 こんにちは。開発部 技術戦略室の吉村と申します。今年の1月からAIコーディングエージェントをフル活用した1人開発によって、PoCの新規プロダクトや、ちょっとした社内ツールを爆速で立ち上げるような仕事をしています。今のところ1ヶ月1プロダクトペースで開発サイクル全体を回せており、現在2プロダクト目が仕上がろうとしているぐらいのタイミングです。ソフトウェアエンジニアリングに対する潮流が目まぐるしい昨今ですが、「Time To Market」を意識した速度感があり刺激のある経験をさせていただいております。
こんにちは。開発部 技術戦略室の吉村と申します。今年の1月からAIコーディングエージェントをフル活用した1人開発によって、PoCの新規プロダクトや、ちょっとした社内ツールを爆速で立ち上げるような仕事をしています。今のところ1ヶ月1プロダクトペースで開発サイクル全体を回せており、現在2プロダクト目が仕上がろうとしているぐらいのタイミングです。ソフトウェアエンジニアリングに対する潮流が目まぐるしい昨今ですが、「Time To Market」を意識した速度感があり刺激のある経験をさせていただいております。
さて、直近の「AIと1人開発」を通して、環境変数やシークレットの実装について、AIは雑な実装を行うケースが多いなと感じました。 AIの実装をレビューするにしろ、従来通り自前で実装するにしろ、これらの実装に対する適切な審美眼は持っておきたいところです。 そこで今回は環境変数とシークレットの管理について、複数の観点から整理と効率化を考えてみました。 この記事を通して、お手元のプロダクトのリポジトリの環境変数・シークレットを見直すきっかけになれば幸いです。
そもそもシークレットと環境変数とは何か
シークレットや環境変数は皆さんご存じのようにプログラムの外部から注入されます。似たような値にコード内定数がありますがしばしばこれらは混同されます。まずはこれらを用途で分類してみたいと思います。(※他にもBuild Args, Feature Flags, Infra Metadataなどございますが簡単のために本記事の対象外とさせていただきます。)
- シークレット: 秘匿性のある値、実行環境によって変動するかどうかは問わない。
- 環境変数: 秘匿性のない値、実行環境によって変動する可能性がある。
まず、シークレットについては秘匿性があることが必要条件です。この点は明白だと思いますが、ややこしいことにシークレットは「実行環境によって変動する可能性がある」という環境変数の性質を持つ場合があります。この性質がしばしば環境変数とシークレットを混同してしまう原因になるわけです。まず、判断基準として秘匿性があればシークレット、なければ環境変数やコード内定数の利用を考えます。 続いて、環境変数は秘匿性が無いことが必要条件です。これは実行環境では比較的簡単に環境変数の値を参照することができるためです。そして「実行環境によって変動する可能性がある」という性質を持っています。しかしながらこの性質は軽視されがちでしばしば、コード内定数っぽいものも環境変数にされがちで、環境変数の数が煩雑なほど多くなってしまっている状況をよく見かけます。
ここで個人的な設計ポリシーを提案します。環境によって差分の可能性がないのであればそれは環境変数ではなくコード内定数として管理すべき値だと私は考えます。
シークレットや環境変数は可能な限り管理を少なくする。シークレットでも環境変数でもない値をコード内定数として管理する。
コード内定数が何者なのか、どう管理するのかは後述します。ひとまず環境変数とシークレットの用途に焦点を戻しましょう。つまり、個人的には下記の値は環境変数で管理すべきではないと考えています。
- 秘匿性のある値: シークレットで管理する
- 実行環境によって変動する可能性がない: コード内定数で管理する
では、コード内定数とはなんでしょうか? 前述の通り、シークレットでも環境変数でもないことを判断しているので、秘匿性がなく実行環境により変動する可能性がないという前提がこの時点で確定しています。コード内定数は当然ながら値を変更したければ再デプロイする必要があるという性質を持ちます。 環境変数の性質として「実行環境によって変動する可能性がある」と書いたのは、たまたまどの実行環境でも値が同じというケースが存在するためです。環境変数なのかコード内定数なのかという境界は実際問題、曖昧でわかりにくいです。というより実践的には慣例で決めたり、判断がつかない値に関しては「決め」の問題であることがほとんどです。ただし、先ほど述べた性質の違いがあります。コード内定数の変更には、コードの修正とビルド、そして再デプロイという一連のサイクルが必要です。一方、環境変数は成果物(イメージやバイナリ)を再作成することなく、デプロイ設定の更新だけで値を切り替えられます。ただし、多くの実行基盤では環境変数の反映にプロセスの再起動を伴うため、完全な動的変更を行いたい場合は機能フラグ(Feature Flags)の検討が必要です。つまり、プロセスの再起動(再デプロイ)なしに値を切り替えたいから環境変数を使うという判断はしてはいけません。一方、値を切り替える頻度がデプロイライフサイクルの中で収まるようななかなか変わらない値なのでコード内定数を使うという判断をすることは妥当です。
ここまでをまとめると外部注入する値は下記のフローでどこで管理すべきか判断できます。 この判定フローをAIに意識してもらうようにしましょう。シークレットと環境変数とコード内定数を適切に使いわけてもらうことが期待できます。
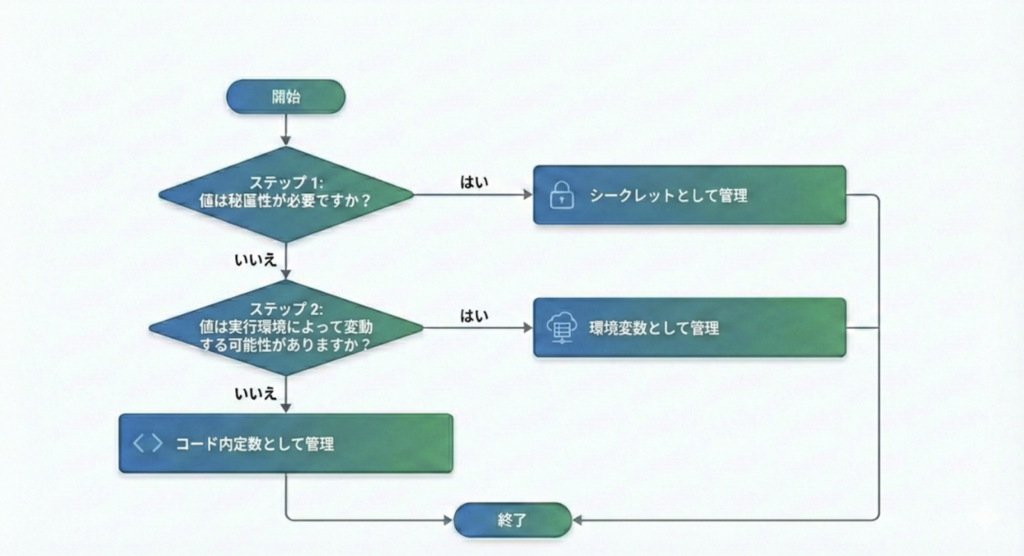
シークレット、環境変数、そしてコード内定数の効率的な管理方法
シークレットの管理
当社の開発環境において、シークレットと名前のつく管理ツールは2つあります。※そのほか1Passwordなどの有償ツールを使うという選択肢もありますね。
- GitHub Secrets を使う
- AWS Secrets Manager / Google Cloud Secret Manager を使う
GitHub SecretsはGitHub Actionsを実行する際に参照する必要のあるシークレットを埋め込むことを主たる目的としています。一度保存すると、たとえ管理者権限があっても値そのものを参照できない(Write-only)という性質があります。ログに出力しようとしてもアスタリスクで自動的にマスクされます。これはセキュリティ機能として優秀ですが、開発・運用視点では「値を確認できない」という不便さがあります。ということはシークレットの値をどこか他の場所(鍵付きのドキュメントやファイルなど)で管理する必要が出てきます。これは地味に手間のかかる管理方法ですね。また、GitHub Secretsで設定した値を実行環境の環境変数として注入する行為は、セキュリティリスクを高めるため避けるべきです。
Secret Managerはクラウドネイティブな実行環境では魅力的な選択肢です。IAMによって厳格な権限管理が可能です。そして権限があれば値そのものの参照が可能です。つまり、シークレットの値をどこか他の場所で管理する必要がありません。「正」となる値をここ一箇所で管理すればよく、二重管理が不要になります。 こういうわけで私個人としては基本的にSecret Managerに大部分のシークレット管理を任せ、GitHub Secretsに設置するシークレットは例えばAWSのSTS AssumeRoleやGoogle CloudのWorkload Identityによる権限借用とか通知先のSlackのWebhook情報など「クラウド環境に入るための鍵」や「CI/CD固有の値」といった必要最小限に抑えることを慣習にしています。
ここで2つ目の個人的な設計ポリシーを提案します。
シークレットは可能な限り、そもそも持たなくて良いモダンな方法がないか検討する。
そもそもシークレットなど持たなくて良いのであれば持たない方法を採用すれば良いという考え方です。 下記に削減できるシークレットと具体的な削減方法を記載しておきます。
- AWS/Google Cloudのサービスアカウントクレデンシャルキー: そもそもGitHub Secretsに置くことセキュリティ観点から推奨されません。AWSならSTS AssumeRole、 Google CloudならWorkload IdentityとGitHub用のサービスアカウントを組み合わせて権限借用することでこれらのキーは不要になります。
- ビルド&デプロイ時に環境変数として注入: そもそもシークレットの値を環境変数として注入するのはセキュリティ観点から推奨されません。アプリケーションコードでシークレットマネジャーから読み取りインメモリキャッシュさせるなどといったアプローチが一般的です。最近ではデプロイ前にシークレットをボリュームマウントしたりコンテナのサイドカーを設定してシークレットを参照するアプローチもあるようです。AIの手助けを借りればこれらの構成も昔ほどハードルが高くないアプローチとなっているのではないでしょうか。個人的にはCloudRunでデプロイ時にシークレットをマウントする手法に便利さを感じて利用させていただいています。
- APIキー: パブリックなAPIであればOAuth/OIDC、プライベートなAPIであればIAM認証への移行を検討します。もちろん、キーをなくすだけでなく、WAFやVPCによるインフラ防御、モバイルならFirebase App Check、WebならreCAPTCHAなど、多層防御の実装は必須です。
- DBアカウント/パスワード: RDSやCloud SQLなどのマネージドサービスであれば、IAM認証を利用することでDB固有のパスワード管理を削減できる場合があります。もちろんアプリ側の対応としてSDKやトークン生成処理が必要になりますが、ここも以前ほどハードルの高い実装ではなくなってきているのではないでしょうか。セキュリティ向上とのトレードオフとして十分に検討する価値があります。
まとめるとシークレットの管理方法としては下記が効率良さそうです。 実行環境でのシークレットの参照には基本的にSecret Managerを使い、その際、都度参照するとコストが嵩むのでインメモリキャッシュさせます。よりモダンな実行環境ではボリュームマウントやサイドカーパターンで構築することも検討します。 GitHub Secretsはクラウドへの権限借用の設定を保存したり、ビルドやデプロイ時に直接参照が必要な値を保存したりする用途に絞ります。こちらは生の値を参照できないので二重管理の運用コストが必要になることを意識します。
環境変数の管理
続いて環境変数の管理に焦点をあてます。環境変数の管理方法としては下記の3つのアプローチが思い浮かびました。
- GitHub Variables
- dotenv系ライブラリ
- AWS Parameter Store / Google Cloud Parameter Manager
GitHub Variablesはソースコードには含まれないものの、リポジトリの閲覧・管理権限を持つメンバーであれば設定画面から値を確認できてしまいます。先ほどの章で環境変数は秘匿性がない値と言い切りましたが、秘匿性があるかないかというのは実は会社のポリシー次第で扱いが変わります。そういった準秘匿な値が環境変数には設定されうるのでGitHub上で値を直接確認できてしまうのは好ましくありません。そもそもGitHub Secretsと同様にここはビルド&デプロイ時に参照する必要のある値をおくのが本筋であって実行環境に注入する値をおく必要性は薄いです。
dotenv系ライブラリはアプリケーションコードの中に.env.local, .env.test, .env.prodなどとファイルをおく方式です。こちらもリポジトリに公開される形で値が設定される点でセキュリティ的に推奨されない点は同様です。だいたいこのケースでは.gitignoreでdotenvファイルまたはその一部をGit管理外にしているケースも散見されます。しかしGit管理外にしてしまうということは、どこかに別途管理している鍵付きドキュメントがあり、こちらもシークレットと同様に二重管理運用を行う羽目になります。
環境変数の管理方法としてクラウドネイティブなアプローチでは、AWSならParameter Store、Google CloudならParameter Managerを利用することをおすすめします。 これらはGitHubのリポジトリに値をコミットして管理する必要がありません。また、Secret Manager同様にIAMによる厳密な公開管理が可能です。実行環境に環境変数としてまとめて注入することも可能です。また、シークレットと同じインターフェース(SDK)で値を一元管理・注入できるため、アプリケーションの構成がシンプルになります。 まとめると環境変数の管理方法としては下記のようになります。
- 実行環境への環境変数の注入はクラウドネイティブなパラメータストアを使う。
- GitHub Variablesはビルド&デプロイ時に参照する環境変数のみに絞って設定する。
コード内定数の管理
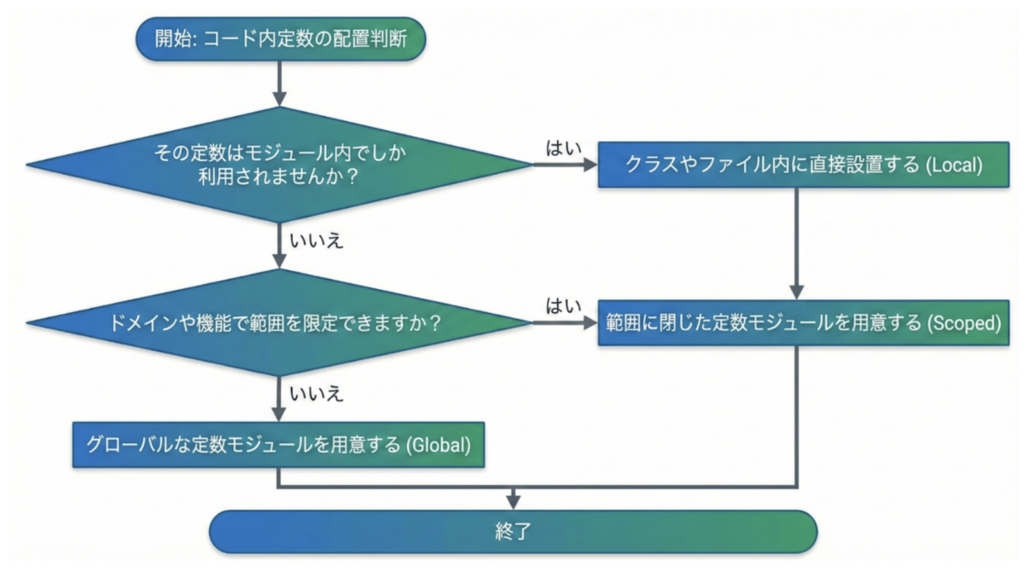
次に、コード内定数の管理方法について探っていきます。3通りの実装パターンが思い当たります。
- グローバルな定数管理用のモジュールを用意する
- 一定の範囲に閉じた定数管理用のモジュールを用意する
- ファイルやクラス内で定数を用意する
グローバルな定数管理用モジュールを用意する: constantsみたいなディレクトリやファイルを用意してそこで定数を集中管理する方法です。再利用性や一目でこのアプリケーションにはどのようなコード内定数があるのかという俯瞰ができます。反面、多くのモジュールがこの定数モジュールに依存するため密結合が増えテスタビリティを損ないます。また利用箇所から離れた箇所に定義があるため可読性が損なわれます。また、運用期間の経過ともに、あらゆる定数が雑多に放り込まれる神ファイルになりがちです。基本的には避けるべき最終手段です。
一定の範囲に閉じた定数管理用モジュールを用意する: ソースコードのルート直下ではなく特定のディレクトリ内で定数管理用のモジュールを用意します。グローバルな定数管理モジュールのメリットを活かしつつ、不要な密結合を局所的に減らす中間的なアプローチです。可読性が損なわれるデメリットも低減できますが解消されるわけではありません。
定数を利用するクラスやファイルに設置する: 利用する定数が近くにあるのでファイルやモジュールの依存は発生せず疎結合でテスタビリティを担保できます。その代わり定数の定義がアプリケーションコードの至る所に分散することになり重複定義に気が付きにくくなります。とはいえ、早すぎるDRYによって結合度が高まるリスクを考えれば、多少の重複は許容するという考え方も重要です。
どちらで定数管理するのかは両者のトレードオフを意識して判断しますが、対象の定数の影響範囲や意味を考えると判断の足掛かりとなります。ポイントは局所性の高い方から判断していく方針です。 こちらの判定フローもAIに意識してもらうようにすれば定数管理が散らかることなく整然と整理されることが期待できます。
コラム
.envにシークレットを含めるべきか
ローカル環境にはSecret Managerは存在しないので.envからシークレットの値を注入するアプローチが一般的です。しかし、私の設計ポリシーでは環境変数とシークレットを明確に区別します。これはローカル環境も例外ではありません。例えばクラウド環境でボリュームマウントしているのであればローカル環境ではsecrets/ディレクトリを.gitignoreしておき、マウント時と同様に構成しておきます。.envは環境変数のみに絞り、シークレットは別途管理にすることで設定読み込み用の実装にローカル環境の場合は環境変数を読み込むという条件分岐を書かずに済みます。環境変数をシークレットの代わりに使うのではなく何らかの手段でシークレットの参照をエミュレートできればそれが美しいというのが私の意見です。
管理方法
中身にダミー値が書いてあるdotenv系ライブラリを使ったり.env.exampleなどを用意しGit管理しておき、ファイルコピーして.envを作成し、値を手動で書き換えるアプローチはよく見かけますが設定が煩わしく、やはりどこかに値を管理する鍵付きドキュメントが存在することになります。テスト環境用のクラウドプロジェクトに存在するParameter Store/Parameter Managerでローカル用の.envファイルを保存しておき、Makefileなどで開発者のローカルマシン上にコピーできるようにしておけば便利になります。
環境変数とシークレットの実装
ここまで環境変数とシークレットは何者なのか、どのように管理すれば良いのかを整理しました。また、副産物としてコード内定数の管理方法についても触れました。ここからはそれらの実装に踏み込んだ内容を考えていきます。
中央集権で管理する
環境変数とシークレットに関しては外部注入される値なのでテスタビリティの担保が課題となります。 コードにインラインで外界からの参照を埋め込むとテストコードを書くときに困ります。1箇所で集中管理することで、DIによる依存性注入、インターフェースによるモック差し替えなどテスタビリティの担保が可能になります。
AIが生成するコードは関数やメソッド処理のインラインにos.Getenv(XXX)のような環境変数を直接参照する実装が埋め込まれる傾向が多いように感じます。この状態を許容するということはユニットテストの実装において環境変数を都度差し替えることにも繋がり大変です。こういうわけで、私はいつも環境変数やシークレットを集中管理するモジュールを先に実装し、そこを経由して参照するようにAIに意識してもらっています。
FailFast
値が設定されていない場合に明示的に失敗させる方針です。失敗させるとエラーが発生するため、一見よくないように思えますが、実際は逆の発想で、本番リリースより前の開発段階で設定不備に気がつくことができ、正しい値を設定して品質を向上できるというメリットがあります。「デフォルト値/オプショナル値を設定しているおかげでなんとなく開発環境で動いていたアプリケーションが、なぜか本番環境では止まってしまった」みたいな事故を未然に防ぐための実装ポリシーです。この方針を徹底するためには、基本的には不要なデフォルト値やオプショナル値を許容しません。つまり、環境変数やシークレットなど外部から注入する値は原則全て必須にします。
少し抽象的な話をさせていただきますと、デフォルト値やオプショナル値というものは、本質的には条件分岐と等価です。
- デフォルト値A’を設定した関数にAという値を渡したときの副作用はf(A)です。
- デフォルト値A’を設定した関数に何も渡さないときの副作用はf(A’)です。
- オプショナル値Bを設定した関数にBを渡したときの副作用はf(B)です。
- オプショナル値Bを設定した関数に何も渡さないときの副作用はf(null)です。
それぞれ2通りの入力と出力が発生している点に注目してください。これは、関数内でif文を書いていることと本質的に変わりません。
当然ながらコードを美しく保つには条件分岐はなるべく少ない方が良いわけです。そして、デフォルト値やオプショナル値はよくよく考えてみると設定しなくても良いケースが多いことに気がつくことができます。もちろん絶対禁止とまではいいませんが、これまで述べたトレードオフを意識した上で必要に応じて適切にデフォルト値やオプショナル値を設定することはいたって健全です。
AIにコーディングしてもらっているとこの点を軽視する傾向にあると感じます。AIにとって与えられた実装タスクに対するゴールはおおよそ「最短ステップで動くコードを実装する」ことに収斂します。つまり短期的な目標達成のためにデフォルト値やオプショナル値を設定して帳尻を合わせ「とりあえず動くコード」を実装しようとするクセがありそうだなというのが私の見立てです。私はAIの専門家ではないので、この点に関しては使ってみての経験則でしかなく原因についてはっきりとしたことは申し上げにくいですが、ソフトウェアエンジニアとしての対処法は明確です。それがFailFastを徹底させるようにAIに意識させることとなるわけです。
インメモリキャッシュ
毎回、Secret Manager/Parameter Managerや環境変数を参照しないようにしましょう。 ランタイム起動時に値のロードを行い、値が設定されているかどうかFailFastでチェックを行い、適切にセットされていなければすぐさまエラーにします。また、このバリデーションをクリアした場合はメモリ内の変数にセットを行い、再度参照する場合はその変数を見るようにします。
タイプセーフ & 値の合成
もし、型を明示できる言語であればこのタイミングで適切な型を割り当てましょう。できれば必ず値がセットされていることが保証できる型(non nullableな型)だと後続のコードでいちいち存在チェックを行わずに済みます。また、値を組み合わせて使う場合には組み立て後の値を用意しておくのも便利です。例えば「http://127.0.0.1:8080」を組み立てる必要があり、環境変数などの注入で「127.0.0.1」と「8080」をそれぞれ設定するのであれば周辺の関数なりメソッドで「http://127.0.0.1:8080」を返却してあげるユーティリティを生やしておくと便利です。
まとめ
この記事ではAIのコーディングをレビューするための審美眼をもつ必要があるという出発点に立ち、そもそも環境変数やシークレットとは何者なのか?どう管理すべきか?といった話題についてAIや人間といった実装主体は関係なく基本的な実装論に立ち返りました。そしてそれらの実装方針に対する意思決定のフローを明確化しました。具体的には下記です。
- シークレット、環境変数、コード内定数の違いと値の分類方法を整理しました。
- むやみやたらにこれらのシークレットや環境変数を増やさない方が良いというポリシーについて紹介させていただきました。
- 続いてこれらの値の管理方法について検討しました。
- 特にシークレットは初めから管理しなくて良い代替手段がないか検討するというポリシーについて紹介させていただきました。
- ローカル環境での.env系の取り扱い方について紹介させていただきました。
- 最後にこれらの値を参照する実装方針について紹介させていただきました。
ここまで読んでくださった皆様へのプレゼント
最後にこれを流行りのAgent Skillsに落とし込みましょう。手元のGeminiに出力してもらったSKILL.mdは下記のようになりました。皆様のコーディングの一助となれば幸いです。
1. 設定値の分類と管理スキル
--- name: config-value-classification description: シークレット、環境変数、コード内定数の適切な分類と管理方法を決定する。秘匿性と変動性を判断基準とする。 --- # 設定値の分類と管理の判断フロー このスキルは、コードに外部から注入する値をシークレット、環境変数、コード内定数のいずれで管理すべきかを判断し、実装方針を指示します。 ## 判断基準 | 分類 | 秘匿性 | 実行環境による変動の可能性 | 管理の原則 | | :--- | :--- | :--- | :--- | | シークレット | 必須 | 問わない | Secret Manager / GitHub Secrets (必要最小限) | | 環境変数 | なし | ある | Parameter Store / Parameter Manager | | コード内定数 | なし | ない | コード内の定数モジュール/クラス | ## AIへの指示事項 1. 秘匿性の確認: 値に秘匿性(APIキー、DBパスワードなど)があればシークレットとして扱い、後述の`secret-management-policy`スキルを適用する。 2. 変動性の確認: 秘匿性がなく、実行環境によって値が変動する可能性があれば環境変数として扱う。 3. コード内定数の適用: 秘匿性がなく、実行環境による変動の可能性がなければコード内定数として扱う。コード内定数は原則、最も局所性の高い場所(ファイル内、クラス内)で定義することを推奨する。
2. シークレット管理のモダン化スキル
--- name: secret-management-policy description: シークレット管理を最小化し、モダンな代替手段(IAM認証、Workload Identityなど)の採用を検討する。 --- # シークレット管理のモダン化 このスキルは、シークレットを持つこと自体の必要性を問い、持たなくて済むモダンなアプローチを提案します。 ## シークレット削減の検討事項 1. クラウドクレデンシャルキー: GitHub Secretsに生で置かず、AWS STS AssumeRoleやGoogle Cloud Workload Identityによる権限借用への移行を検討する。 2. APIキー: パブリックAPIはOAuth/OIDC、プライベートAPIはIAM認証への移行を検討する。WAFやApp Checkなどの多層防御は必須とする。 3. DBアカウント/パスワード: マネージドDB(RDS/Cloud SQLなど)であれば、IAM認証を利用してDB固有のパスワード管理を削減することを検討する。 ## シークレットの参照方針 - 実行環境: 基本的にSecret Managerを使用し、都度参照によるコスト増を避けるためインメモリキャッシュを実装する。 - CI/CD: GitHub Secretsはクラウドへの権限借用やCI/CD固有の値など、必要最小限に絞る。
3. 外部注入値の実装原則スキル
--- name: env-var-constant-impl description: 環境変数やシークレットを参照する際の実装における品質向上(中央集権、FailFast、キャッシュ、型安全)を徹底する。 --- # 環境変数とシークレットの実装原則 このスキルは、コード内で環境変数やシークレットを参照する際の実装品質を向上させるための原則を指示します。 ## 徹底すべき原則 1. 中央集権管理: `os.Getenv(XXX)`のような外界からの参照を関数やメソッドのインラインに埋め込まず、環境変数やシークレットを集中管理する専用モジュールを実装し、そこを経由して参照する。これにより、DI(依存性注入)やモックによるテスタビリティを担保する。 2. FailFastの徹底: 外部から注入する値は、原則として全て必須とする。値が設定されていない場合に、デフォルト値やオプショナル値を設定して処理を継続せず、ランタイム起動時に明示的に失敗(エラー)させる。 3. インメモリキャッシュ: 毎回、Secret Manager/Parameter Managerを参照せず、ランタイム起動時にロードしバリデーションをクリアした値はメモリ内の変数にセットして再利用する。 4. 型安全と値の合成: 可能であれば、値がセットされていることを保証できるnon-nullableな型を割り当てる。組み合わせて使う値(例: ホストとポート)は、組み立て後の完全な値(例: `http://127.0.0.1:8080`)を返却するユーティリティを用意する。
参考文献
- docs.github.com
- docs.github.com
- aws.amazon.com
- docs.aws.amazon.com
- cloud.google.com
- docs.cloud.google.com

