RISC-V のベクトル命令の仕様一覧のページ
サイクル精度シミュレータ Sniperの勉強
- AMBA CHIについての勉強
- オープンソース形式検証ツールSymbiYosysを用いて形式検証に入門する
- Vivado Simulatorを使ってUVMに入門する
- RISC-V IOMMU の構成についてマニュアルを読んでまとめる
XiangShanの実装しているaBTB (Ahead-BTB)について学ぶ
XiangShan の aBTB (Ahead-BTB) は、公開スライドを見る限り、BP1/S1 段に置かれた大容量の先行BTBである。BPU全体は3-stage prediction pipelineで構成される。
- BP1: uBTB + aBTB
- BP3: mBTB + RAS + TAGE + ITTAGE
が置かれている。つまり aBTB は、精密な最終判定器というより、フロントエンド初段で先読みして fetch を止めないための predictor である。
容量は 1K entries / 4-way と明示されている。

https://tutorial.xiangshan.cc/micro25/slides/Microarchitecture Design Philosophy.pdf
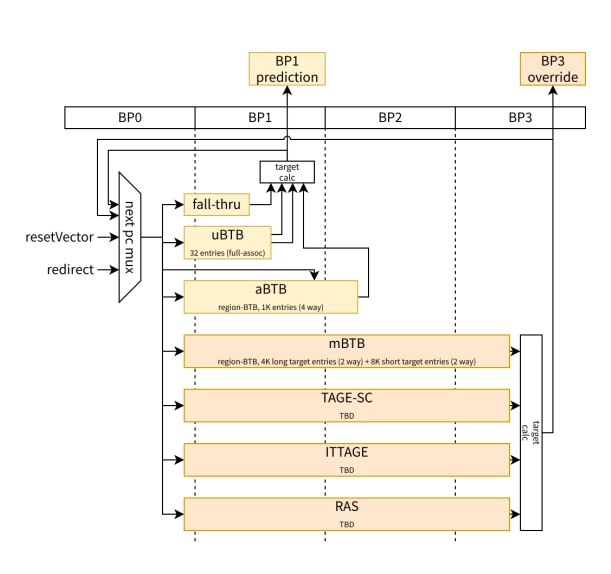
この構成から読めるのは、BP1 はレイテンシ最優先、BP3 は精度優先 という役割分担である。aBTB は BP1 側にいるので、「分岐を厳密に解く」より “次にどこを取りに行くべきかを先に出す” のが主目的となる。
1. uBTBとaBTBの違い
| Predictor | Index | Tag | 予測 |
|---|---|---|---|
| uBTB (left) | A | A | B |
| aBTB (right) | A | B | C |
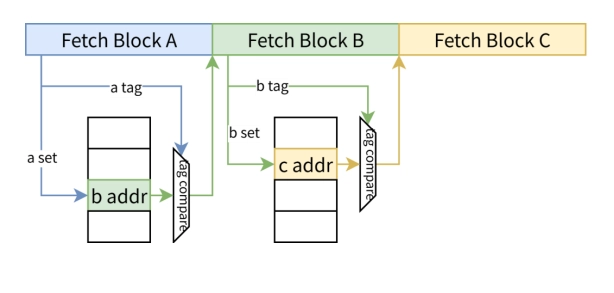
現在フェッチしている A で引く index = A tag = A pred = B A を見た瞬間に「A の中の最初の taken branch の飛び先は B」を返す
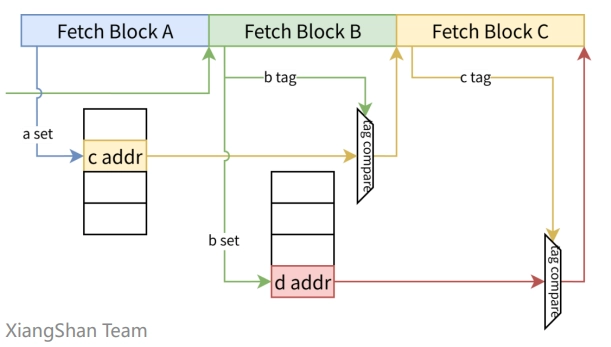
現在フェッチしている A で引く index = A ただし tag = B pred = C A の時点で「次に来るはずの B が正しいなら、 その次の有力候補は C」を返す
- uBTB: Fetch Block A を見て、A にある分岐を検出し、次の Fetch Block B を返す
- このブロックから次へ、という構造
- aBTB: 同じく A で引くが、照合対象は B 側に置き、さらに先の C を返す
- つまり aBTB は A→B→C という 1 段先行パイプライン を内部化した予測器となっている。
- このブロックから、次のブロックをカギにして、さらにその先へ (Aheadは、Tag=B / Prediction=C)となる。
2. なぜ Tag が B になるのか
通常のBTBなら、「今見ているブロックのPC」 で引いて、「そのブロック内の分岐ターゲット」 を返せばよい。ところが aBTB は 将来のフェッチブロック C を先に返したい。すると A だけでは情報が足りない。そこで、
- A を index に使って候補セットを引く
- その中で “本当に次が B か” を tag で確認する
- 一致したら C を prediction として出す
という構成になりなる。
+------------------------------+ | set/index key : A | | tag : B | | payload : C address | +------------------------------+
つまり aBTB は、単一ブロックに対するターゲット表 ではなく、フェッチブロック列 A→B→C の相関を圧縮して持つ表 となる。これは classic な ahead predictor の考え方そのものですが、XiangShan の公開資料ではそれを BP1 の S1 predictor として実用的に組み込んでいる。



