- はじめに
- ワークフローをインフラに委ねなかった理由
- 全体構造:クリーンアーキテクチャの適用
- DDDでワークフローを表現する
- ① 実行形態からの完全分離
- ② Protocolによる依存性逆転
- ③ Model Adapterで将来耐性を確保
- ④ Observabilityと整合する構造
- まとめ
はじめに
こんにちは。プラットフォーム開発本部 第4開発部 ユーザーレビューグループの大野です。
私たちは、DMMに投稿されるユーザーレビューを処理するバックエンド基盤を開発・運用しています。
レビュー投稿チェックや自動承認などのAI機能は、ユーザー体験の一部として本番トラフィックの中で動作します。
しかしAI処理では、正規化→1次判定→分岐→高精度モデル呼び出し…のように複数ステップが連なる構成になりやすく、従来はマネージドサービスを組み合わせた個別最適な構成となっていました。
その結果、AIだけが既存のバックエンド設計やDevOpsの枠組みから外れた“特別な存在”になっていました。
前編「レビューAI基盤の再構築 AIを特別扱いしないための設計原則」では、この構造的な問題と設計原則を整理しました。
本記事では、その原則をどのようなコード構造として実装したのかを解説します。
ワークフローをインフラに委ねなかった理由
AI処理では、次のように複数のステップが連なる構成になりがちです。
- 入力正規化
- 低コストモデルによる一次判定
- 条件分岐
- 高精度モデル呼び出し
- フォールバック
- 結果整形
こうした処理は、Step Functions や Temporal、あるいは DSL ベースのワークフローオーケストレーターに切り出すことも可能です。
それでも私たちは、その道は選ばず、ワークフローをコードとして表現する方針を取りました。
その理由は、次の一言に尽きます。
「入力をどう処理するか」「どの条件で分岐するか」「どのモデルを呼ぶか」
——そうした決定は、すべてビジネスロジックの領域にあります。
ワークフローをインフラに委ねると、そうした決定は設定ファイルや定義DSLの中に埋もれ、ドメインの責務から切り離されてしまいます。
結果として、次のような状態が生まれます。
- ビジネスロジックがインフラ構成に分散する
- ドメインの意図がコードから読み取れなくなる
- 責任境界が曖昧になる
私たちは、ワークフローを「実行手順」ではなく、
ドメインの判断の連鎖として扱うことを選びました。
だからこそ、ワークフローはDomain層のビジネスロジックとして実装しています。
次節では、その構造を示します。
全体構造:クリーンアーキテクチャの適用
ユーザーレビューAI基盤 pf-review-ai-platform はクリーンアーキテクチャをベースに設計しています。
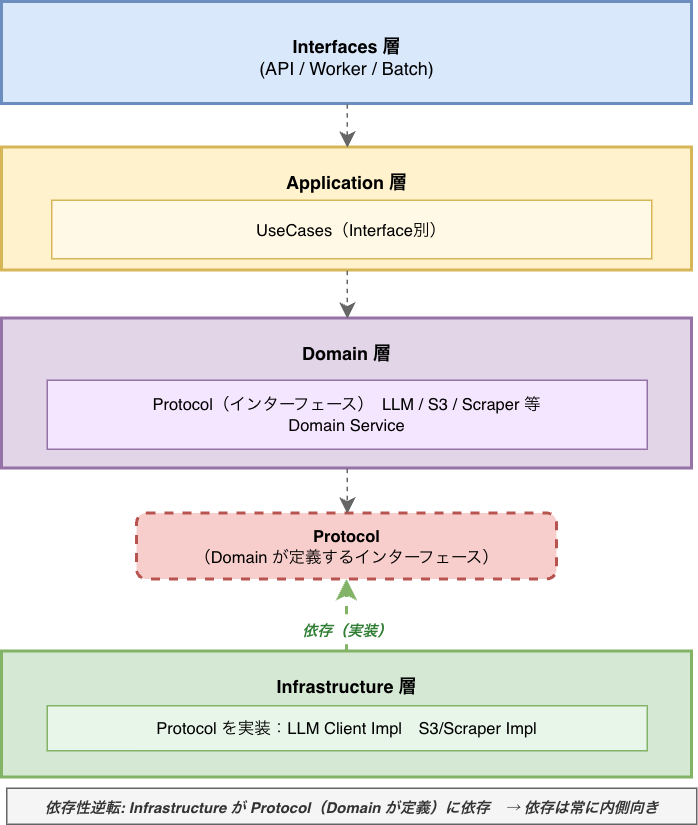
クリーンアーキテクチャでは、次のような構造を取ります。
- 内側がビジネスロジック
- 外側が技術的詳細
- 依存性は内側に向かう
AIワークフローをDomain層に置くことで、次の要素をすべて外側へ押し出しました。
- 実行形態
- LLMプロバイダー
- モデルフォーマット
これは単なる層の分割ではなく、ワークフローをビジネスロジックとして扱う設計判断です。
DDDでワークフローを表現する
ワークフローをDomain層に置くために、DDDのパターンを採用しました。
Value Object
バリデーションと不変性をここに集約します。
@dataclass(frozen=True) class ReviewContent: text: str rating: int
Rich Domain Model
判定ロジックはモデル側に持たせます。
@dataclass class PreCheckResult: category: PreCheckCategory def is_ok(self) -> bool: return self.category == PreCheckCategory.OK
Domain Service (ワークフロー)
ワークフローの制御フローを Domain Service (ワークフロー)として実装します。
処理の全ステップをコード上で明示的に表現しています。
※ 以下は構造を示すための簡略化した例です。
class PreCheckDomainService: def check(self, review: ReviewContent) -> PreCheckResult: # 0. レビュー内容を正規化し、明らかな不正入力を排除する normalized = self._normalize(review) if normalized.is_empty(): return PreCheckResult.reject("empty_review") # 1. 判定用プロンプトのテンプレートを取得する template = self._storage.read_file(prompt_bucket, "pre_check.txt") # 2. 軽量モデルで一次判定を行う(大半のケースをここで確定させる) first_prompt = self._build_prompt(normalized, template, mode="first_pass") first = self._llm.invoke( LLMRequest( prompt=first_prompt, model_id="us.anthropic.claude-haiku-4-5-20251001-v1:0", ) ) first_result = self._interpret_first_pass(first) # 3. 明らかに問題がない/問題があるケースはここで終了する if first_result.is_clear_ok(): return PreCheckResult.ok(reason="first_pass") if first_result.is_clear_ng(): return PreCheckResult.reject(reason="first_pass") # 4. 判定が曖昧なケースのみ、高精度モデルで再評価する final_prompt = self._build_prompt( normalized, template, mode="final_pass", hints=first_result.hints, ) final = self._llm.invoke( LLMRequest( prompt=final_prompt, model_id="anthropic.claude-3-5-sonnet-20241022-v2:0", ) ) return self._interpret_final_pass(final)
このメソッドが行っているのは、次の一連のステップ制御そのものです。
- プロンプトテンプレート取得
- プロンプト組み立て
- LLM推論呼び出し
- 結果解釈
しかしそれはDSLではなく、ドメイン責務の実装です。
汎用ワークフローエンジンにしなかったのは、この判断ロジックをインフラ設定やDSLに埋もれさせないためです。
AIワークフローは「実行手順」ではなく、ドメインの判断の連鎖です。
一方で、LLMやストレージなど外部I/Oに起因する例外の判定・変換やリトライ方針は、Domainの責務ではありません。
それらはUsecase(Application層)で集約して扱い、実行環境や運用制御の責務を外側の層に分離しています。
このように責務を分離することで、判断ロジックをドメイン境界の内側に明示できます。
以降では、その実現を支える4つの設計判断を順に示します。
① 実行形態からの完全分離
AI機能には複数の実行形態があります。
- 同期API
- 非同期Worker
- バッチ
- エージェント
しかし、Domain Serviceはそれを知りません。実行形態の差分はInterfaces層が吸収します。
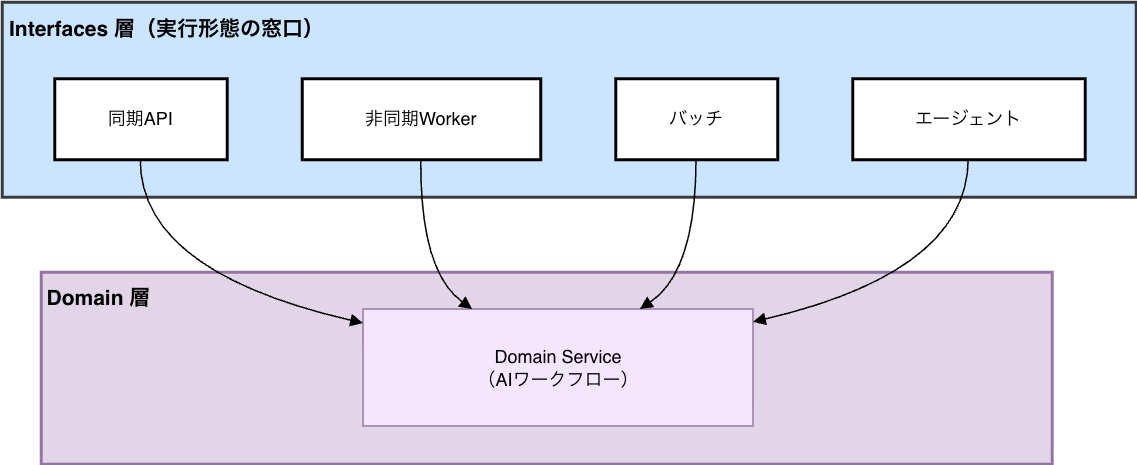
これにより、次のような構造になりました。
- Domain Service(ワークフロー)は実行形態を問わず再利用可能(API・Worker・バッチ・エージェントで同じロジックを共有)
- ワークフローはランタイム非依存
- 新しい実行形態追加が容易
- スケーリング戦略を分離可能
② Protocolによる依存性逆転
Domain層がLLMプロバイダー(Bedrock / OpenAI など)を直接知ることはありません。
そのために、Pythonの Protocol を使ってインターフェースを定義します。
# Domain層が依存するインターフェース class LLMProtocol(Protocol): def invoke(self, request: LLMRequest) -> LLMResponse: ...
Domain層は「このメソッドを持つもの」にのみ依存します。
具体的な実装クラスには依存しません。
Infrastructure層では、このProtocolを実装します。
# Infrastructure層の実装クラス(Domainはこれらを直接知らない) class BedrockLLM(LLMProtocol): def invoke(self, request: LLMRequest) -> LLMResponse: # AWS Bedrock API を呼び出し、LLMResponse に変換して返す ... class OpenAILLM(LLMProtocol): def invoke(self, request: LLMRequest) -> LLMResponse: # OpenAI API を呼び出し、LLMResponse に変換して返す ...
Domain Serviceは常に LLMProtocol としてLLMを扱います。
その結果、以下のような変更はInfrastructure側の対応だけで完結します。
- プロバイダーの変更
- テスト用Mockへの差し替え
- コスト最適化のためのモデル戦略変更
重要なのは、LLMを“特別な存在”として扱わないことです。
LLMは、DBやキャッシュと同じ「外部I/O」の一つにすぎません。
クリーンアーキテクチャの依存性逆転により、LLMはドメイン境界の外側へ押し出されます。
これにより、モデルやプロバイダーが進化しても、ドメインロジックは壊れないという将来耐性を確保しています。
ただし、BedrockLLM の内部にはもう一つの課題があります。
Bedrockが提供するモデル(Claude・Titan・Mistralなど)は、それぞれAPIのリクエスト形式が異なります。
この差異を BedrockLLM に直接持たせると、
モデル追加のたびに実装が肥大化し、変更箇所が増えていきます。
その問題を解決するのが、次に説明する Model Adapter パターンです。
③ Model Adapterで将来耐性を確保
BedrockLLM(LLMProtocol の実装)がモデルごとのリクエスト形式の差異を直接持つことを避けるため、
モデル単位のフォーマット変換をAdapterパターンで吸収します。
# BedrockLLM が利用する内部インターフェース(Infrastructure層) class ModelAdapterProtocol(Protocol): def execute(self, request: LLMRequest) -> LLMResponse: ... # モデルごとのAdapter実装(共通の LLMRequest/LLMResponse に変換) class ClaudeAdapter(ModelAdapterProtocol): def execute(self, request: LLMRequest) -> LLMResponse: # Claude 用のAPI形式に変換して Bedrock を呼び出し、LLMResponse に変換 ...
LLMProtocol が「Domainから見たLLMという概念」を抽象化するのに対し、
ModelAdapterProtocol はInfrastructure層の内部インターフェースとして「特定モデルとの通信フォーマット」を隠蔽します。
呼び出し関係は次のとおりです。

LLMRequest/LLMResponse は基盤内の共通型で、各モデルAdapterが固有のAPI形式への変換責務を担います。
新モデル追加は以下の2ステップのみです。
- 対応するモデルAdapterクラスを実装する
- DIコンテナに登録する
Domainはもちろんのこと、BedrockLLM 自体にも変更は不要です。
モデルの世代交代や新モデル追加を、Adapterの追加だけで完結させられる構造です。
④ Observabilityと整合する構造
前編でDatadog LLM Observabilityに触れました。
本基盤では、次のような構造を取っています。
- LLM呼び出しはProtocol経由で一元化
- ワークフローステップが明示的に存在
- 分岐がコードで表現されている
そのため、以下の観測が一元的に実現できます。
- LLM呼び出し単位でトークン計測
- ステップ単位の実行時間トレース
- 分岐経路の可視化
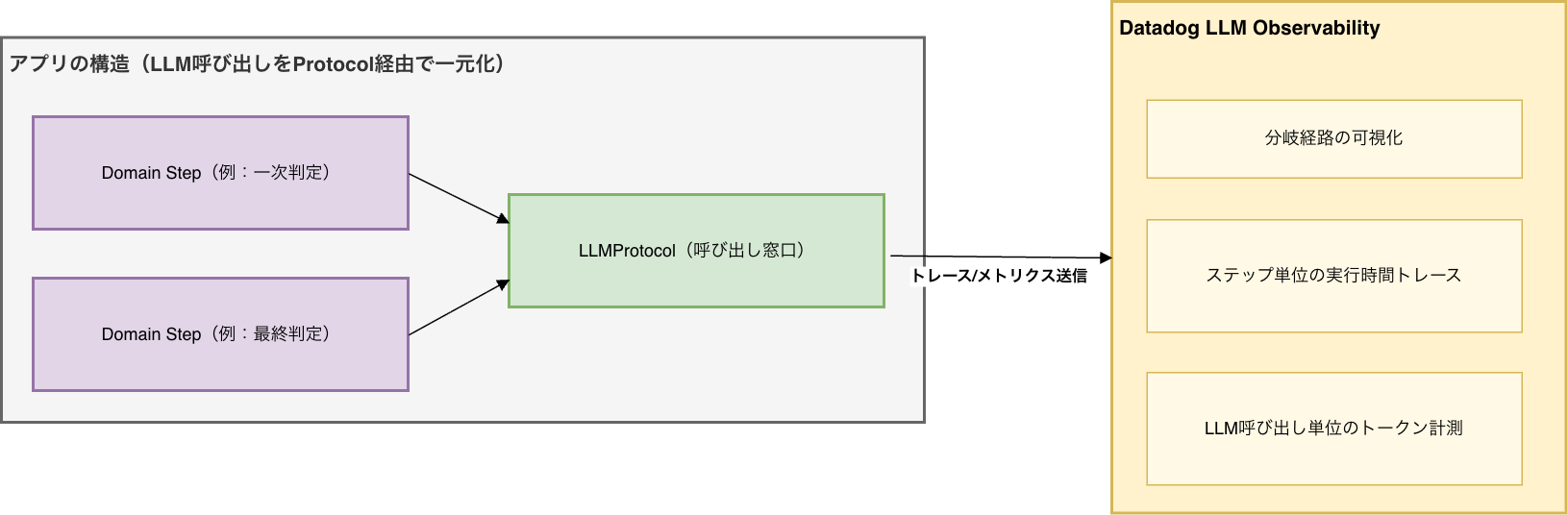
実装上は、LLM呼び出しを担うProtocol実装(例:BedrockProtocolClient)でDatadogのスパンを生成しています。
from ddtrace import tracer class BedrockProtocolClient(LLMProtocol): def invoke(self, request: LLMRequest) -> LLMResponse: # Bedrockクライアントを作成 bedrock_client = boto3.client("bedrock-runtime", region_name=self._region_name) # モデルIDに応じた適切なAdapterを取得 adapter = self._get_adapter(request.model_id) # LLM Observability のスパンを生成 with LLMObs.llm(name="llm_invoke"): # adapter 経由でBedrock APIを呼び出し、LLMResponse に変換して返す response = adapter.execute(request, bedrock_client) return response
LLMObs.llm コンテキスト内で実行されたLLM呼び出しは、
モデルID・トークン使用量・レイテンシなどが自動的にスパンへ紐付けられます。
LLM呼び出しが LLMProtocol に集約されているため、
観測コードもInfrastructure層の一箇所に集約されます。
Domain側に観測ロジックを書く必要はありません。
ワークフローは「判断の連鎖」として表現され、
観測はProtocol実装の責務として外側に配置されています。
Observabilityは後付けの仕組みではありません。
LLM呼び出しをProtocolに集約するという設計判断の帰結として、 自然に観測可能な構造になっています。
まとめ
AIを特別扱いしない
前編では、上記の設計原則を示しました。
本記事では、その原則をコード構造としてどのように実装したかを解説しました。
私たちが行った設計判断は、次の4点に集約されます。
ワークフローはDomainに、実行形態の差分はInterfaces層へ
こうした複数ステップからなるAI処理はインフラ設定ではなく、レビュー承認というビジネスロジックです。
その責任をドメイン境界の内側に置きDomain Serviceとして明示し、API・Worker・バッチといった実行形態の差分はInterfaces層が吸収します。外部I/OはProtocolで抽象化する
LLMプロバイダーへの依存をDomainから排除し、Infrastructure側に閉じ込めました。モデル差異はAdapterで吸収する
モデル追加や世代交代があっても、DomainやProvider実装を壊さない構造にしました。観測と整合する呼び出し構造を取る
LLM呼び出しを一元化し、ステップをコードとして明示することで、
Datadog LLM Observabilityによるトークン計測・分岐可視化と自然に整合する設計になっています。
AIを特別扱いしないとは、AIを通常のアプリケーション構造の中に戻すことです。
- ワークフローはDomainへ。
- 実行形態の差分はInterfaces層へ。
- 外部I/OはProtocolを通して外側へ。
- 進化するモデルはAdapterへ。
- 観測は構造の延長線上へ。
その結果、AIは例外的な基盤ではなく、標準的なバックエンド設計の延長として扱えるようになりました。
最後までお読みいただきありがとうございました。 この記事が、みなさんの設計や実装の一助となれば幸いです。
