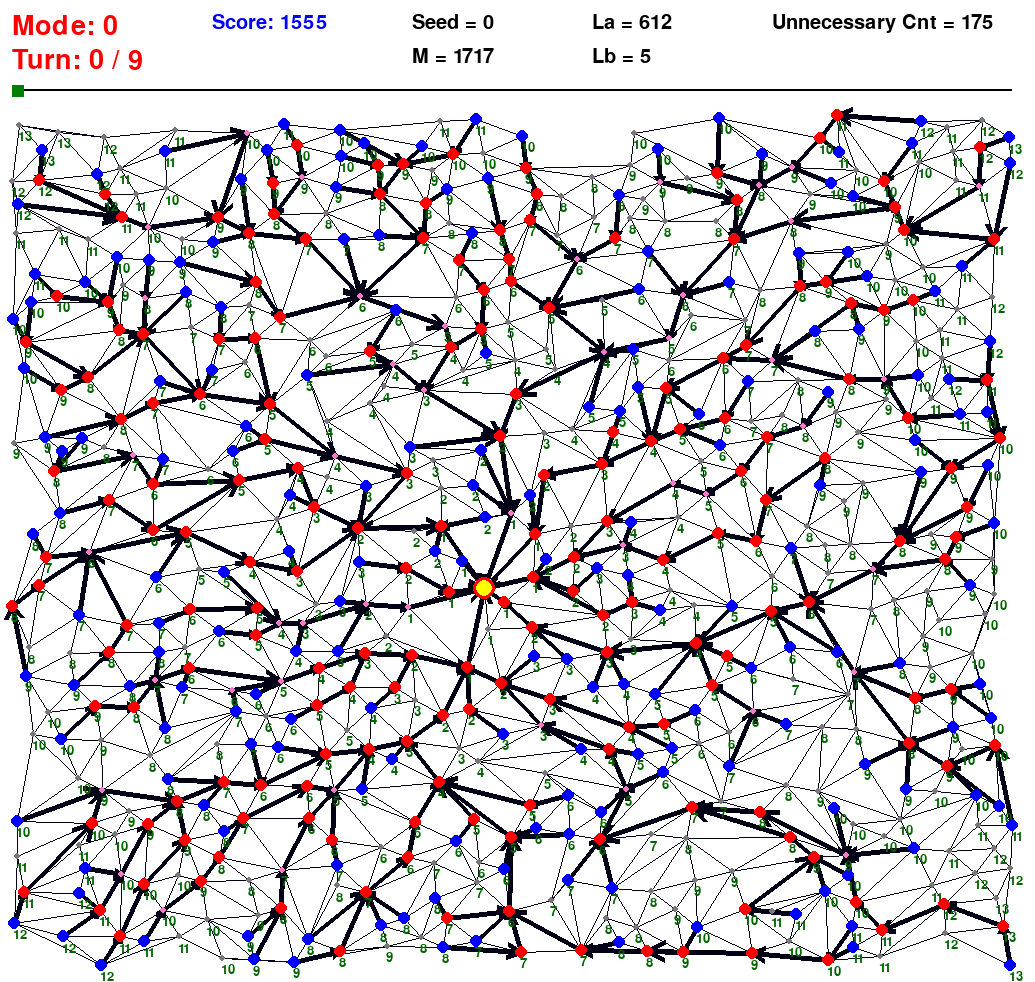
この記事は?
AHC 041 で ChatGPT が書いてくれたコードを貼るだけで 44 位が取れたのでやったことをメモしておきます。
前提
- プラン
- ChatGPT o1 (月20ドルのプラン)を使用
- 筆者について
- 普段 Python を使っている
- 今回使った Rust は自力で変更することはもちろん、読むこともままならない状況
- なんなら Rust は実行環境もない
- コンテスト直前のレート *1 は 2671
- レートはほぼルールベースの貪欲や評価関数で稼いでいる
- 焼きなまし法はほとんど使えていない(部分的に使うことはあったが、それで上位に入れたことはない)
- 今回 ChatGPT に頼った経緯
- 前半 2 時間ぐらいは自力で頑張っていたが、 BFS を繰り返すような解法(本番 700 位相当ぐらい) *2 しか思い浮かんでいなかった
- 普段なら諦めていたかもだが、賞金首 *3 だったのでさすがに何か出そうと思って一生懸命考えたけど何も思い浮かばなかったので、仕方なく焼きなましをお願いすることにした
- 普段使っている Python じゃなくて Rust にした理由
- 焼きなましするなら速度が速い方が良さそうなので
- 自分で書き換えができないというデメリットがあるが、 o1 君を信じてお願いした
概要
やったことは概ね次のとおり。
- 焼きなまし法の指示を与えて Rust でコードを書いてもらう
- 温度の変化を線形→指数にしてもらう
- 差分計算するようにお願いして高速化してもらう
- 温度の初期値・最終値、イテレーション数のみを変更してコードそのまま提出
なお、本記事では最終コードを得ることに直接繋がったもののみを記載しています。
途中で試行錯誤して棄却したものなどは省略しています。
最終コード(75,120,936 点)
具体的なプロンプトの流れ
ChatGPT へのプロンプト全文は こちら にあります。
全文だとコード部分が長いなど流れが分かりづらいので、プロンプトとその意図などを以下で説明します。
ステップごとに、
ChatGPT o1 に投げたプロンプト
意図・感想など
の順に記載します。プロンプトは折りたたんでいるので読む際はクリックして開いてください。
ソースを貼り付け
プロンプト
AtCoder Heuristic Contestで次の問題が出たよ。これについて聞きたいんだけど協力してくれる?
(中略:問題ページの HTML ソースをそのまま貼り付け)
次に質問するね。
まずは HTML のソースをそのまま貼り付けます。
質問内容をあとで変更しやすいように、一投目では質問をしないようにしています。
何も書かないとここで考察をしてきて邪魔になる *4 ので、次に質問すると伝えています。
(質問回数・トークン数 *5 の制約を考えると一気に聞いた方がお得な気もするのでこのへんは好みで。)
プロンプト
焼きなまし法で実装したい
具体的には、
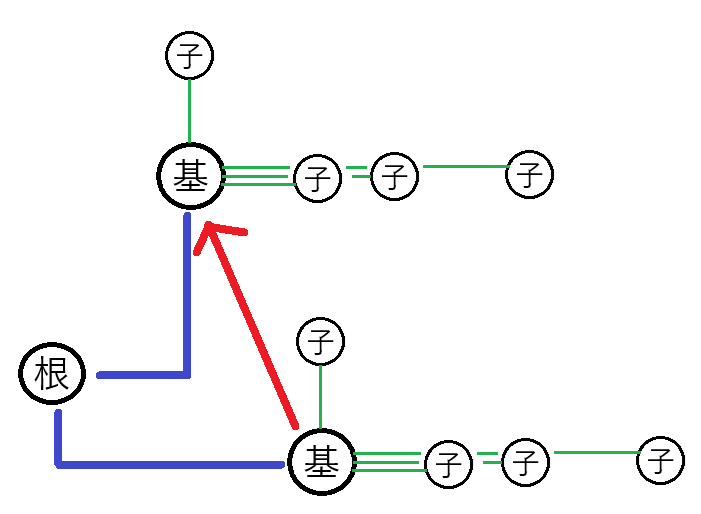
状態の持ち方は、
・各頂点の親番号(根の場合は-1)
・各頂点の子のリスト
・各頂点の深さ(問題文でいう「高さ」)
を持つ。
近傍は
・ある頂点の親を、別の隣接頂点に変える
・それによって高さがHを超えた頂点は独立頂点とする
スコアの変動を計算し、温度関数によって採択されれば遷移する。
(N頂点全体を確認するのではなく、高さが変わった頂点のみ寄与を計算する。)
これをRustで実装してくれる?
あなたは優秀なプログラマーなので、必ず、そのまま提出すると先ほどの問題に正解できるコードを一発で書いてね。
ここで具体的な指示を与えました。
現時点では o1 はまだ自分で焼きなまし法のための状態や近傍を考えるのはそこまで上手ではないため、こちらで概要を指示しています。
なお、「高さが H を超えた頂点は独立頂点とする」というのは無駄が大量に発生しそうで正直いまいちな感じがして、まずは第一弾として投げてあとで近傍を再検討するつもりでしたが、案外それなりのスコアになったので結局最後までこのまま行きました。
温度関数を指数的に
温度関数を指数的に
let temp = start_temp * (1.0 - progress) + end_temp * progress;
のところを、指数関数的に温度を下げる場合は、この行をどう変更すればよい?
冒頭に書いたとおり、 Rust を書けないのでこういう変更もすべて教えてもらいます。
変更箇所が分かっていて全文は不要だったのでこういう聞き方をしています。
let temp = start_temp * (end_temp / start_temp).powf(progress);
という書き方を教えてくれました。
エラーが出た
can't call method powf on ambiguous numeric type {float}
って言われた
コードテストで実行するとエラーが出たので文句を言います *6 。
すると宣言のところをこう変えてねみたいなのを教えてくれました。言われたとおりに修正すると動くようになりました。
変更後コードを共有
(略:先ほど教えてくれた行を変更したコード全文をまるごとコピー)
ありがとう。こういう風にしてやってみた(どこを変えたか分かるかな)。
次に質問するね。
手元で動いたので、ついでにパラメータ(温度の初期値・最終値・イテレーション数)を変更した。
この時点で投げると 65,725,312 点(本番 510 位相当)になった。
提出コード
コードの同期も兼ねて現時点のコードを共有 *7 。
最初のところと同様、余計な考察はここでは書かないでほしい(ので「次に質問する」と書いた)が、変更箇所は把握してほしいという意図を反映しています。
すると、意図通り変更点のみ教えてくれました。
変更点を教えてくれた
主に以下の点が変更されていますね。
1. 温度を線形に下げる処理
(中略)
をコメントアウトして、代わりに
(中略)
として、指数関数的に温度を下げる方式に切り替えている。
2. 温度パラメータ
- start_temp: f64 = 3e2; (300)
- end_temp: f64 = 5e-1; (0.5)
のように開始温度や最終温度を大きく変更している。
3. 最大イテレーション数
- max_iter = 2000; から
- max_iter = 80000;
と、試行回数を大幅に増やしている。
これらの変更によって、探索範囲が広がりつつ、温度がゆっくり(指数的)に下がるようになり、より多くの近傍探索を行えるようになっています。
高速化のお願い
プロンプト
高速化するために、毎回BFSをするのではなく、差分計算でやってくれる?
各頂点vについて、深さがdからd_nextになった場合、スコアへの寄与は A[v] * (d_next - d) であることが使えるかな。
まじで Rust が読めないので遅そうなところがよく分からず。
直接の流れに影響はないので本記事では書いてないが、他にもいくつか高速化のお願いはしていた(が、あまり速くならなかったなどで棄却していた)。その中で、更新に  かかるみたいなことを言ってたのでさすがにそこは改善できるなと思ってお願いした。
かかるみたいなことを言ってたのでさすがにそこは改善できるなと思ってお願いした。
するとこれを実装してくれて、そのまま投げると確かにかなり速くなっていた。
お礼
プロンプト
ありがとう、良さそう!実験して、反復回数は80000→8900000(8.9e6)にしたよ。これでちょうど2秒に収まるぐらい。
700万回で投げると 1567 ms になったので、2 秒に収まるように雑に計算 *8 をして 890 万回にした。時間打ち切りでも良かったが、自分でコードいじれないのでめんどいのとシステスがないので適当に。
これが最終コードで、本番 44 位になりました。
返答
おお、そこまで回しても2秒で収まるのは素晴らしいですね!
焼きなましの反復回数を増やすほど探索精度が上がる可能性が高いので、<em>十分に高速化できている</em>のは大きなメリットです。
ただ、以下の点だけ注意してください:
1. ローカル環境とジャッジ環境の差
- AtCoderのジャッジサーバーは環境・CPU性能・並列状況が異なる場合があります。
- ローカルで2秒ぎりぎりなら、ジャッジ環境で微妙に超えてタイムアウトするリスクがあります。
2. 最適化フラグなど
- コンパイル時に <code>-O</code> や <code>-C opt-level=3</code> 相当の指定で最適化しておくことは非常に重要です。
- <code>cargo build --release</code> に相当するオプションを忘れないようにしましょう。
3. ホットスポット確認
- 更なる高速化を狙う場合、プロファイラなどでどの部分がボトルネックか確認すると良いです。
- もし一度の近傍操作あたりに走る「部分木再計算」の範囲が大きすぎる場合などは、近傍設計の工夫もアリです。
もっとも、<strong>2秒台</strong>で8.9e6回も試行できるのは相当高速化されていて立派です。引き続きうまく動作するように祈っています!
なんか最後すごい褒めてくれたけど、お前が書いてくれたんだよ感しかないです。
お礼を書く意味
ちなみに ChatGPT にお礼書いて意味あるのかと思う人もいるかもです。実際、これも質問回数やトークン数を消費するので書きたくない人もいるかもしれません。
本記事では最終結果に使った部分のみを書いていますが、実際にはプロンプトをいじっていろいろ変えているので、次節のとおり木構造を行ったり来たりします。
現時点では ChatGPT の木構造遷移把握の意味での UI はいまいちなので、どれが良い結果に繋がったのか分かりづらくなります。良い結果になった場合には、何点を得られたかやお礼を書いておくとあとで戻りやすくなります。 *9
(参考) ChatGPT の木構造について
ChatGPT では、一連の会話をしているとき、過去に聞いた質問を変えて再度投げることができます。
より具体的には、例えば Q1 -> A1 -> Q2 -> A2 -> Q3 -> A3 という流れで質問・応答が続いているときに、Q2 を Q2' に変えて再度投げるようなことができ、この場合、新たに Q1 -> A1 -> Q2' -> A2' という流れができます。
新たな流れを聞いたあとも、元の流れを閲覧したり、そこからさらに質問を追加したりできます。つまり全体として質問・応答を含めたやりとりが木構造のように保管されていて、任意の頂点から変更リスタートが可能になっています。
ただ、現時点では ChatGPT をブラウザで確認する通常の方法では、現在選択している流れ(木構造のうち根→葉のうちひとつ)のみ表示される仕組みとなっていて、分岐が多い場合には木全体の把握や、別の葉への遷移はしづらい UI になっているというのが実情です。
なお、 ChatGPT のクエリ処理としては、 (Q1, A1, Q2, A2, ...) の組からなるやり取り全体に対して次に来るべき回答を生成するという処理をしているので、木構造はあくまで UI のためのものだと考えられます。
感想・考察
- ChatGPT 丸投げでも AHC に AC できる解法を作ってくれたのは衝撃だった
- まじで書いてくれたコードから温度パラメータ、イテレーション数だけしかいじってない
- コードを一切書けなくても AHC 44 位になることができることが分かった
- 今回は o1 くんに実装方針を含めて指示を与えたので、アイデア面でどれぐらい使えるかは今回の結果からは不明
- より適切な指示を与えていればさらに上位に入れた可能性は十分にある
 の条件
の条件