリ間の凝集度が低く、結合度が極めて高いという欠陥を示唆している可能性がある。
もちろん、明確に技術スタックが異なるようなFEとBEを境界とした分散なら分かる。しかし、たとえば複数のBEシステムが複雑に絡み合っているなら問題だ。
結局、AI導入効果が伸び悩む背景には、AI以前の問題である「旧来の設計不備」が横たわっていることも多い。
【戦略】境界の妥当性検証と戦略的集約の検討をはじめる
マルチリポ環境でAI導入効果を最大化するためにまず着手すべきは、“リポジトリ境界の妥当性”、延いては “コンポーネント境界の妥当性” の検証である。
もし単一の機能改修において、定常的にリポジトリを跨ぐ変更が発生しているなら、それは分割の単位が不適切である可能性が高い。それなら、リアーキテクチャを検討する。セットで変更されることが多いリポジトリなら、単純に、統合してしまってもよい。
リポジトリ移行やリアーキテクチャは時間と労力を要する仕事だが、長い目で見れば、AIの文脈理解を助けるだけでなく、保守コストの削減にも直結する。
一方で、ソフトウェアアーキテクチャやリポジトリ分割は適切でも、複数のリポジトリを横断して変更しなければならないこともある。ドメイン駆動設計で言う「境界付けられたコンテキスト」をまたいだ機能開発など、ざらにあるからだ。
このようなケースが頻発するのであれば、リポジトリの集約も検討の余地がある。
ただし、あまりに巨大なモノリポは、ビルド・テストの遅延やCI/CDの複雑化を伴う。そのトレードオフを踏まえたうえでの判断になるだろう。
選択肢の一つとして、ハイブリッドなリポジトリ戦略もある*7。コアなものは一つのリポジトリに集め、そうでないものはマルチリポで管理するアプローチだ。この「戦略的集約」こそが、AIの視野を確保しつつ、システムの肥大化を制御する現実的な解となるのかもしれない。
コードベースの状態(グリーンフィールド/ブラウンフィールドと低複雑度/高複雑度)
エンジニアの日常は、見通しの悪い絡み合ったコードとの奮闘に多くの時間が費やされる。新規にソフトウェアを開発するプロジェクトより、既存ソフトウェアの保守・拡張にあたることが多いからだ。
追加開発を長年繰り返してきたコードベースは、時代遅れなコードや複雑な依存関係が堆積し、それが開発の自由度を奪う。タスクの難易度が高まるほど、この制約は足かせとして重くのしかかる。
こうした開発環境の差異を、建築業の用語を借りて「グリーンフィールド」と「ブラウンフィールド」というメタファーで表現することがある。
グリーンフィールドとは汚染されていない未開発な土地を指す。再開発または再利用しようとしている、既存汚染物質を伴う用地のことはブラウンフィールドと呼ばれる。
(引用: Neal Ford, Rebecca Parsons, Patrick Kua 著/島田 浩二 翻訳『進化的アーキテクチャ ─絶え間ない変化を支える』2018年, オライリー・ジャパン, 6.2)
ソフトウェア開発においては、新規にソフトウェアを開発するプロジェクトをグリーンフィールド、既存のソフトウェアを扱うプロジェクトをブラウンフィールドと呼ぶ。
引用文内での「汚染」という言葉は、既存ソフトウェアに蓄積された “時代遅れなコード” や “複雑な依存関係” といった、エンジニアリング活動の足かせを象徴している。つまり、既存ソフトウェアを扱うプロジェクトは、開発生産性が低くなりがちだと古くから認識されていた。
AI時代において、ブラウンフィールドのこの問題は打開されたのだろうか。
【調査結果】ブラウンフィールドかつ複雑なタスクはAIとの相性が悪い
スタンフォードのYegor Denisov-Blanchは、「プロジェクトの成熟度(project maturity)」と「タスクの複雑性(task complexity)」の組み合わせの4象限で評価した結果を紹介していた*8。「プロジェクトの成熟度」は、グリーンフィールドかブラウンフィールドで分類されている。
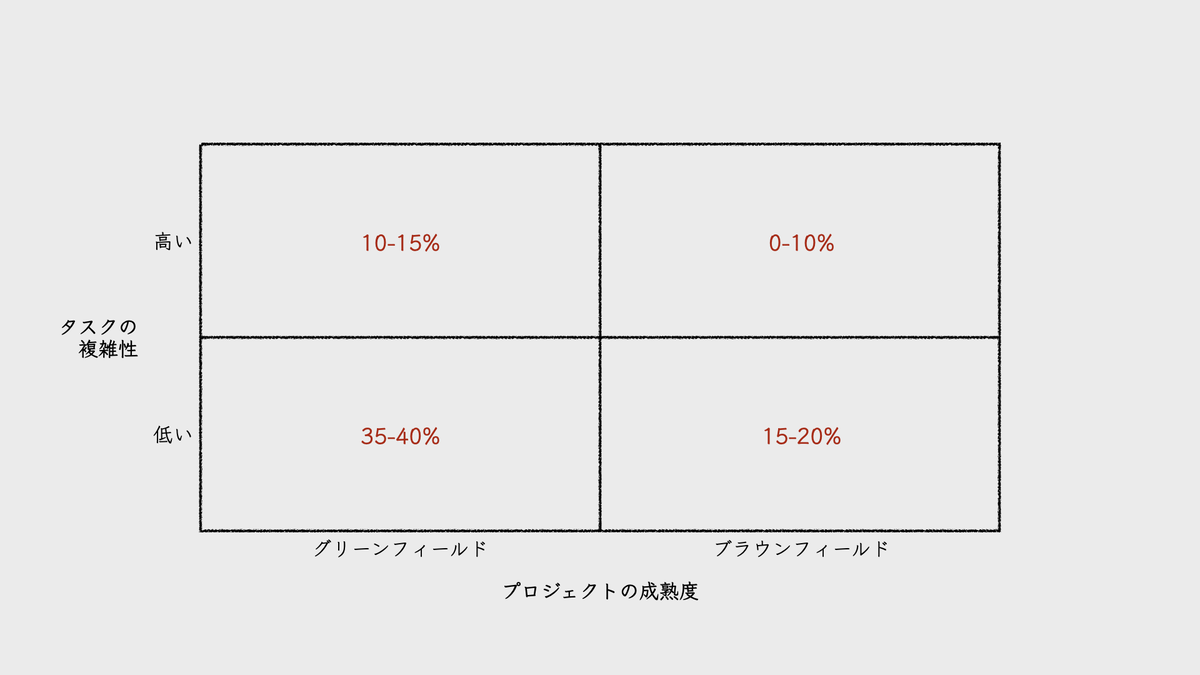
出典: Yegor Denisov-Blanch (Stanford)「Does AI Actually Boost Developer Productivity? (100k Devs Study)」AI Engineer, 2025年7月24日, 13:28~ (動画内の図をもとに筆者が作成)
データが示す傾向は明白だ。AI導入による恩恵は、グリーンフィールドかつ低複雑性のタスクで最大化される一方、ブラウンフィールドかつ高複雑性の条件下では著しく減衰する。
なお、ここで言う生産性とは、コード行数やcommit数、PR数といった単純な指標ではない。独自のモデルを用ったcommitベースでのコード評価によって、バグによる手戻りなどの変更が取り除かれた結果が用いられている。*9
【洞察】AIは2種類の複雑性を区別できない
Denisov-Blanchは調査結果に対し「根本的な原因は不明」としているが、AIを駆使する多くの開発者にとっては納得感ある結果と映ったはずだ。
AIによるコード生成において、タスクの複雑性が増せば実行時間は長迷するだけでなく、成果物の品質低下で手戻りも生じる。これは日常的にAIを活用する者なら誰もが抱く肌感覚だろう。
特にブラウンフィールドのコードベースにおいては、必然的に内包される「本質的複雑性」に加え、過去の成り行きで積み重なった「偶有的複雑性」が混在する。この二重の複雑性がタスクの難易度を高め、AIのパフォーマンスを阻害する主因ではないか。
ソフトウェアには、解くべき課題に由来する「本質的複雑性(essential complexity)」と、レガシーな設計や場当たり的な回避策による「偶有的複雑性(accidental complexity)」が内包されている*10。後者はしばしば技術的負債と化す。
結局のところ、コードベースの複雑性に起因するのではないか、というのが私の見立てだ。もちろん、ブランフィールドのコードベースの方が規模が大きいかもしれず、それが一因であることも考えられる。それは、後述する別の議論で扱うことにしよう。
先述の通り、歴史の長いプロジェクトほど内部構造が複雑化しやすい。異なる機能間のロジックが明確に分離されておらず、絡み合い、本来あるべき境界線が消失している。
この複雑な依存関係を解きほぐすのは人間にとっても困難だが、それはAIにとっても同様だ。むしろ、開発者が持つ暗黙知にアクセスできないAIが介入することで、構造をさらに悪化させるリスクさえ内包している。
NetflixのJake Nationsによれば、AIは、二種類の複雑性──本質的複雑性と偶有的複雑性──を区別しない。*11
混在するこれら二つの複雑性を分離・整理するには、開発の背景、歴史的経緯、ドメイン知識に基づく高度な経験則が不可欠となる。だが、コンテキストが不足したAIには、そのような分離は行えない。ロジックも技術的負債も、単なる “既存コードの一部” として等価に認識されるだけだ。
結果、過去の奇妙なワークアラウンドやレガシーな設計思想の上に、AIが生成したコードがさらに塗り重ねられる。そうしてコードベースが抱える偶有的複雑性はさらに悪化する。
こうしてAI導入による速度的メリットは、肥大化する複雑性と手戻りのコストによって容易に相殺されてしまう。では、この「AIが複雑性を増幅させる」という不可避な停滞を前に、どのような選択をすべきなのだろうか。
【戦略】「Easyボタン」を捨て、開発ワークフローを選択的に切り替える
「期待する動作さえすれば良し」と振り切るのであれば、少なくとも内部品質の手直しコストを削減できるが、それで本当に良いのだろうか。これは従来の言葉で言えば、「『クイック&ダーティ』を選択してスピードを優先し、品質を犠牲にするのか」という古典的な問いである。
だが、AIによって開発が加速した世界において、この選択はかつてないほど深刻な状況を招く。Capital OneのMax Kanat-Alexanderが指摘するように、質の低いPR(bad rubber stamp PRs)を量産し、形骸化したレビューを繰り返せば、コードベースは複雑化の一途を辿る悪循環に陥る*12。その悪化スピードは、これまでの比ではない。
Nationsは、AIによって助長されたこのクイック&ダーティな選択肢を「究極の “Easy” ボタン(ultimate easy button)」と呼んだ。
ここでいう「Easy」とは、Rich Hickeyが提唱した「Simple」と対比される概念だ*13。端的に言えばクイック&ダーティを指す。目先のスピードと引き換えに「後回しにされた複雑性」を受け入れるトレードオフだ。従来で言えば、StackOverflowからの安易なコピペがその典型例と言える。
対する「Simple」は、「Complex(複雑)」の対極にあり、要素が絡み合わず、保守性の高い構造を指す。これは設計や実装に対する深い洞察と、熟慮の末にのみ到達できる境地である。
では、安易な「Easyボタン」に逃げるのではなく、AIを駆使して「Simple」をいかに実現すべきか──。
鍵となるのは、複雑なタスクにおいて、通常のワークフローから、より「コンテキストエンジニアリング」に重心を移したアプローチへと切り替えることだ。
通常のワークフローに欠けているのは、変更対象となるコードベースの綿密な調査と、そこから導き出される詳細な実装計画である。これらを抜きにして、いきなりAIにコード生成を命じたところで、到底満足な結果は得られない。
このアプローチは、AIにアドホックな指示を出して実装を継ぎはぎしていく「最も素朴な手法(most naive way)」*14とはパラダイムが異なる。目指すべきは「正確なコードの生成」そのものではなく、それを可能にする「精度の高い実装計画」をいかに構築するかという、AIとの協働のあり方だ。

Nationsもそうであるが、HumanLayerのDex Horthyは、その有望な手法としてRPI(Research, Plan, Implement)を詳述している*15*16。これはDenisov-Blanchの調査結果も踏まえ、「ブラウンフィールドにおける複雑なタスクを効果的に実行するためのコンテキストエンジニアリング」として位置づけられる。
RPI以外にも、簡易にやるならAIコーディングツールの「PLANモード」の活用もそうだろう。また、仕様の詳細化まで含めるなら「SDD(スペック駆動開発)」も同様の志向を持つと言える(※ただし、Horthyは一部のSDDツールに対しては否定的な見解を示している*17)。
コードベースの規模
複雑化と並び、規模の膨張もまた、業務システムやWebサービスのブラウンフィールドプロジェクトにとって無視できない障壁となる。「リーマンの法則(Lehman's laws of software evolution)*18」が、これを的確に言い表している。
- 複雑性の増大(Increasing complexity):
- 継続的に変更されるソフトウェアは、リファクタリング等の明示的な改善を行わない限り、内部の構造的複雑性が増大する。
- 継続的な成長(Continuing growth):
- ソフトウェアは、ユーザーの満足度を維持するため、継続的に機能を拡張し続けなければならない。
「継続的な成長」による継続的な機能拡張の結果は、それらの累積に伴うコードベース規模の巨大化である。特にAIによって開発が高速化された現代では、このサイクルまでもが加速し、コードの膨張スピードはかつての比ではない。
ここで懸念すべきは、「コードベースの規模そのものが、AI導入効果を減衰させる変数になり得るか」という点だ。
【調査結果】規模が大きくなるほどAI導入効果は低減する
Denisov-Blanchは、コードベースの規模が拡大するほど、AI導入による生産性向上の恩恵が目減りするというグラフを提示している*19。これは厳密な実証データのプロットではなく、研究チームが数多くの事例を観測する中で導き出した、理論的な傾向を視覚化したものである。

出典: Yegor Denisov-Blanch (Stanford)「Does AI Actually Boost Developer Productivity? (100k Devs Study)」AI Engineer, 2025年7月24日, 15:35~ (動画内のグラフをもとに筆者が作成)
提示されたグラフでは、コードベースの規模が大きくなるにつれ、AIの寄与率が急激に減衰していく曲線が描かれている。このグラフは、縦軸に「AIによる生産性向上の推定効果」、横軸にコードベースサイズ(1K LOCから10M LOCまでの対数スケール)を取る。
現実のプロジェクトに目を向けると、この減衰は決して無視できない。業務システムやWebサービスのブラウンフィールドプロジェクトが扱うコードベースが、1-2K LOCということは稀だろう。ある調査によれば、一般的なソフトウェア開発におけるコード行数の中央値は31.8K LOC、75パーセンタイル値は96.1K LOCに達する*20。
この統計を先の曲線に当てはめるならば、現代のブラウンフィールドプロジェクトの多くは、そのコードベース規模により、AI導入効果が大きく減衰していることになる。
【洞察】物理的な量そのものがAIの推論精度を汚染する
Denisov-Blanchは、規模の拡大がAIのパフォーマンスを低下させる背景として、以下の3点を挙げている*21。
- コンテキストウィンドウの限界:
- 大きなコンテキストウィンドウを持つモデルであっても、扱うコンテキスト長(トークン数)が増えるほど、コーディングパフォーマンスのスコアが落ちてしまう。
- SN比:
- 本来注目すべきロジック以外の「ノイズ」の混入が増え、モデルを誤った推論へと誘導する。
- 複雑性(Complexity):
- 規模に比例して依存関係やドメインロジックが増え、複雑性が高まる。
これらの要因のうち、2と3は本質的には「コードベースの複雑性」に帰属する問題であり、既に考察した通りである。
したがって、巨大なコードベースを扱う際に生じる「規模そのもの」に起因する影響を解明するため、ここでは「コンテキストウィンドウの限界」に焦点を絞って掘り下げたい。
【戦略】効果的なコンテキストエンジニアリングでスマートゾーンを維持する
大容量のコンテキストウィンドウを持つモデルを採用するのは一つの解決策だが、無計画な対話を重ねれば、そのリソースは瞬時に枯渇する。モデルによっては、容量が逼迫すると古い情報を自動圧縮(auto compaction)するものもあるが*22、それはあくまで対症療法に過ぎない。
Horthyは、ウィンドウ容量の半分に満たない段階でもパフォーマンスの低下が始まると指摘し、その閾値を超えた領域を「ダムゾーン(dumb zone)」と定義した。例えばClaude Codeにおいては、容量の約40%がその境界線になると述べている*23。
そこで求められるのは、コンテキストを最小限に保ち、AIのパフォーマンスを最大化させる「スマートゾーン(smart zone)」を維持する工夫だ。そのためには、コンテキストウィンドウの内部構造に対する深い理解と、戦略的なコンテキストエンジニアリングが不可欠となる。
ウィンドウを占有するのは、プロンプトやコードだけではない。システムが予約している領域に加え、MCPツールのメタ情報や CLAUDE.md といったユーザー定義領域も含まれる。特に後者を無秩序に肥大化させている場合、AIの「思考の余白」を自ら奪っていることに他ならない。
コンテキストとは、単に情報を詰め込めばよいという性質のものではないのだ。だからこそ、次の4点に意識を向けたい。
- コンテキストのリフレッシュ*24:
- AIとの対話が迷走し始めたら、
/clearなどを使い、コンテキストをリセットして新しいウィンドウでやり直す。
- AIとの対話が迷走し始めたら、
- サブエージェントによる階層化*25:
- サブエージェントを活用することで、推論のプロセスを各々のウィンドウに閉じ込める。メインエージェントには「結果」のみを返却させることで、親ウィンドウの汚染を防ぐ。
- 動的なスキルロードの活用*26:
- エージェントスキルを利用し、必要な情報のみをオンデマンドで読み込ませる。常にすべてのドキュメントを読み込ませるような静的な管理を避ける。
- 意図的な圧縮(Intentional compaction)*27*28:
- RPIのようにプロセスをフェーズ分けし、各段階の成果をMarkdown等に集約する。次フェーズでそれらを参照することで、中間過程の膨大なトークンを破棄し、本質的なコンテキストの密度を高める。
これらの手法は、単なる機能の知識にとどまらず、コンテキストウィンドウの構造やAIコーディングツールの内部挙動に対する深い洞察、そして実践を通じた習熟が不可欠であることを示唆している。
従来のコーディングにおいて、優秀なエンジニアがIDEやエディタを使いこなしていたのと同様に、AI時代においてもツールの習熟は不可欠なのである。
さいごに: 「人間にとって良い環境は、AIにとっても良い」
ここまで考察してきたリポジトリ戦略、コードの複雑性、そして規模の問題は、すべて地続きの課題である。大規模なコードベースは宿命的に複雑性を内包し、大規模化を避けようとすればリポジトリを分散管理の方向へ進ませる。
しかし、いずれにしても本質的な問いは、「AIがそのタスクを遂行するために必要なコンテキストを、ノイズなく、かつ地続きに把握できているか」という点に集約される。
AIが真にパフォーマンスを発揮できるのは、境界が明確で、不必要な依存がなく、関心が適切に分離された見通しの良いコードベースだ。これは、私たちが理想としてきたソフトウェアアーキテクチャそのものに他ならない。
セッションの中でKanat-Alexanderが述べた「人間にとって良い環境は、AIにとっても良い(What's good for human is good for AI)」という言葉*29が、それをよく言い表している。
参考文献
*1:Molisha Shah「Monorepo vs Polyrepo: AI's New Rules for Repo Architecture」Augment Code, 2025年10月11日, What We Thought We Knew
*2:Nicholas Arcolano「AI Coding Tools Not Paying Off? Your Code Architecture Might Be to Blame.」Jellyfish, 2025年10月16日
*3:Nick Arcolano(Jellyfish)「What Data from 20m Pull Requests Reveal About AI Transformation」AI Engineer, 2025年11月25日, 14:32~
*4:Yegor Denisov-Blanch (Stanford)「Does AI Actually Boost Developer Productivity? (100k Devs Study)」AI Engineer, 2025年7月24日, 9:06~
*5:Nick Arcolano(Jellyfish)「What Data from 20m Pull Requests Reveal About AI Transformation」AI Engineer, 2025年11月25日, 14:32~
*6:Rohit Radhakrishnan「Monorepo vs. Polyrepo for Multi-Stack Vibe Coding: A Developer’s Decision Framework」Medium, 2025年9月12日
*7:Molisha Shah「Monorepo vs Polyrepo: AI's New Rules for Repo Architecture」Augment Code, 2025年10月11日, What This Means in Practice
*8:Yegor Denisov-Blanch (Stanford)「Does AI Actually Boost Developer Productivity? (100k Devs Study)」AI Engineer, 2025年7月24日, 13:21~
*9:Yegor Denisov-Blanch (Stanford)「Does AI Actually Boost Developer Productivity? (100k Devs Study)」AI Engineer, 2025年7月24日, 6:18~
*10:フレデリック・P・ブルックス,Jr. 著, 滝沢 徹, 牧野 祐子, 富澤 昇 訳『人月の神話【新装版】』丸善出版, 2014年, 第16章
*11:Jake Nations(Netflix)「The Infinite Software Crisis」AI Engineer, 2025年12月21日, 07:42~
*12:Max Kanat-Alexander (Capital One)「Developer Experience in the Age of AI Coding Agents」AI Engineer, 2025年12月24日, 15:00~
*13:Rich Hickey「Simple Made Easy」InfoQ, 2011年10月20日
*14:Dex Horthy(HumanLayer)「No Vibes Allowed: Solving Hard Problems in Complex Codebases」AI Engineer, 2025年12月3日, 2:56~
*15:Jake Nations(Netflix)「The Infinite Software Crisis」AI Engineer, 2025年12月21日, 10:55~
*16:Dex Horthy(HumanLayer)「No Vibes Allowed: Solving Hard Problems in Complex Codebases」AI Engineer, 2025年12月3日, 7:45~
*17:Dex Horthy(HumanLayer)「No Vibes Allowed: Solving Hard Problems in Complex Codebases」AI Engineer, 2025年12月3日, 17:41~
*18:「Lehman's laws of software evolution」Wikipedia
*19:Yegor Denisov-Blanch (Stanford)「Does AI Actually Boost Developer Productivity? (100k Devs Study)」AI Engineer, 2025年7月24日, 15:35~
*20:『ソフトウェア開発分析データ集2022』独立行政法人情報処理推進機構(IPA), 2022年, P16 表1-2-5 SLOC規模
*21:Yegor Denisov-Blanch (Stanford)「Does AI Actually Boost Developer Productivity? (100k Devs Study)」AI Engineer, 2025年7月24日, 16:15~
*22:平川 知秀「Claude Codeのコンテキストウィンドウを完全に理解する」gihyo.jp, 2025年12月23日, 「Auto Compactの領域」
*23:Dex Horthy(HumanLayer)「No Vibes Allowed: Solving Hard Problems in Complex Codebases」AI Engineer, 2025年12月3日, 5:55~
*24:Dex Horthy(HumanLayer)「No Vibes Allowed: Solving Hard Problems in Complex Codebases」AI Engineer, 2025年12月3日, 3:09~
*25:Dex Horthy(HumanLayer)「No Vibes Allowed: Solving Hard Problems in Complex Codebases」AI Engineer, 2025年12月3日, 6:28~
*26:Barry Zhang & Mahesh Murag(Anthropic)「Don't Build Agents, Build Skills Instead」AI Engineer, 2025年12月9日, 4:21~
*27:Dex Horthy(HumanLayer)「No Vibes Allowed: Solving Hard Problems in Complex Codebases」AI Engineer, 2025年12月3日, 3:48~
*28:Dex Horthy(HumanLayer)「No Vibes Allowed: Solving Hard Problems in Complex Codebases」AI Engineer, 2025年12月3日, 7:26~
*29:Max Kanat-Alexander (Capital One)「Developer Experience in the Age of AI Coding Agents」AI Engineer, 2025年12月24日, 17:42~