概要
ICPC2022模擬国内予選 (2022/Practice/模擬国内予選/案内 - ICPC OB/OG の会) に参加しました。
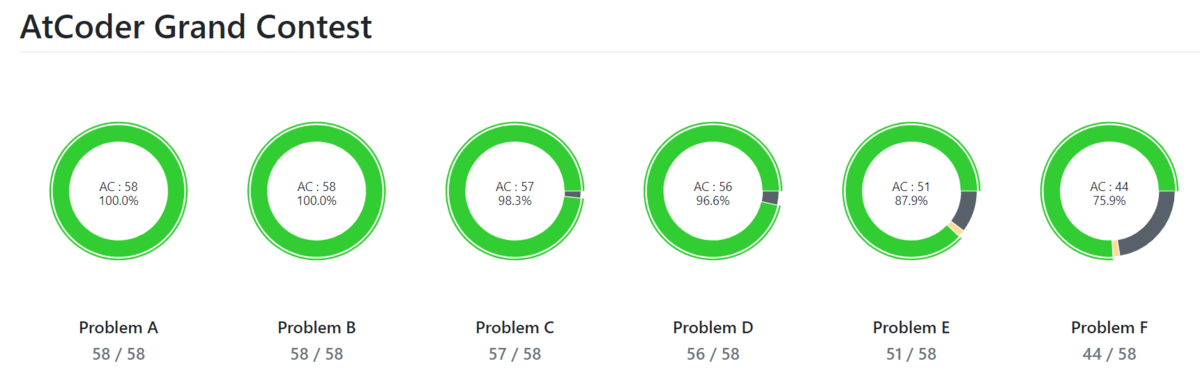
結果は ABCDEFG の7完で2位でした。
チーム名は Bue World でチームメンバーは kopricky, mtsd, pachicobue でした。
もちろん今年の ICPC 参加資格はありません。
経緯
模擬国内予選が開催されることを 2 人に伝えましたが、kopricky の生存確認が取れることは稀で、このままだとパチコと 2 人参加だな~と思っていました。
6/18(土)午後 3 時 48 分 kopricky :「ところで模擬国内出るぶえ!(たぶん)」
良かった~
6/25 当日
30分前に全員の起床を確認。コンテスト10分前にパチコと dicord で合流。
午後1時。コンテストが始まりました。
とりあえず自分が A を読み、パチコが B を読むことに。
(開始して数分経ったところで、koprickyも現れました。kopricky「よし!やるぞ!」)
A問題:連番
N 個の整数からなる列 A = (a1, a2, ..., aN) が与えられる.A を昇順に並べかえたとき,連続する整数が続く区間の長さの最大値を求めよ.
なるほどなるほど、流石に A は簡単だと、
int res = 0;
int tmp = 1;
for(int i=0;i<n-1;i++){
if(a[i]+1==a[i+1])tmp++;
else{
chmax(res,tmp);
tmp = 1;
}
}
chmax(res,tmp);
と書くも、サンプルが合わない。もうダメかもしれないなと思って問題文を読み返すと "A を昇順に並べかえたとき" と書いてあった。最初から sort しておいてくれよと思いながら直して、提出システムにまごつきながら AC (0:06:01)。
その間に、パチコが B を実装して、kopricky が C をやっていました。(BとCに関しては完全並列なため全く把握してません)
パチコが B 大変だなと言ってたような気がしますが、すぐに AC (0:12:49)。
その間に自分が D をやり始めていました。
D 問題:動く点 P と愉快な仲間たち Q, R
凸 N 角形上を 3 点が動く問題。3 <= N <= 2000。
どれかの点が隣の頂点に到着するごとに時間の区間を区切ることを考える。
D 問題の幾何だし、大体こういうのは各区間で下に凸!三分探索!そうじゃないと解けません!と言ってそのまま書き始める。
意外と実装は重くなく、適当に書いてみたらサンプルが合う。まあ投げてみるっしょで AC (0:23:21)。
そんなこんなしている間にこれどうやって提出するんだっけ?とか言っていた koprickyが C も AC (0:28:55)
E の問題文を見た瞬間にパチコ用の問題であることが分かったので、特に何も考えずにパチコに E 問題の全権を託す。そしたら爆速で AC (0:40:42)。流石パチコとしか言いようがなかった。
ここからは、
F 問題 : kopricky, mtsd
G 問題:pachicobue
という分担で進めることに。
F 問題 : N 階ダンジョンと K 人の勇者たち
この問題を読んですぐ、「最小流量制約+流量に対して線形にコストが上がっていく最小費用流」であることは分かった。
kopricky はフロー周りを詳しかったはずなので(色々実装してるし)、話し合いながら考察を進める。
流量の分だけ辺を追加して間に合う?とか言ってみるもまあ無理だよねという話に。
凸費用流は解けるって聞いたことあるなと思って、いろいろ調べてみるもあんまりよく分からず。kopricky に流石にその方向性はやばくね?と諭されたので、フローのお気持ちを考えることに。
まあよくわからんけど、最短路反復の際に見る辺って実は各辺について、現在の流量+1の辺と現在の流量の逆辺 だけでいいんじゃない?と試しに言ってみる。
ほんとぉ?と言われるも、まあこれじゃなかったらこの問題は解けねえと言ってみる。最小費用流ってどうやって更新するんだっけ、ポテンシャルとかなんかあったよねと、いろんな文献とライブラリを眺めながら苦しむことに。
まあ辺のコスト変える方針でいっちょ書いてみるか!と自分がコーディングへ。
最小流量制約ってどうやるのか忘れたな、まあ -INF みたいな辺で管理すりゃええか!-> 辺のコストガチャガチャ変えて壊れんのかな、まあ壊れん壊れん!
と雰囲気でライブラリを改造してみると、サンプルがある程度合って、ほんとぉ?と言いながら提出しようかなという気持ちに。
でもちょっと待てよ、これ答え long long のギリギリまで大きくなるけど -INF とかやって大丈夫なの? -> うーん、ダメそう... -> 実際にテストケースをダウンロードしてみて、流量制約について valid かの test を書いて自分の出力と比較すると、valid なものに対して -1 を返していて涙。
ええい! int128 で管理したれ! -> なんか出力が全部壊れました。涙。
ここら辺で険しいよ~と kopricky に助けを求めるも、あまり伝えても意味がなさそうだったので、ライブラリのどこでおかしくなっているかを確認しに行くとstd::numeric_limits<__int128_t>::max() とかがかなり怪しそうという気持ちに。
INF 周りをいじくりまくったらようやくそれっぽい出力になり、ええい提出してやれ!と提出すると AC (02:01:39)。1時間半かかりました。long long ギリギリを攻めるのやめてくれ~。
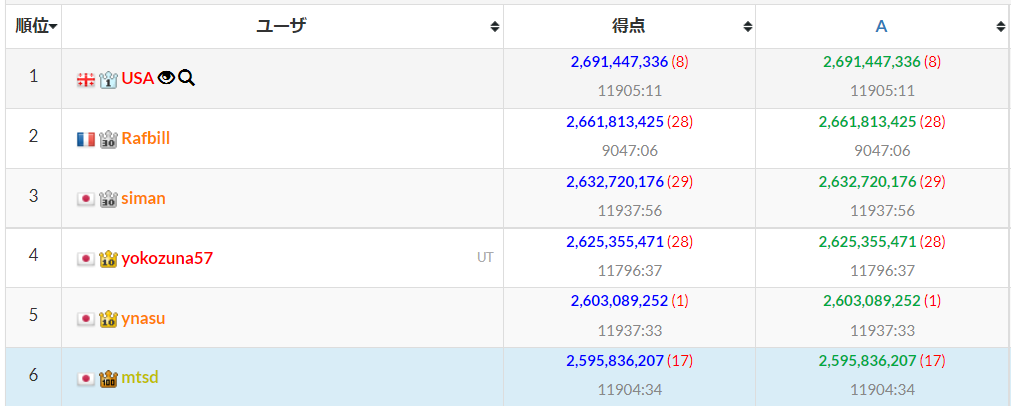
順位表を見るとこの時点で 3位 に!
ん?よく見ると F に1ペナ生えてる。kopricky、なんか提出ミスっちゃったかも。。。
kopricky 「あ、バレた?」(愚直を出力したら爆速で終わったらしいので提出したら出力が普通におかしくて WA を生やしていたらしいです)
そんなこんなで、パチコの G の様子を聞いてみると、最適値が合うところまで来たけど復元がまだ上手く行ってないと伝えられる。
じゃあ H 読んでおくかと H にトライ。
H問題 : パレード
問題は、単純連結無向グラフが与えられ、
条件1. 各辺については2回まで通ってよいけど、連続では通ってはダメ
条件2. 各辺について1回以上通るような一筆書き
の2つの条件を満たす経路を求めるような問題。
とりあえず自明にダメなケースとして、次数1 の頂点が 3つ以上あるケースはダメとわかる。
0 or 2 の場合を考えればよい。(これ今見ると嘘で、何故か偶数個しかないと勘違いしてるね)
多分これは必ず経路が作れるんだろうなという競プロ勘が働き、どうやって構築するかなという気持ちになる。
とりあえず次数 1 の頂点が 2 個 s, t の場合を考えてみると、とりあえず適当に 1 つ s-t パスを取りのぞいてみて、すべての辺を倍化してやればオイラー路の感じで出来そう。
あとはいい感じにガチャガチャやるのかな~?
と考えていたところで、パチコから G の HELP 要請が。
どうやら、G問題の大体はできているが、経路を作るところで嘘が見つかりハマっていたらしい。
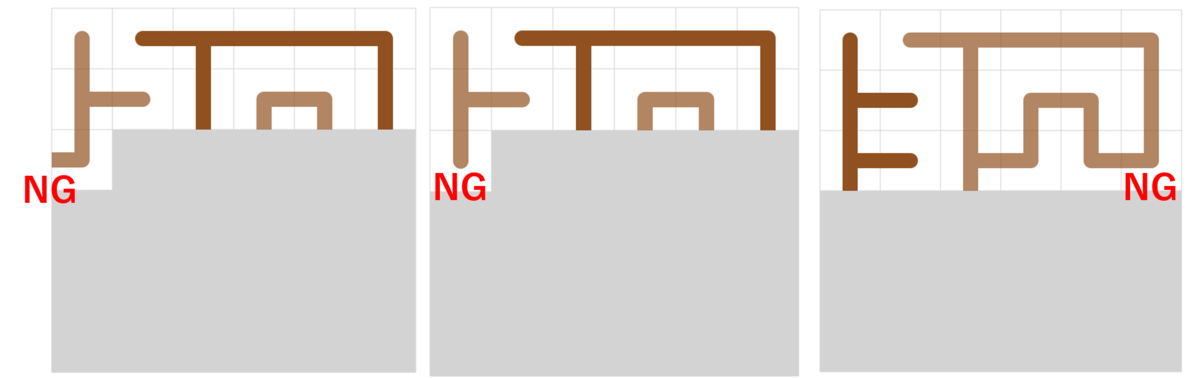
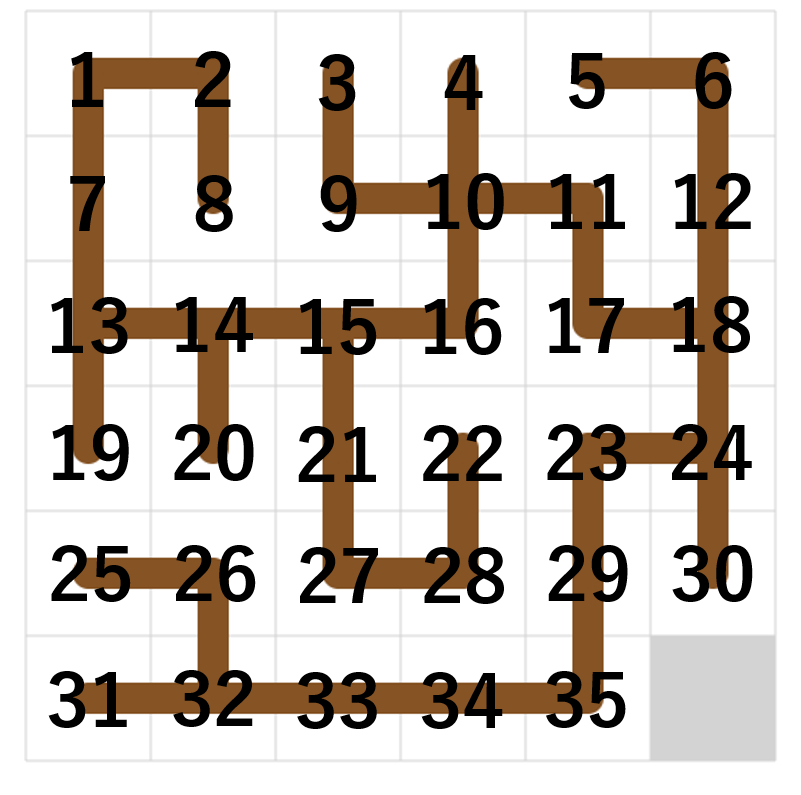
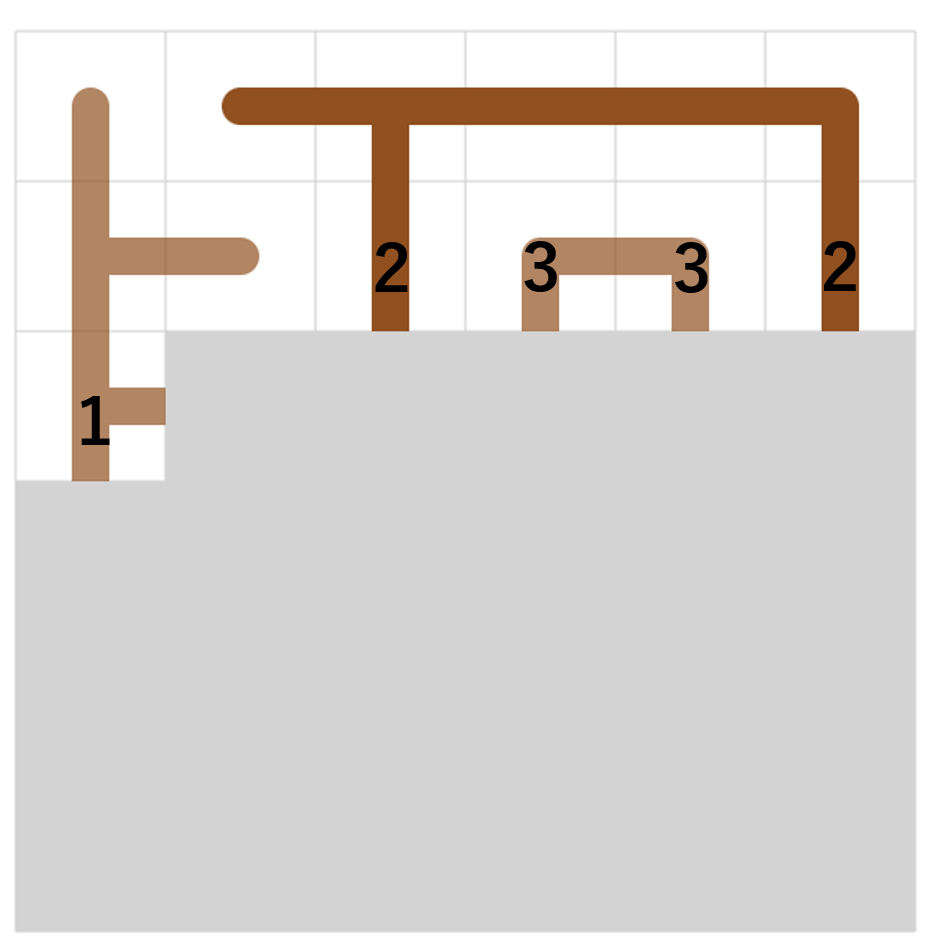
頂点1,2,...,n が順に並んでいて、各頂点 x について x より番号が小さい頂点に伸びる辺の数と x より番号が大きい頂点に伸びる辺の数(合わせて辺の数は高々2)が与えられるので、オイラー路を作成してください
という問題が解ければよいというところまで来ているとのこと。
頂点番号が小さい方から順に処理して貪欲に辺を加えていけばよいと思うんだけど、上手くいかないケースがある。という話だった。
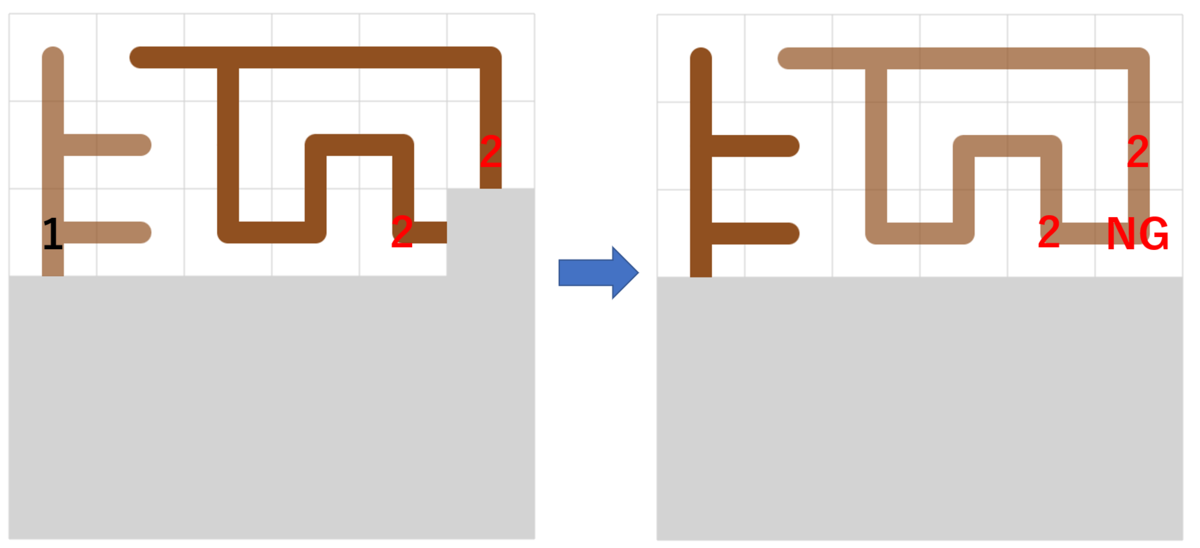
よく聞いてみると、スタートとゴールを途中でくっつけてしまっている場合があったらしく、じゃあスタートとゴールをくっつく場合はそれを回避するように貪欲を書けばいいんじゃないと言ってみる。なんかそれで上手く行きそうという話に。
もう残り時間もわずかで、なんか上手くいかない -> いやバグってた をしていて、冷や冷やしながら応援すると AC! (02:53:20)
ここから H を悪あがきで考えてみると、
今見ている walk が s-u-v-t となっていて、walk に含まれる辺を含まないような u-v walk があったとすると、
s-(今のwalkに含まれない u- v) - (今のwalk の v-u) - (今のwalkに含まれない u- v) - t
の順に繋ぎなおせばうまくいきそうという気になってくる。
O(M^2)だけどこれを実装したれ!と実装し始めるももちろん間に合わずに終了。
Hをヤケクソで実装している間、後の2人は阪神-中日戦を見ていました(阪神10-0中日)。
終わった後に20分追加で書いてみて、テストケース公開後に回してみるもどこかで無限ループが発生していましたとさ。おしまい。
まとめ
強豪チームはフルで参加していないチームも多そうでしたが、模擬国内で 2 位をとることができて嬉しかったです!
ICPCの参加資格を数年前に失っているのにチームバチャを謎にたくさんやっていた甲斐がありました!
各人の得意分野はかなりお互いに把握していて、しかも得意分野(やる分野)はほとんどかぶっていない
kopricky : データ構造、セグ木系、知識
pachicobue : 数学系、PEみたいのとか
mtsd : その他(二人が苦手な分野、パズル、ゲーム系、実装するだけをやらされる)
という感じなので、チームコンはやりたい問題だけできて楽しいです(幾何だけ醜い押し付け合いが始まります)。
いつまで OB が模擬国内に出ているんだという感じですが・・・
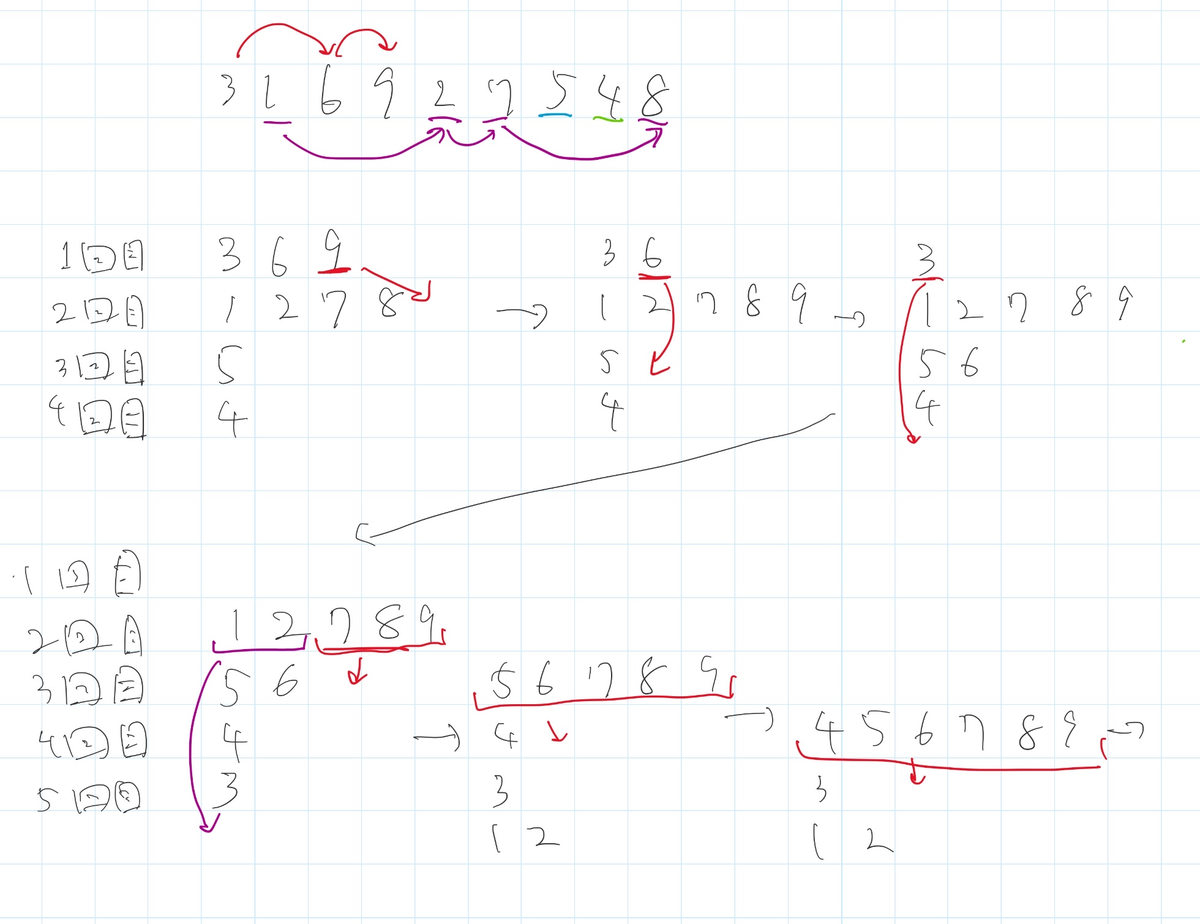
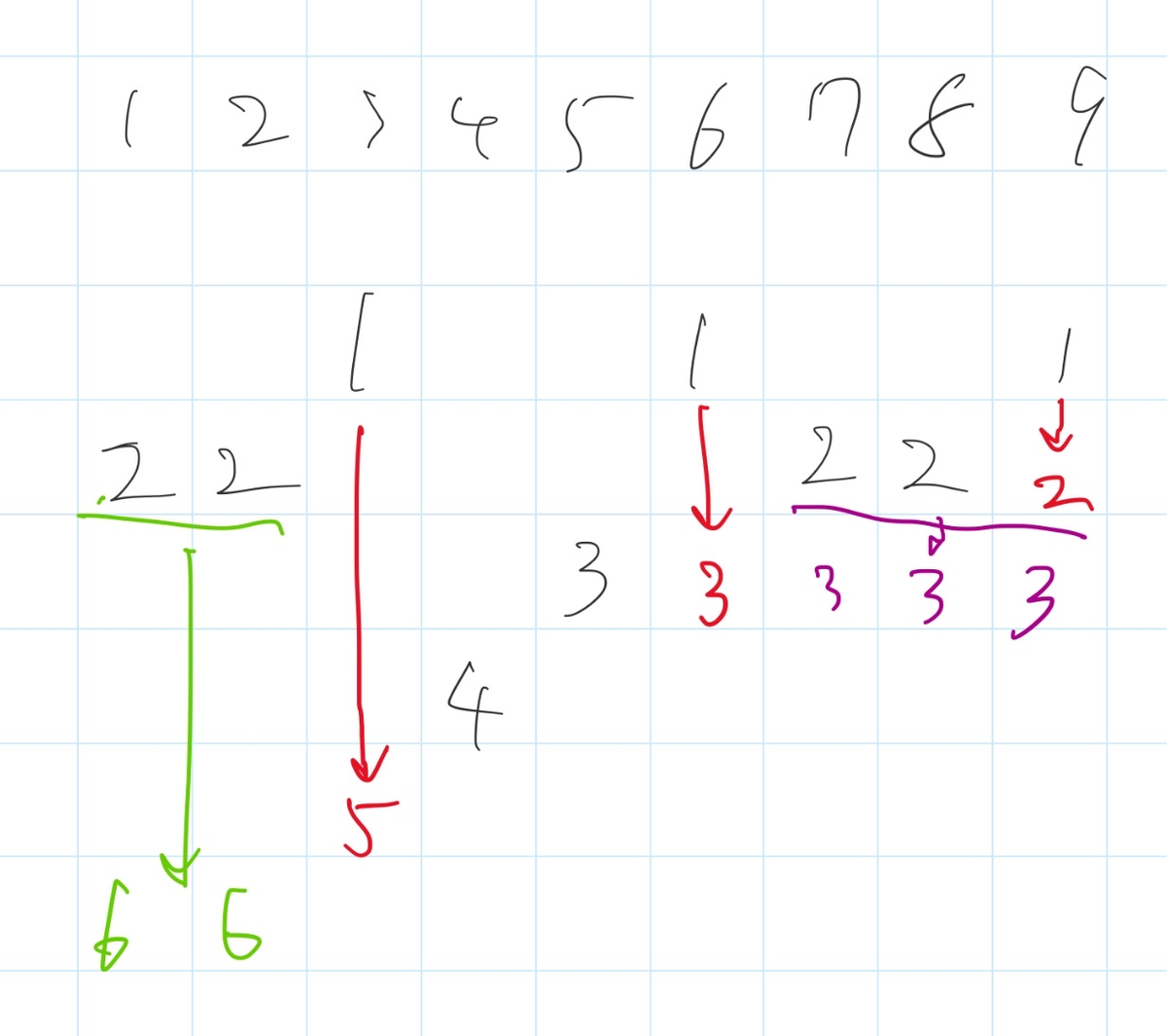
 AC!終わり!(平衡二分探索木がよく分からなくて、雑に二分探索で log を2個つけたら TLE したのはご愛嬌)
AC!終わり!(平衡二分探索木がよく分からなくて、雑に二分探索で log を2個つけたら TLE したのはご愛嬌)