This is a summary of the seminal paper "Attention Is All You Need," which introduced the Transformer architecture.
Introduction
I decided to read the famous "Attention Is All You Need" paper properly, as I had never worked through the original paper in detail before.
- Version 1 published June 12, 2017
- Google Brain / Google Research
- Code: tensor2tensor/tensor2tensor/models/transformer.py at master · tensorflow/tensor2tensor · GitHub
All figures in this article are cited from the paper above.
Note: This article was translated from my original post.
Attention Is All You Need
Overview
- Background
- Sequence transduction models traditionally used encoder-decoder architectures with RNNs or CNNs
- Attention mechanisms were also being used to some extent
- Challenge
- Training was difficult due to the sequential nature preventing parallelization
- What they did
- Created a model using only attention mechanisms, without RNNs or CNNs
- Enables parallel training
- Named it the Transformer
- Created a model using only attention mechanisms, without RNNs or CNNs
- Results
- Achieved state-of-the-art performance on translation tasks
- Also achieved strong results on English constituency parsing
- Demonstrated strong generalization performance
Method
Model Architecture

- Encoder
- Number of layers N = 6
- Norm: Layer normalization
- Decoder
- Number of layers N = 6
- The masking in Masked Multi-Head Attention ensures that attention only considers tokens at previous positions
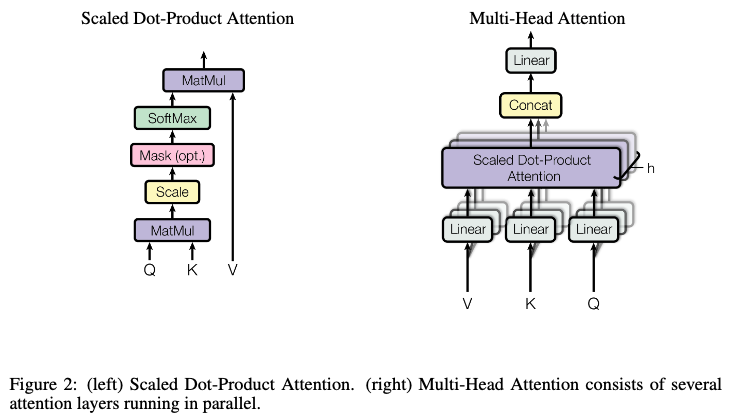
- Scaled dot-product attention was chosen over additive attention for computational efficiency
- While both have similar theoretical complexity, dot-product attention is faster and more memory efficient in practice due to optimized matrix multiplication implementations
- Scaling is applied because dot-product values grow large as the key dimension increases
- Multi-Head Attention uses h = 8 heads
Training Method
- Used 8 NVIDIA P100 GPUs
- 12 hours to train the base model
- 3.5 days to train the big model
- Optimizer
- Adam optimizer
- Regularization
- Residual Dropout
- Label Smoothing
Results
Translation Tasks
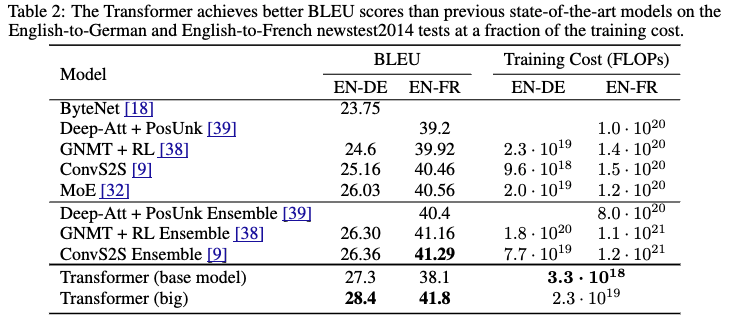
- Transformer (big) outperformed existing models on both English-to-German and English-to-French translation tasks
- Transformer (base) also surpassed existing models on the English-to-German translation task
- Training cost was lower than existing models
Transformer Model Variations
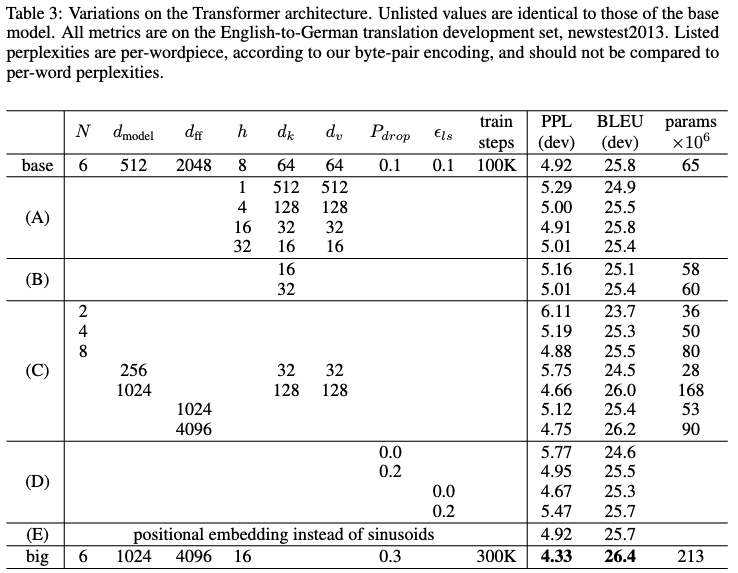
- (A): Varying the number of attention heads
- Single-head attention showed poor results (perplexity, BLEU)
- (B): Reducing attention key size (dimensions)
- Performance degraded
- (C): Larger models performed better
- (D): Removing dropout reduced performance
- (E): Replacing positional encoding with learned positional embeddings showed almost no difference in results
English Constituency Parsing
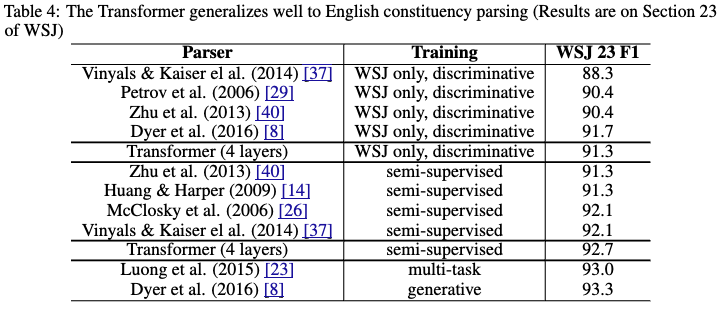
- Experiment to verify the generalization capability of the Transformer
- No task-specific tuning was performed
- The Transformer model outperformed many existing models
Conclusion/Thoughts
Above is my summary of the paper "Attention Is All You Need."
Below are my personal notes:
- What were the authors trying to achieve?
- Proposing a model architecture that enables parallel training while maintaining high performance
- What are the key elements of their approach?
- Using only attention mechanisms, eliminating RNNs and CNNs entirely
- Adopting Multi-Head Attention
- Which cited papers do I want to read next?
- Other thoughts
- I had only known the famous Transformer architecture diagram, so I wasn't sure which parts were actually novel. The key innovation is using only attention mechanisms without RNNs or CNNs; the other architectural components were previously established concepts. Now the paper title "Attention Is All You Need" finally makes sense.
[Related Articles]
