Pytorchスタイルになって書きやすくなったFlaxの新API「NNX」の使用感の確認のため、ALE/Breakout(ブロック崩し)向けにDQNを実装しました。
Jaxとは?
JAXとはGoogleによって開発されている高性能数値計算ライブラリであり、「①NumPyの使いやすさ + ②柔軟な自動微分 + ③マルチCPU/GPU/TPUでの分散並列コンピューティング」をシンプルな記述で実現します。
①Numpyの使いやすさ
JAXはNumpyスタイルのAPIを提供するため、NumPyに慣れている人なら非常に簡単に使い始めることができます。。

②柔軟な自動微分
JAXであればNumPyでは不可能な関数の自動微分が可能です。もちろんTensorflowやPytorchでも自動微分は可能ですが、TensorFlowのtf.GradientTapeやPyTorchのloss.backward()が計算グラフを構築し、そのグラフを遡って勾配を計算するのに対し、JAXのgradは「関数を受け取り、その関数の勾配を計算する新しい関数を返す」という純粋な関数変換として動作するため、シンプルかつ柔軟な記述が可能となります。

例えば、jaxでは高階微分を非常にシンプルに記述できます。深層学習ではあまり役立ちません*1が、物理シミュレーションや高度な最適化手法の研究においては強力な記法です。

③マルチCPU/GPU/TPUでの分散並列コンピューティング
JAXは大規模分散並列コンピューティングを前提として設計されているため、マルチデバイスの恩恵を容易に享受することができます。
最も簡単には関数を@jax.jitでラップしてしまえば、あとはXLAコンパイラが「内部処理をどのように分割(パーティション化)するか」「デバイス間の通信をどのようにコンパイルするか」を自動的に解決し並列処理を実現してくれます。
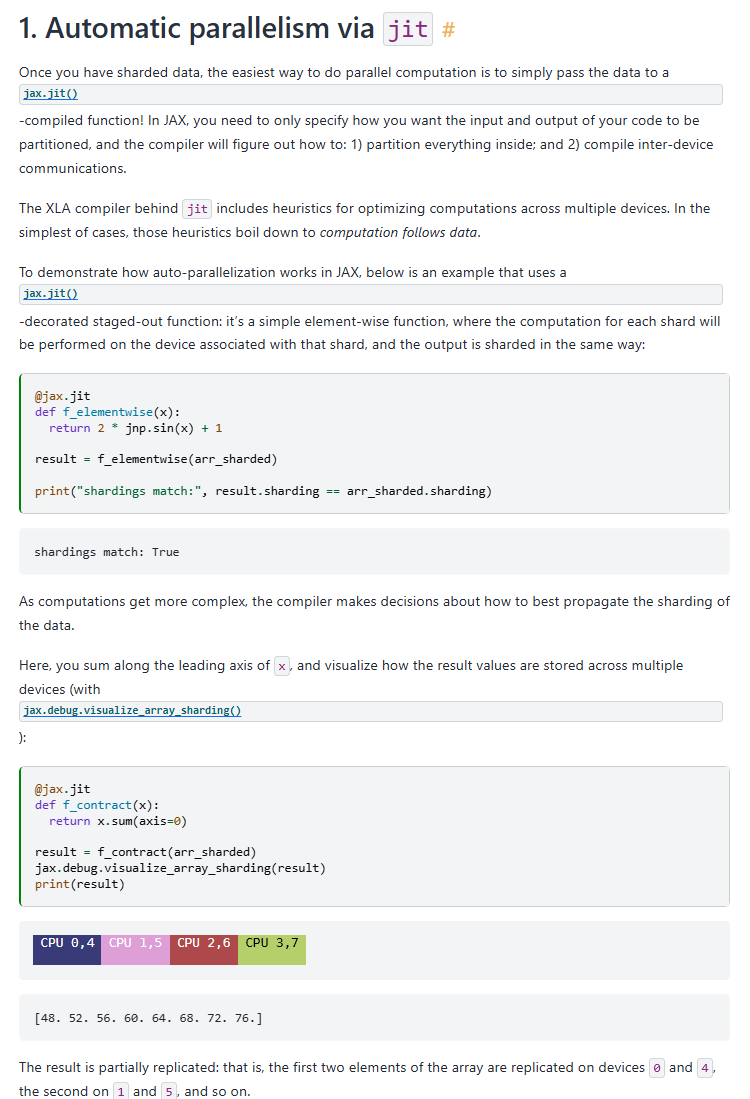
もちろん上記のような自動並列化だけでなく明示的な分割による高度な並列化を行うことも可能です。たとえば以下のチュートリアルではデータパラレル(4分割)とモデルパラレル(2分割)を組み合わせた複雑な分散処理を比較的シンプルな記述で実現しています。
Distributed arrays and automatic parallelization — JAX documentation
Flax NNXとは?
jaxは「Tensorflow vs Pytorch vs Jax」みたいなタイトルでよくtfやtorchと比較されていますが、jaxはあくまで自動微分つき数値演算ライブラリであり深層学習フレームワークではありません。ディープラーニングをやりたい場合、基本的にはjaxをベースとした深層学習フレームワークであるFlaxを使うこととなります
PyTorchスタイルになったFlaxの新しいAPI
Flaxは旧Google research(現Google Deepmind)によって2020年にリリースされたjaxベースの深層学習フレームワークです。
FlaxはJaxを開発するGoogle Research発という背景からエコシステムにおける深層学習フレームワークの大本命となるはずでした。しかし、旧API (Flax Linen API)では関数型の思想があまりにも強く書き味の癖が強かったため他フレームワークからのユーザー流入を獲得できずにいたため、大幅なテコ入れとして2024年にFlaxの新たなAPIであるNNXがリリースされました。Flax NNXという名前からも明らかですが、torch.nn スタイルの記法を踏襲しているため、Pytorchユーザーやtensorflowのsubclassing API ユーザーであれば非常に簡単に使い始めることができます。

jaxエコシステムにおける有力な深層学習フレームワークとして他にDeepMindのhaikuがありましたが、Google Deepmindの発足に伴って機能追加を停止しFlaxを推奨化したことにより、2025年現在ではjaxでディープラーニングするならほぼFlax一択という状況になったかと思います。
余談: Flax NXXまでの経緯
前述のとおり、JAXは数値演算ライブラリであり深層学習フレームワークではありません。
PyTorchやTensorFlowが「モデルの作り方 (nn.Module)」や「訓練ループの作法」まで提供する「全部入り」なのに対し、JAXは強力な計算部品を提供するだけで、モデルをどう作りどう管理するかは完全にユーザーに委ねています。その結果、深層学習フレームワークが乱立する状況が最近まで続いていました。
Flax (Google research):
パラメータは外部の辞書で管理。状態管理も明示的で関数型の思想に忠実だがコーディングがヤバいくらい煩雑*2。Haiku (Deepmind):
PyTorchのようなオブジェクト指向でパラメータ管理を暗黙的に行う。tf sonnetのjax版といった感じで書きやすい。Equinox (Patrick Kidger氏による個人開発):
モデル自体がパラメータを含むPyTreeで最もJAXのデータ構造に忠実。書きやすい。
とくにFlaxとHaikuの内ゲバが完全にjax普及の足を引っ張ってた感があります。最近Google ResearchとDeepMindが統合されてGoogle Deepmindになったことでようやくカオス状態から脱出したため、安心してFlaxを使っていけるようになりました。
なぜ強化学習にJax/Flaxを使うのか?
強化学習のコンテクストにおいてJaxを導入するモチベーションは2つあります。
大規模言語モデル向け強化学習
近年の発展著しい「大規模言語モデルの強化学習チューニング」においては、1GPUに乗り切らない巨大なモデルを複数のGPUに分割して訓練する高度な分散並列コンピューティングが必要となります。このような分散並列コンピューティングはPytorchやTensorflowにもAPIがあるものの、(偏見だけど)明らかに後付けであり無理している感が否めません。一方で後発ライブラリであるjaxは前述のとおり高度な分散並列処理を比較的シンプルな記述で実装することができます。これはLLM向けの強化学習において非常に重要な特性です。
参考: 分散学習基礎講座
フィジカルAI(AIロボティクス)
LLMと同様に近年発展著しい「フィジカルAI」(AIの物理世界への干渉を可能とする試み)、大雑把に言うとAIロボティクス分野では、しばしば何らかの物理シミュレーションを伴います。ここで、物理シミュレーションをJaxで実装することによりm環境そのものが微分可能になり報酬シグナルの逆伝播に基づいて方策ネットワークを直接最適化することができます。
「映像も物理も、微分可能になるとすごいことが起きる」ということの意味を文系にもわかるように説明しようと試みる – WirelessWire News
微分可能なシミュレータ上での方策最適化 - Preferred Networks Research & Development
とはいえ、微分可能プログラミングは正直なところ最近は盛り下がっている感があるので今後に期待。 まあシミュレータ使わなかったとしても、ロボットだとニューラルネットとは別に勾配ベースの最適化計算がいろいろ走る気がするので、GPUで容易に大規模高速微分ができるJaxは採用メリットあるような気がする(ロボットは門外漢なので適当)。
DQN(Deep-Q-Network)の実装
前置きが長くなってしまいましたがFlaxの新しいAPIであるFlax NNXの使用感を確かめるためDQNを実装します。 アルゴリズムの詳細解説はしないので、The Deep Q-Learning Algorithm - Hugging Face Deep RL Courseなどを参照ください。
実装全文:
https://github.com/horoiwa/rl-with-flax-nnx/blob/main/src/dqn.pygithub.com
DQNとは
DeepMindのDQN(2013)とは古典強化学習アルゴリズムのQ学習に深層学習を導入することにより、Atari環境(レトロゲーム環境)において、ゲーム画面のみを入力としたアルゴリズムとしては初めて人間レベルのパフォーマンスを達成し、「深層強化学習」という分野を切り開いたエポックメイキングな手法です。
深層強化学習を学ぶという観点では重要な手法ではあるものの、AdamやらBatchNormalizationやらの深層学習安定化テクニックが普及する前の手法ゆえに、論文通りに実装すると学習がかなり不安定かつ遅いです。このため今回はDQN論文に忠実に実装していないことに留意ください。
Jax(GPU版)/Flaxのインストール
PytorchでもTensorflowでもGPU環境の初期構築には苦労する印象ですが、GPU版Jaxは「最新のNVIDIA GPU Driverがインストール済み」かつ「CUDAが未インストール」の「Linux/WSL2環境」であれば pip install --upgrade "jax[cuda12] flax orbax" だけでインストール可能です。

jax.devices()でCudaDeviceが表示されればOK。
>>> import jax >>> jax.devices() [CudaDevice(id=0)]
NVIDIA GPU Driverについて、WSL2の場合はホストWindows側にインストールされていればOKっぽい。Linuxの場合は頑張って自力インストールしましょう。私はめんどくさかったのでGCPでNVIDIA GPUドライバプリインストール済みUbuntuイメージ(Ubuntu 24.04 LTS Accelerated)を使ってスポットVMを作成しました。
令和最新版:Atari環境の構築
次に強化学習の標準ベンチマークとして使用されているAtari(Arcade Learning Environment: ALE)環境を構築します。

以前までは、OpenAI GymからAtari環境を利用していたのですが、紆余曲折ありOpenAI Gymは更新終了したため、引継ぎ先であるGymnasiumをインストールします。
>>> pip install "gymnasium[atari,other]" opencv-python
NOTE: gymnasium[accept-rom-license] は最新バージョンでは不要*3。
NOTE: 依存解決がうまくいっていないっぽく、opencv-pythonを明示的にインストールしないとUbuntu環境ではlibGL.so.1: cannot open shared object file: No such file or directoryというエラーが発生。上記のopencv直接インストールでもダメならapt update && apt install libgl1。
Gymnasiumは強力なWrapperを揃えており、Atari環境向けには以下のようにWrapperをネストして適用すると前処理(リスケールとかグレスケ化とか)や一定エピソードごとの動画記録などを自動でやってくれて便利。
Environments - ALE Documentation
List of Wrappers - Gymnasium Documentation
フレームスタックWrapperはPytorchのスタイルに従ってChannel First形式(CHW)でStackする。JaxとTensorflowはChannel Lastなので継承してHWCに修正していることに留意。
NOTE: import ale_py をimport gymnasium as gymより先に記述しないと「ROMが見つからない!!」と怒られることがある。そのうち修正されるはず。
モデルの定義
flax.nnxでDQN-CNNを定義したのが以下のコード。Pytorchとの間違い探しみたいですが、わかりやすい違いはすべてのレイヤーが乱数シードrngs: nnx.Rngsを引数として要求する点でしょう。ちょっと面倒かもですが、実験の再現性が確実に保証されるメリットは大きいです((厳密にやるならトレーニングループ内のε-greedy選択でも標準ライブラリ(random.random)を使うのではなくjax.randomで乱数生成すべき))。
ロスの定義

ロスの定義方法についてはjaxの関数型プログラミングの思想が反映されているためPytorchとはだいぶ雰囲気が異なります。
具体的には勾配計算の対象となるnnx.Moduleだけを引数にとるロス関数(loss_fn)を定義し、これをnnx.value_and_gradでラップすると戻り値としてロスと勾配を返す関数となります。なお、nnx.Module以外に必要なデータは関数の外側から渡す必要があるため高階関数としてtrain_stepを定義します。好みが分かれるかもですが、私はこの記法わかりやすくて好きですよ。
加えて、とても地味ながら特筆すべきは以下の一行。
q_values_selected = q_values[jnp.arange(len(data["actions"])), data["actions"]]
そうです、jax/flaxではnumpyとほぼ同等のFancy Indexingが利用可能なため、tf.gather_ndとかtorch.gatherによるパズルを解かなくてよいのです。これはありがたい。
トレーニングループの実装
サンプル収集しながら4ステップ(16フレーム)ごとにネットワーク更新するだけ。収集したサンプルはlz4で圧縮してReplayBufferに保持するようにしてあるので数GBのRAMで問題なく実行可能です。
ここで、jaxの関数型スタイルの良さをtarget_networkとonline_networkの重み同期処理から垣間見ることができます。
"""Copy weights from online network to target network."""
_graphdef, _state = nnx.split(online_network)
nnx.update(target_network, _state)
nnx.splitにより、nnx.Moduleをグラフ定義(_graphdef)と内部状態(_state)に分割することができるため、あとは取り出した内部状態でtarget_networkを上書きすれば2つのネットワークが完全に同期されます。
学習結果
GCPのvCPU:2 RAM:13GB GPU: T4のVMで12時間くらいかけて2Mステップの学習を行いました。
2Mステップの学習でも最大300点くらいとれており、DQN論文では50Mステップ*4学習して400点くらいであることから、問題なく再現できていると判断できます。

Jax/Flax.NNXでDQNを実装。NNXではPytorchの書き味とJaxのパフォーマンス&スケーラビリティが両立されてていい感じ pic.twitter.com/CLGSP6w2FB
— めんだこ (@horromary) July 5, 2025
ちなみに参考まで、一般的な教師あり学習とは異なり深層強化学習(Q学習)では獲得報酬の増大に伴ってlossがだんだん大きくなっていきます。

次:PPO
*1:深層学習はパラメータ多すぎて二次以上の微分は計算量的に無理なため
*2:本質的に状態の塊であるDeepLearningで関数型原理主義をやるとコードがクッソ煩雑になるのは不可避なのである
*3:We have remove pip install "gymnasium[accept-rom-license]" as ale-py>=0.9 now comes packaged with the roms meaning that users don't need to install the atari roms separately with autoroms.
Gymnasium Release Notes - Gymnasium Documentation
*4:frameskip=4設定なので実フレームでは200Mステップとなる
