生成AI の書籍がたくさん出てきています。今回は、世の中から遅れないように、LangChainとLangGraphによるRAG・AIエージェント[実践]入門 エンジニア選書 を読みながら、OpenAI の GPT をAPI から使っていこうと思います。
では、やっていきます。
参考文献
LangChainとLangGraphによるRAG・AIエージェント[実践]入門 エンジニア選書 は、2024年11月に出版されています。475ページぐらいあります。扱っているモデルは、OpenAI の「gpt-4o」なので、少し古いですが、Python を使って、簡単な LLMアプリケーションを動かすところから、AIエージェント開発まで、幅広く扱っています。LLMアプリ開発を初めて行うときに、とても役立つと思います。
LangChainとLangGraphによるRAG・AIエージェント実践入門
LangChainとLangGraphによるRAG・AIエージェント[実践]入門 エンジニア選書 に掲載されているプログラムは、以下の GitHub で公開されています。
この書籍に従って、OpenAI の API を使って、LLMアプリケーションを動かす場合、必ず料金がかかります。普段、ChatGPT を使う場合は、少し使うだけなら無料ですが、OpenAI の API を使って、LLMアプリケーションを動かす場合、APIキーを取得して、事前に料金をチャージしないと、OpenAI の API が動きません。チャージの最低金額が 5ドルです。従量課金であり、5ドル分である程度は使えますので、そんなに高いわけではありません。
それでは、以降からは、書籍の章立てに従って、進めていきたいと思います。
第1章:LLMアプリケーション開発の基礎
この章では、LLMアプリケーションについて、これまで起こってきたことを振り返り、今後に必要になっていく AIエージェントの概要について触れています。
2023年は、社内ドキュメントを検索して、質問に対して回答する RAG を用いたシステムが、多くの企業に導入された年だったそうです(この書籍は、2024年11月に発売されています)。
AIエージェントは、正確な定義はまだ固まってなさそうですが、この書籍では、OpenAI の API と、それを扱う LangChain について、実践的な内容を解説していくとのことです。
第2章:OpenAIのチャットAPIの基礎
この書籍では、OpenAI の GPT-4o、GPT-4o-mini というモデルを対象としています。これらはモデルファミリーと呼ばれ、実際のモデルは、継続的にアップグレードされており、「gpt-4o-2024-08-06」や、「gpt-4o-mini-2024-07-18」などのモデルが使われます。ちなみに、GPT-4o の「o」は、「omni」の略であり、テキストの入出力だけでなく、画像、動画、音声といったマルチモーダルな入出力を含んでいることを指しているそうです。
ここで、書籍の内容ではありませんが、本日(2025/10/18)時点の OpenAI のモデルと、その料金について見てみました。
これによると、最新のモデルファミリーは、GPT-5、GPT-5 mini、GPT-5 nano、GPT-5 pro があるようです。以下に簡単に料金をまとめます。それぞれは、1Mトークン(100万トークン)あたりの料金です。
| モデル | 入力 | キャッシュされた入力 | 出力 |
|---|---|---|---|
| GPT-5 | $1.250 | $0.125 | $10.000 |
| GPT-5 mini | $0.250 | $0.025 | $2.000 |
| GPT-5 nano | $0.050 | $0.005 | $0.400 |
| GPT-5 pro | $15.00 | $120.00 |
トークンについて触れておきます。テキストをモデルに入力する際、トークンと呼ばれる単位に分割されます。ライブラリが分割するため、1文字が何トークンとか、1単語が何トークンかを言うことはできませんが、目安として、日本語の場合、1文字が 1 から 3トークンになるようで、英語に比べてトークン数が多くなるようです。
書籍の内容に戻ります。
OpenAI のテキスト生成の API には、「Completions API」と、「Chat Completions API」があり、前者は従来使われていたもので、今後は後者が使われるということで、この書籍では、後者の解説を行っています。
後で分かったことですが、OpenAI のサイトにアクセスし、ドキュメント(Docs)を見ると、「Chat Completions API」から、「Responses API」というものが使われていました。以下に、o3 や、GPT-5 などの推論モデルで、優れたパフォーマンスを発揮するとあります。
今後出版される書籍は、「Responses API」を使った内容に変わっていくことになりそうです。
OpenAIのAPIキーの取得
ここからは、OpenAI の API を使うために、OpenAI の公式サイトで、アカウント登録を行い、OpenAI の APIキーを取得する手順が書かれています。Web の ChatGPT は無料で使えますが、API を使うと基本的には料金が発生します。
以下のサイトにアクセスします。
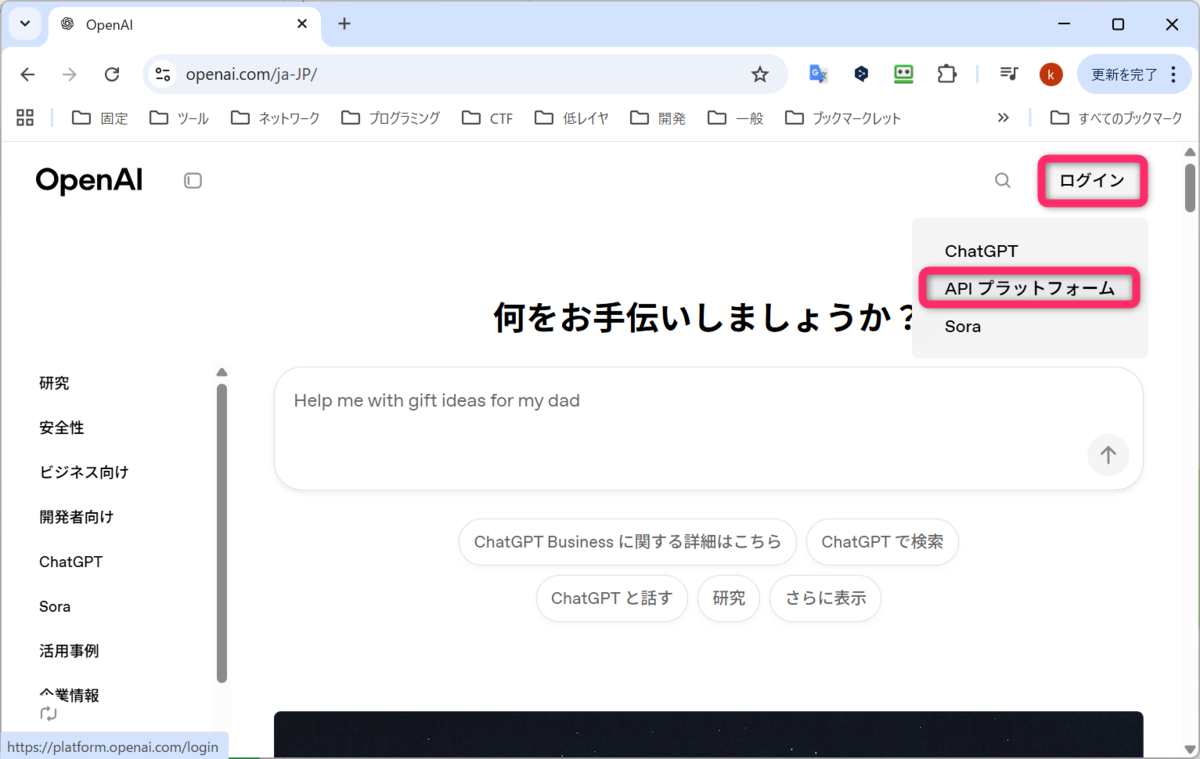
画面右上のログインの APIプラットフォームをクリックします。
- アカウントを持っていない場合
サインアップをクリックします。
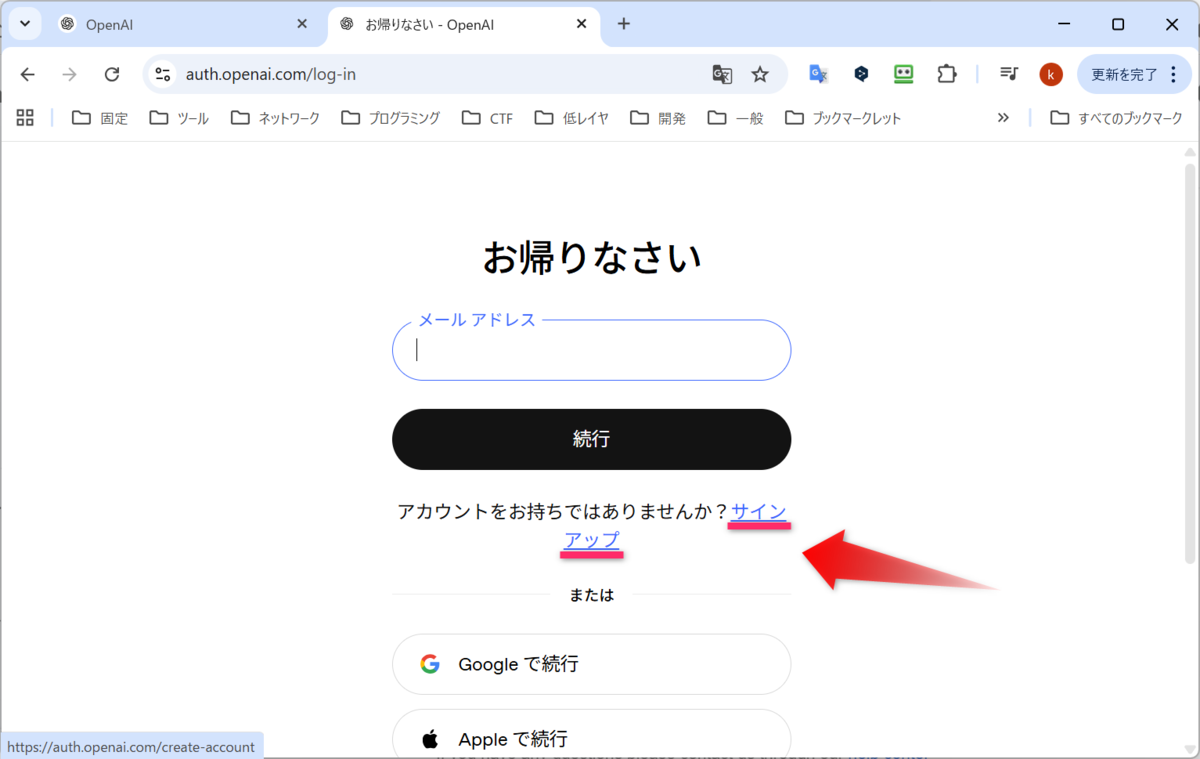
メールアドレスを入力して、続行をクリックします。
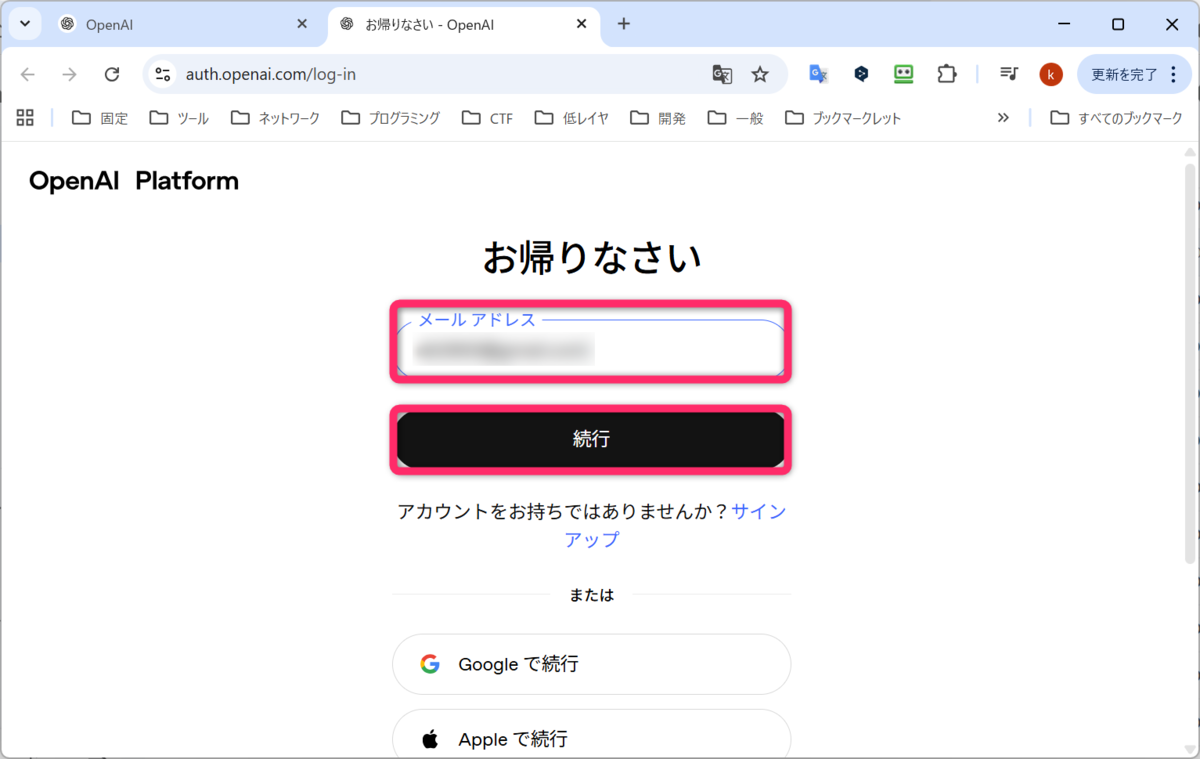
- アカウントを持っている場合
メールアドレスを入力して、続行をクリックします。
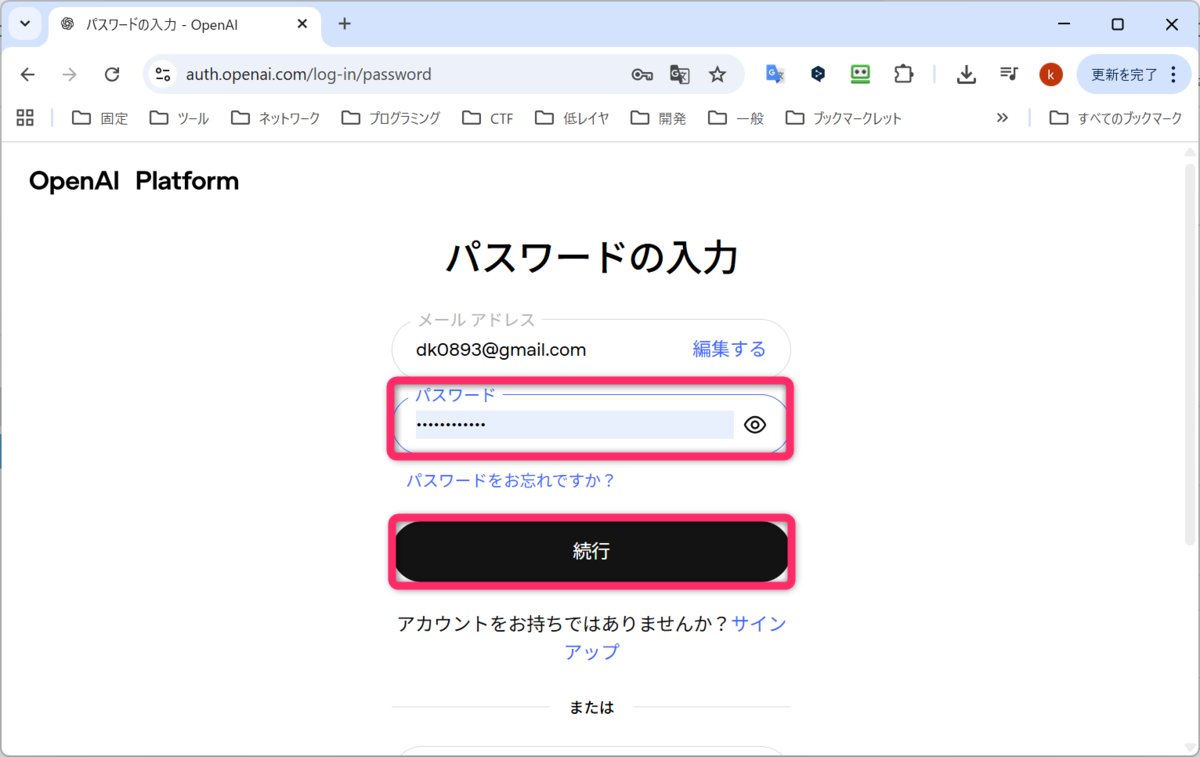
続いて、パスワードを入力して、続行をクリックします。
登録してるメールアドレスに、6桁の検証コードが届くと思うので、入力して、続行をクリックします。

無事にログインできました。続いて、Get started をクリックします。
続いて、Create an API Key をクリックします。
続いて、Create new secret key をクリックします。画面右上と画面中央に同じボタンがありますが、どちらも同じだと思います。私は画面中央の方をクリックしました。
Name を入力できますが、Optional なので、私は何も入力せずに、Create secret key をクリックしました。
APIキーが生成されました。Copy を押して、大事なところで管理しましょう。終わったら、Done をクリックします。
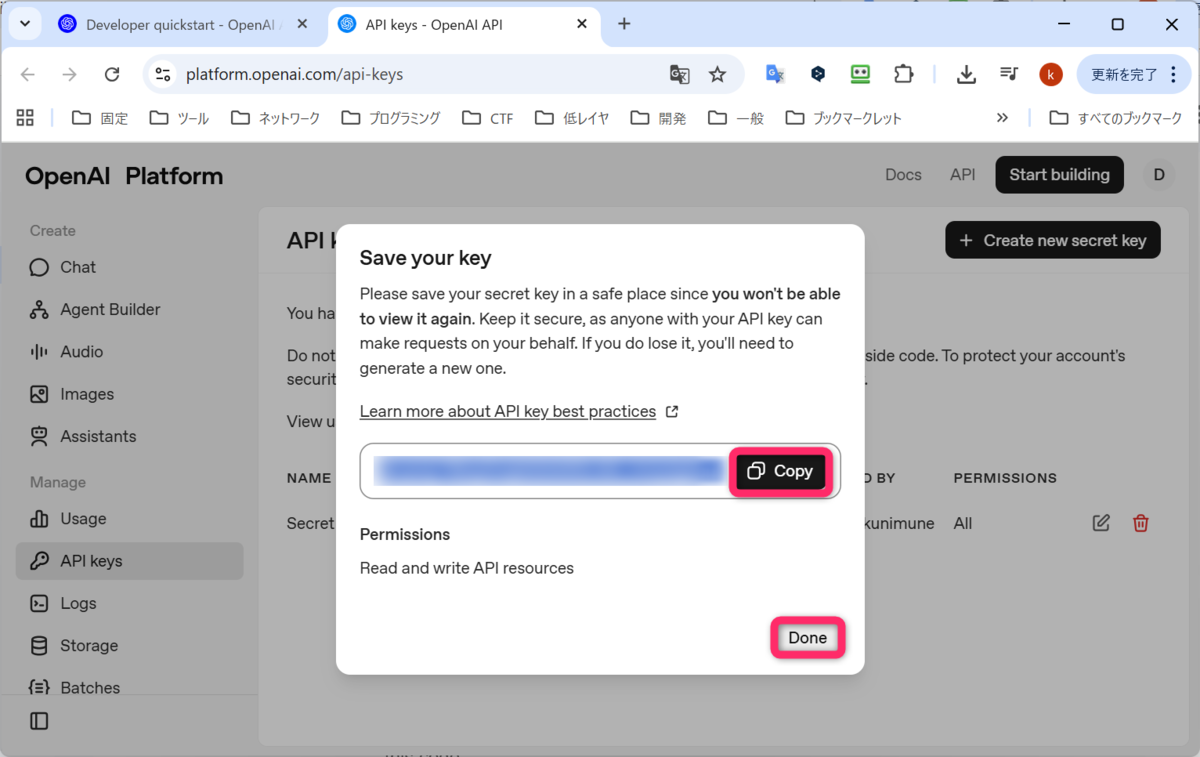
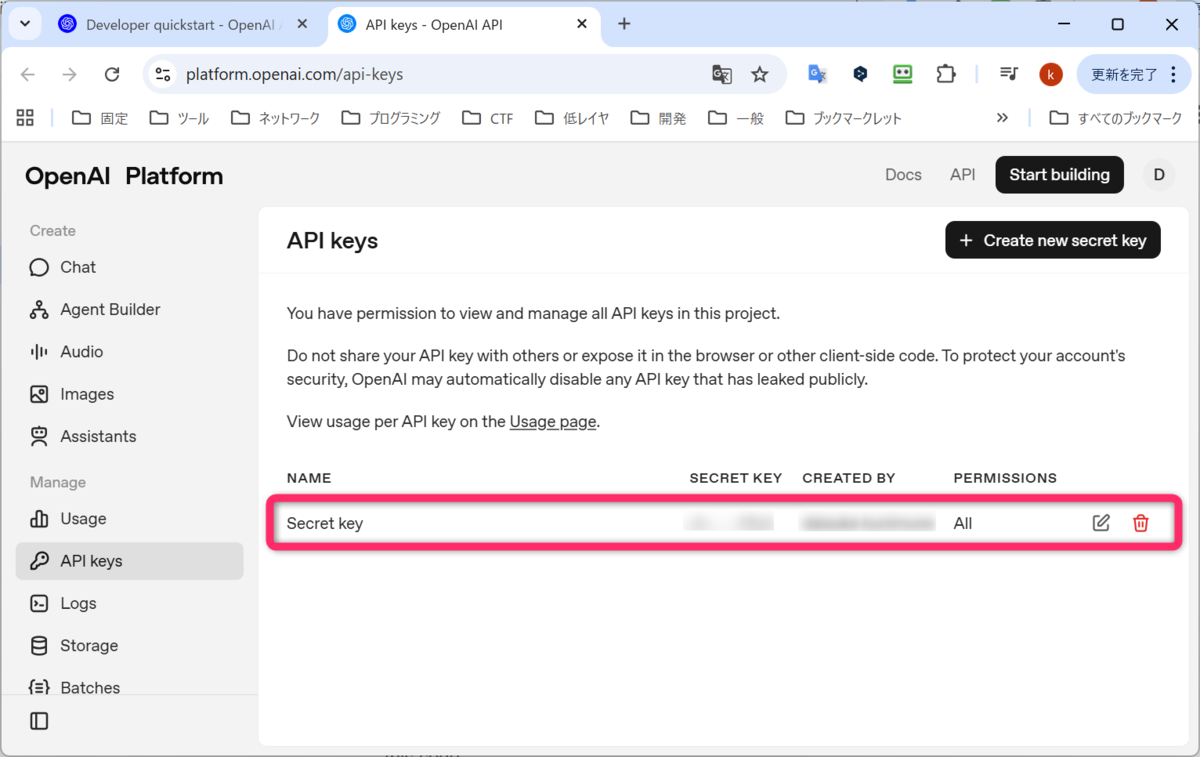
Create new secret key を押す前の画面に戻り、Secret key が、1行出来ていました。APIキーの発行がうまくいったようです。
- 409エラーが出た場合
アクセスが集中していることにより、エラーが発生しているようです。しばらく時間を空けてから試してください。
OpenAIのAPIで動作確認
openai のライブラリをインストールします。
今回は、WSL2 で Python を使うのは初めてだったので、Python のセットアップも含めて、実行しています。
$ sudo apt install python3-pip $ sudo apt install python3.12-venv $ python3 -m venv ~/20251023env $ source ~/20251023env/bin/activate $ pip3 install openai
では、Quickstart に書かれている通りに実行してみます。まず、先ほど取得した APIキーを環境変数の XXX のところに設定します。
$ export OPENAI_API_KEY="XXX"
以下の Pythonスクリプトをエディタで作ります。Quickstart は、「gpt-5」を使う設定でしたが、精度が必要ないところでは、なるべく料金をおさえるため、「gpt-5-nano」に変更します。
from openai import OpenAI client = OpenAI() response = client.responses.create( model="gpt-5-nano", input="Write a one-sentence bedtime story about a unicorn." ) print(response.output_text)
それでは実行します。エラーになりました。やはり、OpenAI の API には、無料枠はなくて、お金払ってください、というエラーが出ました。
$ python3 example.py Traceback (most recent call last): File "/home/ubuntu/svn/OpenAI/example.py", line 4, in <module> response = client.responses.create( ^^^^^^^^^^^^^^^^^^^^^^^^ File "/home/ubuntu/20251023env/lib/python3.12/site-packages/openai/resources/responses/responses.py", line 840, in create return self._post( ^^^^^^^^^^^ File "/home/ubuntu/20251023env/lib/python3.12/site-packages/openai/_base_client.py", line 1259, in post return cast(ResponseT, self.request(cast_to, opts, stream=stream, stream_cls=stream_cls)) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "/home/ubuntu/20251023env/lib/python3.12/site-packages/openai/_base_client.py", line 1047, in request raise self._make_status_error_from_response(err.response) from None openai.RateLimitError: Error code: 429 - {'error': {'message': 'You exceeded your current quota, please check your plan and billing details. For more information on this error, read the docs: https://platform.openai.com/docs/guides/error-codes/api-errors.', 'type': 'insufficient_quota', 'param': None, 'code': 'insufficient_quota'}}
以前は無料枠があったらしいのですが、今は、なくなったそうです。仕方ないので、課金します(笑)。
OpenAIのAPIに課金する
画面右上の Start building をクリックします。
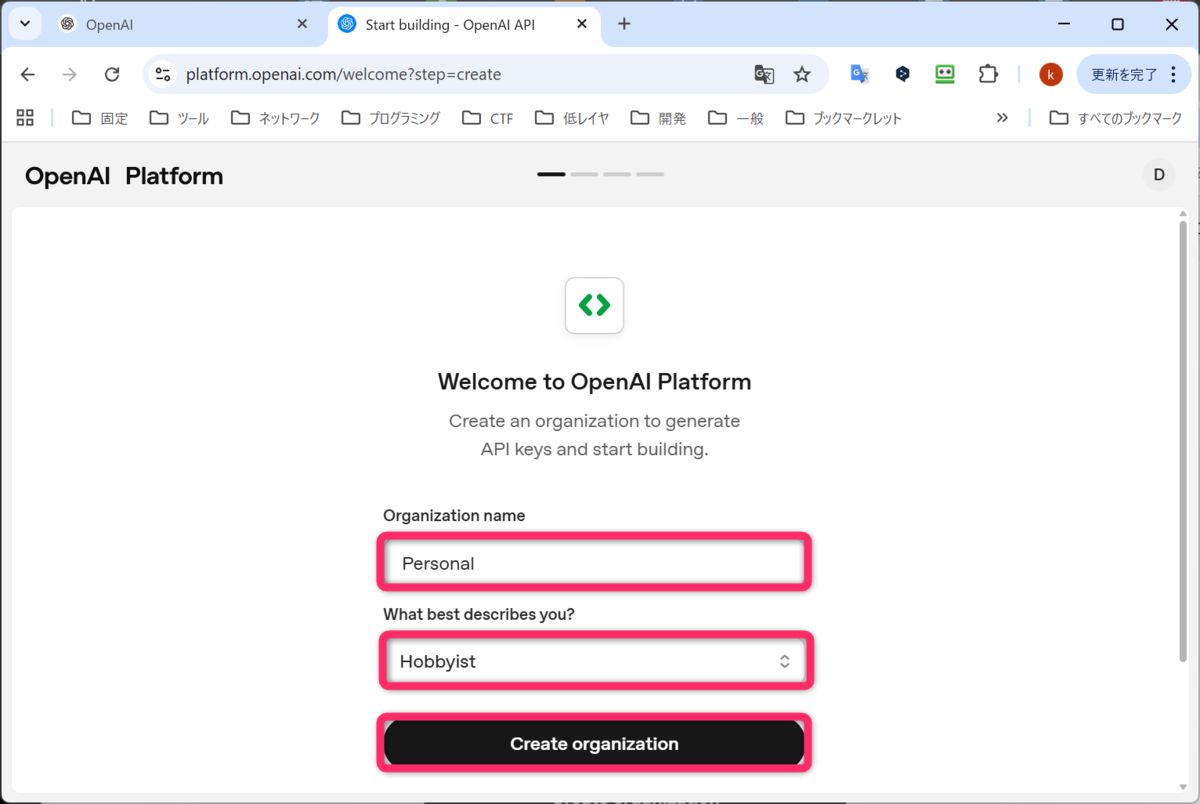
Organization name(組織名)の入力し、一番自分を表す選択肢の選択し、Create organization をクリックします。
ここはチームを招待する場合はメールアドレスを入力するようですが、私の場合は特にその用途はないので、何も入力せずに、Continue をクリックします。
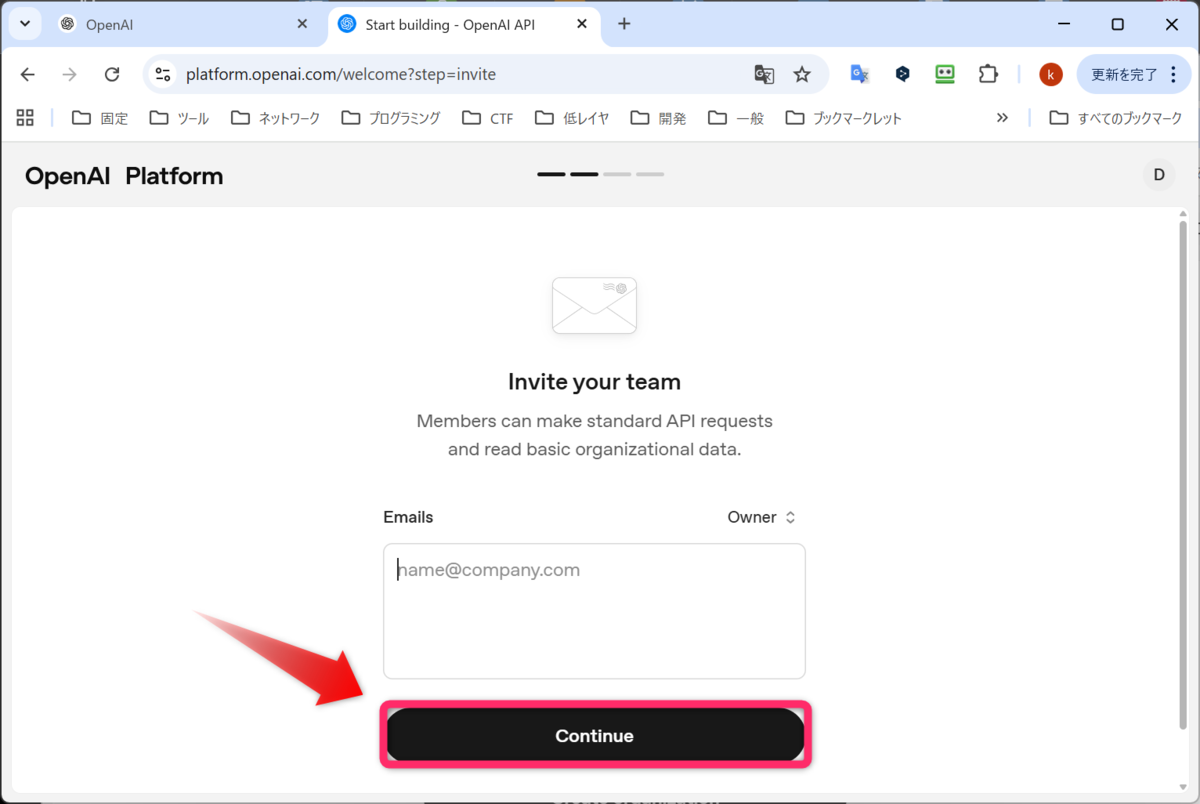
先ほど、APIキーは作成したので、I'll do this later をクリックします。
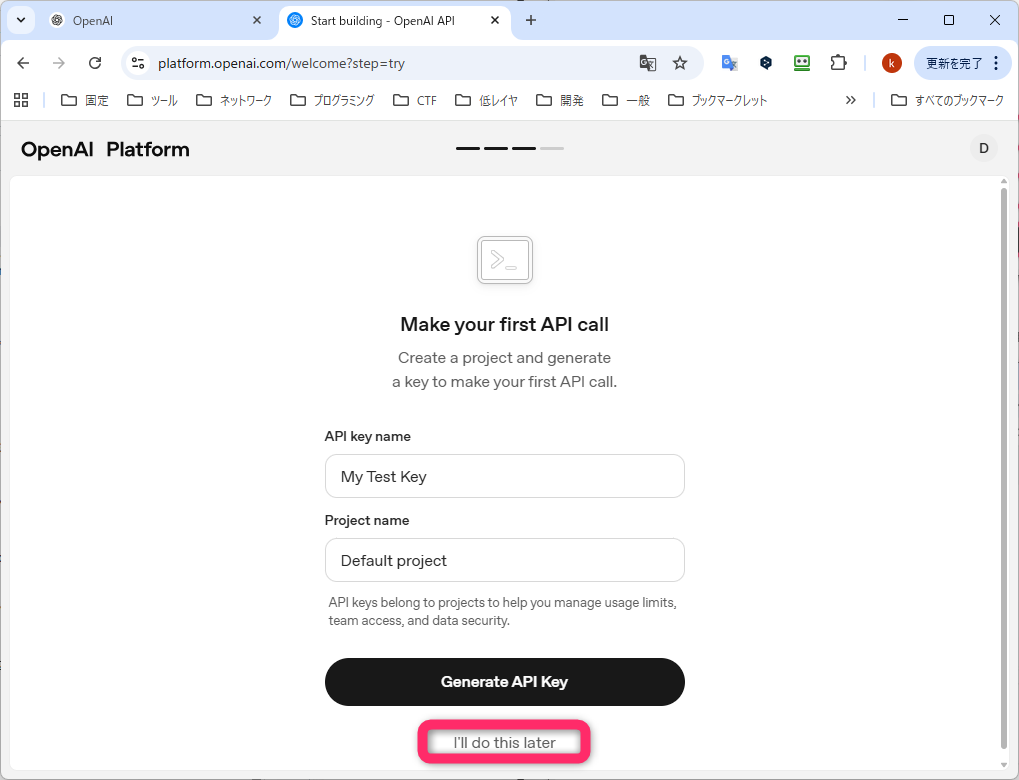
次は、チャージ金額の選択です。$5 がデフォルトで選択されています。Purchase credits をクリックします。
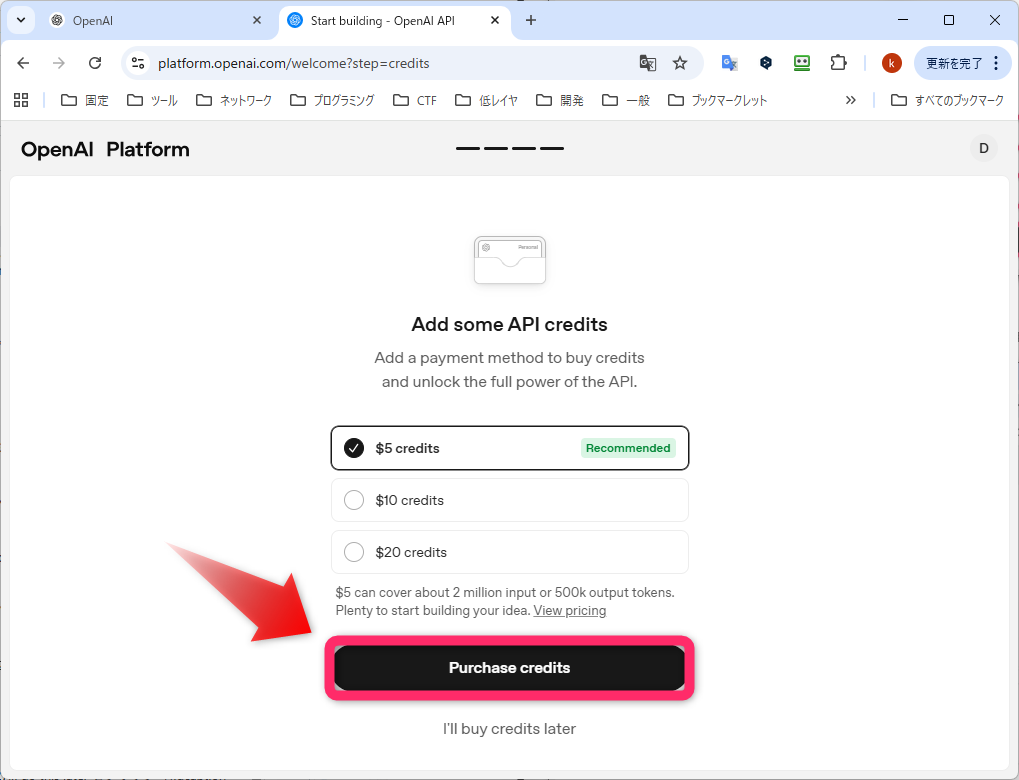
続いて、クレジットカード情報を入力します。下の方に、ビジネスで購入するのか、というチェックボックスがありましたが、私はチェックを入れませんでした(クリックしてしまって、正確に何が書かれていたのか忘れました)。ボタンに書かれていた内容も忘れましたが、Confirm 的な感じのをクリックします。
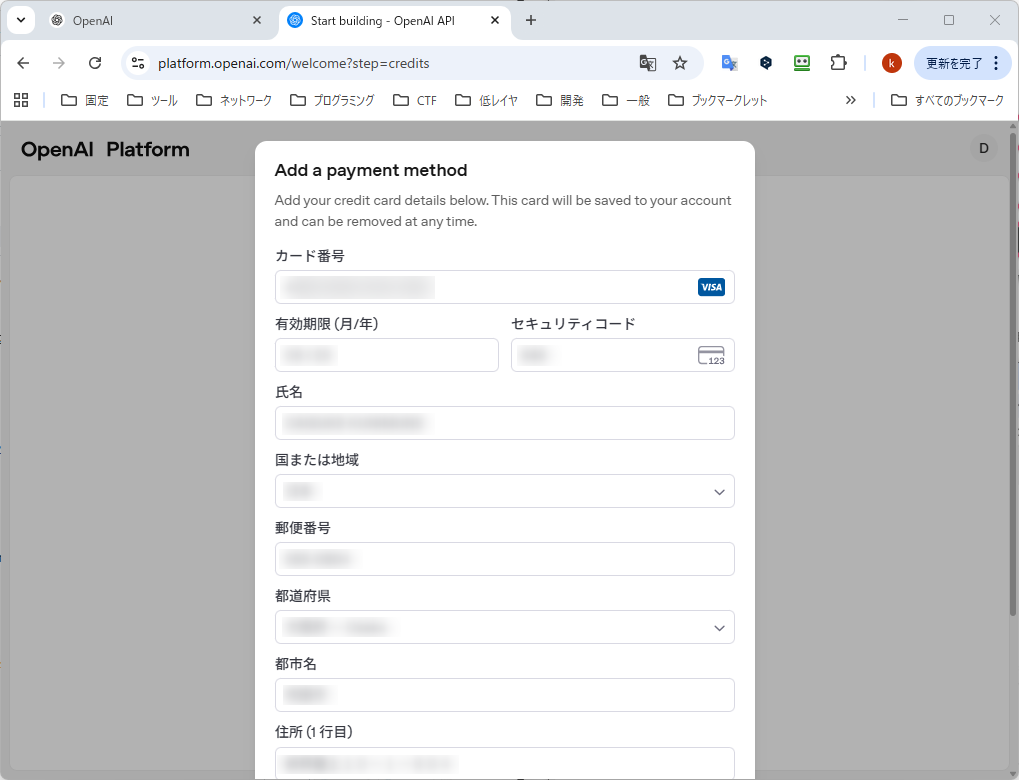
確認画面です。見積り税?を入れると、$5.5(約825円)です。Confirm payment をクリックします。
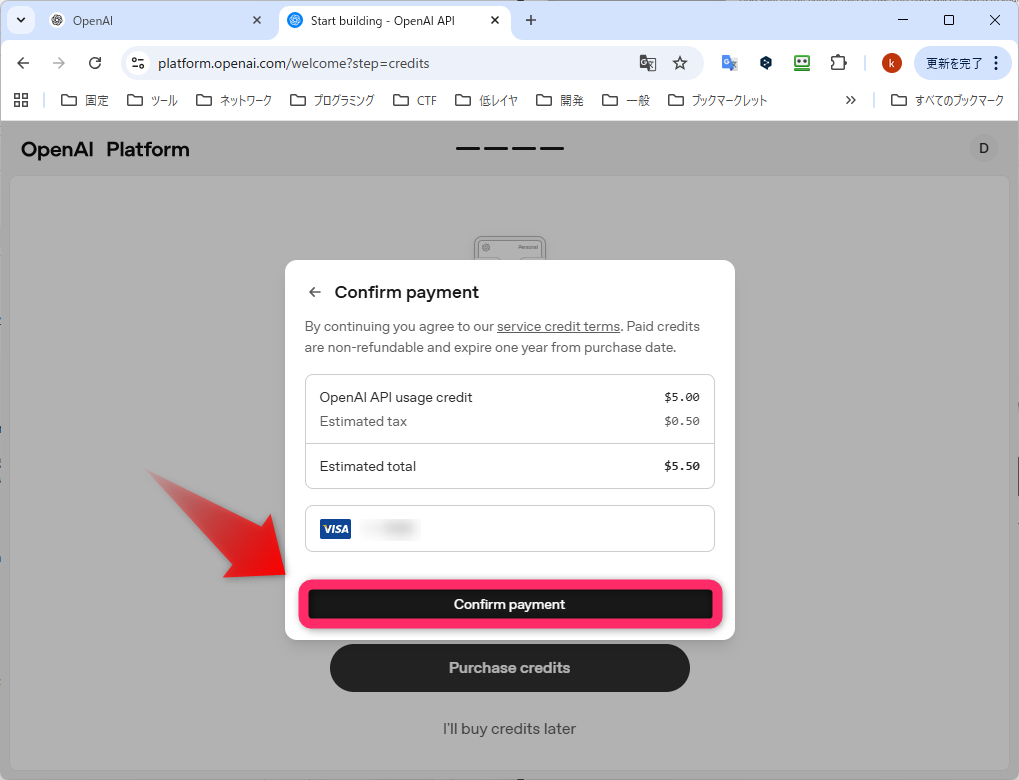
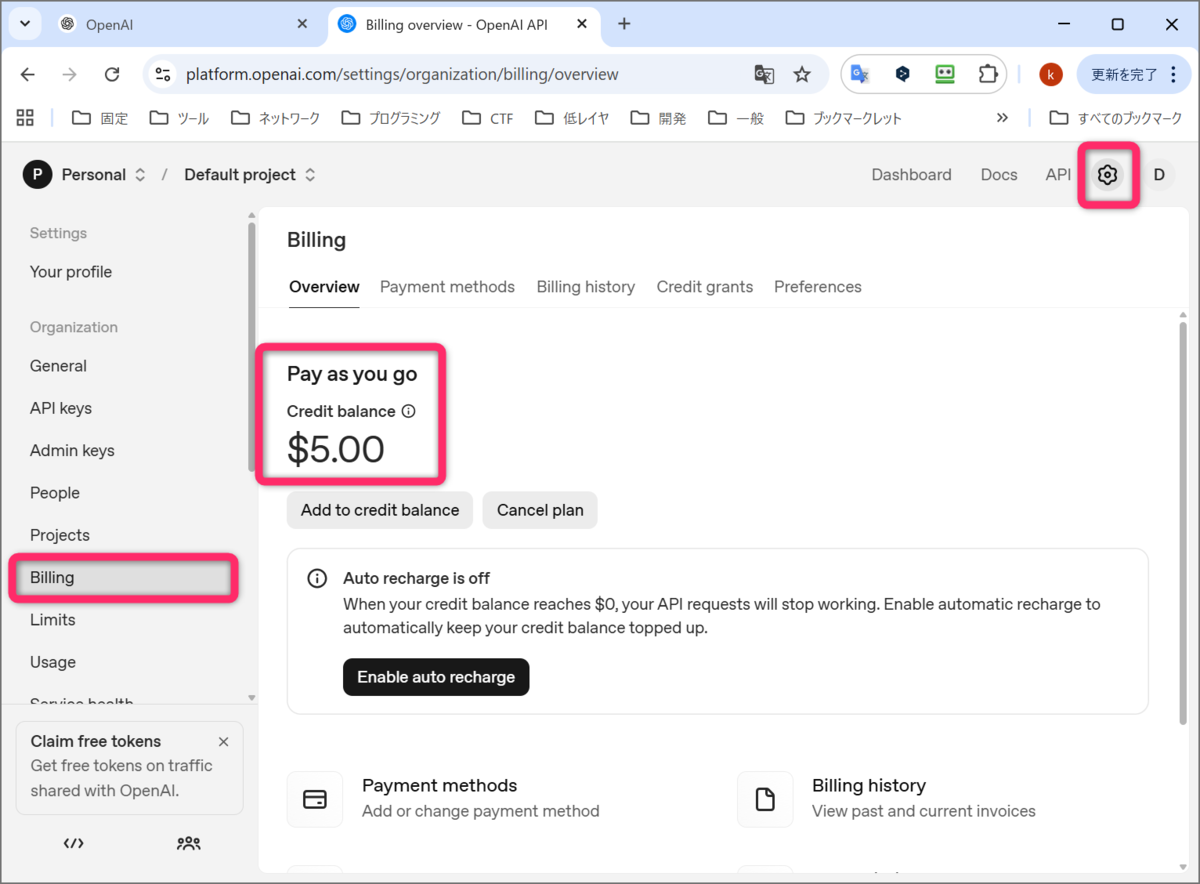
購入が完了したようです。右上にあった Start building が、設定アイコンに変わっています。クリックすると、設定画面になります。左のサイドバーの Billing をクリックすると、5ドルがチャージされました。
再度OpenAIのAPIで動作確認
先ほど作った Pythonスクリプトを再度実行してみます。
ちゃんと回答が返ってきました。入力は、「Write a one-sentence bedtime story about a unicorn.(Google翻訳:ユニコーンについての1文の就寝前の物語を書いてください。)」です。回答の Google翻訳は、「銀色の月明かりの下、優しいユニコーンが静かな草原をそっと歩き、夜空を星の光で照らし、眠っている世界全体が「おやすみ」とささやくまで続きました。」とのことです。
$ python3 example.py
Under a silver moon, a gentle unicorn padded softly through a quiet meadow, brushing the night with starlight until all the sleeping world whispered good night.
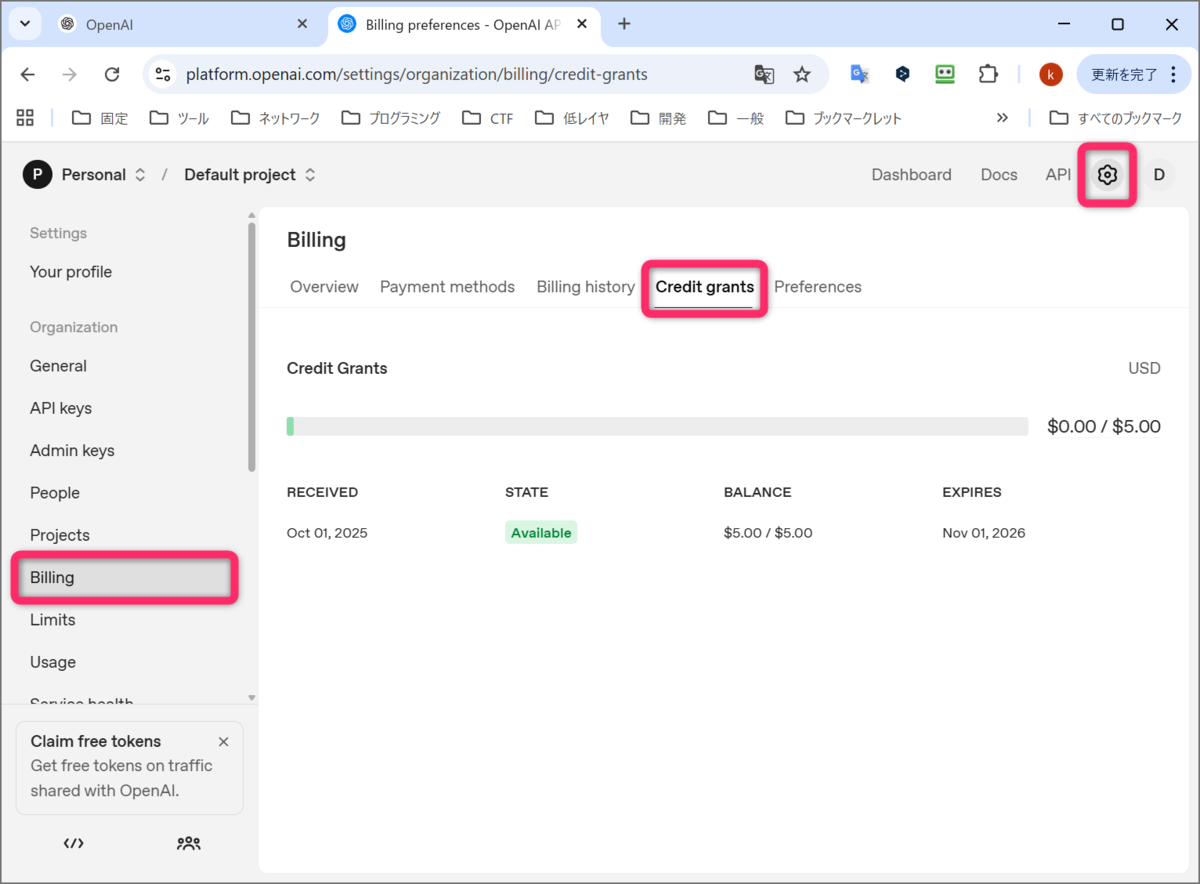
使用状況(使用料金)を確認してみます。先ほどと同じ、OpenAI のサイトの設定アイコンをクリックして、設定画面に移動し、左のサイドバーの Billing をクリックし、Credit grants をクリックします。少しだけ緑色のバーが進んでいました。この緑色のバーが右端までいくと、再度課金する必要があります。
Chat Completions APIのハンズオン
OpenAI の API が使えるようになりました。ここからは、OpenAI のライブラリを使い、「Chat Completions API」を試していく解説が書かれています。
しかし、少し困りました。冒頭でも書きましたが、現在の OpenAI のサイトでは、「Chat Completions API」ではなく、「Responses API」に移行しています。
「Chat Completions API」と「Responses API」について、以下のサイトが分かりやすかったです。
こちらによると、しばらくは、「Chat Completions API」のサポートは続きそうだが、「Responses API」への移行が推奨されていそうです。また、API として互換性は無いが、機能としては上位互換で、「Responses API」に機能が追加されていく感じです。
私の場合は、「Chat Completions API」について、深く理解した状態ではないので、「Responses API」を使っていく方が良さそうです。
そうなると、この章のハンズオンを読んで、実際に試すよりは、OpenAI の公式のハンズオンを実際にやってみた方が良さそうです。
一応、この先で、ハンズオンで行っている項目だけ列挙しておきます。
- 簡単なテキスト生成
- 「Chat Completions API」はステートレスなため、過去のやり取りをリクエストに含めた回答を得る
- ChatGPT の WebUI のように、徐々に回答を得る(ストリーミングで応答を得る)
- JSONモード:response_format に JSON を指定して、JSON形式の応答を得る
- 画像入力の方法
- Function calling:使える関数と使い方の一覧を与えて、LLM に使う関数とその方法を回答させて、こちらで関数を実行し、その結果を再度 LLM に渡して、最終的な応答を得る
最終的には、OpenAI の API を直接使うのではなく、LLM開発フレームワークである LangChain を使って、間接的に OpenAI の API を使うことになるので、この章の内容は、ふーん、という感じで見ておけばいいと思います。
この章はここまでとします。
第3章:プロンプトエンジニアリング
冒頭にも紹介しましたが、第3章で扱っているプログラムのリンクを貼っておきます。https://github.com/GenerativeAgents/agent-book/blob/main/chapter03/notebook.ipynb で、Jupyter notebook の形式で公開されています。
ここでは、プロンプトエンジニアリングについて、基本的なところから丁寧に解説されています。
プロンプトエンジニアリングとは、LLM が指示通りに回答を出力してくれるように、LLM に与える入力(リクエスト)を工夫するための試行錯誤のことです。
LLM を使ったアプリケーション(例えば、Python)では、LLM の回答を文字列として、処理することになります。実際にやってみると、これじは、なかなか上手くいきません。毎回違うフォーマットで回答してきたり、想定していないところに半角空白が入ったり、と、プログラムでは、とても扱いにくい内容です。
書籍では、まず、必要以上に長い回答を出力してくる、と言っています。その場合は、例えば、「100文字程度で答えてください」と指示することで、希望に沿った回答が得られると説明されています。
ここからは、料理のレシピを LLM に作ってもらう、という例で説明が展開されています。
プロンプトエンジニアリングのテクニックとして、最初の内容は、単純に、「XXX のレシピを考えてください」とするのではなく、「命令と入力データを分離する」ことを勧めています。例えば、以下のような感じです。
prompt = '''\ 以下の料理のレシピを考えてください。 料理名: """ {dish} """ '''
prompt という変数は、prompt.format(dish=dish) のように使われることが想定されています。dish には、「カレー」などの指定された料理名が入ります。Python の文法としては、トリプルクォーテーションは、改行を含めた複数行の文字列を表現(入力)できます。
先頭の 1行が命令(タスク)の指定ですね。料理名のところからが入力データとなっています。入力データは、分かりやすいように、「"""」や、「###」といった記号で区切ることが多いそうです。
次に、「コンテキスト(文脈)を与える」ことを勧めています。つまり、詳細な指示を与える、ことで、期待通りの出力が得られやすくなる、ということです。
上のプロンプトを改善した例は以下です。
prompt = '''\ 前提条件を踏まえて、以下の料理のレシピを考えてください。 前提条件: """ 分量: 一人分 味の好み: 辛口 """ 料理名: """ {dish} """ '''
次に、「出力形式を指定する」ことを勧めています。
上のプロンプトを改善した例は以下です。
prompt = '''\ 前提条件を踏まえて、以下の料理のレシピを考えてください。 前提条件: """ 分量: 一人分 味の好み: 辛口 """ 料理名: """ {dish} """ 出力は以下のJSON形式にしてください。 ``` { "材料": ["材料1", "材料2"], "手順": ["手順1", "手順2"] } ``` '''
実際には、指示を与えるのではなく、JSONモード(response_format を JSON で指定する)や、Function calling を使うことになる、説明されていました。
また、プロンプトエンジニアリングの参考として、以下のサイト「Prompt Engineering Guide」が紹介されています。日本語化されていて、大変参考になります。
第4章:LangChainの基礎
ここでは、LangChain の説明がされています。
LangChain とは、LLMアプリケーション開発のフレームワークです。Python のライブラリで言うと、LangChain は複数のライブラリで構成されています。LangChain のベースとなる部分と LangChain Expression Language(LCEL)を提供する 「langchain-core」ライブラリや、OpenAI や、Anthropic などの言語モデルをインテグレーションの実装である「partners」の中に「langchain-openai」ライブラリや、「langchain-anthropic」ライブラリなどがあります。
LangChain は、LLM を総合的に扱えるフレームワークなので、OpenAI、Anthropic(Claude)、Google(Gemini)などの各種 LLM を共通のインタフェースで使えるように設計されています。
これまで、OpenAI のライブラリ($ pip3 install openai)を使っていました。LangChain の「langchain-openai」ライブラリは、 OpenAI のライブラリを内部的に呼び出しているようです。LangChain は、「Responses API」にも対応しています。そういう意味では、LangChain を使えば、「Chat Completions API」と「Responses API」のどちらを使うかを考えなくていい、ということになります。とはいえ、現状は、LangChain であっても、「Responses API」を明示的に使う指示は必要なので、LangChain を覚えれば、OpenAI の API は細かく考えなくていい、ということになります。
書籍の内容は、少し古いかもしれないので、LangChain の公式サイトの方も見ながら進めます。
トップページはシンプルに見えますが、かなり大きいサイトで、どこを見ていいか分からなくなります。さらに、LangChain の公式サイト自体が、リニューアル中なのか、https://docs.langchain.com というドメインと、https://reference.langchain.com というドメインが混在している状態です。
とにかく、LangChain というリンクを押してみます。すると、LangChain overview というページに飛びます。左のサイドバーを見ると、Get Started に Install というリンクが見つかります。とりあえず、それを押してみます。
まずは、Python の langchainライブラリをインストールします。だいぶ、、たくさんのライブラリがインストールされました。
$ pip install -U langchain Installing collected packages: zstandard, xxhash, urllib3, tenacity, pyyaml, packaging, ormsgpack, orjson, jsonpointer, charset_normalizer, requests, jsonpatch, requests-toolbelt, langgraph-sdk, langsmith, langchain-core, langgraph-checkpoint, langgraph-prebuilt, langgraph, langchain Successfully installed charset_normalizer-3.4.4 jsonpatch-1.33 jsonpointer-3.0.0 langchain-1.0.3 langchain-core-1.0.2 langgraph-1.0.2 langgraph-checkpoint-3.0.0 langgraph-prebuilt-1.0.2 langgraph-sdk-0.2.9 langsmith-0.4.39 orjson-3.11.4 ormsgpack-1.11.0 packaging-25.0 pyyaml-6.0.3 requests-2.32.5 requests-toolbelt-1.0.0 tenacity-9.1.2 urllib3-2.5.0 xxhash-3.6.0 zstandard-0.25.0
続いて、OpenAI(langchain-openai)と、Anthropic のライブラリ(langchain-anthropic)のインストールについて書かれています。今は、OpenAI を使っているので、前者をインストールします。
$ pip install -U langchain-openai Installing collected packages: regex, tiktoken, langchain-openai Successfully installed langchain-openai-1.0.1 regex-2025.10.23 tiktoken-0.12.0
次は、Get Started の Quickstart を見てみます。Anthropic の Claude を使う場合の例が書かれています。OpenAI の説明を探します。Webページの上部に、並んでいるメニューのうち、Integrations をクリックします。Popular providers ということで、LLM を提供している、たくさんのプロバイダが並んでいます。OpenAI をクリックします。
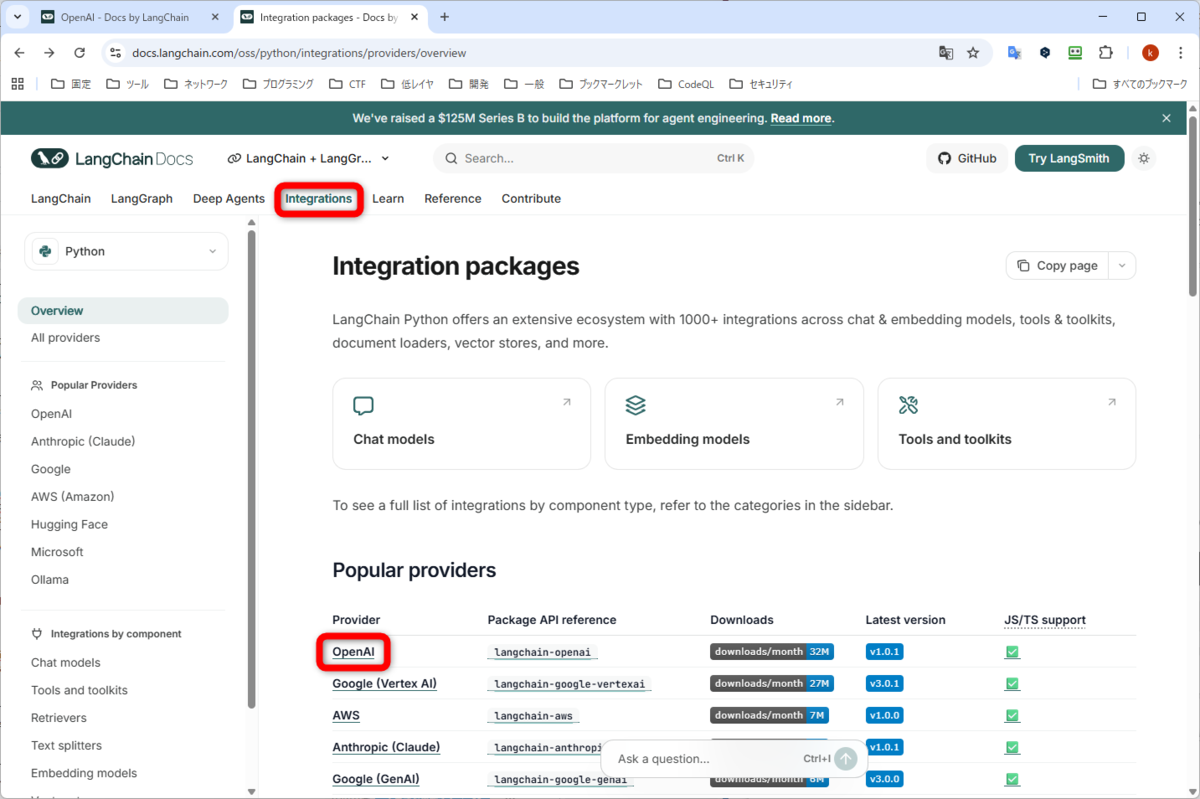
Model interfaces と書かれていて、ChatOpenAI や、OpenAI などが並んでいます。前者の ChatOpenAI は、「Chat Completions API」と「Responses API」を使う方で、後者の OpenAI は、上で出てきた「Completions API」という古い API を使うものです。ChatOpenAI をクリックします。
かなり、量の多いページが表示されます。右のサイドバーには、ページ内のリンクが並んでいます。Responses API も書かれているようです。
最初の方は、まずは、ChatOpenAI の簡単な使い方が書かれています。OpenAI と同じく、環境変数 "OPENAI_API_KEY" に、上で取得した APIキーを格納しておきます。あとは、Pythonスクリプトで、ChatOpenAI のインスタンス(オブジェクト)を作り、LLM に与えるメッセージを作り(messages)、実行(invoke)するという流れです。以下が実際のコードです。やってみます。
最後の LLM からの応答を表示するところだけ、ai_msg となっていたので、print文に変えています。
from langchain_openai import ChatOpenAI llm = ChatOpenAI( model="gpt-5-nano", # stream_usage=True, # temperature=None, # max_tokens=None, # timeout=None, # reasoning_effort="low", # max_retries=2, # api_key="...", # if you prefer to pass api key in directly instead of using env vars # base_url="...", # organization="...", # other params... ) messages = [ ( "system", "You are a helpful assistant that translates English to French. Translate the user sentence.", ), ("human", "I love programming."), ] ai_msg = llm.invoke(messages) print(ai_msg)
実行します。応答は、見やすいように、改行などを入れています。また、ID などについて、一部省略しています。
英語からフランス語に翻訳してください、ということで、"I love programming."(私はプログラミングが大好きです。)を与えます。content に、フランス語?で応答が返ってきています。Google翻訳に貼り付けると、「私はプログラマーです。」というフランス語でした。
content 以外に、追加の情報がたくさん返ってきています。
$ python example_chatopenai.py content="J'aime programmer." additional_kwargs={ 'refusal': None } response_metadata={ 'token_usage': { 'completion_tokens': 269, 'prompt_tokens': 30, 'total_tokens': 299, 'completion_tokens_details': { 'accepted_prediction_tokens': 0, 'audio_tokens': 0, 'reasoning_tokens': 256, 'rejected_prediction_tokens': 0 }, 'prompt_tokens_details': { 'audio_tokens': 0, 'cached_tokens': 0 } }, 'model_provider': 'openai', 'model_name': 'gpt-5-nano-2025-08-07', 'system_fingerprint': None, 'id': 'chatcmpl-CXRV', 'service_tier': 'default', 'finish_reason': 'stop', 'logprobs': None } id='lc_run--1a95' usage_metadata={ 'input_tokens': 30, 'output_tokens': 269, 'total_tokens': 299, 'input_token_details': { 'audio': 0, 'cache_read': 0 }, 'output_token_details': { 'audio': 0, 'reasoning': 256 } }
以降は、ChatOpenAI という API に対して、いろんな機能を使った実行方法の概要が書かれています。ストリーミング(Streaming usage metadata)、Function Calling(LangChain では、Tool calling と呼ばれる)、Responses API などです。詳細な仕様は、Webページの上部に、並んでいるメニューの Reference(以下のリンク)に書かれています。
以下の Reference を見て、各機能の概要を見ていきたいと思います。
モデルのインスタンス化(Instantiate)
上の簡単な使い方と同じです。この後に、メッセージ(messages)を定義して、それを引数として、invokeメソッドを実行すれば、LLM から応答が返ってきます。
以降は、追加の機能(ストリーミング、非同期処理、Function calling など)の紹介がたくさん続きます。ここでインスタンス化したモデル(model変数)に、追加で実行することで、いろいろな機能を実現する、というイメージで説明されています。
from langchain_openai import ChatOpenAI model = ChatOpenAI( model="...", temperature=0, max_tokens=None, timeout=None, max_retries=2, # api_key="...", # base_url="...", # organization="...", # other params... )
ストリーミング(Streaming usage metadata)
ストリーミングとは、Webページの ChatGPT のように、徐々に、応答が表示されていく機能です。Reference では、普通に invoke を実行する代わりに、以下のような実装が紹介されていました(messages は別途定義される想定です)。大きな入出力の場合に重宝する機能だと思います。
for chunk in model.stream(messages): print(chunk.text, end="")
非同期処理(ainvoke、astream、abatch)
LangChain がサポートしている非同期処理は、Python の asyncioライブラリを利用したものになっています(たぶん)。よって、Python の非同期処理の手順通り実装を行います。asyncioタスクとして、ainvoke、astream、abatch を実行することで、非同期処理が実現できるんだと思います。
実例を示したいと思います(★準備中)。
Tool calling(Function calling)
Function calling(Tool calling)は、LLM に、利用可能な関数を伝えておいて、LLM にそれらの関数の中から、この関数をこういうパラメータで使いたい、と判断させる機能です。
具体的には、OpenAI の API(Function calling)の場合、Chat Completions API の引数の tools に、利用可能な関数に関する情報を渡し、応答では、choices の message の content は null となり、代わりに、message に tool_calls というキーが含まれて、そこに利用したい関数とそのパラメータが格納されています。
LangChain では、以下のような実装が紹介されていました。
GetWeather や、GetPopulation といった機能(ツール)を定義しておいて、モデル(model)に対して、bind_toolsメソッドで、ツールを紐づけて、紐づいたモデル(model_with_tools)を受け取ります。その後、いつも通り、invokeメソッドを実行します。すると、LLM からの応答の ai_msg に、tool_calls というメンバに、実行したい関数とパラメータがリストで格納されています。
実際に動かしてみます。最後の行の ai_msg.tool_calls では、インタラクティブシェル(対話形式の Python)じゃないと動かないので、printメソッドに変更しました。
from pydantic import BaseModel, Field class GetWeather(BaseModel): '''Get the current weather in a given location''' location: str = Field( ..., description="The city and state, e.g. San Francisco, CA" ) class GetPopulation(BaseModel): '''Get the current population in a given location''' location: str = Field( ..., description="The city and state, e.g. San Francisco, CA" ) model_with_tools = model.bind_tools( [GetWeather, GetPopulation] # strict = True # Enforce tool args schema is respected ) ai_msg = model_with_tools.invoke( "Which city is hotter today and which is bigger: LA or NY?" ) #ai_msg.tool_calls print(ai_msg)
実行します。応答については、見やすいように、改行などを入れています。
内容は分かっていませんが、利用したい関数がリストに格納されて返ってきました。
$ python example_chatopenai_details.py [ { 'name': 'GetWeather', 'args': { 'location': 'Los Angeles, CA' }, 'id': 'call_p2hdkUqyw2LcBYdlbnCNZCYN', 'type': 'tool_call' }, { 'name': 'GetWeather', 'args': { 'location': 'New York, NY' }, 'id': 'call_IUAZ1CLURcrpP1yOwwz116u3', 'type': 'tool_call' }, { 'name': 'GetPopulation', 'args': { 'location': 'Los Angeles, CA' }, 'id': 'call_2XMs5BUmXNfLs2KfLNlxPCG8', 'type': 'tool_call' }, { 'name': 'GetPopulation', 'args': { 'location': 'New York, NY' }, 'id': 'call_49xJ1lQTPm5gPdITchgUrfiF', 'type': 'tool_call' } ]
おわりに
今回は、LangChainとLangGraphによるRAG・AIエージェント[実践]入門 エンジニア選書 の章に従って、LLM開発について理解を始めました。書籍はまだ続きますので、今後もこの記事を更新していきます。
最後になりましたが、エンジニアグループのランキングに参加中です。
気楽にポチッとよろしくお願いいたします🙇
今回は以上です!
最後までお読みいただき、ありがとうございました。
