まえがき
皆さんは最近「夢」を見ていますか?
こんにちは、クラウド経費本部 プロダクト開発部 Guardianグループでリーダーをやりつつ、福岡TechPR(技術広報)でよろづやとして暗躍(?)している、@tosite(てっしー)と申します。
以前の記事で「RSpecとAIを組み合わせたパフォーマンスチューニングの自動化」について紹介しましたが、今回はその延長線上にある取り組みについてお話しします。
テーマは「AIに夢を見させる」です。「なんのこっちゃ」という感じだと思いますが、読み進めていただければきっと伝わるはずです!
- まえがき
- はじめに
- 全体アーキテクチャ
- Phase 1: AIによる一次分析
- Phase 2: 人間による調査・対応
- Phase 3: AIのセルフフィードバック
- Phase 4: 人間による学習承認
- Phase 5: コアメモリ更新
- 副次的に得られた効果: チーム全体の学習加速
- 設計上の工夫
- 現在の状況
- まとめ
はじめに
私たちGuardianグループでは、社内の問い合わせ対応業務にAI(Claude Code)を導入しています。
カスタマーサポートから届く技術的な問い合わせに対し、AIが一次分析を行い、対応方針・優先度・過去の類似事例を即座に提示するという仕組みです。
ところが、導入して気づいたことがあります。
「AIは間違える。そして、色んな間違いを何度も繰り返す」と。
プロンプトを手動で書き換えれば改善はできます。
ですが、それでは人間がボトルネックになってしまいます。問い合わせの傾向は日々変化し、プロダクトの仕様も更新されていく中で、プロンプトを手作業で追従させ続けるのは現実的ではありません。
では、どうするか?
私は社内の他の方とお話ししている中で「AIが夢を見ること」を思いつきました。
つまり「人間が夢の中で記憶を整理するが如く、AIが自分自身の出力をふりかえり、自律的に賢くなっていく仕組み」です。
チーム内での通称は「デンキヒツジ」。
由来はもちろんフィリップ・K・ディックの名作SF小説『アンドロイドは電気羊の夢を見るか?(Do Androids Dream of Electric Sheep?)』です。
人間が夜に夢を見て記憶を整理するように、AIも経験をふりかえり、重要なことだけを記憶に定着させ、不要な記憶は忘れていく。
では、私たちのAIは電気羊の夢を見るのでしょうか?
この記事では、その設計思想と実装について紹介します。

全体アーキテクチャ
フィードバックループの全体像
まずは全体像からご紹介します。以下の5つのフェーズでフィードバックループが回っています。
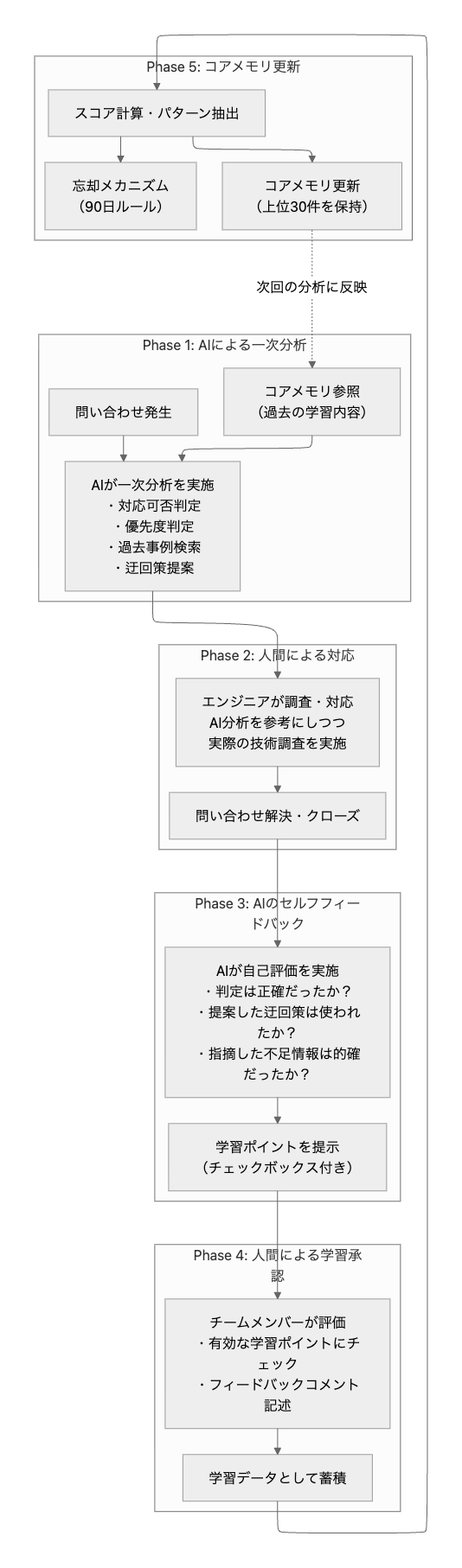
では、各フェーズを順番に見ていきましょう。
Phase 1: AIによる一次分析
問い合わせが発生すると、AIが即座に以下の分析を行います。
- 対応可否判定: 自チームで対応可能か、他チームへのエスカレーションが必要か
- 優先度判定: 影響範囲や再現性から優先度を決定
- 過去事例検索: 類似の問い合わせを自動検索し、関連度スコア付きで提示
- 迂回策提案: 根本対応を待たずに業務を継続できる方法を提案
- 不足情報の指摘: 調査に必要な追加情報を整理
ここでのポイントは、AIがコアメモリを参照していることです。
コアメモリには過去の学習で得られたパターン(例:「この種の問い合わせはDB確認を優先すべき」「この機能に関する問い合わせは仕様確認が先」など)が格納されており、AIはこれを踏まえた上で分析を行います。
Phase 2: 人間による調査・対応
AIの一次分析はあくまで「叩き台」です。
私たちGuardianがそれを参考にしながら、実際の技術調査と対応を行います。
AIの分析が的確であれば対応はスムーズに進みますし、的外れであれば無視して独自に調査します。
いずれの場合も、最終的には人間が責任を持って対応を完了させます。
この「AIは補助、人間が最終判断」という役割分担が、このシステムの大前提です。
Phase 3: AIのセルフフィードバック
問い合わせがクローズされると、AIが自分自身のレビューをふりかえるフェーズに入ります。
AIは以下の観点で自己評価を行います。
| 観点 | 評価内容 |
|---|---|
| 対応可否判定 | 「対応可能」と判定したが、実際はエスカレーションが必要だった → 不正確 |
| 迂回策 | 提案した迂回策が実際に採用された → 的確 |
| 不足情報 | 指摘した項目のうち半分しか実際には必要なかった → 過剰 |
そして、このふりかえりから「学習ポイント」を自動で抽出します。
学習ポイント(例): - [ ] この種のエラーはフロントエンドの問題ではなく、データ不整合が原因であることが多い - [ ] 設定変更後の不具合は、まずDB上の変更履歴を確認すべき - [ ] ファイルアップロードの問題は、拡張子だけでなくContent-Typeも確認が必要
各学習ポイントにはチェックボックスが付いています。これが次のフェーズで重要な意味を持ちます。
なお、このフェーズでは学習データの蓄積は行いません。学習として定着させるかは、次のPhase 4で人間が判断します。
Phase 4: 人間による学習承認
さて、ここがこのシステムの最も重要なフェーズです。
チームメンバーがAIのセルフフィードバックを読み、以下の2つのアクションを行います。
1. 学習ポイントの選別
AIが提示した学習ポイントの中から、実際に有効だと思うものにチェックを入れます。
- [x] この種のエラーはデータ不整合が原因であることが多い ← 有効! - [ ] 設定変更後の不具合はDB上の変更履歴を確認すべき ← すでに知っている / 的外れ - [x] ファイルアップロードはContent-Typeも確認が必要 ← 有効!
2. フリーテキストによるフィードバック
チェックだけでは伝えきれないニュアンスを、自由記述で補足します。
「AIの自己評価は概ね正確だった。ただし迂回策の評価が甘い。提案した方法は理論上は正しいが、実運用では使えないケースがある。」
このフィードバックはAIによって構造化データに変換され、学習データとして蓄積されます。
なぜ人間のゲートが必要なのか
AIが自分で「これは重要な学習だ」と判断して自動的に記憶に定着させることも、技術的には可能です。
ですが、私たちはあえて人間による承認ステップを設けました。理由は3つあります。
- AIの自己評価は完璧ではない: AIが「正確だった」と思っていても、実際には見当違いだったケースがある
- 文脈の欠落: AIはテキスト上のやり取りしか見ていないため、口頭での議論や暗黙知を反映できない
- 学習の質を保つ: ノイズの多い学習データが蓄積されると、かえって精度が下がる
AIが提案し、人間が承認する。この協調が、学習の質を担保する鍵です。
Phase 5: コアメモリ更新
蓄積された学習データは、定期的にコアメモリに統合されます。
スコアリングシステム
学習データはすべてスコアで管理されます。
| イベント | スコア変動 |
|---|---|
| 新規パターンの検出 | +5(初期値) |
| 人間が学習ポイントを承認 | +3 |
| 人間が学習ポイントを却下 | -1 |
| 人間からの改善提案 | +2 |
| AIの自己評価が正確だった | +2 |
| AIの自己評価が不正確だった | -2 |
| 90日間参照されなかった | -5 |
このスコアリングにより、本当に価値のある知識だけが生き残る仕組みになっています。
記憶の階層化
スコアに応じて、知識は3つの階層に分配されます。
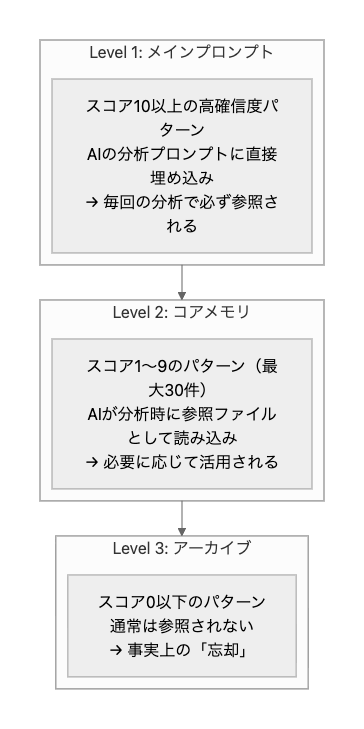
スコアが高い知識ほど、AIの判断に強く影響します。
十分に検証され、繰り返し有効性が確認されたパターンだけが「メインプロンプト」に昇格し、AIの基本的な判断基準の一部になります。
忘却メカニズム
90日間参照されなかったパターンは自動的にスコアが減衰します。これによって以下のメリットがあります。
- プロダクトの仕様変更で陳腐化した知識が自然に消えていく
- コアメモリが常に最新かつ関連性の高い知識で構成される
- 人間が手動でクリーンアップする必要がない
「覚えること」と同じくらい「忘れること」は重要です。
副次的に得られた効果: チーム全体の学習加速
このシステムには、当初想定していなかった嬉しい副次効果がありました。
Phase 4が「チーム学習の場」になった
学習承認のフェーズ(Phase 4)では、チームメンバー全員がAIのセルフフィードバックを確認し、「これは有効な学習か?」を判断します。
この作業を通じて、以下のことが自然に起きるようになりました。
- 問い合わせパターンの共有: 「このパターンの問い合わせについて、実はこう対応するのがベスト」という暗黙知が明示化される
- 判断基準の統一: 「この場合はエスカレーションすべき」「この場合は迂回策で十分」という判断基準がチーム内で揃っていく
- 新メンバーのキャッチアップ: 過去の学習データを読むだけで、頻出パターンと対応方針を短時間で把握できる
AIの学習を評価するという行為が、人間の学習にもなっています。これは嬉しい誤算でした。
設計上の工夫
1. GitHub Issueを学習データストアとして活用
本来であればRAGなどを使って知識を蓄積・検索できる仕組みにしたいところですが、インフラの構築コストがかかってしまいます。
まずはPoCとしてサクッと動くものを作りたかったので、学習データの蓄積先には専用のGitHub Issueを使うことにしました。
- バージョン管理: コメントの編集履歴が残る
- 検索性: GitHub上で全文検索できる
- 透明性: チーム全員がいつでも閲覧・監査できる
- 追加コスト0: 新たなインフラが不要
2. 冪等性の担保
コアメモリ更新処理は、処理済みのデータにマーカーを付与することで冪等性を担保しています。
同じコマンドを何度実行しても、すでに処理済みのデータは再処理されません。安全に繰り返し実行できます。
3. コアメモリの上限管理
コアメモリには最大30件の上限を設けています。
参照する知識が多すぎるとノイズになるため、スコアリングによる自然淘汰で本当に重要なパターンだけを残しています。
現在の状況
この仕組みは現在PoC段階で、チーム内で実際の問い合わせ対応に適用しながら検証を進めています。
手応えとしてはかなり良く、フィードバックループが回るたびにAIの分析が的確になっていく実感があります。
定量的な効果測定も含めて、引き続き検証を頑張っているところです。
まとめ
このシステムの本質は、単にAIを賢くすることではありません。
AIのセルフフィードバックを人間が評価するというプロセスは、AIの学習であると同時に、人間の学習でもあるのです。
AIが見落とした観点に人間が気づき、人間が言語化しきれなかったパターンをAIが抽出してくれます。
この相互作用が、チーム全体の対応力を底上げしています。
「夢」のメタファーで言えば、AIは毎晩の夢で経験を整理し、朝起きたら少しだけ賢くなっている。
そして、その夢の内容を人間が一緒にふりかえることで、人間も新しい気づきを得る。
プロンプトを一度書いて終わりにするのではなく、プロンプトが自律的に進化していく仕組みを作る。
これが、私たちが「AIに夢を見させる」と呼んでいるアプローチであり、「デンキヒツジ」の正体です。
私たちのAIが見ている電気羊の夢。
それは、昨日の問い合わせ対応をふりかえり、明日はもう少しうまくやろうとする、ささやかな自己改善の夢なのかもしれません。
今回の取り組みによってGuardianグループのCRE(Customer Reliability Engineering)業務がさらに進化するとともに、皆さまにとっても参考になれば幸いです。
