前のブログエントリの続き:
引き続き、以下の資料を読んでいく。
- BlockからWarpへ
- GPUコア自体はSIMDパイプライン
- Streaming Processorが入っている
- SIMDプロセッサが大量に入っている (Streaming Multiprocessor: SM)
- BlockはWarpに分解される (SIMD/SIMTユニット:32スレッドのグループ)
- GPUコア自体はSIMDパイプライン

- WarpをベースとしたSIMDと、それまでのSIMDは何が違うのか?
- それまでのSIMDはシングルスレッドで動作している
- 命令はシーケンシャルに動作する
- プログラミングモデルがSIMD: ソフトウェアエンジニアはベクトル長について知る必要がある
- ISA自体に、ベクトル・SIMD命令が含まれている
- それまでのSIMDはシングルスレッドで動作している
- WarpをベースとしたSIMDでは、複数のスカラスレッドが含まれておりSIMDの形で実行される
- 各スレッドは独立に扱われる:プログラミングモデルはSIMDである
- ISA自体はスカラ命令
- 基本的には、SPMDのプログラミングモデルがSIMDハードウェアに実装されている
- SPMP: Single Procedure/Program, Multiple Data
- これはコンピュータ構成方法というよりも、プログラミングモデル
- 各プロセッシング・エレメントはデータが異なる、同じプログラムを実行する
- Prodedureはプログラム中の特定のポイントで同期することが可能である。
- 複数の命令ストリームが同じプログラムを実行する
- 各プログラム/Procedure が 1) 異なるデータを処理する 2) 異なる制御フローパスを実行することができる
- 多くの科学技術計算はこの方式でプログラミングされ、MIMDハードウェアで実行される
- 現代のGPUプログラムは同じような方法でプログラミングされ、SIMDハードウェアで実行される
SIMTの利点:
- 複数のスレッドを柔軟にグループ化することができる
- 例えば、真に同じ命令を実行すると想定されるスレッドをグループ化することができる → 動的にSIMD処理の利点を最大化することができる
WarpベースのSIMDにおいて、スレッドは異なるパスを実行することができる
- 各スレッドは条件付き制御フロー命令を含むことができる
- 各スレッドは異なる制御フローパスを実行することができる

- GPU/SIMT命令において、GPUは制御ロジックを削減するためにSIMDパイプラインを使用する
- Warp内のスレッドの分岐命令によって、分岐のダイバージェンスが発生し、異なる実行パスが発生する

多くのスレッドがある場合
- 同じPCの独立したスレッドを見つけることができる
- そして、それらをまとめて1つのWaprに動的に構成できる
- これにより「ダイバージェンス」の発生を抑え、SIMDの効率を向上させる
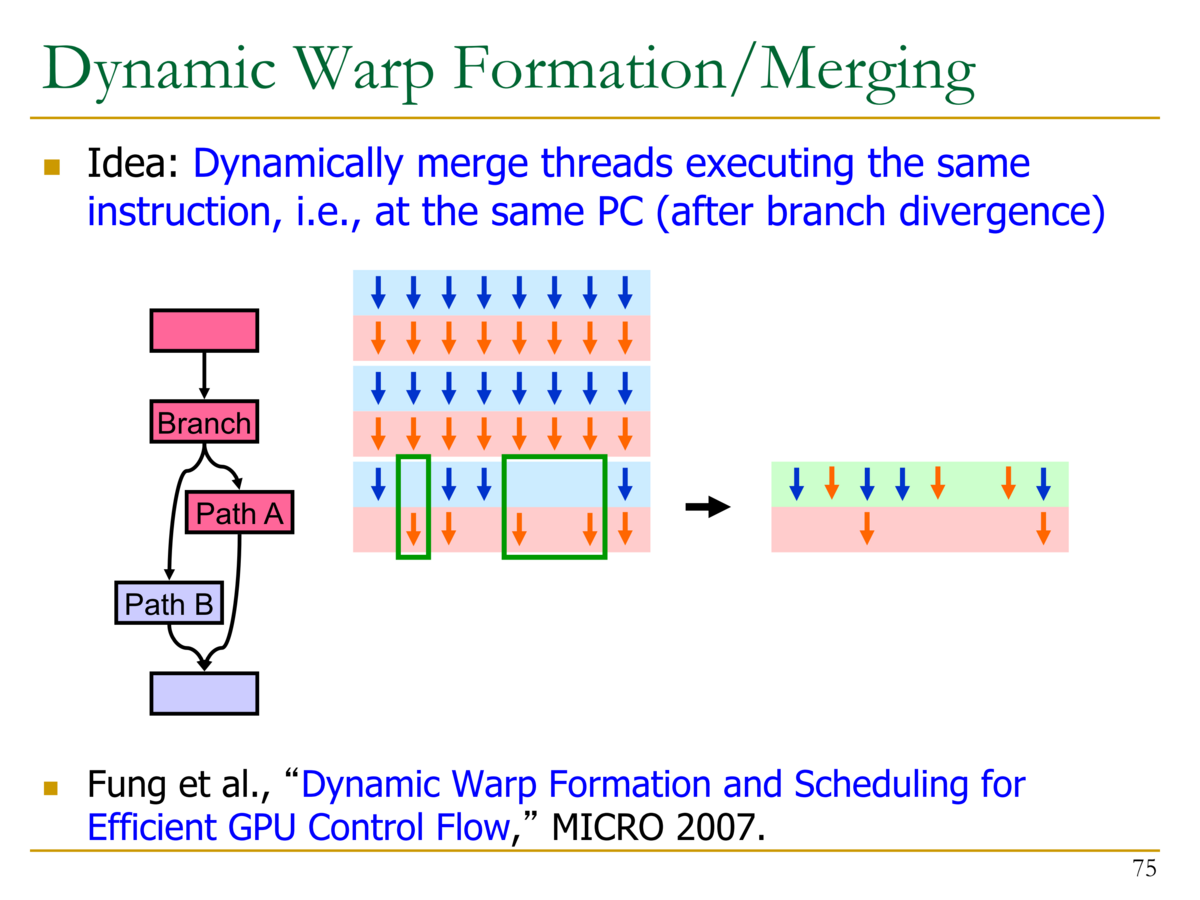
動的なWarpの構成・動的なWarpのマージ
- 同じ命令を実行しているスレッドをマージする (分岐のダイバージェンスが発生した後、同じPCを実行している命令)
- 待ち状態のスレッドから、新しいWarpを構成する