https://docs.spring.io/spring-batch/4.1.x/reference/html/job.html#configureJob
https://qiita.com/kagamihoge/items/12fbbc2eac5b8a5ac1e0 俺の訳一覧リスト
1. Configuring and Running a Job
domain sectionでは、以下図を用いてアーキテクチャデザイン全体について解説しました。
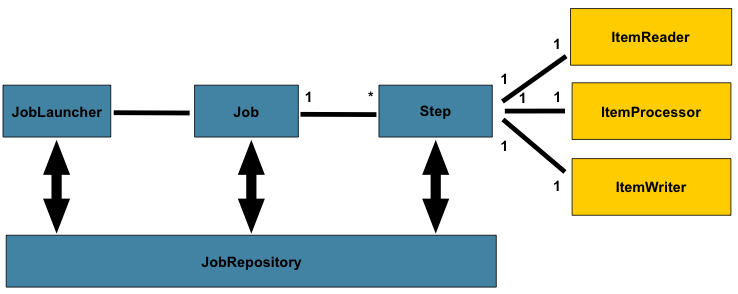
Figure 1. Batch Stereotypes
Jobオブジェクトはstepの単なるコンテナのように見えますが、開発者が知っておいた方が良い多数の設定オプションがあります。また、Jobの実行方法とそのメタデータが実行中にどのように格納されるのかにも注意が必要です。このチャプターでは各種設定オプションとJob実行時の注意事項について解説します。
1.1. Configuring a Job
Jobインタフェースには複数の実装がありますが、ビルダーが設定の違いを吸収します。
@Bean public Job footballJob() { return this.jobBuilderFactory.get("footballJob") .start(playerLoad()) .next(gameLoad()) .next(playerSummarization()) .end() .build(); }
Job(とそれに含むStep)はJobRepositoryを必要とします。JobRepositoryの設定はBatchConfigurerで行います。
上は3つのStepインスタンスを持つJobの例です。また、jobのビルダーでは、パラレル(Split)関連、宣言的なフロー制御(Decision)、フロー定義(Flow)の外部化、も設定出来ます。
1.1.1. Restartability
バッチjob実行時の重要な課題の一つはリスタート時のJobの振る舞いについてです。もし特定のJobInstanceに対するJobExecutionが既に存在する場合、Jobの実行はリスタートと見なします。理想的には、すべてのjobは失敗した箇所から開始可能であるべきですが、それが可能ではないケースがあります。あるケースで新規のJobInstanceを生成する事を保証するのは開発者の責任です。ただし、Spring Batchはその補助機能を提供します。Jobをリスタート不可にする場合、常に新規のJobInstanceで実行し、restartableのプロパティを'false'に設定します。
Java Configuration
@Bean public Job footballJob() { return this.jobBuilderFactory.get("footballJob") .preventRestart() ... .build(); }
別の言い方をすると、restartableをfalseにする事は"このJobは再開出来ない"を意味します。restartableがfalseのJobをリスタートするとJobRestartExceptionをスローします。
Job job = new SimpleJob(); job.setRestartable(false); JobParameters jobParameters = new JobParameters(); JobExecution firstExecution = jobRepository.createJobExecution(job, jobParameters); jobRepository.saveOrUpdate(firstExecution); try { jobRepository.createJobExecution(job, jobParameters); fail(); } catch (JobRestartException e) { // ここを通る }
上のJUnitコードは、リスタート不可のjobの1回目に実行するためのJobExecutionを生成し、特に例外は起きません。そして、2回目にはJobRestartExceptionをスローします。
1.1.2. Intercepting Job Execution
Jobの実行中に、何らかのカスタムコードを差し込むために、ライフサイクルの各種イベント通知が有用な場合があります。SimpleJobは適時JobListenerを呼ぶことでこれを実装しています。
public interface JobExecutionListener { void beforeJob(JobExecution jobExecution); void afterJob(JobExecution jobExecution); }
SimpleJobのjobにJobListenersを追加するにはlisteners要素で行います。
Java Configuration
@Bean public Job footballJob() { return this.jobBuilderFactory.get("footballJob") .listener(sampleListener()) ... .build(); }
なお、Jobの成功か失敗かに依らずafterJobは呼ばれます。成功か失敗かを判別したい場合はJobExecutionから取得します。
public void afterJob(JobExecution jobExecution){ if( jobExecution.getStatus() == BatchStatus.COMPLETED ){ //job success } else if(jobExecution.getStatus() == BatchStatus.FAILED){ //job failure } }
インタフェースに対応するアノテーションは以下の通りです。
@BeforeJob@AfterJob
1.1.4. JobParametersValidator
jobをXMLで宣言したり、AbstractJobのサブクラスにする場合、実行時にjobパラメータ用のvalidatorをオプションで宣言できます。たとえば、すべての必須パラメータを検証してjobを開始したい場合に役立ちます。DefaultJobParametersValidatorでは必須およびオプションの単純なパラメータの組み合わせ検証が可能で、複雑な検証にはインタフェースを自前で実装します。
validatorの設定はjavaのbuilderでも設定可能です。
@Bean public Job job1() { return this.jobBuilderFactory.get("job1") .validator(parametersValidator()) ... .build(); }
1.2. Java Config
Spring 3ではXMLに加えてjavaでのアプリケーション設定機能が追加されました。Spring Batch 2.2.0現在、バッチjobはjava configで設定可能です。javaベースの設定には2つのコンポーネントがあり、@EnableBatchProcessingと2つのビルダーがあります。
@EnableBatchProcessingはSpringファミリーの@Enable~アノテーションと同様の動作をします。@EnableBatchProcessingはバッチjobを組み立てるためのベースとなる設定を提供します。ベース設定内で、StepScopeインスタンスが作られ、他にもいくつかのbeanがautowired可能にしています。
JobRepository- bean name "jobRepository"JobLauncher- bean name "jobLauncher"JobRegistry- bean name "jobRegistry"PlatformTransactionManager- bean name "transactionManager"JobBuilderFactory- bean name "jobBuilders"StepBuilderFactory- bean name "stepBuilders"
この設定のコアとなるインタフェースはBatchConfigurerです。デフォルト実装は上のbeanを提供し、コンテキストにDataSourceのbean定義が必要です。このデータソースはJobRepositoryで使用します。BatchConfigurerのカスタム実装を作ることで上述のbeanのカスタマイズが可能です。基本的には、DefaultBatchConfigurer(BatchConfigurerがコンテキスに無ければこれを使用する)を拡張して必要なgetterをオーバーライドします。なお、スクラッチから実装することも可能です。以下の例はカスタムのtransaction managerを使用する例です。
@Bean public BatchConfigurer batchConfigurer() { return new DefaultBatchConfigurer() { @Override public PlatformTransactionManager getTransactionManager() { return new MyTransactionManager(); } }; }
※ @EnableBatchProcessingを持つconfigクラスは1つだけにして下さい。このアノテーションを1つでもどこかのクラスに付与すると、上述のbeanが利用可能になります。
所定のベースconfigにおいて、job設定のためのビルダーのファクトリーを使用可能です。以下はJobBuilderFactoryとStepBuilderFactoryで2つのstepのjobを設定する例です。
@Configuration @EnableBatchProcessing @Import(DataSourceConfiguration.class) public class AppConfig { @Autowired private JobBuilderFactory jobs; @Autowired private StepBuilderFactory steps; @Bean public Job job(@Qualifier("step1") Step step1, @Qualifier("step2") Step step2) { return jobs.get("myJob").start(step1).next(step2).build(); } @Bean protected Step step1(ItemReader<Person> reader, ItemProcessor<Person, Person> processor, ItemWriter<Person> writer) { return steps.get("step1") .<Person, Person> chunk(10) .reader(reader) .processor(processor) .writer(writer) .build(); } @Bean protected Step step2(Tasklet tasklet) { return steps.get("step2") .tasklet(tasklet) .build(); } }
1.3. Configuring a JobRepository
@EnableBatchProcessingを使う場合、特に設定無くJobRepositoryを使えます。このセクションでは自前での設定についてを解説します。
前述の通り、JobRepositoryはSpring Batch内の各種永続化オブジェクト、JobExecutionやStepExecutionなど、のための基本的なCRUD操作で使います。このクラスはフレームワークの主要機能、JobLauncher, Job, Step、など多くの場所で使用します。
java設定の場合、JobRepositoryが使用可能です。DataSourceがあればJDBCベースの実装が使われ、無ければMapベースが使われます。ただし、BatchConfigurerの実装を利用してJobRepositoryのカスタマイズは可能です。
Java Configuration
... // 以下はBatchConfigurerの実装内に置くものとする。 @Override protected JobRepository createJobRepository() throws Exception { JobRepositoryFactoryBean factory = new JobRepositoryFactoryBean(); factory.setDataSource(dataSource); factory.setTransactionManager(transactionManager); factory.setIsolationLevelForCreate("ISOLATION_SERIALIZABLE"); factory.setTablePrefix("BATCH_"); factory.setMaxVarCharLength(1000); return factory.getObject(); } ...
上記の設定オプションは、 dataSourceとtransactionManagerを除いて、いずれも必須ではありません。設定しない場合、上のサンプルコードに書かれたデフォルト値を使います。They are shown above for awareness purposes. max varchar lengthのデフォルトは2500で、sample schema scriptsのlong VARCHARカラムのlengthになります。
1.3.1. Transaction Configuration for the JobRepository
namespaceもしくはFactoryBeanを使用する場合、transactional adviceがrepositoryのaroundに自動的に作られます。これは、バッチメタデータに含まれる状態のうち、失敗後のリスタートに必要な状態が正しく永続化される、事を保証します。repositoryのメソッドが非トランザクションの場合、フレームワーク振る舞いが不定になります。The isolation level in the create* method attributes is specified separately to ensure that when jobs are launched, もし2つのプロセスが同時に同一jobを起動すると片方だけが成功します。このメソッド用のデフォルトのisolation levelはSERIALIZABLEで、この設定はかなり攻めているため、READ_COMMITTEDでも同様に機能します。2つのプロセスが衝突をしないような場合にREAD_COMMITTEDが適します。ただ、create*メソッドの呼び出しは極めて短時間なので、DBがサポートしていれば、SERIALIZEDが問題となる可能性は低いです。とはいえ、オーバーライドは可能です。
Java Configuration
// 以下はBatchConfigurerの実装内に置くものとする。 @Override protected JobRepository createJobRepository() throws Exception { JobRepositoryFactoryBean factory = new JobRepositoryFactoryBean(); factory.setDataSource(dataSource); factory.setTransactionManager(transactionManager); factory.setIsolationLevelForCreate("ISOLATION_REPEATABLE_READ"); return factory.getObject(); }
namespaceあるいはfactory beansを使わない場合、AOPを使用するrepositoryのtransactionalな振る舞いの設定が必要です。
Java Configuration
@Bean public TransactionProxyFactoryBean baseProxy() { TransactionProxyFactoryBean transactionProxyFactoryBean = new TransactionProxyFactoryBean(); Properties transactionAttributes = new Properties(); transactionAttributes.setProperty("*", "PROPAGATION_REQUIRED"); transactionProxyFactoryBean.setTransactionAttributes(transactionAttributes); transactionProxyFactoryBean.setTarget(jobRepository()); transactionProxyFactoryBean.setTransactionManager(transactionManager()); return transactionProxyFactoryBean; }
1.3.2. Changing the Table Prefix
JobRepositoryのもう一つの設定可能なプロパティにメタデータテーブルのプレフィクスがあります。デフォルトではすべてBATCHが頭につきます。BATCH_JOB_EXECUTIONとBATCH_STEP_EXECUTIONなどです。このプレフィクスを変更しなければならないケースが存在します。スキーマ名をテーブル名に付ける必要があるとか、同一スキーマ内に複数のメタデータテーブルを作る必要があるなどで、この場合はテーブルのプレフィクスを変更する必要があります。
Java Configuration
// 以下はBatchConfigurerの実装内に置くものとする。 @Override protected JobRepository createJobRepository() throws Exception { JobRepositoryFactoryBean factory = new JobRepositoryFactoryBean(); factory.setDataSource(dataSource); factory.setTransactionManager(transactionManager); factory.setTablePrefix("SYSTEM.TEST_"); return factory.getObject(); }
上のように変更すると、メタデータテーブルに対するすべてのクエリに"SYSTEM.TEST_"のプレフィクスがつきます。BATCH_JOB_EXECUTIONはSYSTEM.TEST_JOB_EXECUTIONで参照します。
※ テーブルのプレフィクスだけが変更可能です。テーブルとカラム名は変更できません。
1.3.3. In-Memory Repository
DBにドメインオブジェクトの永続化をしたくないケースが存在します。1つは速度で、コミットポイントごとのドメインオブジェクトの保存には幾分かの時間がかかります。もう1つは、特定のjobに限っては状態を永続化したくない場合です。このような用途のために、Spring Batchはjob repositoryのインメモリMap版を用意しています。
Java Configuration
// 以下はBatchConfigurerの実装内に置くものとする。 @Override protected JobRepository createJobRepository() throws Exception { JobRepositoryFactoryBean factory = new JobRepositoryFactoryBean(); factory.setDataSource(dataSource); factory.setTransactionManager(transactionManager); factory.setIsolationLevelForCreate("ISOLATION_REPEATABLE_READ"); return factory.getObject(); }
インメモリのrepositoryは揮発性でJVMインスタンス間を超えてのリスタートが出来ない点に注意してください。同一パラメータの2つのjobインスタンスを同時に実行する事も保証出来ないので、マルチスレッドJobには適しておらず、また、locally partitioned Stepも同様です。よって、それらの機能を使いたい場合にはrepositoryのDBバージョンを使用してください。
なお、transaction managerを定義する必要があり、その理由はrepository内にはrollback semanticsがあるのとビジネスロジックにはたいていtransactionalな箇所(RDBMSアクセス)があるためです。テスト目的ではResourcelessTransactionManagerを使うと便利です。
1.3.4. Non-standard Database Types in a Repository
使用するDBがサポート対象リストに無い場合、SQLバリアントがなるべく近いものを、サポート対象から1つ選べば使える可能性があります。これを設定するにはnamespaceショートカットの代わりにJobRepositoryFactoryBeanを使用し、一番近いDBタイプをセットします。
Java Configuration
// 以下はBatchConfigurerの実装内に置くものとする。 @Override protected JobRepository createJobRepository() throws Exception { JobRepositoryFactoryBean factory = new JobRepositoryFactoryBean(); factory.setDataSource(dataSource); factory.setDatabaseType("db2"); factory.setTransactionManager(transactionManager); return factory.getObject(); }
(JobRepositoryFactoryBeanはDBタイプが未指定の場合はDataSourceから自動検出します。)プラットフォームごとの主な違いはプライマリキーのインクリメント方法で、これが異なる場合にはincrementerFactoryをオーバーライドする必要があります(Spring Frameworkの標準実装の一つを選んで使用する)。
これが動作しない場合、もしくはRDBMSでは無い場合、SimpleJobRepositoryが依存する各種のDaoインタフェースを実装してSpringの作法に沿ってマニュアルでそれらのbeanをワイヤリングするのが唯一の解決策です。
1.4. Configuring a JobLauncher
@EnableBatchProcessingを使う場合、特に設定無くJobRegistryを使えます。このセクションでは自前での設定についてを解説します。
JobLauncherインタフェースのベーシックな実装がSimpleJobLauncherです。このオブジェクトの依存性は、executionを取得するための、JobRepositoryだけです。
Java Configuration
// 以下はBatchConfigurerの実装内に置くものとする。 ... // This would reside in your BatchConfigurer implementation @Override protected JobLauncher createJobLauncher() throws Exception { SimpleJobLauncher jobLauncher = new SimpleJobLauncher(); jobLauncher.setJobRepository(jobRepository); jobLauncher.afterPropertiesSet(); return jobLauncher; } ...
JobExecutionを取得すると、Jobの実行メソッドに渡され、最終的に呼び出し元にJobExecutionを返します。
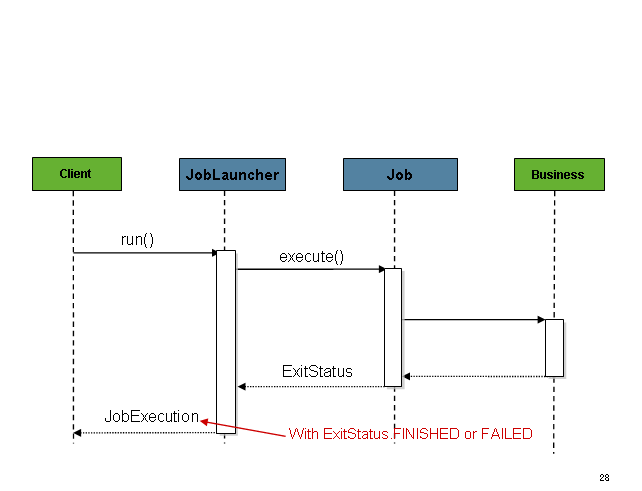
Figure 2. Job Launcher Sequence
このシーケンスは単純化したものでスケジューラから起動する場合にはうまくいきます。しかし、HTTPリクエスト経由の起動時には問題があります。この場合、起動は非同期で行う必要があり、SimpleJobLauncherは呼び出し元へ即時リターンする必要があります。バッチなど長時間実行プロセスでHTTPリクエストをオープンにしたままにするのは良くありません。
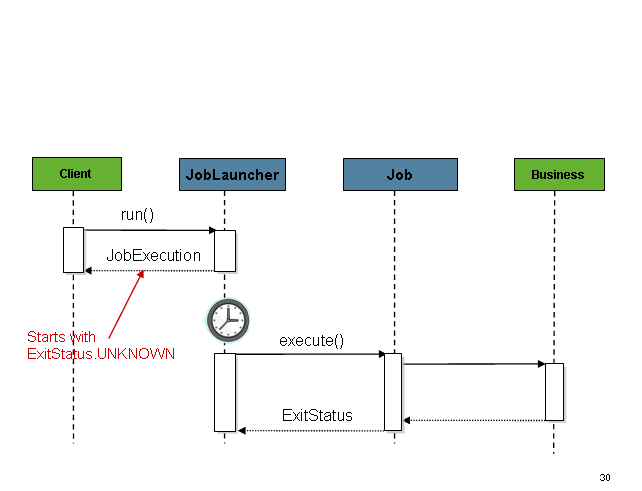
Figure 3. Asynchronous Job Launcher Sequence
SimpleJobLauncherはTaskExecutorを設定することでこのようなケースに簡単に対応できます。
Java Configuration
@Bean public JobLauncher jobLauncher() { SimpleJobLauncher jobLauncher = new SimpleJobLauncher(); jobLauncher.setJobRepository(jobRepository()); jobLauncher.setTaskExecutor(new SimpleAsyncTaskExecutor()); jobLauncher.afterPropertiesSet(); return jobLauncher; }
jobの非同期実行制御にはTaskExecutorインタフェースの実装であれば何でも使用可能です。
1.5. Running a Job
最低点、バッチjobの実行には2つの要素、実行するJobとJobLauncher、が必要です。両者は同一コンテキストでも異なるコンテキストでも構いません。例えば、CLIからjobを起動する場合、各jobごとに新規のJVMをインスタンス化し、各jobごとに固有のJobLauncherを持ちます。ただし、HttpRequestスコープ内のwebコンテナから起動する場合、通常JobLauncherは1つで、これは複数リクエストがjobを起動するために非同期job実行の設定にします。
1.5.1. Running Jobs from the Command Line
エンタープライズのスケジューラからjobを起動するユーザにとっては、CLIが主要なインターフェースになります。たいていのスケジューラ(NativeJobを使用しないQuartzを除く)はOSのプロセスと直接やり取りして、基本的にはシェルスクリプトでキックします。Javaプロセスを起動するには、スクリプトの他、Perl, Ruby, antやmavenなど'build tools'、などがあります。とはいえ、たいていはシェルスクリプトが最もポピュラーで、このサンプルでもシェルにフォーカスします。
The CommandLineJobRunner
jobの起動スクリプトはJava Virtual Machineをキックするので、エントリーポイントとなるmainメソッドを持つクラスが必要です。Spring BatchはまさしくそのためのCommandLineJobRunnerクラスを用意しています。ただし、このクラスはアプリケーションをブートする1つの方法に過ぎず、Javaプロセスを起動する方法は複数あり、このクラスだけが唯一の方法ではありません。CommandLineJobRunnerは4つのタスクを実行します。
- 適切な
ApplicationContextのロード - コマンドライン引数をパースして
JobParametersに入れる - 引数に基づくjobの特定
- job実行にアプリケーションコンテキストの
JobLauncherを使用
これらのタスクはすべて渡す引数のみで実行します。以下が必須の引数です。
Table 1. CommandLineJobRunner arguments
|jobPath|ApplicationContextを生成するためのXMLファイルの場所。このファイルにはJob実行に必要な情報をすべて持つ必要がある。| |jobName|実行するjob名|
これらの引数は最初がpathで次がnameにします。それらの後に来る引数はすべてJobParametersと見なし、'name=value'の形式で渡します。
<bash$ java CommandLineJobRunner io.spring.EndOfDayJobConfiguration endOfDay schedule.date(date)=2007/05/05
通常はjarのmainクラスの宣言にはマニフェストを使用しますが、ここでは説明簡易化のため、直接クラスを指定しています。この例ではdomainLanguageOfBatchと同一の'EndOfDay'サンプルを使用しています。最初の引数は'io.spring.EndOfDayJobConfiguration'でJobを持つconfigクラスの完全修飾クラス名です。次の引数は'endOfDay'でjob名です。最後の引数'schedule.date(date)=2007/05/05'はJobParametersになります。java configの例は以下の通りです。
@Configuration @EnableBatchProcessing public class EndOfDayJobConfiguration { @Autowired private JobBuilderFactory jobBuilderFactory; @Autowired private StepBuilderFactory stepBuilderFactory; @Bean public Job endOfDay() { return this.jobBuilderFactory.get("endOfDay") .start(step1()) .build(); } @Bean public Step step1() { return this.stepBuilderFactory.get("step1") .tasklet((contribution, chunkContext) -> null) .build(); } }
この例はかなり単純化したもので、通常はSpring Batchでバッチjobを動かすには他にも色々なものが必要ですが、CommandLineJobRunnerが必要とする2つのコンポーネント、JobとJobLauncher、がある事を示しています。
ExitCodes
CLIからバッチjobを起動する場合、基本的にはエンタープライズのスケジューラを用います。スケジューラの多くはシンプル(fairly dumb)でプロセスレベルで動作します。つまり、スケジューラは、シェルスクリプトなど、スケジューラが呼び出したOSプロセスについてだけ関知します。この場合、jobの成功か失敗かをスケジューラに戻してやり取りする唯一の方法はリターンコードだけです。リターンコードはプロセスがスケジューラに返す数値で、実行結果を意味します。最もシンプルな場合、0が成功で、1が失敗です。しかし、より複雑なシナリオが考えられます。たとえば、もしjob Aのreturn 4はjob Bをキックし、return 5はjob Cをキックする、などです。この種の振る舞いはスケジューラレベルで設定しますが、重要なのは、Spring Batchなどのフレームワークは特定バッチjobの'Exit Code'の数値表現を返す方法がある、という点です。Spring BatchではこれをExitStatusで表現しており、詳細はChapter 5で解説します。完了コード(exit code)の解説の点で、知るべき最も重要な点は、ExitStatusには完了コードプロパティがありこの値はフレームワーク(か開発者)が設定し、JobLauncherが返すJobExecutionの一部として返されます。CommandLineJobRunnerはExitCodeMapperインタフェースで文字列の完了コードを数値に変換します。
public interface ExitCodeMapper { public int intValue(String exitCode); }
ExitCodeMapperの役割は、文字列の完了コードを数値表現で返すことです。ジョブランナーのデフォルト実装はSimpleJvmExitCodeMapperで、0が正常終了、1が汎用エラー、2はコンテキストにJobが見つからなかったなどのジョブランナーのエラーです。3以上が必要な場合、ExitCodeMapperのカスタム実装が必要です。CommandLineJobRunnerはApplicationContextを作成するクラスで、明示的なワイヤリングが書けないので、上書きしたい値はautowiredする必要があります。つまり、ExitCodeMapperの実装がBeanFactoryにある場合、コンテキスト作成後にランナーにインジェクトされます。自前のExitCodeMapperを使うにはrootレベルbeanとして宣言し、ランナーがロードするApplicationContextの一部となるようにしておきます。
1.5.2. Running Jobs from within a Web Container
歴史的に、バッチジョブなどのオフライン処理は上述のようなCLIで起動していました。しかし、HttpRequest経由で実行するケースがよりベターな選択肢な事も増えました。レポーティング・アドホックなジョブ実行・webアプリケーションサポートなどなどです。定義上バッチジョブは長時間実行するので、最も重要な関心事は非同期なジョブ起動です。
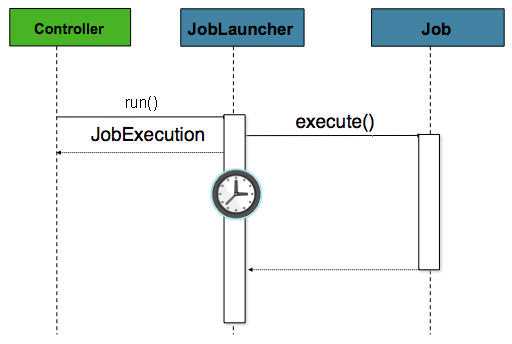
Figure 4. Asynchronous Job Launcher Sequence From Web Container
ここでのcontrollerはSpring MVCのコントローラーです。Spring MVCの詳細については https://docs.spring.io/spring/docs/current/spring-framework-reference/web.html#mvc を参照してください。コントローラーは非同期モードに設定したJobLauncherでJobを実行します。このJobLauncherはJobExecutionを即時リターンします。Jobは実行中のままですが、ノンブロッキングな振る舞いによりコントローラーでHttpRequest処理時に必要な即時リターンが出来ます。以下はその例です。
@Controller public class JobLauncherController { @Autowired JobLauncher jobLauncher; @Autowired Job job; @RequestMapping("/jobLauncher.html") public void handle() throws Exception{ jobLauncher.run(job, new JobParameters()); } }
1.6. Advanced Meta-Data Usage
ここまで、JobLauncherとJobRepositoryインタフェースを解説してきました。共に、jobの起動と、バッチドメインオブジェクトの基礎的なCRUD操作を行います。
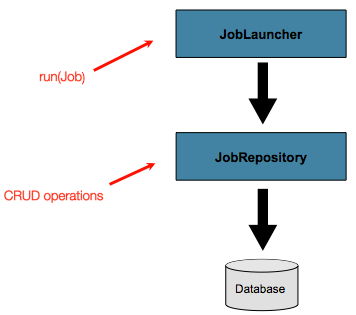
Figure 5. Job Repository
JobLauncherはJobExecutionの新規オブジェクトの生成と実行にJobRepositoryを使います。Jobの実行中、JobとStepの実装は実行の更新に同一のJobRepositoryを使います。基礎的な操作はシンプルなケースでは十分ですが、数百バッチジョブと複雑なスケジューリング要求の大規模なバッチ環境では、メタデータのより高度なアクセスが必要です。
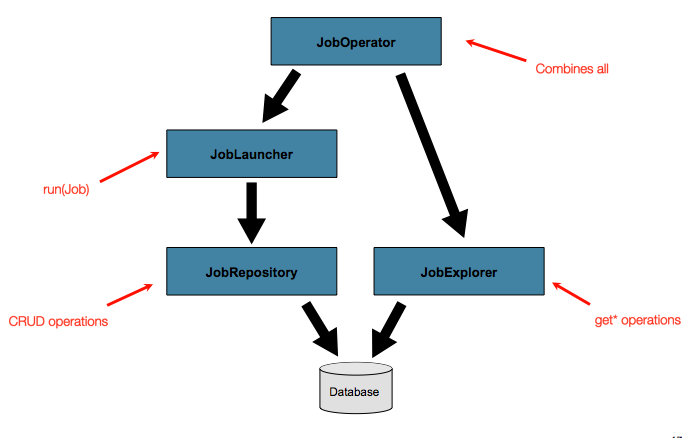
Figure 6. Advanced Job Repository Access
JobExplorerとJobOperatorインタフェースは以降で解説します。これらはメタデータの問い合わせと制御機能を持ちます。
1.6.1. Querying the Repository
高度な機能の前に知るべき基本的な事としては、このインタフェースは既存のexecutionsのリポジトリを問い合わせる機能があります。JobExplorerインタフェースが提供する機能は以下です。
public interface JobExplorer { List<JobInstance> getJobInstances(String jobName, int start, int count); JobExecution getJobExecution(Long executionId); StepExecution getStepExecution(Long jobExecutionId, Long stepExecutionId); JobInstance getJobInstance(Long instanceId); List<JobExecution> getJobExecutions(JobInstance jobInstance); Set<JobExecution> findRunningJobExecutions(String jobName); }
上のメソッドシグネチャの通り、JobExplorerはJobRepositoryのリードオンリーバージョンで、JobRepositoryのように、factory beanを使用して設定します。
Java Configuration
... // 以下はBatchConfigurerの実装内に置くものとする。 @Override public JobExplorer getJobExplorer() throws Exception { JobExplorerFactoryBean factoryBean = new JobExplorerFactoryBean(); factoryBean.setDataSource(this.dataSource); return factoryBean.getObject(); } ...
このチャプター前半で、バージョンやスキーマが異なる場合に備えてJobRepositoryのテーブルプレフィクスは変更可能、と説明しました。JobExplorerもそれらのテーブルを参照するので、こちらでもプレフィクスを設定する必要があります。
Java Configuration
... // 以下はBatchConfigurerの実装内に置くものとする。 @Override public JobExplorer getJobExplorer() throws Exception { JobExplorerFactoryBean factoryBean = new JobExplorerFactoryBean(); factoryBean.setDataSource(this.dataSource); factoryBean.setTablePrefix("SYSTEM."); return factoryBean.getObject(); }
1.6.2. JobRegistry
JobRegistry(と親インタフェースJobLocator)は必須では無く、コンテキストで利用可能なjobをトラッキングしたい場合に有用です。別のアプリケーションコンテキスト(子コンテキストなど)で作られるjobがある場合、そうしたjobを集中管理する場合にも有用です。カスタムのJobRegistryであれば登録済みjob名とその他プロパティを操作できます。フレームワークの提供する実装は1つだけで、これはjob名からjobインスタンスというシンプルなmapベースです。
@EnableBatchProcessingを使う場合、JobRegistryは特に設定無く使えます。自前の設定をするには以下のようにします。
// @EnableBatchProcessingで提供するクラスなので、SimpleBatchConfigurationのgetterを // オーバーライドでカスタマイズが可能。 @Override @Bean public JobRegistry jobRegistry() throws Exception { return new MapJobRegistry(); }
自動的にJobRegistryを処理するには2つの方法があり、bean post processorとregistrar lifecycle componentです。これらは以降のセクションで解説します。
JobRegistryBeanPostProcessor
bean post-processorですべてのjobが生成後にそれらを登録します。
Java Configuration
@Bean public JobRegistryBeanPostProcessor jobRegistryBeanPostProcessor() { JobRegistryBeanPostProcessor postProcessor = new JobRegistryBeanPostProcessor(); postProcessor.setJobRegistry(jobRegistry()); return postProcessor; }
Although it is not strictly necessary, the post-processor in the example has been given an id so that it can be included in child contexts (e.g. as a parent bean definition) and cause all jobs created there to also be registered automatically.
AutomaticJobRegistrar
子コンテキストを作成し、job作成時にそのコンテキストのjobを登録するライフサイクルコンポーネントです。この利点は、子コンテキストのjob名はレジストリ内でグローバルに一意ですが、その依存性は"natural" nameを持つ場合があります。たとえば、複数のXML設定ファイルがそれぞれ1つだけJobを持ち、同一のbean名、例えば"reader"、でItemReaderのそれぞれ異なる定義を持つ場合です。これらのXMLファイルを同一コンテキストにインポートすると、reader定義はクラッシュして別の定義をオーバーライドしてしまいますが、automatic registrarではこれを回避します。これにより、アプリケーションの分割モジュール由来のjobを簡単に統合できます。
Java Configuration
@Bean public AutomaticJobRegistrar registrar() { AutomaticJobRegistrar registrar = new AutomaticJobRegistrar(); registrar.setJobLoader(jobLoader()); registrar.setApplicationContextFactories(applicationContextFactories()); registrar.afterPropertiesSet(); return registrar; }
このregistrarは2つの必須プロパティがあり、1つはApplicationContextFactory(ここでは簡易的にfactory beanから生成している)の配列で、もう1つはJobLoaderです。JobLoaderは子コンテキストのライフサイクル管理とJobRegistry内のjob登録を担当します。
ApplicationContextFactoryは子コンテキスト生成の責務があり、最も一般的な使用法は上述のClassPathXmlApplicationContextFactoryとしてです。このファクトリの機能の1つは、デフォルトでは、設定のいくつかを親コンテキストから子にコピーします。よって、親と同じ設定を使いたい場合、子でPropertyPlaceholderConfigurerやAOP設定を再定義する必要がありません。
必要に応じてAutomaticJobRegistrarをJobRegistryBeanPostProcessorと組み合わせて使用可能です(DefaultJobLoaderを使用する場合に限る)。メインの親コンテキストにも子にもjobを定義する場合、こちらが望ましい場合があります。
1.6.3. JobOperator
上述の通り、JobRepositoryはメタデータのCRUD操作を提供し、JobExplorerはメタデータのリードオンリーの操作を提供します。これらの操作の組み合わせは、バッチオペレータがよく行うJobの停止・リスタート・サマライズなどの、一般的なモニタリングタスクの実行に有用です。Spring Batchはその種の操作をJobOperatorで提供します。
public interface JobOperator { List<Long> getExecutions(long instanceId) throws NoSuchJobInstanceException; List<Long> getJobInstances(String jobName, int start, int count) throws NoSuchJobException; Set<Long> getRunningExecutions(String jobName) throws NoSuchJobException; String getParameters(long executionId) throws NoSuchJobExecutionException; Long start(String jobName, String parameters) throws NoSuchJobException, JobInstanceAlreadyExistsException; Long restart(long executionId) throws JobInstanceAlreadyCompleteException, NoSuchJobExecutionException, NoSuchJobException, JobRestartException; Long startNextInstance(String jobName) throws NoSuchJobException, JobParametersNotFoundException, JobRestartException, JobExecutionAlreadyRunningException, JobInstanceAlreadyCompleteException; boolean stop(long executionId) throws NoSuchJobExecutionException, JobExecutionNotRunningException; String getSummary(long executionId) throws NoSuchJobExecutionException; Map<Long, String> getStepExecutionSummaries(long executionId) throws NoSuchJobExecutionException; Set<String> getJobNames(); }
上記の操作はJobLauncher, JobRepository, JobExplorer, JobRegistryなど多数の異なるインタフェース由来のメソッドを集約したものです。よって、JobOperatorの実装、SimpleJobOperatorは多数の依存性を持ちます。
/** * このbeanにインジェクトされるすべての依存性は@EnableBatchProcessingが作成する。 */ @Bean public SimpleJobOperator jobOperator(JobExplorer jobExplorer, JobRepository jobRepository, JobRegistry jobRegistry) { SimpleJobOperator jobOperator = new SimpleJobOperator(); jobOperator.setJobExplorer(jobExplorer); jobOperator.setJobRepository(jobRepository); jobOperator.setJobRegistry(jobRegistry); jobOperator.setJobLauncher(jobLauncher); return jobOperator; }
※ job repositoryにテーブルプレフィクスを設定する場合、忘れずにjob explorerにも設定してください。
1.6.4. JobParametersIncrementer
JobOperatorの大半は見たままの挙動です、詳細についてはavadoc of the interfaceにあります。ただし、startNextInstanceには注意が必要です。このメソッドは常にJobの新規インスタンスを開始します。JobExecutionに致命的な問題が発生して最初からJobをやり直したい場合に特に有効です。しかし、JobLauncherがパラメータが前回とは異なる場合に新規JobInstanceを開始する新規のJobParametersを必要とするのとは違って、startNextInstanceメソッドは、新規インスタンスをJobに強制するために、Jobに紐付くJobParametersIncrementerを使用します。
public interface JobParametersIncrementer { JobParameters getNext(JobParameters parameters); }
JobParametersIncrementerの責務は、与えられたJobParametersを使用し、これに含まれる何らかの必須の値をインクリメントして'次の'JobParametersオブジェクトを返します。これは、'次の'インスタンスを作るのにJobParametersの何を変更すれば良いのかをフレームワークが知らない場合に有用です。たとえば、JobParametersにdateが1つだけの場合、次回のインスタンスを作る必要がありますが、1日進めるのか、それとも1週間でしょうか。Jobの識別に何らかの数値を使う場合にも同じことが言えます。以下がその例です。
public class SampleIncrementer implements JobParametersIncrementer { public JobParameters getNext(JobParameters parameters) { if (parameters==null || parameters.isEmpty()) { return new JobParametersBuilder().addLong("run.id", 1L).toJobParameters(); } long id = parameters.getLong("run.id",1L) + 1; return new JobParametersBuilder().addLong("run.id", id).toJobParameters(); } }
この例では、'run.id'キーをJobInstancesの識別に使います。JobParametersがnullの場合、Jobをまだ一度も実行していないと見なして初期値を返します。そうでない場合、古い値を取得し、1増やして返します。
ビルダーのincrementerメソッドでJobにincrementerを関連付けします。
@Bean public Job footballJob() { return this.jobBuilderFactory.get("footballJob") .incrementer(sampleIncrementer()) ... .build(); }
1.6.5. Stopping a Job
JobOperatorのよくある使い方の一つはJobのgracefullyな停止です。
Set<Long> executions = jobOperator.getRunningExecutions("sampleJob");
jobOperator.stop(executions.iterator().next());
即時シャットダウン強制する手段がないので、即時シャットダウンはしません。フレームワークの制御下に無いビジネスサービスなど開発者のコードを実行中の場合は特にそうです。しかし、制御がフレームワークに戻り次第、StepExecutionにBatchStatus.STOPPEDをセットしてセーブし、JobExecutionにも終了前に同様の処理をします。
1.6.6. Aborting a Job
FAILEDのjob実行はリスタート可能です(Jobがrestartableの場合)。ABANDONEDのjob実行はフレームワークによるリスタートは出来ません。なお、ABANDONEDはリスタートしたjob実行内でstep実行をskippableにするのにも使います。もし以前に失敗したjob実行でABANDONEDとなったstepがある状態でjob実行する場合、その次のstep(jobフロー定義とstep実行完了ステータスが決定する)に移行します。
プロセスが死んだ("kill -9"やサーバエラー)場合、当然そのjobは動作していませんが、プロセスが死ぬ前に誰もJobRepositoryに通知しないのでそのことを知る術がありません。失敗かアボート(ステータスをFAILEDかABANDONEDに変更)のどちらにするかを決めて手動更新する必要があります。これは運用判断で自動決定は出来ません。restartableでは無いか、リスタートデータがvalidであると判断出来れば、FAILEDに変更します。job実行をアボートするにはSpring Batch Admin JobServiceユーティリティを使います。
