はじめに
この記事では、大容量の機械学習モデルを動かすAWSサーバレスアーキテクチャのモデルケースと、その構築方法を紹介します。
対象とする読者は、次のような思いを持つ方です。
- 大容量モデルをサービス上で運用したい
- 機械学習系のサービスを安く運用したい
- 機械学習モデルを開発する人と、利用する人の開発領域を分けて運用したい
- 何でもいいからサクッとBERTモデルを運用にのせてみたい
大容量モデルをのせたサーバレスアーキテクチャを考える
Lambdaは使えない
もしあなたが「内部で機械学習モデルを利用するWebサービス」をAWSで設計するとしたら、どんなシステム構成にしますか。
多くの人がまず思い描くのは、APIとして利用するLambda内で機械学習モデルを用いる構成だと私は思います。

たとえば上図のように、S3にホスティングしたWebページなどのクライアントから、API Gatewayを通してLambdaを実行する構成です。
AWSの公式ハンズオン資料でも、SageMakerでデプロイしたモデルをAPIで利用する方法として、このLambdaを用いた構成が紹介されています。
しかし、Lambdaにアップロードできるパッケージには制限があるため、大容量モデルはパッケージに含めることができません。
S3に大容量モデルを格納してLambdaで読み込む方法も考えられます。
しかし、残念ながらLambdaの関数内で使えるローカルストレージにも512MBまでという制限があるため、モデルのロードができません。
そのため、Lambda内で大容量モデルを用いる手法は、現状使えません(おそらく今後も)。
では、大容量モデルを組み込むAPIの構成は、どんな設計がいいのでしょうか。
いくつか考えられますが、私が推したいのはAWS Elastic Beanstalk(以降、EB)とAmazon Elastic File System(以降、EFS)を用いる方法です。
EBとEFSを使う
EBは、ユーザーが用意したソースコードに合わせて、サーバ運用に必要な設定(ロードバランサーやAuto Scalingなど)をしたEC2インスタンスを構築・管理できるサービスです。
デプロイしたコード群はS3に保存され、以前の状態にrevertするのも簡単です。
複雑な設定はAWS側に任せて、とにかく手軽にサーバを構築・運用したい人にお勧めのサービスです。
またEFSは、NFSサーバのように、ネットワーク上でファイルを共有できるストレージを構築・管理できるサービスです。
たとえば、EFSファイルシステムで構築した共有ファイルストレージをEC2にマウントすれば、EC2インスタンス上でローカルストレージのように利用できます。
つまり、EBとEFSを使えば、大容量ローカルストレージを外付けしたEC2インスタンスがサクッと手に入るのです。
前節のLambdaを置き換えて下図のような構成にすれば、EC2で立ち上げるAPIサーバから、EFSの共有ファイルストレージに格納した大容量モデルを直接呼び出すことができます。
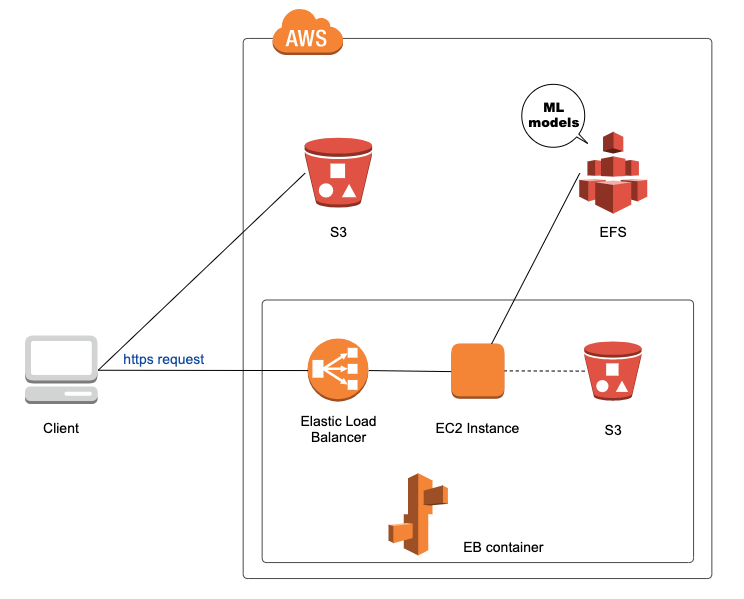
EFSを選んだ理由
本稿ではEFSをローカルストレージとして利用するシステム構成を紹介していますが、AWSには他にもAmazon Elastic Block Store(以降、EBS)を同様の機能に用いることができます。
ただ、EFSでは複数のEC2インスタンスからの同時アクセスが可能なのに対し、EBSは単一のインスタンスからのアクセスしか想定されていません。(参考)
EBSを利用する場合、モデルを利用するインスタンスごとに、モデルをアップロードする必要があります。
この運用は、モデルの管理が煩雑になる恐れがあります。
それに対してEFSを使えば、モデルの管理は楽になります。
モデルの開発者は常に決まったストレージにモデルをアップロードすれば良く、モデルの利用者は決まったストレージのモデルを参照すれば良いのです。
以上より、複数のインスタンスから同じモデルにアクセスする実際の業務運用を考慮して、今回はEFSを選びました。
大容量モデルをのせたサーバレスなAPIを作ろう
それでは、前節で紹介したEBとEFSを使って、大容量モデルを利用するAPIを構築してみましょう。
今回は「日本語で入力された文章同士の類似度をBERTモデルで計算して出力するAPI」を作ってみます。
基本的にはネット上で集められるリソースを使いますが、おそらくAWS無料利用枠に収まらない構成です。ご注意ください。
手順は次のとおりです。
- 手順1:大容量モデルを用意
- 手順2:APIを構築
- 手順3:EBに大容量モデル以外をデプロイ
- 手順4:EBで作成したEC2にマウントしたEFSの共有ファイルストレージに大容量モデルをアップロード
手順1:大容量モデルを用意
まずはモデルデータを手元に用意しましょう。
今回はyoheikikuta氏が公開しているBERTモデルとSentencePieceモデルを利用します。
次の手順のモデル管理ディレクトリで示すデータ(wiki-ja.txt以外)をダウンロードして、解凍しておいてください。
手順2:APIを構築
ダウンロードしたモデルを使って、文章の類似度を計算するAPIを構築します。
私の方でBERTの公式Githubリポジトリのexampleを利用したサンプルコードを用意しましたので、こちらをcloneまたはzipダウンロードしておいてください。
用意したサンプルは、次のようなディレクトリ構成になっています。
. ├── README.md ├── application.py ├── bert_script │ ├── extract_features.py │ ├── modeling.py │ ├── params.py │ ├── tokenization.py │ └── util.py ├── efs │ ├── config.json │ └── sp │ └── wiki-ja.txt └── requirements.txt
このディレクトリで、まずはローカルサーバを立ててみましょう。
はじめに、./efs に手順1で用意したモデルを配置します。
ひとまず、次のように各モデルを配置してください。
efs
├── config.json
├── model
│ ├── model.ckpt-1400000.data-00000-of-00001
│ ├── model.ckpt-1400000.index
│ └── model.ckpt-1400000.meta
└── sp
├── wiki-ja.model
├── wiki-ja.txt
└── wiki-ja.vocab
配置ができたら ./requirements.txt に書かれたパッケージをインストールし、./application.py を実行することで、ローカルのFlaskサーバが立ち上がります。
次に、立ち上がったFlaskサーバに対して、次のcurlコマンドを実行してみましょう。
$ curl -X POST -H "Content-Type: application/json" \ -d '{"target":"畳み込みの逆操作", "texts":["逆畳み込み", "転置畳み込み"]}' \ http://127.0.0.1:5000/sim
上記は、/simというルートに対して {"target":"畳み込みの逆操作", "texts":["逆畳み込み", "転置畳み込み"]} をPOSTで送信するコマンドです。
このコマンドを実行すると、次のようなレスポンスがFlaskサーバから返ってきます。
{ "context": { "sims": [ 0.8242325821278749, 0.7423576157777433 ], "target": "畳み込みの逆操作", "texts": [ "逆畳み込み", "転置畳み込み" ] }, "type": "sentence similarity" }
レスポンスには指定した文章(context.target)や、それに対する各文章(context.texts)の類似度(context.sims)などが含まれています。
これが返ってくれば、ひとまずFlaskサーバ内で動くコードの実行には問題がないはずです。
これらコードの詳しい説明は本稿の趣旨と異なるため避けますが、上記の curl リクエストを受け取り、そのレスポンスを返す処理の流れを表すコードだけ抜粋して解説します。
下記に抜粋したのは、FlaskでHTTPリクエストを制御する ./application.py というスクリプトのスニペットです。
class convert_to_simlarity: def __init__(self): self.output = {"target": None, "texts": None} def from_texts(self, target, texts): self.output["target"] = target self.output["texts"] = texts self.output["sims"] = self.texts2similarity() return self.output def texts2similarity(self): # get futures per sentence body = [self.output["target"]] + self.output["texts"] raw_features = get_futures(BERT_PRAMS, body) # extract "[CLS]" features cls_features = [] for raw_feature in raw_features: cls_feature = list( filter( lambda layer: layer["token"] == "[CLS]", raw_feature["features"] ) ) cls_features.append(cls_feature[0]) # compute cosine simlarity simlarities = calc_simlarity(cls_features[0], cls_features[1:]) return simlarities req = convert_to_simlarity() ################ ### omission ### ################ application = Flask(__name__) application.add_url_rule( "/sim", "similarity", ( lambda: jsonify( { "type": "sentence similarity", "context": req.from_texts( request.get_json()["target"], request.get_json()["texts"], ), } ) ), methods=["POST"], )
上記では、前半で定義するインスタンスオブジェクトが、後半でendpointとルーティングしたlambda関数に紐付けられています。
前半のインスタンスオブジェクトは、受け取った文章を埋め込み表現(数値ベクトル)に変換し、それらから類似度を計算する構成です。
ただし、[CLS] トークンを一つの文章全体の埋め込み表現として扱いました。
(この類似度の算出方法には議論があります。「BERT CLS similarity」などで検索してみてください)
また、類似度の計算にはコサイン類似度を用いています。
後半のルーティングは、Flaskのadd_url_ruleメソッドに沿った内容です。
/sim というルートのendpointでPOSTを受け取ると、lambda関数が発火するように設定されています。
この ./application.py を起点に、BERTモデルを用いた類似度の計算をするAPIが起動するわけですが、詳しくはコードを読んで確認みてしてください。
手順3:EBに大容量モデル以外をデプロイ
EBに efs ディレクトリ下にあるモデル類以外のファイルをデプロイします。
ただ今回用意しているサンプルでは、EBへデプロイする前に、説明の便宜上モデルのパスを変更します。
./bert_script/modeling.py に書かれたパスを、次のように変更しておいてください。
BERT_PRAMS = {
'vocab_file': '/efs/sp/wiki-ja.txt',
'model_file': '/efs/sp/wiki-ja.model',
'bert_config_file': '/efs/config.json',
'init_checkpoint': '/efs/model/model.ckpt-1400000',
...
}
パッと見て分かりづらいですが、相対パスから絶対パスに変更するだけです。
デプロイまでのプロセスは、次のAWS公式開発者ガイドに示されているので、そちらを参照してください。
その際、EB CLI を事前にインストールしておく必要があります。こちらの手順も公式の開発者ガイドを参照してください。
手順4:EBで作成したEC2にマウントしたEFSの共有ファイルストレージに大容量モデルをアップロード
EBで作成したEC2インスタンスに対してEFSの共有ファイルストレージをマウントし、そのストレージに efs ディレクトリ下にあったモデル類をアップロードします。
まずは公式の開発者ガイドに従って、EFSファイルシステムを作成します。
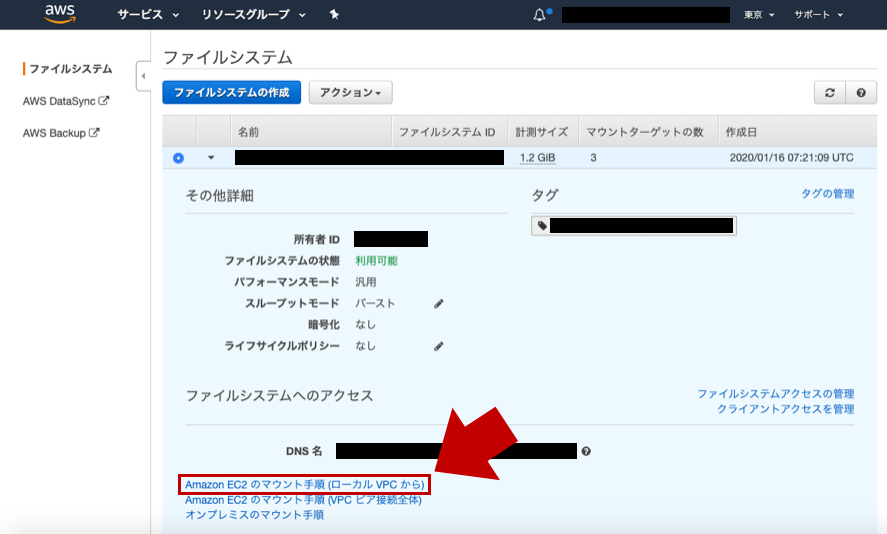
EFSファイルシステムを作成し終わったら、下図で示すリンクで表示されるモーダルを開いてください。
このモーダルに書かれた案内に沿って、EC2に共有ファイルストレージをマウントします。
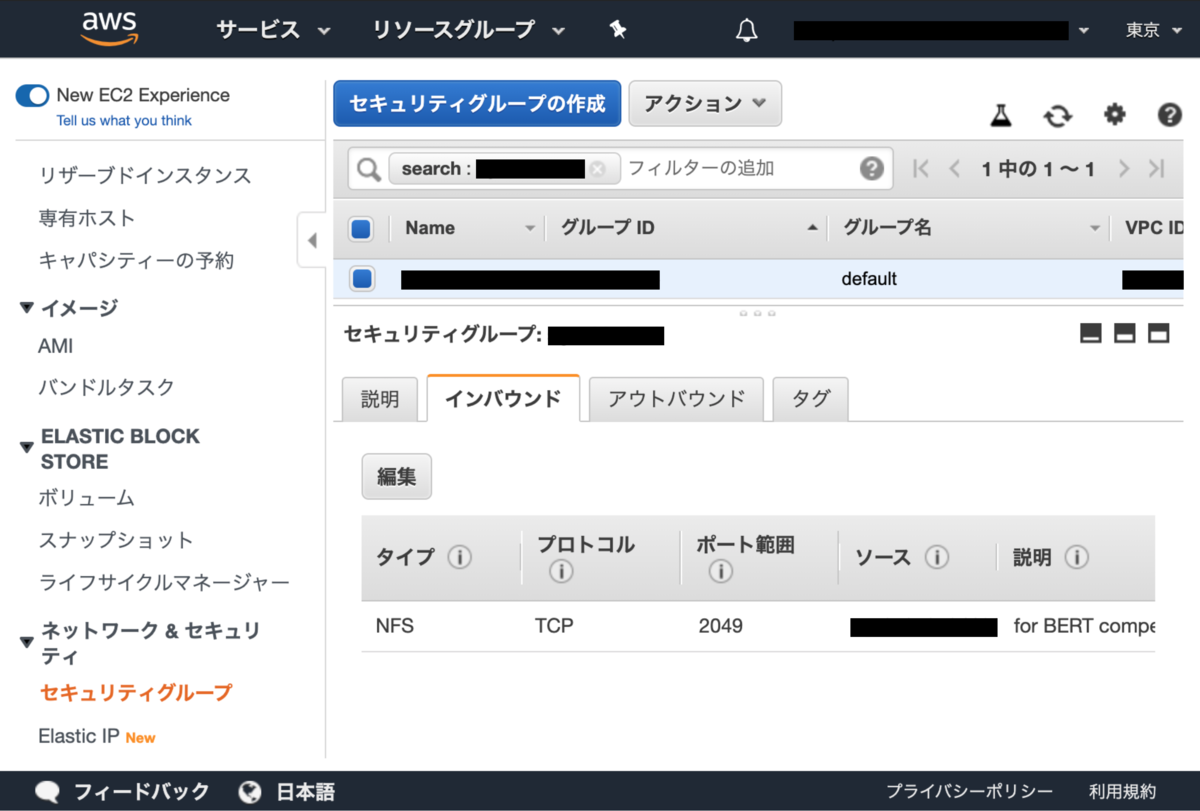
ただその前に、EC2からEFSのファイルストレージに接続できるように、セキュリティグループにルールを追加して、NFSポート(2049番ポート)へのインバウンドトラフィックを許可する必要があります。
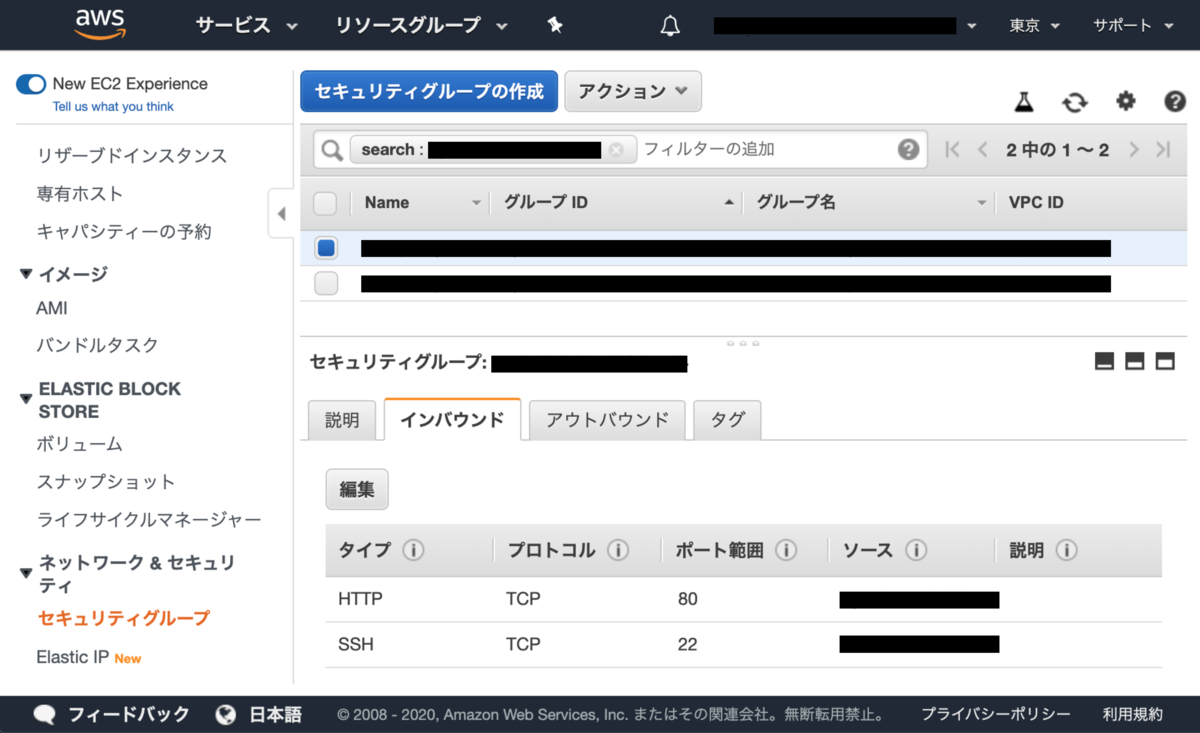
また、この後に自分のPCからEC2にssh接続するためのルールも追加します。SSHポート(22番ポート)にマイIPからのインバウンドトラフィックを許可しておきましょう。
もしこれまでEC2のキーペアを作成したことがない場合は、SSHポートの設定の前に、次のガイドに従って作成しておいてください。
さて、モーダルに書かれた案内に戻ります。補足を加えた手順が次の通りです。
1. EC2インスタンスにssh接続
EB CLIのeb sshコマンドを使うと楽に接続できるのでお勧め。
2. マウントに使う空のディレクトリを用意
ssh接続したEC2内で sudo mkdir efs コマンドを実行し、chmod 755 efs コマンドでパーミッションを解放しておく。
3. EFSマウントヘルパーをインストール
sudo yum install -y amazon-efs-utils コマンドを実行してインストール。
4. EFSマウントヘルパーでマウント
sudo mount -t efs fs-********:/ efs コマンドを実行してマウント。
上記の手順ができたら、ssh接続したまま df -h コマンドを実行してマウントできているか確認してみてください。
/efs に容量の大きなディスクがマウントされていれば、この手順は完了です。
ただ、EC2はAWSのメンテナンスなどで再起動されることがあり、このままでは再起動のたびにマウントし直すタスクが発生してしまいます。
その対応策として、自動マウントの設定をしておくと後々楽です。詳しくは、公式の開発ガイドを参照してください。
ここまでできたら、exit コマンドでログアウトしてしまってください。
最後にマウントした共有ファイルストレージにモデル類をアップロードします。
アップロードは scp コマンドで、モデル類を含んだ efs ディレクトリまるごと行います。
./efs ディレクトリ直下で、次のコマンドを実行してください。
$ scp -r \ -i [キーペアで設定した秘密鍵のパス (ex. ~/.ssh/***.pem)] \ . ec2-user@[public IP (ex. xxx.xxx.xxx.xxx)]:/efs
ちなみに秘密鍵のパスやpublic IPは、前に eb ssh コマンドを実行した直後のコマンドラインに表示されています。
ログを辿ってコピーしてしまいましょう。
以上で、EBとEFSを用いたシステム構成の構成に則った環境構築が完了です。お疲れ様でした。
実行テスト
構築したAPIサーバに対して、curlコマンドを実行してみましょう。
$ curl -X POST -H "Content-Type: application/json" \ -d '{"target":"畳み込みの逆操作", "texts":["逆畳み込み", "転置畳み込み"]}' \ http://app-name.***.region.elasticbeanstalk.com/sim
endpointとなるURLは、EBのアプリ管理画面から取得できます。
おわりに
本章では、AWSで大容量モデルを運用するサーバレスアーキテクチャと、その構築方法を示しました。
構築方法は、具体例として「日本語で入力された文章同士の類似度をBERTモデルで計算して出力するAPI」の開発する手順を紹介し、実践に即した内容にしました。
もちろん具体例で示した方法以外にも実装方法は色々あるので、皆さんの好みの方法で実装してみてください。
追記(2020/06/25)
LambdaにEFSをマウントできるようになったようです。
早速、利用してみたとの事例もありました。素晴らしい👏
