
はじめに
こんにちは。プラットフォーム開発本部 第四開発部 ユーザーレビューグループの松井です。
私たちは、DMMに投稿されるユーザーレビューを処理するバックエンドAPIを開発・運用しています。レビューの投稿・表示は、ユーザー体験を支える基盤機能です。
そのため、Kubernetesを中心とした標準化アーキテクチャを採用し、「コードを書けば運用に乗る」状態を前提に設計しています。
しかし、ひとつだけ問題がありました。
AIを利用した機能だけが、既存のDevOpsモデルに乗っていなかったのです。
本記事では、その構造的な課題と、それをどのような設計原則で再整理したのかを紹介します。
プロダクトAIはバックエンド機能である
私たちが扱ってきたAIは、CursorやCopilotのような開発者向けの支援ツールではありません。エンドユーザーが操作するプロダクトの中に組み込まれ、ユーザーの操作を契機にバックエンドで自動実行されるAIです。
たとえば、DMMのレビュー投稿フローには、次のようなAI機能があります。
(注:一部は計画・開発中)
- 投稿チェックAI(不適切表現・スパム検知)
- 自動承認AI(条件を満たすレビューの自動承認)
- サジェストAI(投稿時の文章改善)
- コンテンツ推薦AI(レビュー投稿を促す推薦)
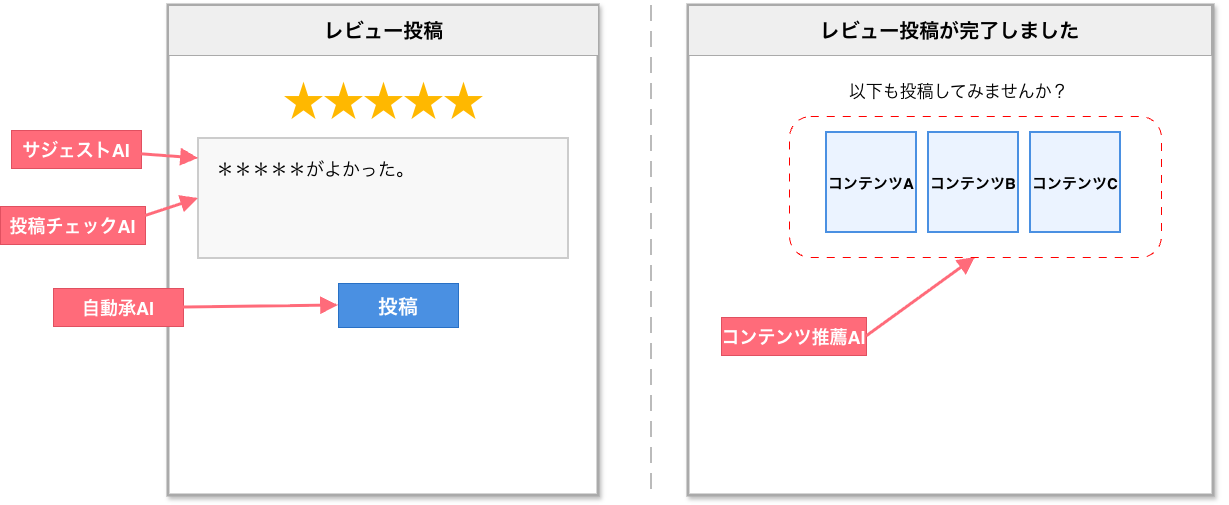
図A: プロダクトに組み込まれたAI機能の全体像
これらはすべて、ユーザーがレビューを投稿・閲覧する体験に直接影響するUXの一部です。プロダクトに組み込まれている以上、次の影響は避けられません。
- 誤判定はそのままユーザー体験の品質問題になる
- レイテンシはユーザーが感じる体感性能になる
- トークン消費は直接的な運用コストになる
つまりこれらのAIは、プロダクトの品質・性能・コストに直結する、信頼性を担保すべきバックエンド機能です。
なぜAIはワークフロー化するのか
AIをプロダクトに組み込む以上、その特性と向き合う必要があります。
- LLMの出力が揺らぐ(同じ入力でも結果が変わる)
- レイテンシが変動する(数秒〜数分かかる)
- コストが入力の量・複雑さによって増減する
これらは通常のAPIとは異なる性質であり、単発の推論呼び出しをそのままプロダクトに置くだけでは安定しません。
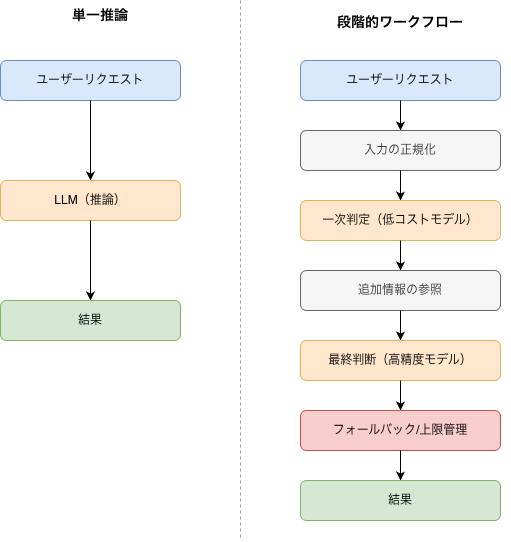
そのため実際のプロダクトの処理は段階化されます。
- 入力の正規化
- 低コストモデルでの一次判定
- 追加情報の参照
- 高精度モデルでの最終判断
- フォールバックや上限管理
結果として、AIは制御されたワークフローになります。
10以上のステップを経ることも珍しくありません。
昨今ではAIエージェントにこれらを委ねる設計もあります。
しかしガードレールや分岐制御を持つ以上、それも広義のワークフローに変化をしていきます。
分散SaaSが生んだ構造的負債
当初、私たちはこれらのワークフローをアプリケーションコードとして実装しました。しかし分岐とステップが増え、コードは急速に複雑化し、精度改善や保守が容易ではありませんでした。
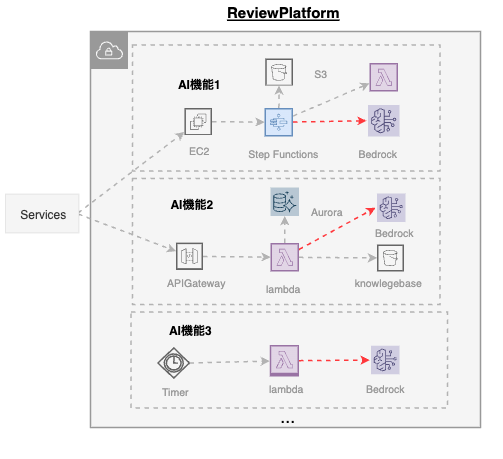
そこでワークフローを切り出し、2024年にマネージドサービスの構成に移行しました。Lambda、SQS、Step Functions、Bedrock Agent などを組み合わせ、機能ごとに最適な構成を採用しました。
しかしこれもまたAI機能が増えるにつれ、別の課題が顕在化します。
- 機能ごとに構成が異なり、障害時に追う経路が統一されない
- ログが統一されておらずサービスごとに実行ログを確認する必要があった
- IAMやリソース管理が機能単位で増殖した
- ローカル開発が難しく、SaaS上での開発・検証となった
- LLM利用状況を横断的に把握できなかった
AIは進化が速く、専用基盤を切り出したくなります。
しかしその瞬間、AIだけが既存のDevOpsモデルから分離された存在になっていました。これが構造的な負債でした。
設計原則 — AIを特別扱いしない
この状態を整理するために定めた原則は一つです。
AIを特別扱いしない。
ワークフローも通常のアプリケーションコードとして実装し、既存のバックエンドと同じ実行基盤・同じ責任境界に戻す。
この原則のもと、2025年から統合基盤の構築を開始したのです。
再設計の3つの軸
1. 実行基盤の統一(Kubernetes)
AIも他のバックエンド機能と同じ扱いです。
ワークフロー専用エンジンに切り出すのではなく、通常のアプリケーションコードとして実装し、Kubernetes上で実行しています。同期・非同期・バッチ実行違いは基盤側で吸収し、既存のCI/CD・監視にそのまま統合しました。
2. ドメイン境界の明確化(DDD)
ワークフローを「LLM呼び出し」や「分岐制御」といった技術の単位だけで組むと、最終的には汎用的な実行エンジンになってしまいます。
しかし私たちのAIは、レビュー承認・投稿チェック・サジェストといった明確な業務責務を持つ機能です。
そこでワークフローは技術単位ではなく、ドメイン単位で構成しました。推論ステップも内部処理として隠すのではなく、規約違反判定や承認可否判断といったドメインロジックとして明示しています。
これにより、AI処理をインフラではなくビジネスロジックとして管理できる設計になりました。
3. ワークフロー内部の可観測性(Observability)
もっとも重要だったのがObservabilityの概念です。
Kubernetesに統合するだけでは、ワークフロー内部は見えません。
「どのモデルを使ったか」「どのステップを通ったか」「どこでトークンが増えたか」「どこで遅延が発生したか」
これらを追跡できなければ、AI処理はブラックボックスのままです。
そこでDatadog LLM Observabilityを活用し、ステップ単位で実行時間・トークン消費・分岐経路を可視化しました。推論も通常のトレース対象となり、ワークフロー全体を一貫して観測できる構造になっています。
これにより、次の3点が実現できました。
精度改善
どのステップで判定がブレているかを特定し、プロンプトやモデル選択、入出力のパラメータ等を継続的に改善できる。コスト監視
LLMのトークン消費をステップ・機能単位で把握し、不要なコストの発生箇所を特定できる。ワークフロー全体の改善
リクエスト単位の分岐経路や遅延箇所が可視化され、ボトルネックを特定してワークフロー構成そのものを改善できる。
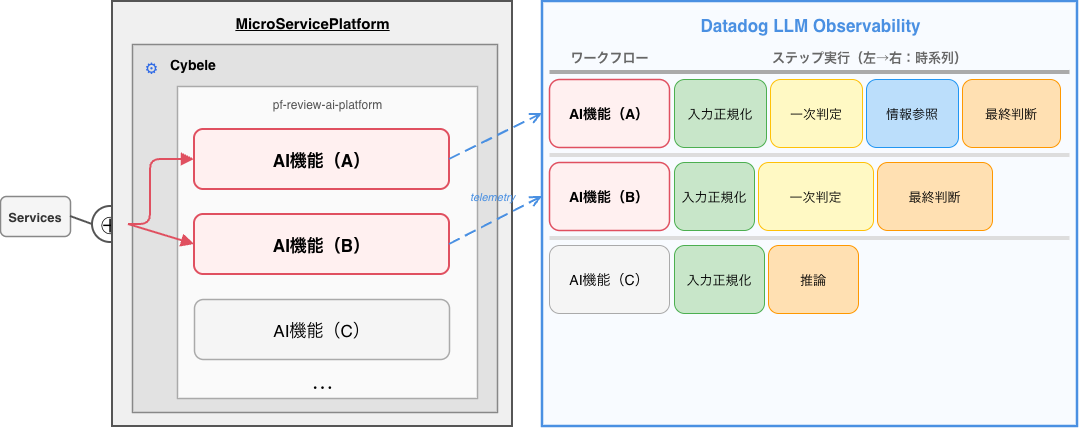
図D: AI基盤の統合とObservabilityによるワークフロー可視化
※ LangSmithやLangFuseなどの選択肢もありますが、既存の監視基盤との統合性からDatadogを採用しています。
統合の成果
この再設計により、AI機能は既存のDevOpsループに自然に統合されました。
- 新機能の追加時に個別のインフラ設計が不要になった
- 障害調査の経路が統一され、原因特定までの時間が短縮された
- LLM利用状況を機能横断で可視化できるようになった
- CI/CDが既存パイプラインにそのまま統合された
最大の成果は、AIが"例外的な基盤"ではなくなったことです。
| 観点 | Before | After |
|---|---|---|
| 実行基盤 | サービスごとに分散 | Kubernetes に統一 |
| 責任境界 | 技術単位で分断 | ドメイン単位で整理 |
| 可観測性 | 内部がブラックボックス | ステップ単位で可視化 |
| CI/CD | 手動デプロイ | GitHub Actions + ArgoCD |
※ 定量的な効果は今後検証予定。
まとめ
AIをプロダクトで使うと、必然的にワークフロー化します。
大切なのは、どのレイヤで責任を持つかでした。
私たちは、実行基盤を統一し、ドメイン境界を明確にし、Observabilityを前提に設計することで、AIを標準的なインフラ運用の枠組みに戻しました。
AIが進化しても、この原則は変わりません。
レビューAI基盤の再構築とは、AIを特別扱いしないための設計原則を、実装レベルで再定義することでした。
では実際に、ワークフローはどう実装されているのか。DDDでどのようにモデリングしているのか。Observabilityはどこにどう埋め込んでいるのか。
具体的な構成やコードについては、ユーザーレビューグループ大野の記事で解説しています。ぜひあわせてご覧ください。
プロダクトAIを標準的なインフラ運用に載せるための実践例として、参考になれば幸いです。
