前回 は、VSCode(Visual Studio Code)で、CodeQL を使う方法について調べました。
CodeQL の挙動を理解するには、対象のソースコードを少し変更して、CodeQL の結果を確認する、を繰り返すことが必要そうです。しかし、これまで対象のソースコードとして、使いたいと考えていた Use-After-Free は、1関数しかなく、データフロー解析を試すことを考えると、少し使いにくいと感じました。そこで、今回は、GitHub に公開されている OSS のうち、軽めの HTTPサーバの実装である Tinyhttpd を調査します。これが CodeQL の対象ソースコードとして、使いやすいといいのですが、まだ分かりません。
それでは、やっていきます。
はじめに
「セキュリティ」の記事一覧です。良かったら参考にしてください。
・第2回:Ghidraで始めるリバースエンジニアリング(使い方編)
・第3回:VirtualBoxにParrotOS(OVA)をインストールする
・第4回:tcpdumpを理解して出力を正しく見れるようにする
・第5回:nginx(エンジンエックス)を理解する
・第6回:Python+Flask(WSGI+Werkzeug+Jinja2)を動かしてみる
・第7回:Python+FlaskのファイルをCython化してみる
・第8回:shadowファイルを理解してパスワードを解読してみる
・第9回:安全なWebアプリケーションの作り方(徳丸本)の環境構築
・第10回:Vue.jsの2.xと3.xをVue CLIを使って動かしてみる(ビルドも行う)
・第11回:Vue.jsのソースコードを確認する(ビルド後のソースも見てみる)
・第12回:徳丸本:OWASP ZAPの自動脆弱性スキャンをやってみる
・第13回:徳丸本:セッション管理を理解してセッションID漏洩で成りすましを試す
・第14回:OWASP ZAPの自動スキャン結果の分析と対策:パストラバーサル
・第15回:OWASP ZAPの自動スキャン結果の分析と対策:クロスサイトスクリプティング(XSS)
・第16回:OWASP ZAPの自動スキャン結果の分析と対策:SQLインジェクション
・第17回:OWASP ZAPの自動スキャン結果の分析と対策:オープンリダイレクト
・第18回:OWASP ZAPの自動スキャン結果の分析と対策:リスク中すべて
・第19回:CTF初心者向けのCpawCTFをやってみた
・第20回:hashcatの使い方(GPU実行時間の見積りとパスワード付きZIPファイル)
・第21回:Scapyの環境構築とネットワークプログラミング
・第22回:CpawCTF2にチャレンジします(クリア状況は随時更新します)
・第23回:K&Rのmalloc関数とfree関数を理解する
・第24回:C言語、アセンブラでシェルを起動するプログラムを作る(ARM64)
・第25回:機械語でシェルを起動するプログラムを作る(ARM64)
・第26回:入門セキュリhttps://github.com/SECCON/SECCON2017_online_CTF.gitティコンテスト(CTFを解きながら学ぶ実践技術)を読んだ
・第27回:x86-64 ELF(Linux)のアセンブラをGDBでデバッグしながら理解する(GDBコマンド、関連ツールもまとめておく)
・第28回:入門セキュリティコンテスト(CTFを解きながら学ぶ実践技術)のPwnable問題をやってみる
・第29回:実行ファイルのセキュリティ機構を調べるツール「checksec」のまとめ
・第30回:setodaNote CTF Exhibitionにチャレンジします(クリア状況は随時更新します)
・第31回:常設CTFのksnctfにチャレンジします(クリア状況は随時更新します)
・第32回:セキュリティコンテストチャレンジブックの「Part2 pwn」を読んだ
・第33回:セキュリティコンテストチャレンジブックの「付録」を読んでx86とx64のシェルコードを作った
・第34回:TryHackMeを始めてみたけどハードルが高かった話
・第35回:picoCTFを始めてみた(Beginner picoMini 2022:全13問完了)
・第36回:picoCTF 2024:Binary Exploitationの全10問をやってみた(Hardの1問は後日やります)
・第37回:picoCTF 2024:Reverse Engineeringの全7問をやってみた(Windowsプログラムの3問は後日やります)
・第38回:picoCTF 2024:General Skillsの全10問をやってみた
・第39回:picoCTF 2024:Web Exploitationの全6問をやってみた(最後の2問は解けず)
・第40回:picoCTF 2024:Forensicsの全8問をやってみた(最後の2問は解けず)
・第41回:picoCTF 2024:Cryptographyの全5問をやってみた(最後の2問は手つかず)
・第42回:picoCTF 2023:General Skillsの全6問をやってみた
・第43回:picoCTF 2023:Reverse Engineeringの全9問をやってみた
・第44回:picoCTF 2023:Binary Exploitationの全7問をやってみた(最後の1問は後日やります)
・第45回:書籍「セキュリティコンテストのためのCTF問題集」を読んだ
・第46回:書籍「詳解セキュリティコンテスト」のReversingを読んだ
・第47回:書籍「詳解セキュリティコンテスト」のPwnableのシェルコードを読んだ
・第48回:書籍「バイナリファイル解析 実践ガイド」を読んだ
・第49回:書籍「詳解セキュリティコンテスト」Pwnableのスタックベースエクスプロイトを読んだ
・第50回:書籍「詳解セキュリティコンテスト」Pwnableの共有ライブラリと関数呼び出しを読んだ
・第51回:picoCTF 2025:General Skillsの全5問をやってみた
・第52回:picoCTF 2025:Reverse Engineeringの全7問をやってみた
・第53回:picoCTF 2025:Binary Exploitationの全6問をやってみた
・第54回:書籍「詳解セキュリティコンテスト」Pwnableの仕様に起因する脆弱性を読んだ
・第55回:システムにインストールされたものと異なるバージョンのglibcを使う方法
・第56回:書籍「詳解セキュリティコンテスト」Pwnableのヒープベースエクスプロイトを読んだ
・第57回:書籍「解題pwnable」の第1章「準備」を読んだ
・第58回:書籍「解題pwnable」の第2章「login1(スタックバッファオーバーフロー1)」を読んだ
・第59回:書籍「解題pwnable」の第3章「login2(スタックバッファオーバーフロー2)」を読んだ
・第60回:書籍「解題pwnable」の第4章「login3(スタックバッファオーバーフロー3)」を読んだ
・第61回:書籍「解題pwnable」の第5章「rot13(書式文字列攻撃)」を読んだ
・第62回:GitHubが開発した静的解析ツール(脆弱性検出ツール)のCodeQLを使ってみる
・第63回:CodeQL(静的解析ツール)で使われるクエリの選ばれ方を調べた
・第64回:CodeQL(静的解析ツール)のクエリの書き方を調べた
・第65回:CodeQL(静的解析ツール)で使われているアラートクエリの中身を調べる
・第66回:CodeQL(静的解析ツール)で使われているパスクエリの中身を調べる
・第67回:CodeQL(静的解析ツール)をVSCodeで使う方法を理解する
・第68回:CodeQL(静的解析ツール)の挙動を確認するための対象ソースコードとしてTinyhttpdを調査する ← 今回
以下は、Tinyhttpd の GitHub です。
CodeQL を実行するためのソースコードとして、簡単すぎず、難しすぎず、かつ、外部から入力を受けるようなものを探しました。ChatGPT にいろいろ相談したところ、このソースコードを推薦されました。
なお、現在の実行環境は、Windows11 に、WSL2 で、Ubuntu 24.04 を入れた環境です。
Tinyhttpdの概要
Tinyhttpd は、シンプルなマルチスレッド対応の簡易 HTTPサーバで、GET/POST を受け付け、静的ファイル配信と CGI実行を行うことができます。
Tinyhttpdの動作を確認する
まずは、GitHub からソースコードを取得して、動作確認していきます。
クローンとビルドを行います。ビルドでは、いくつか警告が出ますが、まずは気にしないことにします。また、ビルドにより、Tinyhttpd の本体である httpd という実行ファイルと、簡易クライアント?の client という実行ファイルが生成されます。
$ git clone https://github.com/EZLippi/Tinyhttpd.git
$ cd Tinyhttpd/
$ make
では、実際に動かしていきます。
実行すると、4000番ポートでクライアントからのアクセスを待っている状態になります。
$ ./httpd
httpd running on port 4000
ここで、ビルドで生成されたクライアントを動かしてみます。
エラーになりました。
$ ./client oops: client1: Connection refused
ソースコードの simpleclient.c を見てみます。
ポート番号が、9734 となっており、サーバの設定(4000)と異なっていました。4000番ポートに修正して再ビルドします。
再度実行してみます。
何も反応がありません。
$ ./client ^C
仕方ないので、VSCode で、サーバ側をデバッガで動かして、動作を確認しました。
クライアントは、1文字だけ、'A' を送っていて、それは受信できていました。その後、サーバは、次の文字を待ち続けていました。
クライアントを終了すると、サーバの recv関数から応答が返り、何も受信しなかったことが分かります。
このクライアントソフトは、何を目的としているのか分かりません。おそらくデバッグ用途だと思います(まともな動作は、そもそも期待してない)。
では、このクライアントソフトで動作確認するのは諦めて、普通のブラウザを使って確認したいと思います。
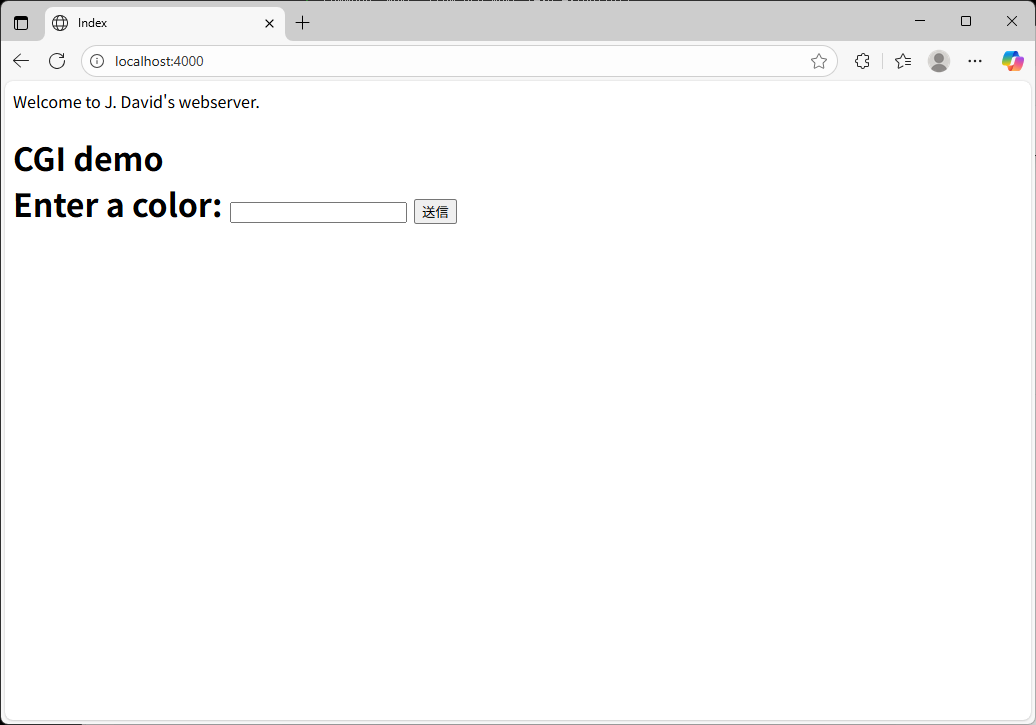
ブラウザを起動して、http://localhost:4000/ にアクセスします。すると、以下の画面が表示されました。ここまでは、正しく動作してるようです。
入力フォームに red と入力して、送信ボタンをクリックしてみます。
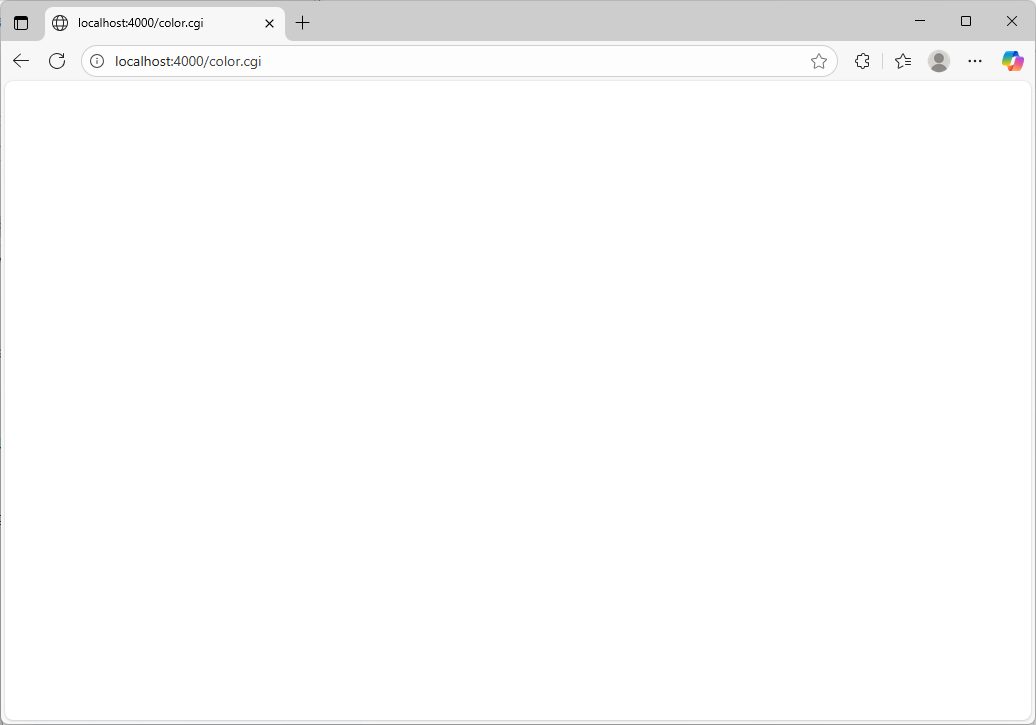
うまく動いていないようです。
いくつか修正しました。
まずは、htdocs/color.cgi と、htdocs/check.cgi に実行権限がなかったので、以下を実行しました。
$ chmod +x htdocs/check.cgi $ chmod +x htdocs/color.cgi
htdocs/color.cgi と、htdocs/check.cgi の内容を見ると、シェバン行が #!/usr/local/bin/perl -Tw となってますが、私の環境では、perl は、/usr/bin/perl だったので、パスを修正しました。
まだ動かないので、CGIファイルを直接実行してみました。
ChatGPT に原因を聞いてみると、CGIモジュールがインストールされてないということでした。
$ REQUEST_METHOD=GET QUERY_STRING=color=red htdocs/color.cgi Can't locate CGI.pm in @INC (you may need to install the CGI module) (@INC entries checked: /etc/perl /usr/local/lib/x86_64-linux-gnu/perl/5.38.2 /usr/local/share/perl/5.38.2 /usr/lib/x86_64-linux-gnu/perl5/5.38 /usr/share/perl5 /usr/lib/x86_64-linux-gnu/perl-base /usr/lib/x86_64-linux-gnu/perl/5.38 /usr/share/perl/5.38 /usr/local/lib/site_perl) at htdocs/color.cgi line 4. BEGIN failed--compilation aborted at htdocs/color.cgi line 4.
CGIモジュールをインストールします。
$ sudo apt install libcgi-pm-perl
もう一度、CGIファイルを実行してみます。
ちゃんと HTML が返ってきてるので、うまくいってるようです。
$ REQUEST_METHOD=GET QUERY_STRING=color=red htdocs/color.cgi Content-Type: text/html; charset=ISO-8859-1 <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"> <html xmlns="http://www.w3.org/1999/xhtml" lang="en-US" xml:lang="en-US"> <head> <title>RED</title> <meta http-equiv="Content-Type" content="text/html; charset=iso-8859-1" /> </head> <body bgcolor="red"> <h1>This is red</h1> </body> </html>
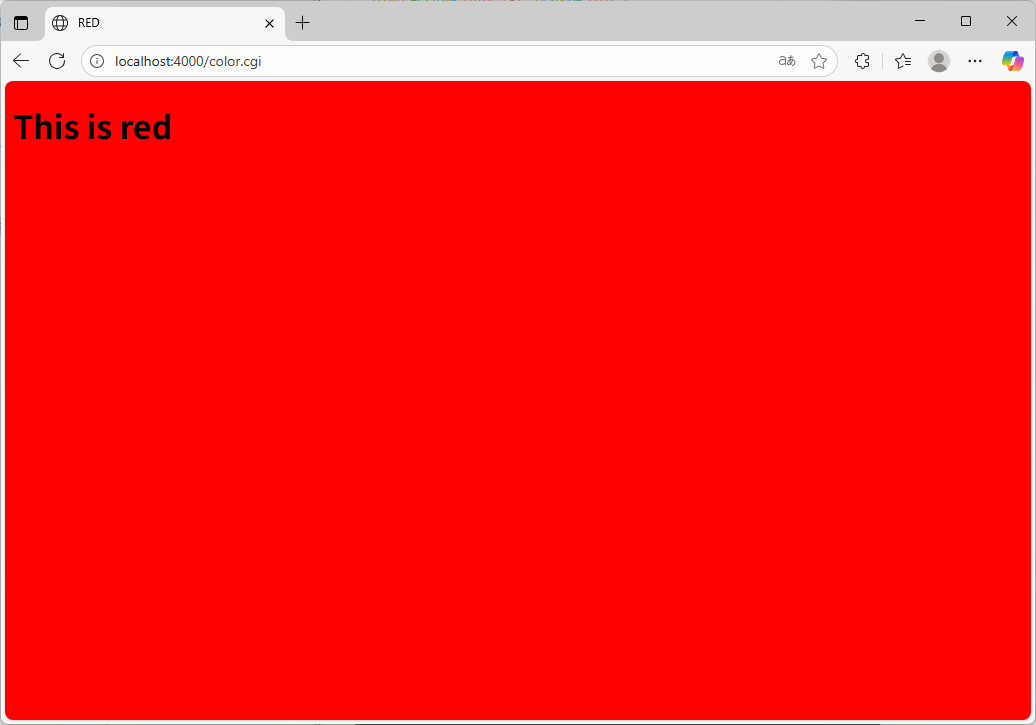
では、httpd を実行してみます。うまく動きました。
Tinyhttpdの詳細
ここからは、Tinyhttpd のソースコードを見ていきます。
main関数
まずは、main関数です。
コメントで、add と書いたところと、debug と書いたところは、私が追加したところです。add の方は、通常は初期化されるところなので、入れておきました。debug の方は、クライアントが接続してきたときに、クライアントの情報を表示しています。
startup関数は後述しますが、TCPサーバとしてのソケットの初期化を行っています。その後、while の無限ループに入ります。
ループ内では、accept関数で、クライアントからの接続を受け付け、クライアントごとに、 pthread_create関数で、スレッドを作成して、そのスレッドにクライアントの処理を任せています。
int main(void) { int server_sock = -1; u_short port = 4000; int client_sock = -1; struct sockaddr_in client_name; socklen_t client_name_len = sizeof(client_name); pthread_t newthread; server_sock = startup(&port); printf("httpd running on port %d\n", port); memset(&client_name, 0, sizeof(client_name));// add while (1) { client_sock = accept(server_sock, (struct sockaddr *)&client_name, &client_name_len); if (client_sock == -1) error_die("accept"); { // debug char buf[INET_ADDRSTRLEN] = {}; inet_ntop(AF_INET, &client_name.sin_addr, buf, sizeof(buf)); printf("accept from %s:%u\n", buf, ntohs(client_name.sin_port)); fflush(stdout); } /* accept_request(&client_sock); */ if (pthread_create(&newthread , NULL, (void *)accept_request, (void *)(intptr_t)client_sock) != 0) perror("pthread_create"); } close(server_sock); return(0); }
startup関数
次は、startup関数です。
普通の TCPサーバの実装です。上位関数からポート番号 0 で指定された場合は、動的にポートを割り当てています。
listen関数で、クライアントを 5つまで受け付けています。
int startup(u_short *port) { int httpd = 0; int on = 1; struct sockaddr_in name; httpd = socket(PF_INET, SOCK_STREAM, 0); if (httpd == -1) error_die("socket"); memset(&name, 0, sizeof(name)); name.sin_family = AF_INET; name.sin_port = htons(*port); name.sin_addr.s_addr = htonl(INADDR_ANY); if ((setsockopt(httpd, SOL_SOCKET, SO_REUSEADDR, &on, sizeof(on))) < 0) { error_die("setsockopt failed"); } if (bind(httpd, (struct sockaddr *)&name, sizeof(name)) < 0) error_die("bind"); if (*port == 0) /* if dynamically allocating a port */ { socklen_t namelen = sizeof(name); if (getsockname(httpd, (struct sockaddr *)&name, &namelen) == -1) error_die("getsockname"); *port = ntohs(name.sin_port); } if (listen(httpd, 5) < 0) error_die("listen"); return(httpd); }
accept_request関数
accept_request関数は、先ほど、pthread_create関数で作成したスレッド関数です。私の方で、いくつかコメントを付けています。
get_line関数で、クライアントから受信した 1行を取得しています(numchars は取得した文字数)。その後の printf関数は私が追加しました。
最初の while文は、スペースが見つかるまで、文字列を取得しています。先頭は、GET か POST を期待しています。いずれにもマッチしない場合は、エラーを返す unimplemented関数を実行しています。
GET or POST で、POST なら cgiフラグをセットしておきます。その後、空白を読み飛ばした後、URL を読み出します。
次は、GET の場合の処理です。先ほど取得した URL を解析します。URL に ? が含まれている場合は、? を \0 に変更して、query_stringポインタに、? の次の位置に設定して、cgiフラグをセットしておきます。
sprintf関数で、要求されたパスを、htdocsディレクトリ内のパスとして、path変数に格納しています。末尾が / の場合、index.html の文字列を追加しておきます。
stat関数で、要求されたパスのファイルが存在しない場合、受信データを全て読み出した後、エラーを表示する not_found関数を実行します。
ファイルが存在した場合、かつ、ディレクトリだった場合は、index.html の文字列を追加します。そのファイルが実行可能なファイルだったら、cgiフラグをセットします。
最後に、cgiフラグがセットされていたら、execute_cgi関数を実行し、そうでなければ、serve_file関数を実行します。
void accept_request(void *arg) { int client = (intptr_t)arg; char buf[1024]; size_t numchars; char method[255]; char url[255]; char path[512]; size_t i, j; struct stat st; int cgi = 0; /* becomes true if server decides this is a CGI * program */ char *query_string = NULL; numchars = get_line(client, buf, sizeof(buf)); printf("get_line(): numchars=%ld\n", numchars); i = 0; j = 0; while (!ISspace(buf[i]) && (i < sizeof(method) - 1))// 先頭は GET or POST のはず { method[i] = buf[i]; i++; } j=i; method[i] = '\0'; if (strcasecmp(method, "GET") && strcasecmp(method, "POST"))// いずれにも一致しなければエラーを返す { unimplemented(client); return; } if (strcasecmp(method, "POST") == 0) cgi = 1; i = 0; while (ISspace(buf[j]) && (j < numchars))// 空白を読み飛ばす j++; while (!ISspace(buf[j]) && (i < sizeof(url) - 1) && (j < numchars))// URL読み込み { url[i] = buf[j]; i++; j++; } url[i] = '\0'; if (strcasecmp(method, "GET") == 0) { query_string = url; while ((*query_string != '?') && (*query_string != '\0')) query_string++; if (*query_string == '?') { cgi = 1; *query_string = '\0'; query_string++; } } sprintf(path, "htdocs%s", url); if (path[strlen(path) - 1] == '/') strcat(path, "index.html"); if (stat(path, &st) == -1) { while ((numchars > 0) && strcmp("\n", buf)) /* read & discard headers */ numchars = get_line(client, buf, sizeof(buf)); not_found(client); } else { if ((st.st_mode & S_IFMT) == S_IFDIR) strcat(path, "/index.html"); if ((st.st_mode & S_IXUSR) || (st.st_mode & S_IXGRP) || (st.st_mode & S_IXOTH) ) cgi = 1; if (!cgi) serve_file(client, path); else execute_cgi(client, path, method, query_string); } close(client); }
get_line関数
get_line関数は、クライアントから受信した 1行を上位に返します。
通常の HTTP のデータは、改行コードが、\r\n ですが、この関数は、\r や、\n にも対応しています。どの改行コードを受信したとしても、buf に格納するのは \n です。
途中のところは、コメントで説明を付けておきました。末尾に、\0 を入れて、この関数は終了します。
int get_line(int sock, char *buf, int size) { int i = 0; char c = '\0'; int n; while ((i < size - 1) && (c != '\n'))// -1 は、末尾に \0 を入れるため { n = recv(sock, &c, 1, 0);// 第4引数はflags /* DEBUG printf("%02X\n", c); */ if (n > 0) { if (c == '\r')// \n、\r\n、\r いずれの場合も \n とする { n = recv(sock, &c, 1, MSG_PEEK);// MSG_PEEK:読まずに覗く /* DEBUG printf("%02X\n", c); */ if ((n > 0) && (c == '\n')) recv(sock, &c, 1, 0);// \r\nの場合 else c = '\n';// \rの場合 } buf[i] = c; i++; } else c = '\n'; } buf[i] = '\0'; return(i);// \n を含む文字数 }
serve_file関数
accept_request関数から呼ばれている serve_file関数です。CGIファイルではない、通常の HTMLファイルを表示します。
whileループ前に、buf に設定しているのは、while の条件を満たすためだと思います。do while を使えばいいだけのような気がします。リクエストの残りを全て読むために、読み飛ばしています。
上位から与えられたファイルパスに対して、ファイルオープンして、headers関数と、cat関数を呼び出しています。
void serve_file(int client, const char *filename) { FILE *resource = NULL; int numchars = 1; char buf[1024]; buf[0] = 'A'; buf[1] = '\0'; while ((numchars > 0) && strcmp("\n", buf)) /* read & discard headers */ numchars = get_line(client, buf, sizeof(buf)); resource = fopen(filename, "r"); if (resource == NULL) not_found(client); else { headers(client, filename); cat(client, resource); } fclose(resource); }
headers関数
serve_file関数から最初に呼び出されている headers関数です。
HTTP のレスポンスのヘッダ部分を送信しています。ヘッダの末尾には、\r\n だけの行が必要だったと思いますので、そこもちゃんと送信しています。
void headers(int client, const char *filename) { char buf[1024]; (void)filename; /* could use filename to determine file type */ strcpy(buf, "HTTP/1.0 200 OK\r\n"); send(client, buf, strlen(buf), 0); strcpy(buf, SERVER_STRING); send(client, buf, strlen(buf), 0); sprintf(buf, "Content-Type: text/html\r\n"); send(client, buf, strlen(buf), 0); strcpy(buf, "\r\n"); send(client, buf, strlen(buf), 0); }
cat関数
serve_file関数から呼び出されている、もう1つの関数の cat関数です。
HTTP のレスポンスのボディ部分を送信しています。こちらも、do while が好きじゃないのか、fgets関数が、2回登場します。
ファイルの内容をそのまま出力しているだけですね。
void cat(int client, FILE *resource) { char buf[1024]; fgets(buf, sizeof(buf), resource); while (!feof(resource)) { send(client, buf, strlen(buf), 0); fgets(buf, sizeof(buf), resource); } }
execute_cgi関数
accept_request関数から呼ばれている、もう 1つの関数の serve_file関数です。CGIプログラムを実行します。
これまでで一番難しい関数ですね。
最初は、GET と POST で分岐します。GET の方は、リクエストボディが存在しないので、残りのリクエストを読み飛ばします。POST の方は、Content-Length を見つけたときは、その値を読み取り、\n が出現した時点でループを抜けます(受信データには、リクエストボディが残っている)。
次に、この後、fork で、子プロセスを生成しますが、親子のプロセス間で通信するために、ここで、パイプを 2つ生成します。子プロセスは実際に CGIファイルを実行します。cgi_output は、子プロセスの出力用(親プロセスは入力となる)で、cgi_input は、子プロセスの入力用(親プロセスは出力となる)です。パイプは読み書き両用はできないので、読み込み用、書き込み用の 2つを用意する必要があります。
fork関数を実行すると、子プロセスが生成されます。親プロセス、子プロセス、ともに、fork関数の呼び出しから戻ります。親プロセス側は、fork関数の戻り値として、子プロセスのプロセスID が返って、子プロセス側は、fork関数の戻り値は 0 になります。これにより、同じソースコードでも、親プロセスと子プロセスで処理を分けることができます。
その後、両方のプロセスが、HTTPリクエストの応答を返しています。うーん、この場合は親プロセスだけが応答を返せばいいと思うのですが、、、ちょっと理由が分かりません。
まず、pid が 0 の場合の子プロセス側の処理から見ていきます。
まず、dup2関数で、子プロセスの書き込み用のパイプを、標準出力として複製します。これにより、子プロセスが標準出力に出力する(printf関数などを使って)と、親プロセスとのパイプにも書き込まれることになります。さらに、dup2関数を実行して、子プロセスの読み取り用のパイプを標準入力として複製します。その後、使用しない方のパイプ(親プロセスが使用する)をクローズしておきます。
次は、putenv関数を使って、環境変数の設定を行います。REQUEST_METHOD に GET or POST を設定します。その後、GET の場合は、QUERY_STRING に ? 以降の内容を設定します。POST の場合は、CONTENT_LENGTH に先ほど取得した内容を設定します。
最後に、execl関数を使って、CGIファイルを実行します。
次に、親プロセス側です。最初に、子プロセス側と同様に、使わないパイプをクローズします。
POST の場合、リクエストボディを Content-Length の分だけ読み出し、子プロセスに送信します。あとは、子プロセスから書き込みがあると、その内容をクライアントに送信するループを実行します。CGIプログラムが終了すると、ループを抜けて、パイプをクローズして、子プロセスの終了ステータスを読み出して終了します。
void execute_cgi(int client, const char *path, const char *method, const char *query_string) { char buf[1024]; int cgi_output[2]; int cgi_input[2]; pid_t pid; int status; int i; char c; int numchars = 1; int content_length = -1; buf[0] = 'A'; buf[1] = '\0'; if (strcasecmp(method, "GET") == 0) while ((numchars > 0) && strcmp("\n", buf)) /* read & discard headers */ numchars = get_line(client, buf, sizeof(buf)); else if (strcasecmp(method, "POST") == 0) /*POST*/ { numchars = get_line(client, buf, sizeof(buf)); while ((numchars > 0) && strcmp("\n", buf)) { buf[15] = '\0'; if (strcasecmp(buf, "Content-Length:") == 0) content_length = atoi(&(buf[16])); numchars = get_line(client, buf, sizeof(buf)); } if (content_length == -1) { bad_request(client); return; } } else/*HEAD or other*/ { } if (pipe(cgi_output) < 0) { cannot_execute(client); return; } if (pipe(cgi_input) < 0) { cannot_execute(client); return; } if ( (pid = fork()) < 0 ) { cannot_execute(client); return; } sprintf(buf, "HTTP/1.0 200 OK\r\n"); send(client, buf, strlen(buf), 0); if (pid == 0) /* child: CGI script */ { char meth_env[255]; char query_env[255]; char length_env[255]; dup2(cgi_output[1], STDOUT); dup2(cgi_input[0], STDIN); close(cgi_output[0]); close(cgi_input[1]); sprintf(meth_env, "REQUEST_METHOD=%s", method); putenv(meth_env); if (strcasecmp(method, "GET") == 0) { sprintf(query_env, "QUERY_STRING=%s", query_string); putenv(query_env); } else { /* POST */ sprintf(length_env, "CONTENT_LENGTH=%d", content_length); putenv(length_env); } execl(path, NULL); exit(0); } else { /* parent */ close(cgi_output[1]); close(cgi_input[0]); if (strcasecmp(method, "POST") == 0) for (i = 0; i < content_length; i++) { recv(client, &c, 1, 0); write(cgi_input[1], &c, 1); } while (read(cgi_output[0], &c, 1) > 0) send(client, &c, 1, 0); close(cgi_output[0]); close(cgi_input[1]); waitpid(pid, &status, 0); } }
htdocs/index.htmlファイル
トップページの index.htmlファイルです。
color.cgi が使われています。
<HTML> <TITLE>Index</TITLE> <BODY> <P>Welcome to J. David's webserver. <H1>CGI demo <FORM ACTION="color.cgi" METHOD="POST"> Enter a color: <INPUT TYPE="text" NAME="color"> <INPUT TYPE="submit"> </FORM> </BODY> </HTML>
htdocs/color.cgi
index.html で実行されている color.cgi です。
perl は、かなり前にやってましたが、すっかり忘れたので、ChatGPT に解説してもらいました。
シェバンのオプションの T は、taint(汚染)チェックを有効化している、とのことで、セキュリティ強化の意味だそうです。もう1つのオプションの w は、警告を有効化しているそうです。
use strict は、文法の厳格化で、use CGI は、CGIモジュールの読み込みだそうです。
あとは、コメントに書きました。
#!/usr/bin/perl -Tw use strict; use CGI; my($cgi) = new CGI; # CGIオブジェクトの生成 print $cgi->header; # Content-Type: text/html などの HTTPヘッダ出力 my($color) = "blue"; # 初期値設定 $color = $cgi->param('color') if defined $cgi->param('color'); # colorパラメータがあれば上書き print $cgi->start_html(-title => uc($color), -BGCOLOR => $color); # <html><head><title>…</title><body> を生成、タイトルと背景色を $color に設定 print $cgi->h1("This is $color"); # h1タグの出力 print $cgi->end_html; # </body></html> を出力
おわりに
今回は、GitHub に公開されている OSS のうち、軽めの HTTPサーバの実装である Tinyhttpd を調査しました。実際に動かすまでに、いろいろと対応する必要があったので、少し時間がかかりました。また、関数の説明については、主要なところは書きましたが、必要に応じて追加しようと思います。
次回は、Tinyhttpd に手を加えて、CodeQL の結果がどう変わっていくのかを調査したいと思います。
最後になりましたが、エンジニアグループのランキングに参加中です。
気楽にポチッとよろしくお願いいたします🙇
今回は以上です!
最後までお読みいただき、ありがとうございました。
