近年の深層学習の隆盛により、IEEE 754以外の数値表現の利用が広まっています。 そのような数値表現をまとめてみました。
深層学習で利用された数値表現の軽い歴史
機械学習には詳しくないので、エポックメイキングなイベントについて的を外しているかもしれません。
深層学習が(今回のブームで/社会的に)注目を集めることとなったきっかけとしては、2012年に畳み込みニューラルネットワークAlexNetがILSVRC2012で優勝したことを外すことはできないでしょう。 AlexNetはNVIDIA GTX 580 GPUを用いて学習されました[1][2]。 当時のGPUは単精度浮動小数点数(binary32)が高速であり、これを用いたと考えられます(GTX 580はbinary32の計算性能が約1.6 TFLOPSです)。
さて、単精度浮動小数点数は深層学習には過剰精度であり、より効率よく計算したいことから、低精度な浮動小数点数の利用が始まりました(当時の主流は畳み込みニューラルネットワークであり、メモリバンド幅の削減よりも計算性能向上が主要な効果だったと思います)。 2015年から2016年にかけて発売されたNVIDIAのGPU(TegraシリーズおよびPascal)は、IEEE 754-2008 で定義されたbinary16の演算を取り扱えるように*1なりました。 2017年に発売されたNVIDIAのGPU(Volta)は、binary16入力・binary32出力のテンソルコアを導入しました。 このころはIEEE 754-2008で定義済みだったbinary16をそのまま使っていたのですが、どうも深層学習には微妙に適さないということがわかってきたようです。
2018年、Googleはbfloat16を提案しました。 bfloat16は、binary32の仮数部の下16ビット削ったフォーマットで、binary32とおよそ同等のダイナミックレンジを持ちます。 bfloat16演算器が最初に搭載されたのはGoogle TPU v2ですが、bfloat16の採用は多くの計算機に広がりました。 また、「独自の数値表現フォーマットを使ってもよい」と後押しされたのか、企業・研究者問わず、新たな数値表現フォーマットの提案も活発になりました。 また、Transformerの隆盛により、計算性能だけでなくメモリバンド幅の制約も厳しくなり、FP8などの過激なフォーマットもどんどん提案されるようになってきています。
この記事では、そういった普通の浮動小数点数ではない数値表現フォーマットをまとめます。 以下、論文で一般に敬称をつけて書かないのと同様、敬称略です(そもそもなんていう敬称をつければいいのかよくわかりませんので。ジェンダー代名詞と同様の問題です)。
あくまで通常の浮動小数点数の範疇であるもの
bfloat16
bfloat16は、binary32の仮数部の下16ビット削ったフォーマットです。
つまり、符号部1 bit、指数部8 bit、仮数部7 bitのフォーマットであり、binary32とほぼ同じダイナミックレンジを持ちます。
正確には、binary32に備わっている非正規化数が存在しない(flush to zero丸めを行う)のでダイナミックレンジは違いますが、小さい方は乗算はもちろん加算でも利用価値が低いのでどうでもいいのでしょう。
この「広いダイナミックレンジを持つ」という特性が、binary16に欠けている、深層学習に重要な特性になっているようです。
bfloat16以降に提案された数値フォーマットについても、ダイナミックレンジをいかに確保するか、という部分が焦点になっています。
FP8(E4M3やE5M2)
FP8は、たった8 bitしかない、過激な浮動小数点数フォーマットです。 この辺になってくると、仮数部を1ビット削って指数部にもう1ビット与えるか、といったような細かい調整が死活問題になってくるようで、異なる二つのフォーマットが提案されています。 E4M3はその名の通り、符号部1 bitに加え、指数部4 bitと仮数部3 bitを持つフォーマットです。 E4M3は高精度であるため、重みの表現に適しているようです。 逆にE5M2は、符号部1 bitに加え、指数部5 bitと仮数部2 bitを持つフォーマットです。 E5M2はダイナミックレンジが広いため、勾配の表現に適しているようです。 ただし、FP8だけですべてを行うのはさすがに無理なようで、指数部/スケールの共有、積算器 (accumulator) に高精度の浮動小数点数型を用いる、などの工夫が必要となってくるようです。
FP8は、IEEEのWorking Group P3109が仕様の策定に向け頑張っているようです。 E4M3は、binary8p4、E5M2はbinary8p3と名付けられる予定とのことです。
精度可変型浮動小数点数(tapered floating point, TFP)
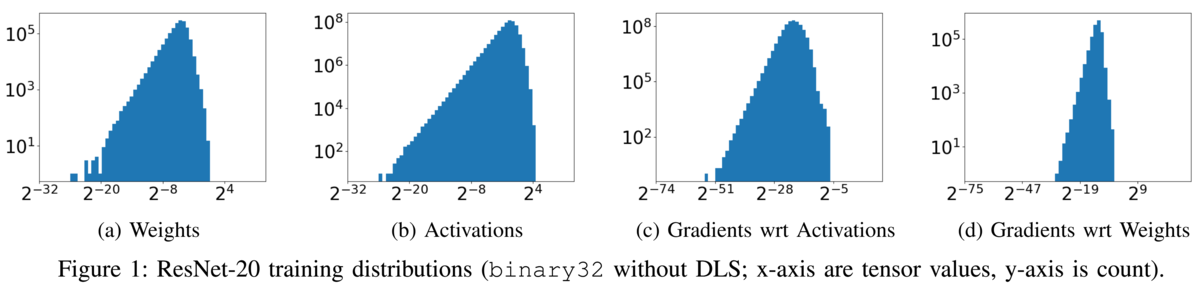
深層学習に出てくる値の分布を見てみると、絶対値が1周辺であることが圧倒的に多い一方、非常に絶対値の大きい/小さい値も無視できないほど出てくるという、冪分布になっているようです(図1)*2。 そこで、絶対値が1周辺の場合は仮数部を長くし、絶対値が1から離れるほど仮数部を短くする代わりに指数部を長くする、という方式が有効です。 このような不可逆圧縮(エントロピー符号化)の考え方を取り入れた方式は、典型的な値における精度とダイナミックレンジを両立することができます。 これがtapered floating pointの考え方です(taperedとは先細りになっていることを意味する単語で、絶対値が1から離れるほど精度が“先細りに”なることを意味していると思われます)。
TFPは非常に歴史のあるフォーマットです。 深層学習以前にも、特定の数値アルゴリズム分野で、有用性が指摘されてきました(特にGraeffeの求根アルゴリズムがよく出てきます。というかそれ以外に利用価値はあるんでしょうか)。 そのダイナミックレンジの広さにより、普通の浮動小数点数ではうまく動作しないものであっても、TFPであれば動作する、という数値アルゴリズムがあるようです。 深層学習用に提案されているTFPは複数あるようですが、TFPの歴史的貢献を無視している論文が多いように思われて残念です。
Robert MorrisのTapered Floating Point (1971)
Robert Morrisにより提案された、最初のTFPです(論文🔒)。 この論文では、符号部1 bit、指数部の符号部1 bit、指数部の長さ指定部3 bit(G=0~7)、指数部G+1 bit、仮数部30-G bit、というフォーマットを提案しています。 これは36ビットのフォーマットですが、時代的背景によるものです。 また、指数部の長さ指定部は4 bitにしてもいいかも、と書かれています。

図2はRobert MorrisのTFPのフォーマットの想像図です(具体的なビット位置は記載されていなかったので、適当に決めました)。 普通の浮動小数点数の指数部が固定長の整数であるのに対し、Robert MorrisのTFPは指数部の表現に(逆テーパーの)浮動小数点数を使っている、と言ってもよいでしょう。 ただし、Robert MorrisのTFPでは、指数部を表現する浮動小数点数の仮数部が、ケチ表現になっていません。 これが原因で、ビットパターンの約2/3しか有効利用されない問題があります(後で出てきます)。
松井正一と伊理正夫の方式 (1980)
松井正一と伊理正夫は、Robert MorrisのTFPを発展させ、64ビットでまで表現できるフォーマットを提案しています(論文)。
Robert MorrisのTFPは、指数部の長さ指定部が3 bitと決め打ちでしたが、これを十分長く(フォーマット長の対数に)取るという変更です。
実際には仮数部長をエンコードしているのですが、指数部長はそれと一対一に対応するため、同じことです。エンコードしているのは指数部長でした(2025/05/14 2:25修正)。

図3は松井正一と伊理正夫の方式のフォーマットです。 Robert MorrisのTFPと異なり、指数部にも仮数部にもケチ表現が使われています。 Bは0~57しか使われず、58~63が余っています。 松井正一と伊理正夫は、この使われていないビット表現を有効活用することにより、さらに大きな数を扱える可能性を提示しています。 TFPは指数部を浮動小数点数で表現する浮動小数点数(level 0 TFP)ですが、さらにこれを再帰的に適用したlevel 1 TFPなどを考える、というものです。
URR (1981~)
URRはUniversal Real number Representationの略だそうで、フォーマット長非依存な数値表現フォーマットです(論文1、1981年・論文2、1983年・英語論文🔒、1983年)。 上で見た二つの方式は、依然として決め打ちな部分があります。 つまり、Robert MorrisのTFPは指数部の長さ指定部が3 bitという決め打ちがあり、松井正一と伊理正夫の方式は64ビットフォーマットなら指数部の長さ指定部が6 bit、という決め打ちがあります。 これに対しURRは、指数部の長さ指定部の長さ自体がエンコーディングされるため、この種の決め打ちが一切ありません。 これにより、例えば123ビットフォーマットや19ビットフォーマットといった中途半端な長さのフォーマットも自然と定義できますし、それらの間の変換も、単に下位ビットを0で埋めたり下位ビットを切り落とすだけです(もちろん、オーバーフローやアンダーフロー、丸め等の処理は必要です)。

図4は、浜田穂積のURRのフォーマットです。 指数部長を符号付き一進エンコーディングしたLで表すのが特徴的です。 指数部の長さは、指数部長指定部の長さよりも3短いものとなります。 また、指数部が0または-1の場合は特殊なフォーマットが使われます(下段。後述)。
URRは数値表現フォーマットの“考え方”であるため、浜田穂積が1981年に提案して以来、種々の変形が提案されています。 そのような論文のうちの一つに、富松剛と金田康正 による「一般化した二重指数分割に基づく数値表現法」(報告、1995年・論文、1998年)があります。

図5は富松剛と金田康正のURRのフォーマットです。 まず、特殊なフォーマットを使う指数部範囲を-2~1に広げました。 また、そうでない部分では、次のフィールドを使います。
- 符号。1ビット
- 指数部長指定部。最低で3ビット。符号付き一進エンコーディングを行う
- 荒い指数部。2ビット固定(
)。底
と底4の間を埋めるのに使う
- 指数部。まず(指数部長指定部の長さ-3)×4の長さだけのビットで二進表現する。さらに荒い指数部の長さ分だけ(つまり0~3ビット)の二進表現が続く。さらに1ビット(
)、底4と底2の間を埋めるビットが続く
- 仮数部。残りのビットをフル活用する
荒い指数部が導入されたことが特徴的で、これにより指数部長指定部の長さを1/4にすることができています。 これは次の論文で定義される漸近的なエンコード効率γが4/5である表現に相当します(その論文では、binary32やbinary64並みの指数部を短くエンコードする場合、γ=4/5が最も良いだろうとしています)。
また、別のURRの変形を論じた論文に、須田礼二と小柳義夫による「新しい可変長指数部浮動小数点数表現形式の提案」(報告、1997年)があります。 この論文では、既存のURRには次のような問題点があることを指摘し、よりよいURRの方向性を提案しています。
- 指数部の変化に伴って仮数部長が2以上変化することが面倒な問題を引き起こす(数値計算でよく知られた誤差に関する議論が大きく毀損される)。指数部のエンコーディングを工夫し、これを回避すべきである
- 浜田穂積のURRで用いられている指数部長エンコーディング方法(ガンマ符号の亜種)は、最短指数部長は短いものの、指数部の漸近的なエンコード効率γが1/2であり、低い。最短指数部長を多少犠牲にしても、漸近的なエンコード効率γが2/3の「方式2」がよいのではないか
- 浜田穂積のURRは、指数部が0or-1の時に特殊なエンコーディングを使っている。そのような特殊なエンコーディングを使う範囲を広げれば、“実用的”な指数部範囲に対してより効率の良いエンコーディングは可能である(きれいではなくなる)
以下は、浜田穂積のURRが8ビットで表現できる値の一部です。 二の補数表現になっていることが特徴で、比較や符号反転を、符号付き整数と同じように行うことができます。 また、TFPは指数部を完全にエンコーディングすることを想定していたと思われますが、URRでは指数部を完全にはエンコーディングできない範囲でも何らかの値を表現することになります(以下の表の例では、端の方では指数部は4の倍数しかとれていません)。
| ビット表現 | 浜田穂積のURR | 備考/前の表現との間隔 |
|---|---|---|
| ... | ... | ... |
| 1 1111111 | -0.0 | 符号付き零 |
| 0 0000000 | 0.0 | 真の零 |
| 0 0000001 | +0.0 | 0.0と区別される符号付き零 |
| 0 0000010 | 1/65536 | 正の有限数の最小 |
| 0 0000011 | 1/4096 | ×16 |
| 0 0000100 | 1/256 | ×16 |
| 0 0000101 | 1/128 | ×2 |
| 0 0000101 | 1/64 | ×2 |
| 0 0000101 | 1/32 | ×2 |
| 0 0001000 | 1/16 | ×2 |
| 0 00010 01 | 1.25/16 | +0.25/16 (+1/64) |
| 0 00010 10 | 1.50/16 | +0.25/16 (+1/64) |
| 0 00010 11 | 1.75/16 | +0.25/16 (+1/64) |
| 0 00011 00 | 1/8 | +0.25/16 (+1/64) |
| 0 00011 01 | 1.25/8 | +0.25/8 (+1/32) |
| 0 00011 10 | 1.50/8 | +0.25/8 (+1/32) |
| 0 00011 11 | 1.75/8 | +0.25/8 (+1/32) |
| 0 001 0000 | 1/4 | +0.25/8 (+1/32) |
| 0 001 0001 | 1.0625/4 | +0.0625/4 (+1/64) |
| 0 001 0010 | 1.1250/4 | +0.0625/4 (+1/64) |
| ... | ... | ... |
| 0 001 1111 | 1.9375/4 | +0.0625/4 (+1/64) |
| 0 01 00000 | 1/2 | +0.0625/4 (+1/64) |
| 0 01 00001 | 1.03125/2 | +0.03125/2 (+1/64) |
| ... | ... | ... |
| 0 01 11111 | 1.96875/2 | +0.03125/2 (+1/64) |
| 0 10 00000 | 1 | +0.03125/2 (+1/64) |
| 0 10 00001 | 1.03125 | +0.03125 (+1/32) |
| ... | ... | ... |
| 0 10 11111 | 1.96875 | +0.03125 (+1/32) |
| 0 110 0000 | 1×2 | +0.03125 (+1/32) |
| 0 110 0001 | 1.0625×2 | +0.0625×2 (+1/8) |
| ... | ... | ... |
| 0 110 1111 | 1.9375×2 | +0.0625×2 (+1/8) |
| 0 11100 00 | 1×4 | +0.0625×2 (+1/8) |
| 0 11100 01 | 1.25×4 | +0.125×4 (+1) |
| ... | ... | ... |
| 0 1111101 | 4096 | ×16 |
| 0 1111110 | 65536 | ×16、最大の有限数 |
| 0 1111111 | +∞ | 正の無限大 |
| 1 0000000 | ∞ | 射影モードの無限大 |
| 1 0000001 | -∞ | 負の無限大 |
| 1 0000010 | -65536 | 最小の有限数 |
| ... | ... | ... |
この表を見ると、「指数部の変化に伴って仮数部長が2変化することがある」「指数部が0or-1の時に特殊なエンコーディングを使っている(指数部長が7 bit→5 bit→3 bit→2 bit、と変化していてイレギュラーになっている)」の二つが理解できると思います。 前の浮動小数点数との間隔が、1/64→1/32→1/64のように単調ではないことも読み取れます(よく知られた「浮動小数点数は、絶対値の小さい方から順に足すと丸め誤差が小さくなる(ことが多い)」というのが成り立たなくなります)。
須田礼二と小柳義夫によるURRは、指数部のエンコーディングを変更することによりこれらの問題を解決したものです。 まず、エンコーディング空間をどのように使用しているかを比較することにします。
浜田穂積のURRは、以下のようにビットパターンを割り当てています。
- 指数部が-1と0のもの(正負で合計4種)に各々1/8(合計1/2)
- 指数部が-2と1のもの(正負で合計4種)に各々1/16(合計1/4)
- 指数部が-4,-3,2,3のもの(正負で合計8種)に各々1/64(合計1/8)
- 指数部が-8~-5,4~7のもの(正負で合計16種)に各々1/256(合計1/16)
- 指数部が-16~-9,8~15のもの(正負で合計32種)に各々1/1024(合計1/32)
- 指数部が-32~-17,16~31のもの(正負で合計64種)に各々1/4096(合計1/64)
- ……
これに対して、須田礼二と小柳義夫による「方式1」URR(浜田穂積のURRと同じく指数部の漸近的なエンコード効率γが1/2)は、次のようにビットパターンを割り当てることで、「指数部の変化に伴う仮数部長の変化は高々1」という性質を満たすようになります。
- 指数部が-1と0のもの(正負で合計4種)に各々1/16(合計1/4)
- 指数部が-4,-3,-2,1,2,3のもの(正負で合計12種)に各々1/32(合計3/16)
- 指数部が-6,-5,4,5のもの(正負で合計8種)に各々1/64(合計1/8)
- 指数部が-8,-7,6,7のもの(正負で合計8種)に各々1/128(合計1/16)
- 指数部が-12~-9,8~11(正負で合計16種)に各々1/256(合計1/16)
- 指数部が-16~-13,12~15(正負で合計16種)に各々1/512(合計1/32)
- 指数部が-24~-17,16~23(正負で合計32種)に各々1/1024(合計1/32)
- 指数部が-32~-25,24~31(正負で合計32種)に各々1/2048(合計1/64)
つまり、指数部の長さが変わるポイントを、二冪だけでなくその1.5倍にも配置することで、問題を解決しています。
表にまとめて比較すると、以下のようになります。
| 指数部 | 種類数 | 浜田穂積のURR | 須田礼二と小柳義夫による「方式1」URR |
|---|---|---|---|
| -1と0 | 4種類 | 各々1/8を割り当て | 各々1/16を割り当て |
| -2と1 | 4種類 | 各々1/16を割り当て | 各々1/32を割り当て |
| -4,-3,2,3 | 8種類 | 各々1/64を割り当て | 各々1/32を割り当て |
| -6,-5,4,5 | 8種類 | 各々1/256を割り当て | 各々1/64を割り当て |
| -8,-7,6,7 | 8種類 | 各々1/256を割り当て | 各々1/128を割り当て |
| -12~-9,8~11 | 16種類 | 各々1/1024を割り当て | 各々1/256を割り当て |
| -16~-13,12~15 | 16種類 | 各々1/1024を割り当て | 各々1/512を割り当て |
| -24~-17,16~23 | 32種類 | 各々1/4096を割り当て | 各々1/1024を割り当て |
| -32~-25,24~31 | 32種類 | 各々1/4096を割り当て | 各々1/2048を割り当て |
須田礼二と小柳義夫による「方式2」URR(漸近的なエンコード効率γ=2/3)も考え方は同じです。指数部の長さが変わるポイントを、四冪の1.25倍・四冪の1.5倍・四冪の2倍、の3か所に配置することで、急激な仮数部長の変化が発生しないようになっています(切り替わりポイントが少し偏って配置されている気がしますが、エンコード空間を使い切る制約が厳しいのでしょう)。
須田礼二と小柳義夫によるURRが、具体的にどのような数値を表せるのかはわかりませんでした。 というのも、須田礼二と小柳義夫によるURRは、「終端部」のような特定のビットパターンが必要なため、フォーマットのビット数が少なく指数部を完全に表すのに必要なビット数に満たない場合に、どのように補えば正しく復元できるのかよくわからないのです。 これは、フォーマットのビット数が少なく指数部を完全に表すのに必要なビット数に満たない場合、指数部の下位ビットに0を補って考えればよかった浜田穂積のURRと対照的です。 また、指数部のエンコード方法は具体的に書かれていますが、その設計指針が「辞書式順序を放棄し、シフタ回路を減らすことを重要視した」としか書かれていないため、二つのビット表現が表す数値の間にどのような大小関係が成り立つのかも明らかではありません(グレイコードのような仕組みになっているように見えるので、うまくビットシャッフルした後にうまくXOR等すれば符号付き整数と同じ順序構造になるのでしょうが、よくわかりませんでした)。 なので、補った後の数値を想像することも困難です。 少なくとも、須田礼二と小柳義夫による「方式2」URRは、8ビットで以下の数を表せます。
- ±{1, 1.25, 1.5, 1.75}×{1/4, 1/2, 1, 2}(32種)
- ±{1, 1.5}×{1/16, 1/8, 4, 8}(16種)
- ±{1/256, 1/128, 1/64, 1/32, 16, 32, 64, 128}(16種)
8ビットで表せる数は256種類ありますが、指数部を完全に表すことのできる数値は64種しかないようです。 残りの192種類のエンコーディングは指数部を完全に表すことはできず、そのような場合にどのような値を表すと定義されるのかは不明です。 かなしいことに、上記64種は特殊なエンコーディングを使う範囲であり、漸近的挙動であるγ=2/3を確認することはできません。 もっとも、この論文の主題は具体的な数値フォーマットというよりは設計指針の修正の提案であり、かつ数値計算に適用することを主眼に置いており、短いデータ長ではTFPが良いとしているので、8ビットなどの極端なビット幅での利用は想定していないのでしょう。
柏木雅英は2016年に、浜田穂積のURRをベースに、指数部のエンコードを一部変更したものが半精度浮動小数点数フォーマットとして適しているのではないかと指摘しています(半精度浮動小数点数に関する思考実験 - kashiの日記)。 これはPosit(2017年)やbfloat16(2018年)よりも早く、深層学習にふさわしい短い数値フォーマットという文脈において、私が知る限り最も早い議論です。
指数部のエンコーディングは、デルタ符号と称していますが、有限の指数範囲を効率よくエンコードするためにアレンジが加えられているように思われます。 エンコード空間は以下のように使っているようです(省略されていて定かではありませんが、エンコード空間を使い切るにはこのようにするしかなさそうです)。
- 指数部が0のもの(正負で合計2種)に各々1/4(合計1/2)
- 指数部が±1のもの(正負で合計4種)に各々1/16(合計1/4)
- 指数部が±2, ±3のもの(正負で合計8種)に各々1/64(合計1/8)
- 指数部が±4~7のもの(正負で合計16種)に各々1/512(合計1/32)
- 指数部が±8~15のもの(正負で合計32種)に各々1/1024(合計1/32)
- 指数部が±16~31のもの(正負で合計64種)に各々1/2048(合計1/32)
- 指数部が±32~63のもの(正負で合計128種)に各々1/8192(合計1/64)?
- 指数部が±64~127のもの(正負で合計256種)に各々1/32768(合計1/128)
- 指数部が±128~255のもの(正負で合計512種)に各々1/65536(合計1/128)ただし指数部が254,-255,255のものはそれぞれ±0, ±Inf, NaNのビットパターンとする*3
このフォーマットのダイナミックレンジは~
と、bfloat16よりも広く、後述のLinear Takum並みです。
最短指数部長は1であり、その次の指数部長も3であるなど、浜田穂積のURRよりもさらに中心での精度に極振りしたエンコーディングになっています(二の補数ではなく符号と絶対値表現になっているのも一因でしょうか)。
指数部が
になったとたんに仮数部が一気に3ビットも削られるのは厳しそうに見えますが、図1を見れば指数部が
を超える値はほぼ出現しないようなので、悪くない選択なのかもしれません。
欲を言えば、指数部が-1のものを中心に置くべきだったかもしれません(きれいではないですが)。
Posit (2017)
John Leroy Gustafsonが(数値計算用に?)提案したType III Unumの別名です。 Positの論文はTFPの一連の研究の貢献を完全に無視しており、あたかも自分が発明したかのように書いているのが気に食わないです。 Positの論文ではRobert MorrisのTFPがビットパターンの約2/3しか有効利用できていない問題を揚げ足取りしていますが、後続のTFPでは解決していた問題であり、ビットパターンの有効利用を大々的に宣伝するのはおかしいでしょう。
Quireを用いれば無誤差で計算できる、というのもよくわからない主張です。 普通の浮動小数点数であってもQuire的な積算器を考えることは可能で、Positの利点とも思えません(Unumの浮動小数点数を置き換えるという思想の一環としては悪くないと思います)。 他の形式の積算器を併用しなければいけないという欠点のように思われます(FP8などにもあるので完全にダメと言うわけではありませんが)。
Quireの採用がハードウェア効率に与える影響は複雑です。 posit16に必要な256 bitのQuireはいかにも巨大に見えますが、意外にも、大きすぎると言い切れるほど大きくはありません。 256 bitの加算器は6000トランジスタほど*4、その前のシフタは4500トランジスタほど*5、と概算すると10500トランジスタほどです。 FP32積算をするとすると、仮に一回ごとに正規化するならば、桁合わせシフタが2000トランジスタほど、加算器が1000トランジスタほど、先行ゼロカウントが1000トランジスタほど、正規化シフタが2000トランジスタほど、指数部の計算に500トランジスタほど、丸めに500トランジスタくらい必要として、7000トランジスタほどになります。 Quire用にはcarry-saved adderが使える利点がある一方、FP32積算ではそのようなことができないのでパイプラインをうまく埋める命令列を実行しないといけないことを考えれば、意外にも馬鹿にできない作戦です。 しかしながら、テンソルコアのように8回とか16回とか32回とかの乗算を全部足したものを最後に正規化する、という場合は正規化のコストが1/8~1/32になります。 そうすると乗算一回に必要なコストは実質3000~3500トランジスタとなり、それより3倍大きなQuireの採用には疑問符が付きます。 また256 bitの積算結果をどこに保存するかも問題となり、いちいち保存する場合はデータ幅が大きいことが問題となり、一気に積算する場合は行列乗算の入力オペランドの再利用性が使えないことが問題になります。
一方で、PositがURRより深層学習や実際的な数値計算に向いているという点は同意せざるをえないでしょう。
URRは二重指数分割を用いるため、のようなあり得ないほど大きい値を表現できますが、一方でそのような値はほぼ使われません。
そのような大きな数を表現できることの代償は、1から離れると精度が急激に低下することです。
一方でPositは、1から離れたときの精度低下が比較的小さくなるように設計されています*6。
Positが深層学習でよい性能を示すのは、深層学習においてはbinary32やbfloat16で表現できる程度のダイナミックレンジがあれば十分だということが原因でしょう。
Positは指数部幅esというパラメータを持ちますが、以下ではPosit Standard (2022)に従い、これが2の場合を取り扱います。
符号部1 bit、regime部可変長(符号付き一進エンコーディング)、指数部es=2 bit、残りのビットは仮数部、というフォーマットです。
regime部が一進エンコーディングで16()の指数を荒く表し、指数部が残りを2の指数として正確に表し、残りは仮数部となります。

図6は、Positのフォーマットです。 Robert MorrisのTFPと比べると、指数部のエンコーディング、もっと言うと伸び縮みする部分が変わっています。 これをまとめると以下のようになります。
| Robert MorrisのTFP | Posit | |
|---|---|---|
| 第一指数部の幅 | 3 bit決め打ち | 一進エンコーディングによる可変長 |
| 第一指数部の表現 | 二進数 | 一進数 |
| 第二指数部の幅 | 第一指数部により決定される可変長 (第一指数部は二重指数) |
2bit決め打ち (第一指数部は一重指数) |
| 第二指数部の表現 | 二進数 | 二進数 |
ややわき道にそれますが、Robert MorrisのTFPは「指数部が浮動小数点数になっている浮動小数点数」である、と解釈したことになぞられると、富松剛と金田康正のURRを「指数部がPositになっている浮動小数点数」と解釈できる点は興味深いです(es=2なのは偶然でしょうか)。 Robert MorrisのTFPはGという固定長の二重指数指示部を持ちます。 富松剛と金田康正のURRに出てきた「荒い指数部」も固定長の二重指数指示部であり、似ています。 これらはそれぞれ浮動小数点数とPositの指数部エンコードフィールドに由来するものになっています。 浮動小数点数の指数部に浮動小数点数やPositを入れたため、その指数部は二重指数指示部になるのです。
さて、Positのダイナミックレンジは、第一指数部が一進数という非効率な方法でエンコーディングされているため、これまでに挙げたどのTFPよりも狭いものとなります。
Positは、浜田穂積のURRと同じく、下位ビットに0を補ったり下位ビットを切り捨てることによりフォーマット長を変換することができます。 この意味では"Universal"と呼ぶに相応しいフォーマットです。 しかし、フォーマット長が伸びるにつれ、一進エンコーディングの非効率性が顕在化します。 その場合にesを変えるというのであれば、Universalと言うことはできないでしょう。 どちらを妥協するべきかは標準化する際にけっこう問題になったようですが、現在の標準ではフォーマット長によらずes=2を使うという決断のようです。
Linear Takum (2024)
Linear TakumはLaslo Hunholdが提案した数値フォーマットです(論文のarXiv版・論文🔒)。 PositはRobert MorrisのTFPに立ち返ったに過ぎずそれより良い数値フォーマットを提案する……という触れ込みですが、どう見てもLinear Takumの方がRobert MorrisのTFPに似ているようにしか見えません。 一応、エンコーディングを頑張って、浜田穂積のURRやPositと同様に単調性を持つ(順序構造が符号付き整数と同じになる)ようになっているようです。 しかし、指数部の長さ指定部が3 bitである点など、Robert MorrisのTFPと本質的に同じ発想(ダイナミックレンジ・効率性)だと思います。
8bitのLinear Takumで表現できる数値の一部を表にまとめてみました。 エンコーディングがかなり込み入っているので、解釈に必要な中間変数cも書いています。
| ビット表現 | c | Linear Takum | 備考/前の表現との間隔 |
|---|---|---|---|
| 0 0 000 000 | × | 0 | Takumに零は一つ |
| 0 0 000 001 | -255 | 最小の正の数 | |
| 0 0 000 010 | -239 | ||
| 0 0 000 011 | -223 | ||
| 0 0 000 100 | -207 | ||
| 0 0 000 101 | -191 | ||
| 0 0 000 110 | -175 | ||
| 0 0 000 111 | -159 | ||
| 0 0 000 111 | -143 | ||
| 0 0 001 000 | -127 | ||
| 0 0 001 001 | -119 | ||
| ... | ... | ... | |
| 0 0 001 111 | -71 | ||
| 0 0 010 000 | -63 | ||
| 0 0 010 001 | -59 | ||
| ... | ... | ... | |
| 0 0 010 111 | -35 | ||
| 0 0 011 000 | -31 | ||
| 0 0 011 001 | -29 | ||
| ... | ... | ... | |
| 0 0 011 110 | -19 | ||
| 0 0 011 111 | -17 | ||
| 0 0 100 000 | -15 | ||
| 0 0 100 001 | -14 | ×2 | |
| ... | ... | ... | ... |
| 0 0 100 110 | -9 | ×2 | |
| 0 0 100 111 | -8 | ×2 | |
| 0 0 101 00 0 | -7 | ×2 | |
| 0 0 101 00 1 | -7 | 1.5/128 | +0.5/128 (+1/256) |
| 0 0 101 01 0 | -6 | 1/64 | +0.5/128 (+1/256) |
| 0 0 101 01 1 | -6 | 1.5/64 | +0.5/64 (+1/128) |
| 0 0 101 10 0 | -5 | 1/32 | +0.5/64 (+1/128) |
| 0 0 101 10 1 | -5 | 1.5/32 | +0.5/32 (+1/64) |
| 0 0 101 11 0 | -4 | 1/16 | +0.5/32 (+1/64) |
| 0 0 101 11 1 | -4 | 1.5/16 | +0.5/16 (+1/32) |
| 0 0 110 0 00 | -3 | 1/8 | +0.5/16 (+1/32) |
| 0 0 110 0 01 | -3 | 1.25/8 | +0.25/8 (+1/32) |
| 0 0 110 0 10 | -3 | 1.5/8 | +0.25/8 (+1/32) |
| 0 0 110 0 11 | -3 | 1.75/8 | +0.25/8 (+1/32) |
| 0 0 110 1 00 | -2 | 1/4 | +0.25/8 (+1/32) |
| 0 0 110 1 01 | -2 | 1.25/4 | +0.25/4 (+1/16) |
| 0 0 110 1 10 | -2 | 1.5/4 | +0.25/4 (+1/16) |
| 0 0 110 1 11 | -2 | 1.75/4 | +0.25/4 (+1/16) |
| 0 0 111 000 | -1 | 1/2 | +0.25/4 (+1/16) |
| 0 0 111 001 | -1 | 1.125/2 | +0.125/2 (+1/16) |
| 0 0 111 010 | -1 | 1.25/2 | +0.125/2 (+1/16) |
| 0 0 111 011 | -1 | 1.375/2 | +0.125/2 (+1/16) |
| 0 0 111 100 | -1 | 1.5/2 | +0.125/2 (+1/16) |
| 0 0 111 101 | -1 | 1.625/2 | +0.125/2 (+1/16) |
| 0 0 111 110 | -1 | 1.75/2 | +0.125/2 (+1/16) |
| 0 0 111 111 | -1 | 1.875/2 | +0.125/2 (+1/16) |
| 0 1 000 000 | 0 | 1 | +0.125/2 (+1/16) |
| 0 1 000 001 | 0 | 1.125 | +0.125 (+1/8) |
| 0 1 000 010 | 0 | 1.25 | +0.125 (+1/8) |
| 0 1 000 011 | 0 | 1.375 | +0.125 (+1/8) |
| 0 1 000 100 | 0 | 1.5 | +0.125 (+1/8) |
| 0 1 000 101 | 0 | 1.625 | +0.125 (+1/8) |
| 0 1 000 110 | 0 | 1.75 | +0.125 (+1/8) |
| 0 1 000 111 | 0 | 1.875 | +0.125 (+1/8) |
| 0 1 001 0 00 | 1 | 2 | +0.125 (+1/8) |
| 0 1 001 0 01 | 1 | 1.25×2 | +0.25×2 (+1/2) |
| 0 1 001 0 10 | 1 | 1.5×2 | +0.25×2 (+1/2) |
| 0 1 001 0 11 | 1 | 1.75×2 | +0.25×2 (+1/2) |
| 0 1 001 1 00 | 2 | 1×4 | +0.25×2 (+1/2) |
| 0 1 001 1 01 | 2 | 1.25×4 | +0.25×4 (+1) |
| 0 1 001 1 10 | 2 | 1.5×4 | +0.25×4 (+1) |
| 0 1 001 1 11 | 2 | 1.75×4 | +0.25×4 (+1) |
| 0 1 010 00 0 | 3 | 1×8 | +0.25×4 (+1) |
| 0 1 010 00 1 | 3 | 1.5×8 | +0.5×8 (+4) |
| 0 1 010 01 0 | 4 | 1×16 | +0.5×8 (+4) |
| 0 1 010 01 1 | 4 | 1.5×16 | +0.5×16 (+8) |
| 0 1 010 10 0 | 5 | 1×32 | +0.5×16 (+8) |
| 0 1 010 10 1 | 5 | 1.5×32 | +0.5×32 (+16) |
| 0 1 010 11 0 | 6 | 1×64 | +0.5×32 (+16) |
| 0 1 010 11 1 | 6 | 1.5×64 | +0.5×64 (+32) |
| 0 1 011 000 | 7 | +0.5×64 (+32) | |
| 0 1 011 001 | 8 | ×2 | |
| 0 1 011 010 | 9 | ×2 | |
| ... | ... | ... | ... |
| 0 1 011 111 | 14 | ×2 | |
| 0 1 011 000 | 15 | ×2 | |
| 0 1 100 001 | 17 | ||
| ... | ... | ... | ... |
| 0 1 100 111 | 29 | ||
| 0 1 101 000 | 31 | ||
| 0 1 101 001 | 35 | ||
| ... | ... | ... | ... |
| 0 1 111 111 | 239 | ||
| 0 1 111 111 | 255 | ||
| 1 0 000 000 | × | NaR | Positと同様の非実数。一つだけ |
| 1 0 000 001 | -255 | 絶対値が最大の負の数 | |
| ... | ... | ... | ... |
Linear Takumは指数部の幅指定部が3 bitという「決め打ち」の定数があるのが美しくないですが、指数部の幅指定部を2 bitにしてしまうとダイナミックレンジが狭すぎですし、逆に指数部の幅指定部を4 bitにしたときのダイナミックレンジは広すぎです。 ただし、指数部が±255までというのがやや狭いと感じれば、ほぼ使われない数値表現が出てしまうことを覚悟で、指数部の幅指定部を4 bitにするのは悪くない決断かもしれません(特に64 bitの場合。32 bitもそうかもしれません)。 それでも、指数部の幅指定部を3 bitにするのは良い決断であると考えられ、少なくともPositのesのような取って付けた「決め打ち」定数よりは美しいと言えるでしょう。 しかしながら、これらの議論は全て、Robert Morrisが1971年に行ったことなのです。
Linear Takumはハードウェア実装も容易なようです。 それもそのはずで、可変長エンコーディングになっている部分の長さが具体的に二進数でエンコードされており、シフタ回路にほぼそのまま入力できるからです。 一方で、浜田穂積のURRで使われるガンマ符号やPositで使われる一進エンコーディングは、そのエンコーディング内に長さが埋め込まれており、シフトするにはまずデコードを行う必要があります。
さて、Linear Takumは単調性(順序構造が符号付き整数と同じ)を良い特性として持ちますが、果たして、比較はそんなに出現する操作なのでしょうか? 数値計算においては、比較なんかよりも、圧倒的に多くの演算を行うはずです。 ここは須田礼二と小柳義夫が指摘したように、固定長部分(符号部と指数部の符号部と指数部の幅指定部)ー仮数部ー指数部、の順番でエンコードすることで、シフタ回路を減らせるという特性を選ぶべきだったのではないでしょうか。 これにより、電力効率の向上や回路面積の削減が期待できそうです(FPGA実装ではそれを評価することは困難そうで、かといって実際に回路設計を行うのはかなり大変そうですが……)。
対数表現を用いるもの
logarithmic number system (LNS)
LNSは、数値を、その符号
とその対数
で表現します。
浮動小数点数は、符号部に加え、整数で表現される指数部と仮数部を持ち、
のような数値を表現できます。
これに対してLNSは、符号部に加え、固定小数点数で表現される指数部のみを持ち、
のような数値を表現できます。
二進浮動小数点数は相対精度が一様ではなく、指数部が変わる部分で相対精度が約二倍変化します。
それに対して、LNSはどこでも相対精度が一定という特徴を持ちます。
仮数部が3 bitの浮動小数点数とLNSが表現できる値の一部を比較してみます。
| ビット表現 | 浮動小数点数(E4M3) | LNS(一例) |
|---|---|---|
| ... | ... | ... |
| 0 0111 000 | 1.000 | 1.000 |
| 0 0111 001 | 1.125 | 1.091 |
| 0 0111 010 | 1.250 | 1.189 |
| 0 0111 011 | 1.375 | 1.297 |
| 0 0111 100 | 1.500 | 1.414 |
| 0 0111 101 | 1.625 | 1.542 |
| 0 0111 110 | 1.750 | 1.681 |
| 0 0111 111 | 1.875 | 1.834 |
| 0 1000 000 | 2.000 | 2.000 |
| 0 1000 001 | 2.250 | 2.182 |
| 0 1000 010 | 2.500 | 2.378 |
| ... | ... | ... |
LNSの利点として、乗算が簡単にできるというものがあります。
数値が対数で表現されているため、乗算は加算器回路で実現できます。
浮動小数点数の乗算は、仮数部のビット幅に対して
の量のトランジスタを使う方式が普通であるのに対し、加算器回路は
~
の量のトランジスタで作れるため、大幅な回路規模削減となります。
一方で加減算が難しくなり、テーブル引きに頼るしかなくなるようです。
LNSはGRAPE-5でも使われたことのある、由緒正しい数値表現フォーマットですが、普及はなかなか進んでいません。 精度を上げようとすると加減算に必要なテーブルサイズが巨大になり、逆に精度が低い場合は普通に作っても乗算回路が小さいため、スイートスポットである精度範囲があまり広くないことによるものと思われます。
Takum (2024)
TakumはLaslo Hunholdが提案した数値フォーマットで、taperedの考え方をLNSに導入した、珍しいフォーマットです(論文のarXiv版・論文🔒)。
Linear Takumよりもこちらの方が本命のようです。
エンコーディングが工夫されているのが生きていて、全ビット反転する(一の補数を取る)とが
になる性質があるのはおもしろいです。
しかしながら、底が
のLNSであること以外は、Robert MorrisのTFPの焼き直しと言わざるをえません。
まとめ
近年の深層学習の隆盛により、IEEE 754以外の数値表現が注目を集めています。 まずは有名どころとして、bfloat16、FP8などのIEEE 754形式のパラメータだけを変えた数値表現を紹介しました。 その後、歴史あるtapered floating point(URRを含む)について紹介しました。 Robert MorrisのTFPは指数部が浮動小数点数になっており、同様に考えるとURRから指数部を取り出したものがPositであると解釈できることを指摘しました。 つづいて、近年もてはやされているPositは非効率であり、また、ごく最近に提案されたTakumは50年以上前に提案されたものとほぼ同じであることを指摘しました。 また、Takumには、昔に指摘された回路効率化技法が同様に適用できるのではないかと指摘しました。 最後に、logarithmic number systemを紹介しました。
以下に、掲載した二進系数値フォーマットの特性をまとめた表を掲載して終わりにします。
| 分類 | 効率 γ |
長さ 非依存 |
決め打ち 定数無し |
単調性および 仮数部位置が固定 |
指数部差1で仮数 部長差が1以内 |
|
|---|---|---|---|---|---|---|
| 符号付き整数 | 固定長整数 | N/A | 〇 | 〇 | 単調かつ 仮数部位置が固定 |
〇 |
| 普通のFP | 指数長固定FP | N/A | × | × | 仮数部位置が固定 | 〇 |
| Robert MorrisのTFP | 有限範囲 指数長可変FP |
1 | 〇 | △g=3 | 不明 単調ではなさそう |
〇 |
| 松井・伊理の方式 | 無限範囲 指数長可変FP |
1 | × | 〇 | 仮数部位置が固定 | 〇 |
| 浜田のURR | (無限範囲)URR | 1/2 | 〇 | 〇 | 単調 | × |
| 富松・金田のURR | (無限範囲)URR | 4/5 | 〇 | △ p=4,q=16 |
単調 | × |
| 須田・小柳の方式1 | (無限範囲)URR | 1/2 | 〇 | 〇 | 仮数部位置が固定 | 〇 |
| 須田・小柳の方式2 | (無限範囲)URR | 2/3 | 〇 | △四進 | 仮数部位置が固定 | 〇 |
| 標準Posit | 無限範囲 指数長可変FP |
0 | 〇 | ×es=2 | 単調 | 〇 |
| Linear Takum | 有限範囲 指数長可変FP |
1 | 〇 | △R長=3 | 単調 | 〇 |
何も考えずに作ると単調にも仮数部位置固定にもならないと思うのですが、Robert MorrisのTFPを除いて、どれもどちらか一方は満たしているんですね(可変長の指数部がある場合、両方を満たすのは無理なので、これは最良です)。
参考文献
[1] ImageNet Large Scale Visual Recognition Competition 2012 (ILSVRC2012) "It was trained on two NVIDIA GPUs for about a week. To make training faster, we used non-saturating neurons and a very efficient GPU implementation of convolutional nets."
[2] NVIDIA CEO が予測する、AI 活用の産業革命 - NVIDIA | Japan Blog「2 台の NVIDIA GTX 580 GPU を使ってわずか数日間のトレーニングを行っただけの「AlexNet」が、何十年にもわたって磨き上げられてきた人間の専門家のアルゴリズムをすべて打ち負かし、その年の ImageNet 大会で優勝しました。」
AIの利用について
ChatGPTを用いて以下の疑問を解決しました。本記事には、それ以外のAI利用はありません。本記事の内容は、すべて私の責任の下に納得・裏取りして書かれたものです。
- AlexNetは人類に勝った最初のGPU利用深層畳み込みニューラルネットワークではないのに、なぜ転換点の象徴となっているのか――大規模データセット・大会の注目度・GPU実装の公開
*1:昔からGPUはFP16をデータ転送量削減のために使っていましたが、演算はできませんでした。
*2:本当に?絶対値が小さい方は単に一様分布では?
*3:+254を±無限大、-255のものを±0、としたほうが大小関係が一貫する気がしますが……。
*5:0が入ってくるシフトは255か所×NANDゲート4トランジスタ、選択するシフトは22+23+25+29+37+53+85+128=402か所×OAIゲート8トランジスタ、選択信号のバッファはFO4でやるとして657か所×0.67トランジスタ
*6:分布の尖度が低く設計されています。逆に言えば裾はすぐになくなるということで、1からかなり離れたところでの精度低下はURRと比べて激しいものとなります
