
VoiceflowのAPL for Audioのβテストが始まりました!待ちに待っていた機能なのでとても楽しみにしていました!ということで、早速レポート!
VoiceflowのAPL for Audioはまだβテスト中です。正式リリース時には変更されている可能性があります。ご注意ください。
VoiceflowのDirective Stepが2021/2/10に正式にリリースされました。ということで、APL for Audioも使えます(ただしAPL for Audio自体がAmazonではまだβですが)
目次
APL for Audioとは?
APL for Audioをご存じない方もいらっしゃると思うので、Alexaスキルでのオーディオ再生について簡単に説明します。そのあと、APL for Audioが加わったことで何がよいのか?をまとめます。
オーディオの基本はわかっている、手っ取り早くAPL for Audioの話が知りたい、という方は、Directive Blockまでスキップしてください。
Alexaスキルでのオーディオ再生
Alexaスキルでオーディオを再生させたい場合、方法は2つあります。
- SSMLを使う
- AudioPlayerを使う
AudioPlayerはちょっと使い方が変わるので詳細は割愛します。
SSMLを使う
SSML(Speech Synthesis Markup Language)とは、「音声合成マークアップ言語」と呼ばれるもので、通常はAlexaの発話を制御するために使用されます。例えば、Alexaの公式ドキュメントで紹介されている以下のSSMLをAlexa開発者コンソールのテストシミュレータで再生してみましょう。
<speak>
最初の文は通常の音量です。
<prosody volume="x-loud">2つめの文はより大きい音量です</prosody>。
起きたときは <prosody rate="x-slow">とてもゆっくり話します</prosody>。
普通の高さで話すこともできますが、
<prosody pitch="x-high"> もっと高い声で話すこともできますし</prosody>、
<prosody pitch="low">低い声も出せます</prosody>。
</speak>
どのスキルでも良いので選択して、テストシミュレータを開いて以下の通りテストシミュレータのタブで「音声と語調」をクリック、上記のSSMLをマルっと上書き、言語に「日本語」を選択して、再生ボタンを押します。

再生してみるとこんな感じです。
発話の前後にあるタグの指定の仕方で、Alexaの発話のスピードや声の高さなどが変わるのがわかりましたよね。
そして、SSMLにはAudioタグというものがあり、これを使うとオーディオの再生ができます。
<speak>
それでは第一問。<audio src="https://example.com/question.mp3"/>
この鳴き声はなんの鳴き声でしょうか?<audio src="https://example.com/lion.mp3" />
回答時間は30秒。どうぞ。
<audio src="soundbank://soundlibrary/ui/gameshow/amzn_ui_sfx_gameshow_countdown_loop_32s_full_01" />
</speak>
※一部URLを伏せています。
同じようにテストシミュレータで再生してみるとこんな感じになります。
※効果音ラボ様の効果音を使用させていただきました。
こういった感じで、Alexaの発話の合間に効果音やサウンド的なものを差し込めるのですね。スキルをにぎやかで楽しいものにするには必須のテクニックですね!
Voiceflowでやる場合はSpeak Blockを使います。

オーディオはmp3ファイルをドラッグ&ドロップでアップロードするだけです。Alexaの公式サウンドライブラリもテキストをコピペで貼るだけですね。とてもかんたんです。
SSMLでオーディオ再生する場合の制限
ただし、SSMLでオーディオ再生する場合にはいろいろな要件があります。詳細は以下にあります。
かんたんに説明するとこういうことです。
- 1回のAlexaの発話で、オーディオファイルは5個まで
- かつ、1回のAlexaの発話で、オーディオファイルの合計再生時間が240秒以内
この制限は結構厳しいです・・・
この制限を超えるにはAudioPlayerを使う必要があります。VoiceflowだとStream Blockでできます。ただしその場合は、音楽を聞くということが目的の「mp3プレイヤー」っぽいスキルになりますので、Alexaとの対話を楽しむようなスキルとは異なったユーザ体験になってしまいます。
そしてもう一つ「Alexaの発話やオーディオの並列再生はできない」ということがあります。つまり、Alexaの発話の後ろでBGM的にオーディオを再生させたり、AlexaとMizuki/Takumiを同時に喋らせたりということができないのですね・・・
ということで、表現力にちょっと限界があるのが実情です。
APL for Audioでできること
そこでAPL for Audioです!APL for Audioでは以下が実現できます。
- 1回の発話で使えるオーディオファイルの数が15個に増えました!
- Alexaの発話とオーディオが同時に並列で再生できるようになりました!もちろん、発話同士・オーディオ同士の同時再生も可能です!
- フィルター設定により、オーディオのフェードイン・フェードアウト、再生時間の調整、ボリュームの調整ができるようになりました!
- より高音質で、かつ、多彩なフォーマットに対応!
素晴らしいですね!これにより表現豊かな音声コンテンツが期待できます!詳細については以下でもまとめていますので、よろしければご覧ください。
Directive Block
前フリが長くなりましたが、ではVoiceflowのAPL for Audioについて見ていきましょう。今回、APL for Audioのために新しいブロックが増えました。「Directive Block」です。

もう一つ「Event Block」というのが増えていますが、ここはちょっと置いときましょう(こちらも詳細がわかればご紹介したいと思います。)
こんな感じでサンプルスキルを作ってみました。

最初にユーザの名前を聞いて、そのユーザを主人公としたお話を話すという「物語」的なサンプルスキルをイメージしています。
ここまでの部分でテストした感じはこんな感じです。

ではここにDirective Blockをつなげましょう。

Directive Blockをクリックして、どういう設定ができるのかを見てみましょう・・・っと、大きなテキスト入力欄だけですね。

ここに試しに以下のコードをコピペしてみてください。
こんな感じになればOKです。
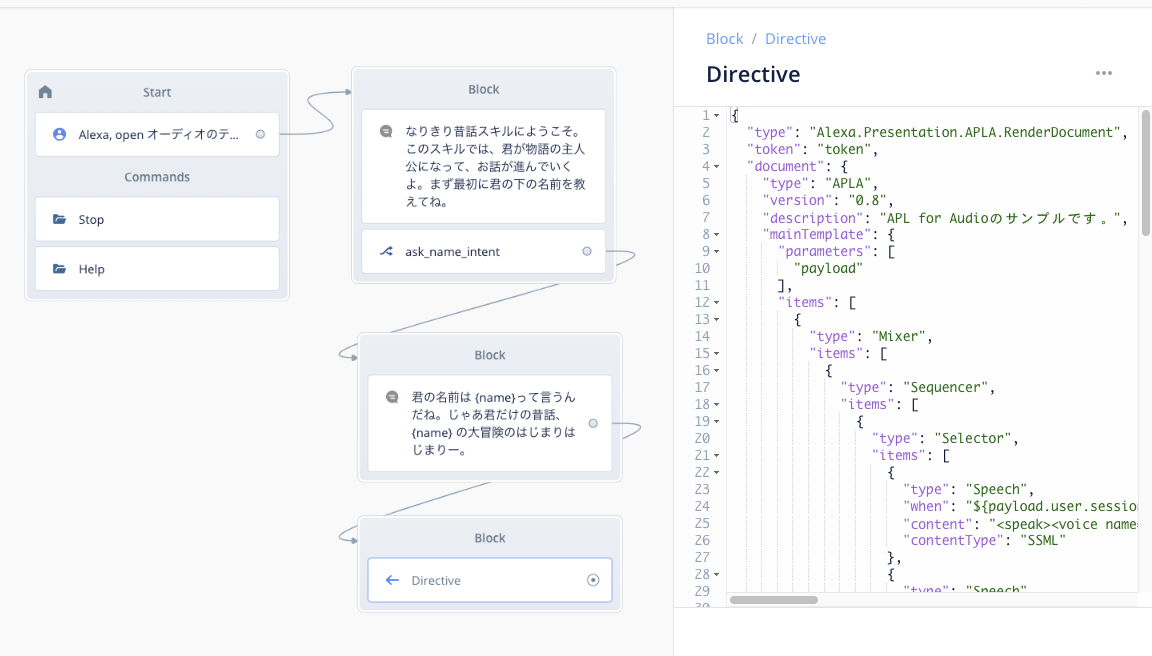
ではアップロードしてテストシミュレータで確かめてみましょう。

せっかくなので音声付きで試したものをお聞きいただきましょう。
※SHW様のフリー音源を使用させていただきました。
BGM付きでいろんな効果音とともに発話が流れていますね!VoiceflowでもAPL for Audioが実現できました!
APLAドキュメントとは?
さきほどコピペしてもらったコードは、「APLAドキュメント」といい、APL for Audioで発話や音声を定義するために使用します。
ちなみに、画面付きデバイス向けにビジュアル表示をする場合にも同様のコードが必要になり、こちらは「APLドキュメント」と言います。細かいところは違いますが、似たような構造になっています。
APLAドキュメントは、Alexa開発者コンソールにAPL/APL-Aオーサリングツールというものがあり、それを使って作成します。かんたんに流れを説明しておきます。
Alexa開発者コンソールにログインして、Voiceflowで作成しているスキルを開きます。

左のメニューから「マルチモーダル」をクリックします。

新しいタブで以下のような画面が開きます。これがAPLのオーサリングツールです。

オーサリングツールは、APL for Audioだけでなく、画面付きデバイス向けのAPLにも対応しています。このタブの部分をクリックすることで、APL for Audio用・APL用を選択できます。今回はAPL for Audio用のドキュメントを作成しますので、"Audio"が選択されていればOKです。

ではAPLAドキュメントを作成します。"Create Audio Response"をクリックします。2つありますがどちらでもよいです。

APLAドキュメントのエディター画面が開きます。ここでドキュメントを修正していくわけですね。

APLAドキュメントそのものの書き方についてはそれだけで結構なボリュームになるので割愛します。[公式のドキュメント](https://developer.amazon.com/ja-JP/docs/alexa/alexa-presentation-language/apl-for-audio-reference.html)を見ていただければと思いますが、まだ英語だけなんですよね。。。
修正した内容は左下の「再生」をクリックすると確認ができます。

こんな感じで波形が表示されて再生されれば動作しています。

エラーの場合は右下に以下のようなメッセージが表示されて再生されません。エラー箇所を探して修正します(どこが間違ってるかは教えてくれない・・・)

完成したら、右上のダウンロードアイコンをクリックして、ファイルをダウンロードします。

ファイルをエディタで開きます。

で、あとはVoiceflowのDirective Blockにコピペするだけ・・・と言いたいところですが、現時点では少しだけ修正が必要になります。一番最初に"document": {と書かれている箇所の上に以下の2行を追加します。
"type": "Alexa.Presentation.APLA.RenderDocument", "token": "token",

あとはコピペしてDirective Blockに貼り付ければOKです!
開発者ディスクアイコンをクリックすると該当のスキル内に保存されますが、Voiceflowでは使用しません(Voiceflow側のDirective Blockにコピペするので)。ただ、管理上どこかに保存しておきたいという場合には良いと思います。
まとめ
VoiceflowでもAPL for Audioができました!Alexa Liveからそれほど時間が経ってないんですが、非常に対応が早かったですね!
が、コードを書かずにGUIだけでできるVoiceflowでも、残念ながらAPL for AudioのドキュメントについてはGUIでかんたんに設定ができるという風にはまだなっていません。これについては、Alexa開発者コンソールのオーサリングツールもAPLAドキュメントについては現状コードを書くしかない(画面付きデバイス向けAPLドキュメントのエディターは多少GUIで設定できるようになっている)ですし、エラーが起きても原因がわかりにくかったり、ドキュメントがまだ日本語になっていなかったりと、Amazon公式でもまだまだ整備段階のようなので致し方ないかもですね。Amazon公式とVoiceflowのAPL for Audio β版、両方含めて今後の改善に期待したいと思います。
ただそれを差し引いても、APL for Audioを使うと非常に表現力が高くなり、よりにぎやか・臨場感のある・楽しいスキルの開発が可能になると思いますので、積極的に使っていきたい機能です。正式にリリースされた場合にはぜひご活用ください!
繰り返しになりますが、VoiceflowのAPL for Audioはまだβテスト中です。リリース時には変更されている可能性があります。ご注意ください。
おまけ
コードを書いている人向けにおまけ&私の勝手な妄想レベルなので無視してください。
Directive Blockって要はディレクティブを追加するんですね。ask-sdkで書くとこの部分。
return handlerInput.responseBuilder
.addDirective({
"type": "Alexa.Presentation.APLA.RenderDocument",
"token": "token",
"document": {
...snip...
},
"datasources": {
...snip...
}
})
.getResponse();
以下が必要になのはそういうわけですよね・・・
そして、説明しなかったこれ。
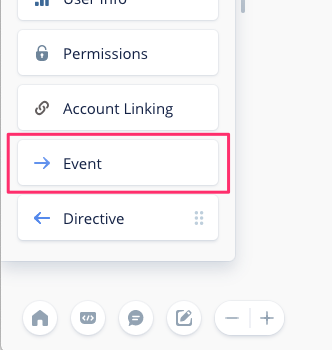
中の設定を除くと・・・
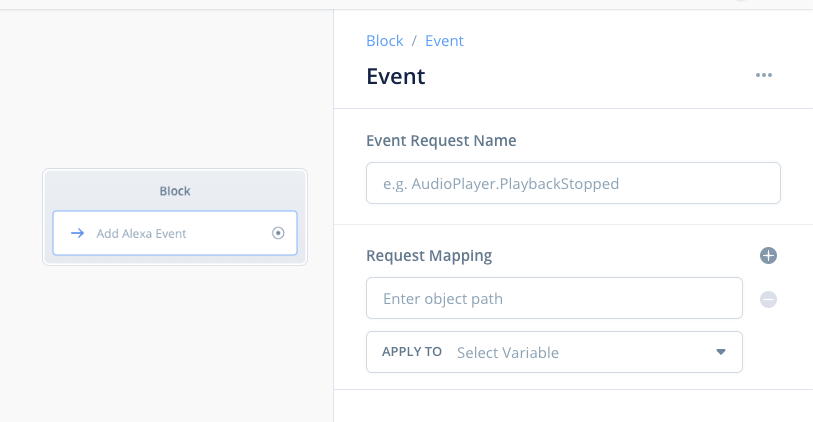
いやー、この2つでいろいろ考えると、夢が広がるなぁーーー。ちなみにこちらもβテストじゃないと見れないですし、かつ詳細についてはまだアナウンスされていません。期待して待ちたいです。
