This is a summary of the GPT-2 paper "Language Models are Unsupervised Multitask Learners."
Introduction
The paper summarized here:
Language Models are Unsupervised Multitask Learners
- Published: February 2019
- OpenAI
- Code: GitHub - openai/gpt-2: Code for the paper "Language Models are Unsupervised Multitask Learners"
This is the GPT-2 paper.
The original GPT paper can be found here:
*All figures in this article are cited from the paper.
Note: This article was translated from my original post.
Language Models are Unsupervised Multitask Learners
Overview
- Background
- Natural language processing tasks have traditionally been solved using supervised learning
- Challenge
- Previous language models were essentially narrow specialists trained through supervised learning on specific domains
- Creating a generalist language model that works across broad domains had not yet been achieved
- What they did
- Created WebText, a web-scraped dataset
- Built a GPT model using unsupervised learning
- Trained on WebText
- Used byte-level BPE (Byte Pair Encoding)
- Architecture based on the original GPT with minor modifications
- The largest model (1.5B parameters) is called GPT-2
- Results
- Achieved results comparable to existing models on reading comprehension tasks without any additional training on labeled data
- Achieved state-of-the-art performance on 7 out of 8 language modeling benchmark datasets
- Demonstrated reasonable performance on other tasks as well
- Larger models consistently produced better results
Method
Creating the WebText Training Dataset
- WebText: A dataset created by scraping web pages linked from Reddit

- Even without explicitly preparing translation pairs as training data, the presence of such bilingual content within web pages means the model could potentially learn to handle translation tasks
BPE: Byte Pair Encoding
How should strings be encoded as input to the model?
Challenges:
- The conventional approach of treating Unicode strings as UTF-8 byte sequences doesn't perform well on word-level tasks
- BPE (Byte Pair Encoding), despite its name, is typically performed on Unicode code points rather than byte sequences
- When applying BPE to Unicode code points, the required vocabulary becomes enormous
- Byte-level BPE keeps the required vocabulary small (256 base tokens)
- However, applying BPE directly at the byte level doesn't optimize well
- Combinations of common words and punctuation get merged into single tokens inappropriately
Their solution:
- Byte-level BPE
- But with merges between different character categories prevented
This aims to achieve word-level performance while maintaining the generality of the byte-level approach.
Model Architecture
Based on the original GPT architecture with some modifications:
- Moved layer normalization to the input of each transformer sub-block
- Added an additional layer normalization after the final self-attention block
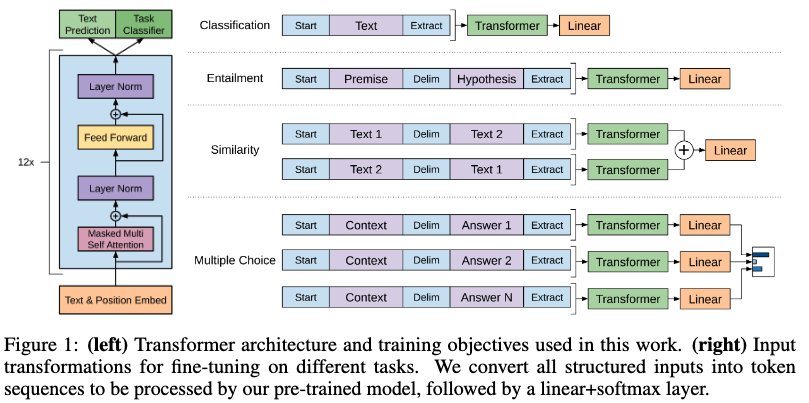
They also created models of multiple sizes. The largest model is called GPT-2.

Results
Language Modeling Tasks

- Achieved state-of-the-art on 7 out of 8 datasets
- Larger improvements were seen on smaller datasets
- WikiText2, PTB
- Significant improvements were also seen on datasets requiring long-range dependencies
- LAMBADA, CBT
- Poor results on 1BW (One Billion Word Benchmark)

- Larger model sizes consistently produced better results
Common Sense Reasoning Ability
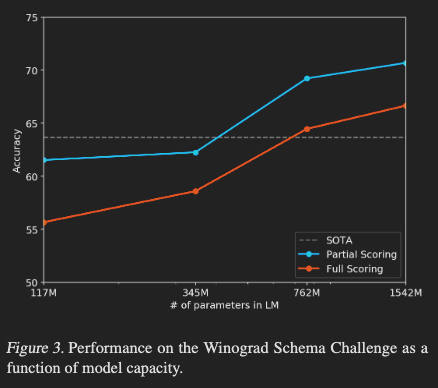
- Winograd Schema Challenge: Measures common sense reasoning ability through pronoun disambiguation in sentences
- Achieved state-of-the-art performance
Reading Comprehension
Tested on Conversation Question Answering (CoQA).
- Achieved 55 F1 score
- Results matched or exceeded 3 out of 4 baseline systems
- Without any additional training on question-answer pairs
- State-of-the-art is a BERT-based model with 89 F1 score, close to human performance
Summarization Tasks

- Results not significantly better than existing models
- Tends to focus on recent content without properly understanding details
Translation Tasks
| Task Set | GPT-2 Results |
|---|---|
| WMT-14 English-French | 5 BLEU |
| WMT-14 French-English | 11.5 BLEU |
- WMT-14 English-French results are slightly lower than existing unsupervised models
- WMT-14 French-English results are better than many unsupervised baselines but lower than the unsupervised state-of-the-art
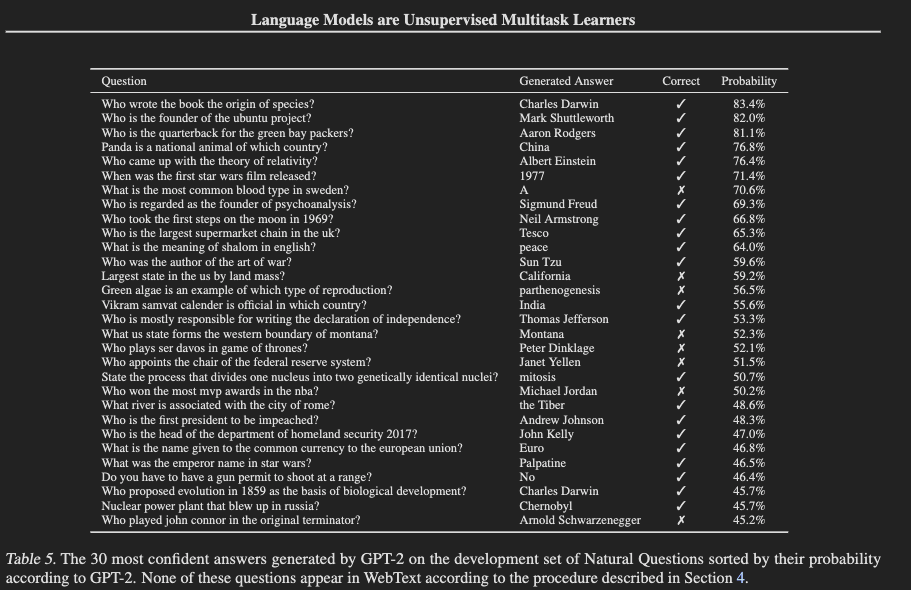
QA Tasks
How well can it answer factual questions?
- Dataset: Natural Questions
- GPT-2 accuracy: 4.1% (exact match evaluation)
- Better than the smallest model's results (below 1%), suggesting that increasing model size could improve performance
- Existing QA systems combining information retrieval achieve 30-50%
- GPT-2's results are significantly lower
Generalization vs Memorization
Are these results truly due to GPT-2's generalization ability? Or is it solving tasks through memorization because of overlap between training and test datasets? Since WebText is a massive collection of diverse web pages, this is a valid concern.
They investigated this question.

- Examined overlap between training data (WebText) and each test dataset using 8-gram Bloom filters
- WebText overlap ranges from about 1-6%
- Average of 3.2%
- Training data for each test dataset itself has an average 5.9% overlap with test sets
- WebText actually had less overlap than typical benchmark training sets
Conclusion/Thoughts
That's my summary of the paper "Language Models are Unsupervised Multitask Learners."
Below are my personal notes:
- What are the authors trying to achieve?
- Demonstrate the general language capabilities of models through unsupervised learning and zero-shot transfer
- What are the key elements of their approach?
- Creating high-quality web-scraped data: WebText
- Scaling up model size and using unsupervised learning
- Byte-level BPE
- Which cited papers would I like to read next?
- Thoughts
- While the original GPT relied on fine-tuning, GPT-2 demonstrates strong capabilities through unsupervised learning without fine-tuning. Combined with subsequent work on scaling laws, it's fascinating to see the beginning of the era of "just make models bigger and performance improves"—at least in these early stages.
[Related Articles]
