This is a summary of the paper "The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits".
- Introduction
- The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits
- Conclusion/Thoughts
- References
Introduction
The paper covered in this summary:
- Published February 27, 2024
- Microsoft team
- Code: unilm/bitnet at master · microsoft/unilm · GitHub
All figures in this article are cited from the above paper.
Note: This article was translated from my original post.
The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits
Overview
- Background
- Recent advances in LLMs have been remarkable, but growing model sizes demand increasingly more resources
- Various approaches have been proposed to address these challenges, including post-training quantization
- 1-bit model architectures like BitNet have shown potential for significant improvements in computational efficiency
- No multiplication required
- Reduced memory usage
- Challenge
- Develop an improved version of BitNet
- What they did
- Created BitNet b1.58
- Uses ternary values {-1, 0, 1}
- Note: The original 1-bit BitNet used binary values {-1, 1}
- Created BitNet b1.58
- Results
- Beyond a certain size threshold, it achieved benchmark results comparable to or exceeding full-precision models
- Computational efficiency was also excellent
Method
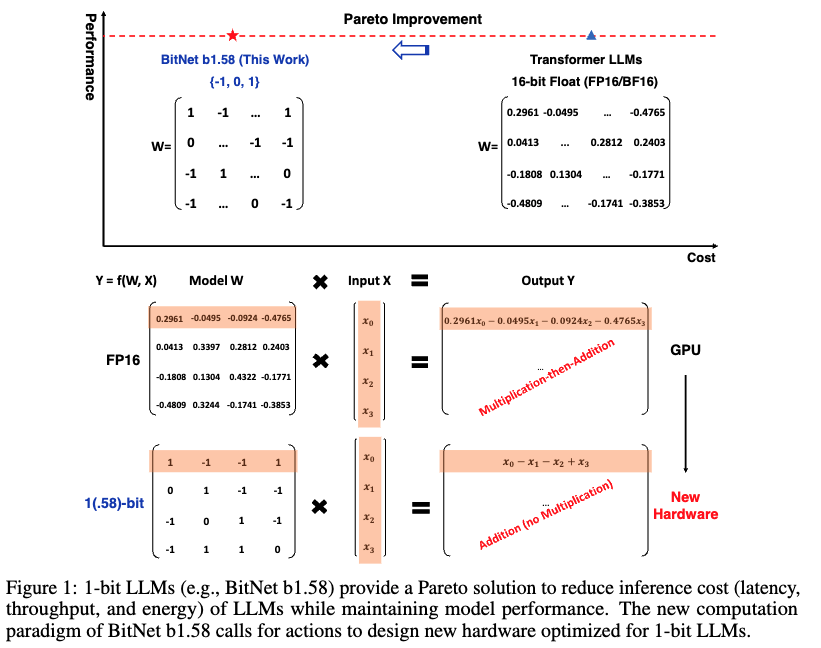
- BitNet b1.58 is based on the BitNet architecture
- Uses BitLinear instead of nn.Linear
- Weights are quantized to 1.58-bit: {-1, 0, 1}
- Activations are 8-bit
- Deriving 1.58-bit: {-1, 0, 1}
- Weights are scaled by their mean absolute value, then rounded to {-1, 0, +1}
- Component structure follows LLaMA
Results

- Perplexity matched LLaMA at 3B parameters and showed significantly better results at 3.9B
- BitNet b1.58 also performed better in terms of memory and latency

- As model size increased, the gap between BitNet b1.58 and LLaMA narrowed, reaching parity at 3B and surpassing LLaMA at 3.9B
- Evaluation used lm-evaluation-harness
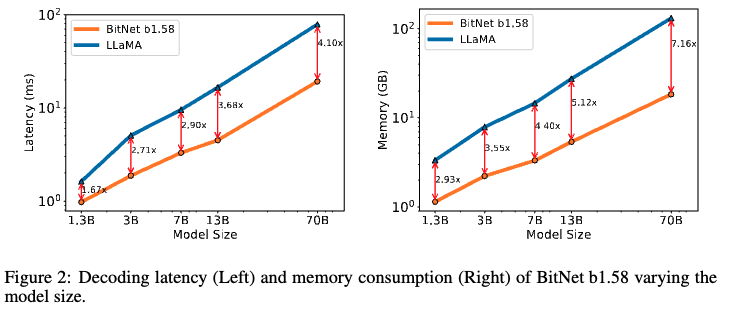
- As model size increased, memory and latency became more efficient compared to LLaMA

- Energy consumption was significantly lower for BitNet b1.58

- BitNet b1.58 achieved larger batch sizes and higher throughput

- To examine performance with larger training datasets and assess BitNet b1.58's scalability with training token volume
- Compared with StableLM-3B (a SOTA open-source model trained on the same data) using 2T (trillion) tokens of training data
- BitNet b1.58 showed superior results
Conclusion/Thoughts
That wraps up this summary of the paper "The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits".
Below are my personal notes:
- What are the authors trying to achieve?
- Demonstrate that quantized models can match full-precision models in performance
- What are the key elements of their approach?
- Ternary weight representation
- What cited papers should I read next?
- Other thoughts
- The training process wasn't entirely clear to me, so I'd like to examine the original BitNet paper and BitLinear implementation
- It's fascinating that quantization doesn't degrade performance (and sometimes even improves it)
- This form of information transmission does seem closer to biological neural firing in the brain
- I'm excited to see AI becoming increasingly similar to biological neural networks
[Related Articles]
