
はじめに
この記事は DMMグループ Advent Calendar 2023 の2日目の記事です。
こんにちは、プラットフォーム事業本部 マイクロサービスアーキテクトグループで認証認可サービスの開発と運用をしている渡部です。
この記事では私のチームがSLI/SLOを導入し、運用を進める中で出会った課題や学びを共有します。特に複数のマイクロサービスが依存しあっている状況において、開発者目線のSLIからユーザー目線のSLIへ見直した経緯について述べます。
SLI/SLOの導入以前からの課題
私たちのチームが開発する認証認可サービスはレガシーなシステムに依存していました。この依存関係により、サービス品質の低下が私たちのサービス起因なのかそれとも依存先システム起因なのかの判別に手間がかかり、運用負荷が高まっていました。つまり、私たちのマイクロサービスが実際にどの程度の品質を保持しているのかをうまく把握するのが困難な状況でした。
そのような状況の中で、DMMプラットフォームにSLI/SLOを導入する取り組みが始まり、認証認可サービスにもSLOを導入することになりました。
このDMMプラットフォームにSLOを導入する取り組みについて、詳しくは同僚のKudoさんがCloud Operator Days Tokyo 2023で登壇した資料を見ていただければと思います。
(参考: DMMプラットフォームに ゼロベースでSLO導入している取り組み 適切なSLI模索の軌跡 )
そして私たちのチームは「依存先システムの影響で自サービス単体の品質がうまく把握できない」という課題感を持ってSLO導入に取り組むことになりましたが、これがユーザー視点のSLO運用から離れていくきっかけとなったのでした...。
どのようなSLIを採用したか
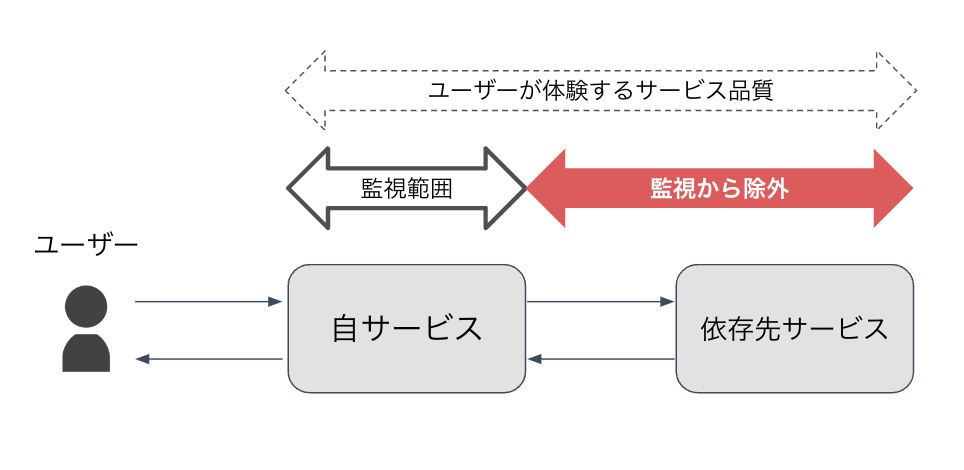
結論から述べると、依存先レガシーシステムに影響されないメトリクスをSLIとして採用しました。例えば、レイテンシについては依存先システムの応答時間を除外するようにし、エラーレートの計算からは依存先システム起因のエラーを除外するようにしました。
つまり、以下のような自サービスに限定したメトリクスを計測し、サービスの信頼性を評価するSLIとして使用することとしました。
- 依存先の応答時間を含まないレイテンシ
- 依存先に起因するエラーを除外したエラーレート
このような監視をGoで実現した具体的な方法については、DMM.go #6 マイクロサービスの効率的な監視〜不安定な依存先との闘い〜 で紹介しましたのでよければご参照ください。
得られた成果と課題
依存先システムの影響を除いたSLIを採用することで、普段のチームの運用負荷は軽減しました。
なぜなら、他チーム管轄の依存先システムが不調になったとしても私たちのサービスを監視するアラートは発火せず、対応を迫られることがないからです。加えて、今までは依存先システムの応答時間に覆い隠されていた自サービスレイテンシの小さな不調にも気づけるようになりました。
一方で(本末転倒な話ではありますが)SLO導入の本来の目的であった、ユーザーが体験するサービス品質を正確に可視化することができなくなりました。
また、依存先システムの影響を除外する仕組みの実装により、SLIの定義だけでなくアプリケーションの実装も複雑化し、認知負荷が増大しました。
結果として、運用負荷の軽減という成果は一定程度得られましたが、ユーザーの満足度を可視化し、ビジネス的な意思決定に活用できるSLO運用とはかけ離れた形となりました。
成果
- 依存先システム起因の品質悪化時にアラート対応を迫られない
- 自サービス単体の品質が可視化され、小さな不調に気づける
課題
- SLIがユーザーの満足度を表す指標でない
- 認知負荷の増大
まとめと展望
今後は依存先のパフォーマンスを含むシンプルなメトリクスへ修正しようと考えています。
また依存先システムの影響を除いたメトリクスの有用性は変わらないため、そのようなメトリクスは自サービス監視の一部として引き続き使用する予定です。
ユーザー目線であるべきSLIでは依存先も含めた全体の品質を計測しつつ、開発者・運用者のために自サービス単体の品質も別で可視化する、という状況を目指すのが良いのではないかと考えています。
私たちのチームでのSLI/SLO運用は今も手探りな状況ですが、この見直しの経緯を共有することで同じような問題を抱える方の参考になれば幸いです。
