ATOM開発チームの上野です。
普段はGo言語を使ってAPIサーバやバッチ処理機構の実装などを担当しています。
ATOMには旧システムと新システムが存在しており、2026年現在も両者は並行運用されています。
システムのリニューアル版をリリースするにあたり、避けて通れなかったのがデータ移行の問題です。
当初から「一定期間は並行運用になる」こと自体は想定していましたが、実際に運用を続ける中で、その期間は想定よりもずっと長いものになっていきました。
今回は、旧システムを停止できない前提のもとで、新システムを提供し続けるために取り組んできた「定期的なデータ移行の仕組み」 と、その運用を5年間続けてきた中で直面した現実、判断、そして割り切りについて振り返ります。
なぜビッグバン移行を選ばなかったのか
システムリニューアルの背景は以下です (よくある理由)
- 長年蓄積した技術負債
- UI / UX の改善
- パフォーマンスや保守性の向上
一方で、旧システムを停止して一気に移行する、いわゆるビッグバン移行は避ける方針をとりました。 (ユーザを強制的に新システムへ移行させることによる解約リスクが高すぎた)
当時の議論では、「技術的には一気に移行した方が楽だ」という声も当然ありましたが 事業としてそれを許容することはできませんでした。
そこで、次のような作戦を立てました。
- 新旧システムを並行運用する
- 時間をかけて段階的にユーザに移行してもらう
- サポートを手厚くし、ユーザの負担を極力下げる
並行運用は「妥協」のように思われることもありましたが、当時の僕たちにとっては、最も現実的で責任のある選択だったと思っています。
並行運用を前提にしたデータ移行設計
新旧システムは、DBも含めて完全に独立した構成でした。
対象は数百テナント存在し、データ量が多いテーブルでは、数千万レコードに達するものもあります。
このデータを、ユーザ操作を極力伴わない形で、定期的に自動移行する仕組みを採用しました。
自動移行の基本方針
最初に定めた方針は、「ユーザにできるだけ意識させずに、裏側で安全に移行を進める」というものでした。具体的には、ユーザ操作を極力不要にし、定期的な自動同期を基本としつつ、新旧システム間のデータ構造差分は移行バッチ側で吸収する、という考え方です。
ただ、この方針は設計を進め、実装と運用を見据える中で、早い段階から壁に当たってしまいました。
データ構造の大きな違い
旧システムとリニューアル版では、データ構造が異なります。
例えば、旧システムではN-N(多対多)だった関連が、リニューアル版ではN-1(多対一)に変更されているケースがあります。
このようなデータは、単純なマッピングでは移行できません。
対応として、旧DBと新DBの間に「ステージング用の中間DB」を用意し、そこで変換処理を行いました。
中間DBを挟んだのは、変換や整形の処理を旧DB/新DBから切り離しておきたかったのと、
長期運用の中で再実行や原因追跡をしやすくするためです。(いわば移行の作業場)
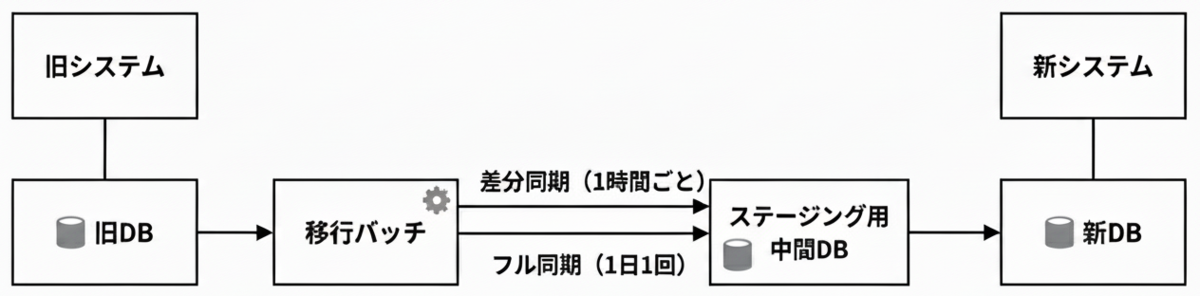
ただ、中間DBを挟み、変換処理を行なっても、すべての差分を機械的に吸収できるわけでなく
どうしても整理しきれないデータは残りました。
ここについては、「すべてを自動で解決しようとしない」と早めに割り切りました。具体的には、整理できないデータについてはユーザに手動で整合してもらう前提とし、その負担を下げるための補助機能や一括登録機能を新システム側に用意する、という判断です。
「可能な限り自動化したい」という気持ちは最後までありましたが、限界を認めることも、長期で回し続ける運用では重要だったと感じています。
データ量とDB負荷という現実
もう一つ、大きな壁になったのがデータ量とDB負荷です。
テナントごとにデータ量の差が非常に大きく、中には数百万レコードを超えるものもありました。全件同期を高頻度で回そうとすると、新システム側DBへの負荷が現実的ではなく、理論上は問題なく見えても、実運用では厳しい場面が何度もありました。
そこで、同期方式を2段階に分ける設計にしました。
同期モードの設計
| モード | 説明 | 頻度 |
|---|---|---|
| 差分同期 | タイムスタンプを基に変更分のみ移行。低負荷だが一部移行できない情報あり | 1時間ごと |
| フル同期 | 全データを再同期。高負荷だが確実に最新化できる | 1日1回 |
加えて、データ量が極端に多いテナントについては、同期頻度を落とすなどの個別調整も行いました。
この頃にはチーム内で、「すべてのユーザに、同じ移行戦略は通用しない」という共通認識ができていました。
実運用で起きたトラブル
運用が始まると、設計段階では想定しきれなかった問題も出てきました。
不要・不完全なデータまで移行してしまった
自動移行を優先した結果、
- リニューアル版では不要なデータ
- 明らかに不完全な状態のデータ
まで移行してしまうケースがありました。
この点については、「並行運用フェーズではある程度は許容する」と割り切り、完全移行のタイミングで最終的なデータクリーニングを行う方針としました。
移行を進める中では「このやり方で本当に良いのか」「負担をかけすぎていないか」と迷う場面も多くありました。ここではあくまで、並行運用フェーズにおける現実として、その難しさを受け止めながら進めていくしかありませんでした。
想定外データによるランタイムエラー
旧システムは歴史が長く、実際に運用を始めてみると、想定外データが原因で移行処理が止まることが頻発しました。
- 必須項目のはずが値が空
- 定義されていないenum値が入っている
なかなか旧システムの詳細な把握しきれず、動かしてみて初めて知るデータも多かったです。
結果として、継続的な監視や例外対応を積み重ねる運用が前提となり、場合によっては「このデータは移行しない」という判断も必要になりました。
運用の中で割り切った判断
運用の中で、いくつか重要な割り切りを行いました。
自動移行を破棄し、ゼロから登録し直す選択肢
旧システムの状態があまりに散らかっている場合、
- 自動移行しても使い勝手が悪い
- リニューアル版の価値を活かせない
というケースがありました。
そのため、
- 自動移行したデータをあえて破棄する
- 一括登録機能で整理済みデータを流し込む
という選択肢をユーザに提示しました。
結果として、クリーンな状態で使い始められた方が満足度が高いケースも少なくありませんでした。
自動移行の対象の見直し
当初はすべてのユーザのデータを自動移行の対象としていましたが、途中で方針を見直しました。
- 旧システムを使い続けるユーザが一定数存在
- 定期移行処理が無駄になる
- DB負荷と運用コストだけが増える
この状況を放置するのは現実的ではありませんでした。
そこで、
- 自動移行が必要なユーザに対象を絞る
- サポートデスクと連携し、移行タイミングを合わせる
という運用に切り替えました。
まとめ
継続的な自動移行は、顧客離れや炎上リスクを大きく下げてくれました。一方で、機械的な自動移行には明確な限界があり、例外対応や「移行しない」という判断を含めて運用として受け止める必要がありました。
また、「ユーザに負担をかけないこと」と「ユーザに頑張ってもらうこと」の線引きをどこに引くかが、運用の成否を大きく左右しました。すべてのユーザを同じ戦略で扱うのは難しく、ユーザごとに移行の進め方を調整する前提に立つ方が、結果的にうまく回りました。
最後に、リニューアルは不要なデータを捨てるチャンスでもあります。すべてのデータを無条件に移行することが、必ずしもユーザにとって良いとは限らず、場合によっては一度整理して入れ直した方が満足度が高いケースもありました。
移行期間中は我々にとっても、お客様にとっても決して楽な時間ではありませんが、リニューアル版を使っていただいた後に「以前より使いやすくなった」「業務が楽になった」といった声をいただくこともありました。すべてが順調だったわけではありませんが、この取り組みは無駄ではなかったと感じています。
同じように、旧システムを抱えたままリニューアルを進めている方にとって、本記事の経験談が「こういう進め方もあるのか」と考えるきっかけになれば幸いです。
