前回 は、GitHub が開発した CodeQL(セキュリティ脆弱性を検出するオープンソースのツール)で使われているクエリについて、どのように記述するのか、について調査しました。
クエリには、大きく分けて、アラートクエリとパスクエリがあります。今回は、アラートクエリの実装を見て、理解していきたいと思います。
現在検出しているクエリの VeryLikelyOverrunWrite.ql は、アラートクエリだったので、まずはこれを見ていきたいと思います。それ以外のアラートクエリも見たいと思います。
それでは、やっていきます。
- はじめに
- VeryLikelyOverrunWrite.ql
- OverrunWrite.ql
- OverflowStatic.ql
- UnterminatedVarargsCall.ql
- OverflowBuffer.ql
- BadlyBoundedWrite.ql
- おわりに
はじめに
「セキュリティ」の記事一覧です。良かったら参考にしてください。
・第2回:Ghidraで始めるリバースエンジニアリング(使い方編)
・第3回:VirtualBoxにParrotOS(OVA)をインストールする
・第4回:tcpdumpを理解して出力を正しく見れるようにする
・第5回:nginx(エンジンエックス)を理解する
・第6回:Python+Flask(WSGI+Werkzeug+Jinja2)を動かしてみる
・第7回:Python+FlaskのファイルをCython化してみる
・第8回:shadowファイルを理解してパスワードを解読してみる
・第9回:安全なWebアプリケーションの作り方(徳丸本)の環境構築
・第10回:Vue.jsの2.xと3.xをVue CLIを使って動かしてみる(ビルドも行う)
・第11回:Vue.jsのソースコードを確認する(ビルド後のソースも見てみる)
・第12回:徳丸本:OWASP ZAPの自動脆弱性スキャンをやってみる
・第13回:徳丸本:セッション管理を理解してセッションID漏洩で成りすましを試す
・第14回:OWASP ZAPの自動スキャン結果の分析と対策:パストラバーサル
・第15回:OWASP ZAPの自動スキャン結果の分析と対策:クロスサイトスクリプティング(XSS)
・第16回:OWASP ZAPの自動スキャン結果の分析と対策:SQLインジェクション
・第17回:OWASP ZAPの自動スキャン結果の分析と対策:オープンリダイレクト
・第18回:OWASP ZAPの自動スキャン結果の分析と対策:リスク中すべて
・第19回:CTF初心者向けのCpawCTFをやってみた
・第20回:hashcatの使い方(GPU実行時間の見積りとパスワード付きZIPファイル)
・第21回:Scapyの環境構築とネットワークプログラミング
・第22回:CpawCTF2にチャレンジします(クリア状況は随時更新します)
・第23回:K&Rのmalloc関数とfree関数を理解する
・第24回:C言語、アセンブラでシェルを起動するプログラムを作る(ARM64)
・第25回:機械語でシェルを起動するプログラムを作る(ARM64)
・第26回:入門セキュリhttps://github.com/SECCON/SECCON2017_online_CTF.gitティコンテスト(CTFを解きながら学ぶ実践技術)を読んだ
・第27回:x86-64 ELF(Linux)のアセンブラをGDBでデバッグしながら理解する(GDBコマンド、関連ツールもまとめておく)
・第28回:入門セキュリティコンテスト(CTFを解きながら学ぶ実践技術)のPwnable問題をやってみる
・第29回:実行ファイルのセキュリティ機構を調べるツール「checksec」のまとめ
・第30回:setodaNote CTF Exhibitionにチャレンジします(クリア状況は随時更新します)
・第31回:常設CTFのksnctfにチャレンジします(クリア状況は随時更新します)
・第32回:セキュリティコンテストチャレンジブックの「Part2 pwn」を読んだ
・第33回:セキュリティコンテストチャレンジブックの「付録」を読んでx86とx64のシェルコードを作った
・第34回:TryHackMeを始めてみたけどハードルが高かった話
・第35回:picoCTFを始めてみた(Beginner picoMini 2022:全13問完了)
・第36回:picoCTF 2024:Binary Exploitationの全10問をやってみた(Hardの1問は後日やります)
・第37回:picoCTF 2024:Reverse Engineeringの全7問をやってみた(Windowsプログラムの3問は後日やります)
・第38回:picoCTF 2024:General Skillsの全10問をやってみた
・第39回:picoCTF 2024:Web Exploitationの全6問をやってみた(最後の2問は解けず)
・第40回:picoCTF 2024:Forensicsの全8問をやってみた(最後の2問は解けず)
・第41回:picoCTF 2024:Cryptographyの全5問をやってみた(最後の2問は手つかず)
・第42回:picoCTF 2023:General Skillsの全6問をやってみた
・第43回:picoCTF 2023:Reverse Engineeringの全9問をやってみた
・第44回:picoCTF 2023:Binary Exploitationの全7問をやってみた(最後の1問は後日やります)
・第45回:書籍「セキュリティコンテストのためのCTF問題集」を読んだ
・第46回:書籍「詳解セキュリティコンテスト」のReversingを読んだ
・第47回:書籍「詳解セキュリティコンテスト」のPwnableのシェルコードを読んだ
・第48回:書籍「バイナリファイル解析 実践ガイド」を読んだ
・第49回:書籍「詳解セキュリティコンテスト」Pwnableのスタックベースエクスプロイトを読んだ
・第50回:書籍「詳解セキュリティコンテスト」Pwnableの共有ライブラリと関数呼び出しを読んだ
・第51回:picoCTF 2025:General Skillsの全5問をやってみた
・第52回:picoCTF 2025:Reverse Engineeringの全7問をやってみた
・第53回:picoCTF 2025:Binary Exploitationの全6問をやってみた
・第54回:書籍「詳解セキュリティコンテスト」Pwnableの仕様に起因する脆弱性を読んだ
・第55回:システムにインストールされたものと異なるバージョンのglibcを使う方法
・第56回:書籍「詳解セキュリティコンテスト」Pwnableのヒープベースエクスプロイトを読んだ
・第57回:書籍「解題pwnable」の第1章「準備」を読んだ
・第58回:書籍「解題pwnable」の第2章「login1(スタックバッファオーバーフロー1)」を読んだ
・第59回:書籍「解題pwnable」の第3章「login2(スタックバッファオーバーフロー2)」を読んだ
・第60回:書籍「解題pwnable」の第4章「login3(スタックバッファオーバーフロー3)」を読んだ
・第61回:書籍「解題pwnable」の第5章「rot13(書式文字列攻撃)」を読んだ
・第62回:GitHubが開発した静的解析ツール(脆弱性検出ツール)のCodeQLを使ってみる
・第63回:CodeQL(静的解析ツール)で使われるクエリの選ばれ方を調べた
・第64回:CodeQL(静的解析ツール)のクエリの書き方を調べた
・第65回:CodeQL(静的解析ツール)で使われているアラートクエリの中身を調べる ← 今回
以下は、CodeQL の公式サイトです。
また、CodeQL CLI の公式ドキュメント(GitHub Docs)は以下です。ありがたいことに、日本語のドキュメントがあります。
このページにリンクがある ライセンスのページ を見ると、CodeQL は、GitHub で公開されているリポジトリのように、オープンソースに使うことは許されていますが、GitHub のプライベートリポジトリのような公開されていないソフトウェアに使う場合は、商用ライセンスが必要になるようです。
ちゃんと分かっていなかったのですが、上記の GitHub Docs の他に、CodeQL の公式ドキュメントとして、以下もあります。上の日本語で表示できるドキュメントから、下のドキュメントにリンクが貼られていて、違うサイトがあることには、何となく気づいていましたが、ちゃんと紹介できていませんでした。
なぜ、2つに分かれているのかは分かりませんが、クエリの書き方や、クエリを記述する際の文法については、こちらにしか書かれていません。
こちらを参考にしながら、実際のクエリを読み解いていきたいと思います。
◆2025/9/29 追記
CodeQL のクエリの一部は、CWE ごとのディレクトリで管理されています。CWE の一覧は、日本のサイトは以下が分かりやすかったです。
https://secualive.jp/feed/cwe/list/
バッファオーバーフロー関連として、以下を見ていきたいです。クエリ数は、クエリが格納されている cpp-queriesディレクトリの Security/CWE/CWE-XXX のディレクトリにあるクエリ数を示しています。このディレクトリ以外にもバッファオーバーフロー関連のクエリは存在します。
| CWE | 概要 | クエリファイル数 |
|---|---|---|
| CWE-119 | バッファエラー | 2ファイル |
| CWE-120 | 古典的バッファオーバーフロー | 5ファイル |
| CWE-121 | スタックオーバーフロー | 1ファイル |
| CWE-122 | ヒープオーバーフロー | 0ファイル |
| CWE-126 | バッファオーバーリード | 0ファイル |
| CWE-131 | 正しくないバッファサイズ計算 | 1ファイル |
| CWE-787 | 境界外書き込み | 0ファイル |
| CWE-788 | バッファの終端後のメモリ領域に対するアクセス | 0ファイル |
| CWE-805 | 不適切な長さの値によるバッファへのアクセス | 0ファイル |
バッファオーバーフロー関連のクエリを整理しておきます。
| ディレクトリ | クエリファイル名 | クエリ種別 | description |
|---|---|---|---|
| CWE-119 | OverflowBuffer.ql | アラートクエリ | メモリバッファにアクセスする関数を誤って使用すると、バッファの末尾を超えてデータの読み取りまたは書き込みが行われる可能性があります。 (調査済み:典型的なバッファオーバーフロー) |
| CWE-119 | OverrunWriteProductFlow.ql | パスクエリ | 書き込みまたはアクセス操作中に静的配列のサイズを超えると、バッファオーバーフローが発生する可能性があります。 |
| CWE-120 | BadlyBoundedWrite.ql | アラートクエリ | 長さパラメータが宛先バッファのサイズと一致しないバッファ書き込み操作では、オーバーフローが発生する可能性があります。 (調査済み:書き込みサイズが確定する標準ライブラリ(strncpyなど)を使用してバッファのサイズを超えてアクセスする場合) |
| CWE-120 | OverrunWrite.ql | アラートクエリ | 書き込まれるデータの長さを制御しないバッファ書き込み操作では、オーバーフローが発生する可能性があります。 (調査済み:strcpy、strncat、sprintf などの書き込まれるデータの長さを制御しない関数が対象) |
| CWE-120 | OverrunWriteFloat.ql | アラートクエリ | 書き込まれるデータの長さを制御しないバッファ書き込み操作では、浮動小数点入力が極端な値になるとオーバーフローが発生する可能性があります。 |
| CWE-120 | UnboundedWrite.ql | パスクエリ | 書き込まれるデータの長さを制御しないバッファ書き込み操作では、オーバーフローが発生する可能性があります。 |
| CWE-120 | VeryLikelyOverrunWrite.ql | アラートクエリ | 書き込まれるデータの長さを制御しないバッファ書き込み操作はオーバーフローする可能性があります。 (調査済み:strcpy、strncat、sprintf などの書き込まれるデータの長さを制御しない関数が対象) |
| CWE-121 | UnterminatedVarargsCall.ql | アラートクエリ | センチネル値なしで可変引数関数を呼び出すと、関数が引数リストを終了するために特定の値を想定している場合にバッファオーバーフローが発生する可能性があります。 (調査済み:可変長引数を持つ関数が対象) |
| CWE-131 | NoSpaceForZeroTerminator.ql | アラートクエリ | 文字列全体とゼロ終端のためのスペースが常に確保されることを保証せずに 'malloc' を使用してバッファを割り当てると、バッファオーバーランが発生する可能性があります。 |
| Critical | OverflowCalculated.ql | アラートクエリ | 'malloc' で割り当てられたバッファには、コピー先の文字列を格納するのに十分な領域がない可能性があります。この操作によりバッファオーバーランが発生する可能性があります。バッファに文字列(ゼロ終端文字を含む)を格納するのに十分な領域があることを確認してください。 |
| Critical | OverflowDestination.ql | パスクエリ | コピー先バッファではなくコピー元バッファから導出されたサイズでコピー操作を呼び出すと、バッファオーバーフローが発生する可能性があります。 |
| Critical | OverflowStatic.ql | アラートクエリ | 書き込みまたはアクセス操作中に静的配列のサイズを超えると、バッファオーバーフローが発生する可能性があります。 (調査済み:静的配列が対象) |
| Critical | SizeCheck.ql | アラートクエリ | ポインタの型のインスタンスを格納するのに十分なメモリを割り当てずに「malloc」、「calloc」、または「realloc」を呼び出すと、バッファオーバーフローが発生する可能性があります。 |
| Critical | SizeCheck2.ql | アラートクエリ | ポインタ型の複数のインスタンスを格納するのに十分なメモリを割り当てずに「malloc」、「calloc」、または「realloc」を呼び出すと、バッファオーバーフローが発生する可能性があります。 |
また、CodeQL のメソッドの公式のヘルプを探すのに便利なページがあったので紹介します。
ここで検索すれば、すぐにメソッドのヘルプを見ることができます。大変助かります。
VeryLikelyOverrunWrite.ql
まず、以下の記事で、CodeQL CLI を実行しました。
daisuke20240310.hatenablog.com
このときに使用した UAF の脆弱性を含むソースコードは以下のリポジトリのものを使わせてもらってます。
CodeQL CLI を実行したときに出力された CSVファイルの 1行を貼ります。use_after_free.c の 49行目の 32カラムから 39カラムを指摘しています。
"Likely overrunning write","Buffer write operations that do not control the length of data written may overflow","error","This 'scanf string argument' operation requires 255 bytes but the destination is only 20 bytes.","/use_after_free.c","49","32","49","39"
指摘箇所のソースコードは以下です。3行のうち、scanf関数のところが 49行目になります。20byte しか確保していないのに、255byte を格納しようとしているため、CodeQL が検知したのだと思います。
username = malloc(20*sizeof(char)); printf("Enter username: "); scanf("%254s", username);
@name が Likely overrunning write のクエリは、VeryLikelyOverrunWrite.ql(qlpacks/codeql/cpp-queries/1.4.2/Security/CWE/CWE-120/VeryLikelyOverrunWrite.ql)です。
同じディレクトリに、VeryLikelyOverrunWrite.md というファイルがあり、これをブラウザで見ると説明を見ることが出来ます。このクエリについての説明というよりは、バッファオーバーフローの説明になっているので、クエリを読み解くのに役に立つわけではありませんでした。
VeryLikelyOverrunWrite.ql の内容は以下です。
そんなに長くありません。
まず、先頭のコメントアウト部分(QLDoc)は、メタデータです。@name はクエリ名で、CodeQL CLI を実行したときに出力された CSVファイルの 先頭カラムに出力されます。
@kind が problem なので、パスクエリではなく、アラートクエリです。
以下で、詳しく見ていきます。
/** * @name Likely overrunning write * @description Buffer write operations that do not control the length * of data written may overflow * @kind problem * @problem.severity error * @security-severity 9.3 * @precision high * @id cpp/very-likely-overrunning-write * @tags reliability * security * external/cwe/cwe-120 * external/cwe/cwe-787 * external/cwe/cwe-805 */ import semmle.code.cpp.security.BufferWrite /* * See CWE-120/UnboundedWrite.ql for a summary of CWE-120 alert cases. */ from BufferWrite bw, Expr dest, int destSize, int estimated, ValueFlowAnalysis reason where not bw.hasExplicitLimit() and // has no explicit size limit dest = bw.getDest() and destSize = getBufferSize(dest, _) and estimated = bw.getMaxDataLimited(reason) and // we can deduce from non-trivial range analysis that too much data may be copied estimated > destSize select bw, "This '" + bw.getBWDesc() + "' operation requires " + estimated + " bytes but the destination is only " + destSize + " bytes."
QL言語で使われているライブラリの仕様は以下で説明されています。
where句から見ていきます。
まず、1番目の条件は、not bw.hasExplicitLimit() となっています。BufferWrite型の変数の bw について、hasExplicitLimitメソッドが実行されています。ライブラリの仕様の BufferWriteクラスの説明を探します。以下にありました。
BufferWriteクラスは、可変量のデータをバッファに書き込む操作(strcpy、strncat、sprintf など)を扱うクラスのようです。
このページ内で、hasExplicitLimitメソッドを探します。Predicates のところにありました。以下の説明があります。そのオペレーション(C言語のライブラリ関数)が、明確な制限のあるパラメータを持っているかどうか、を判定するようです。例えば、strncpy はコピーする文字数を指定する制限がありますが、strcpy は文字数の制限がありません。つまり、not bw.hasExplicitLimit() は、strcpy のような明確な制限のない関数を実行していた場合に、真になりそうです。今回は、scanf関数ですが、明確な制限は無いため、検知されたのだと思います。
Holds if the operation has an explicit parameter that limits the amount of data written (e.g. strncpy does, whereas strcpy does not); this is not the same as exists(getExplicitLimit()) because the limit may exist though it’s value is unknown.
次の条件は、dest = bw.getDest() です。ライブラリ仕様の同じページに解説があります。このオペレーション(例:scanf関数)の出力先のバッファが存在していたときに、真になると思います。
次の条件は、destSize = getBufferSize(dest, _) です。どのようにマニュアルを探していいか分からないので、「CodeQL "getBufferSize"」で、Google検索します。すると、ヒットします。引数の説明が分かりませんが、おそらく、引数のバッファのサイズを返すのだと思います。
次の条件は、estimated = bw.getMaxDataLimited(reason) です。BufferWriteクラスのページに説明があります。2つ見つかりますが、BufferWriteEstimationReasonクラスを引数に取る方です。reason は使ってないように見えますが。書き込まれる最大量を取得します。
最後の条件は、`estimated > destSizeです。上で求めた 2つの変数を比較しています。destSize は 20 で、estimated は 255 です。よって、真になります。
全ての条件が and で接続されているので、全ての条件が真になった場合に、この指摘が出力されると思います。
マニュアルについて、引数について説明が無いなどが困りますが、CodeQL CLI が指摘を出している根拠は理解することが出来ました。
OverrunWrite.ql
VeryLikelyOverrunWrite.ql と同じディレクトリにあるクエリの OverrunWrite.ql も見てみます。以下です。
VeryLikelyOverrunWrite.ql と、とても似ています。
/** * @name Potentially overrunning write * @description Buffer write operations that do not control the length * of data written may overflow. * @kind problem * @problem.severity error * @security-severity 9.3 * @precision medium * @id cpp/overrunning-write * @tags reliability * security * external/cwe/cwe-120 * external/cwe/cwe-787 * external/cwe/cwe-805 */ import semmle.code.cpp.security.BufferWrite /* * See CWE-120/UnboundedWrite.ql for a summary of CWE-120 alert cases. */ from BufferWrite bw, Expr dest, int destSize, int estimated, BufferWriteEstimationReason reason where not bw.hasExplicitLimit() and // has no explicit size limit dest = bw.getDest() and destSize = getBufferSize(dest, _) and estimated = bw.getMaxDataLimited(reason) and // we exclude ValueFlowAnalysis as it is reported in cpp/very-likely-overrunning-write not reason instanceof ValueFlowAnalysis and // we can deduce that too much data may be copied (even without // long '%f' conversions) estimated > destSize select bw, "This '" + bw.getBWDesc() + "' operation requires " + estimated + " bytes but the destination is only " + destSize + " bytes."
diffコマンドより、WinMerge の方が分かりやすいので、キャプチャを貼ります。
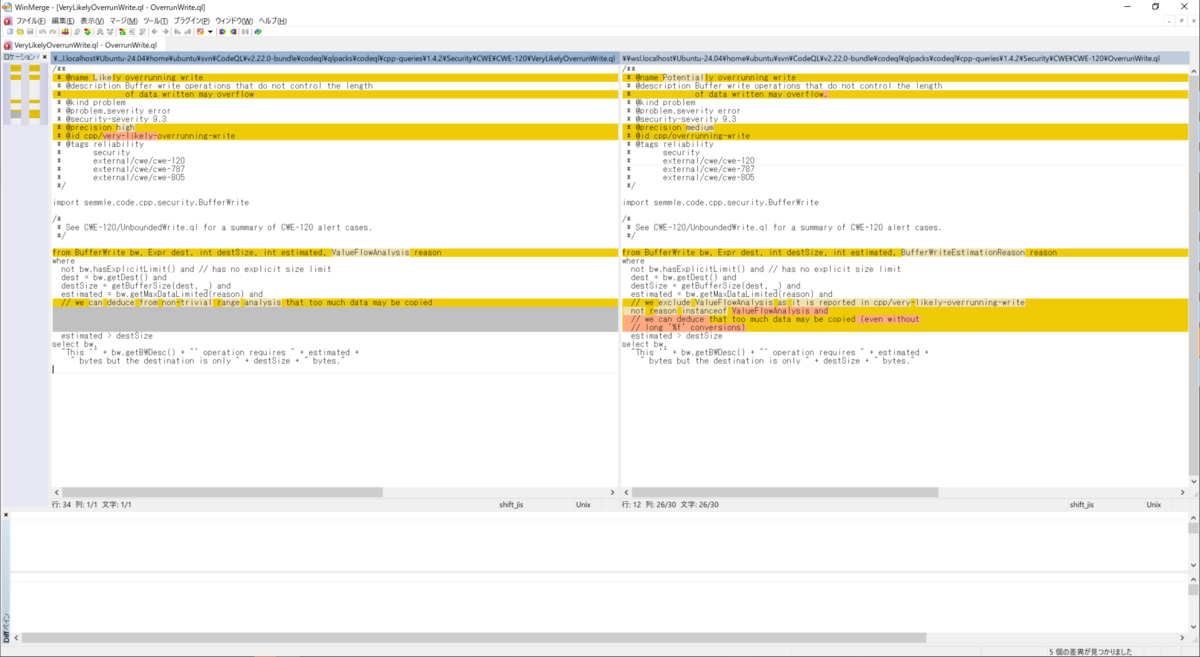
where句に注目すると、違いは、以下の 1つの条件が追加されているだけです。
重要そうなので、コメントも一緒に入れています。このコメントの意味は、「ValueFlowAnalysisはcpp/very-likely-overrunning-writeで報告されているため除外します。」ということのようです。
// we exclude ValueFlowAnalysis as it is reported in cpp/very-likely-overrunning-write not reason instanceof ValueFlowAnalysis and
instanceof の説明は、以下にあります。長いページですが、真ん中より少し下にあります。
これによると、reason が ValueFlowAnalysis型ではない、ということをチェックしています。
また、以下を見ると、BufferWriteEstimationReason とは、親クラスであり、ValueFlowAnalysis は、その子クラスであることが分かります。
つまり、バッファへの書き込みサイズを推定する手法はいくつかあり、その中で、値の流れを解析する(ValueFlowAnalysis)手法で推定できた場合は、reason が、ValueFlowAnalysis を示すことになり、それ以外の手法で推定した場合は、BufferWriteEstimationReason の子クラスのいずれかを示すことになると思います。
よって、この条件は、ValueFlowAnalysis で書き込みサイズを推定できるなら、VeryLikelyOverrunWrite.ql で検知して、それ以外の推定手法なら、この OverrunWrite.ql の方で検知する、と言う意味だと思います。
OverflowStatic.ql
バッファオーバーフロー関連で、OverflowStatic.ql(qlpacks/codeql/cpp-queries/1.4.2/Critical/OverflowStatic.ql)も見てみます。
だいぶ長いです。ChatGPT だけが頼りです。
まず、メタデータです。
@problem.severity warning ということで、上の 2つより、警告度としては一段低い扱いです。@description を見ると、「書き込み、または、アクセス操作中に静的配列のサイズを超えると、バッファ オーバーフローが発生する可能性があります。」とのことです。
/** * @name Static array access may cause overflow * @description Exceeding the size of a static array during write or access operations * may result in a buffer overflow. * @kind problem * @problem.severity warning * @security-severity 9.3 * @precision high * @id cpp/static-buffer-overflow * @tags reliability * security * external/cwe/cwe-119 * external/cwe/cwe-131 */
まず、from/where/select句から見てみます。
全然分かりませんが、3つのメソッドの呼び出しに分かれており、or なので、それぞれの条件で検出します。
以下で読み解いた結果、overflowOffsetInLoopメソッドは、forループで固定長配列(静的に確保された配列)にループ変数(i など)による境界超過でアクセスするケースを検出するようです。
wrongBufferSizeメソッドは、標準ライブラリの 8個の関数(strncpy や memcpy など)で、固定長配列が使われており、かつ、関数で指定したサイズが、配列サイズを超えている場合に、検出するようです。
outOfBoundsメソッドは、固定長配列に対して、整数定数の添え字によるアクセス(x[10] = 3 など)で配列サイズを超えているかどうかを検知しているようです。
この中では、2番目の wrongBufferSizeメソッドの条件が 1番検出しやすそうです。
from Element error, string msg where ( overflowOffsetInLoop(error, msg) or wrongBufferSize(error, msg) or outOfBounds(error, msg) ) and not error.getFile() instanceof ConfigurationTestFile // elements in files generated during configuration are likely false positives select error, msg
overflowOffsetInLoopメソッド
overflowOffsetInLoopメソッドから見てみます。このファイル内に定義されています。
BufferAccessクラスの変数が使われており、先にそちらを見る必要があります。さらに、そこでは、staticBufferメソッドが使われており、その中では、staticBufferBaseメソッドが使われています。よって、staticBufferBaseメソッドから見ていきます。
staticBufferBaseメソッドは以下です。staticBufferBaseメソッドは、配列(可変長ではなく固定長配列)の添え字が変数でアクセスされている場合、という条件のようです。詳しく見ていきます。
Variable は普通の変数ですが、VariableAccess は、変数に対してアクセスする式をモデル化したものとのことです。例えば、n = 10(書き込みアクセス)や、n + 5(読み込みアクセス)のような感じです。
v.getType().(ArrayType).getBaseType() instanceof CharType は、ある変数(v)の型が char型配列であるという条件のようです。
access = v.getAnAccess() は、右辺は、配列の添え字を返し、左辺は変数アクセスの式です。つまり、配列の添え字に変数が使われている、という条件のようです。
ChatGPT はこのように解説してくれましたが、getAnAccess の公式ヘルプ を見ると、右辺は変数アクセスを取得するだけのようです。
また、実際に、Tinyhttpdを使用してCodeQL(静的解析ツール)のクエリの挙動を確認する - staticBufferBaseメソッドの2番目の条件に注目する で可視化したところ、添え字とは関係ないアクセス(例:numchars = get_line(client, buf, sizeof(buf));)も検出していました。これは、単純に変数アクセスを取得してるだけであり、上の条件を合わせると、静的な配列のアクセスを取得しているということだと思います。
not memberMayBeVarSize(_, v) は、配列は可変長ではない、という条件のようです。
not access.isUnevaluated() は、評価できないの否定なので、評価できる(有効な)変数アクセスの式、という条件のようです。
private predicate staticBufferBase(VariableAccess access, Variable v) { v.getType().(ArrayType).getBaseType() instanceof CharType and access = v.getAnAccess() and not memberMayBeVarSize(_, v) and not access.isUnevaluated() }
memberMayBeVarSizeメソッドについて、もう少し調べます。memberMayBeVarSizeメソッドは、import semmle.code.cpp.commons.Buffer の Bufferライブラリで定義されているメソッドで、以下です。
コメントを見る限り、確かに、可変長ではない配列という条件のようです。
/** * Holds if `v` is a member variable of `c` that looks like it might be variable sized * in practice. For example: * `v` が `c` のメンバ変数であり、実際には可変サイズである可能性がある場合に保持されます。例えば、 * ``` * struct myStruct { // c * int amount; * char data[1]; // v * }; * ``` * or * ``` * struct myStruct { // c * int amount; * char data[]; // v * }; * ``` * This requires that `v` is an array of size 0 or 1, or that the array has no size. * これには、`v` がサイズ 0 または 1 の配列であるか、配列にサイズがないことが条件となります。 */ predicate memberMayBeVarSize(Class c, MemberVariable v) { c = v.getDeclaringType() and exists(ArrayType t | t = v.getUnspecifiedType() | not t.getArraySize() > 1) }
次は、staticBufferメソッドです。staticBufferメソッドは、上の staticBufferBaseメソッドの条件を満たし、かつ、そのバッファのサイズを取得しています。
ただ、size = getBufferSize(access, _) は難しいです。バッファサイズを取得しているわけですが、なぜ、v を渡さず、access を渡しているのかが分かりません。ChatGPT によると、v を渡すと、配列に対して、ポインタアクセスをしていた場合に、サイズが分からないから、ということです。全然分かりません(笑)。
getBufferSize(Expr bufferExpr, Element why) の公式ヘルプ を見ると、引数で指定されたバッファのサイズを取得する、とだけ書かれていて、引数の説明がありません。ChatGPT に、引数の意味について聞いてみると、bufferExpr は、バッファを指定する式で、why は、なぜ、このバッファサイズが使われたのかを説明するためのコンテキスト(オプション)とのことで、通常は使われないということです。
第1引数の型が Expr なので、Variant型の v ではなく、VariableAccess型の access を渡す必要があった、ということだと思います。VariableAccess の公式ヘルプ の親クラスを追っていくと、Expr が見つかります。
predicate staticBuffer(VariableAccess access, Variable v, int size) { staticBufferBase(access, v) and size = getBufferSize(access, _) }
次は、BufferAccessクラスです。
ArrayExpr を拡張しています。ArrayExpr は、CodeQL library for C and C++ によると、Expr [ Expr ] という配列アクセス式とのことです。staticBuffer なので、固定長配列に限定しています。
次の Macro m から始まる条件は、よく分かりません。コメントを Google翻訳すると、「厳密に制御されているものの危険に見える可能性のある strcmp のマクロ実装内のアクセスを除外します。」とのことでした。ChatGPT によると、strcmp 関数(マクロ?)は、問題ないので、除外する、ということらしいです。/usr/include/string.h を見てみました。マクロではなさそうです。
/* Compare S1 and S2. */ extern int strcmp (const char *__s1, const char *__s2) __THROW __attribute_pure__ __nonnull ((1, 2));
最後は reachable(this) です。コメントの Google翻訳は、「バッファアクセスは到達可能でなければならない(デッドコードではない)」とのことです。
結局のところ、BufferAccess は、固定長配列アクセス式を表すクラスで、配列サイズ、対象の変数を簡単に取り出せるようにしたもの、ということらしいです。
class BufferAccess extends ArrayExpr { BufferAccess() { exists(int size | staticBuffer(this.getArrayBase(), _, size) and size != 0 ) and // exclude accesses in macro implementation of `strcmp`, // which are carefully controlled but can look dangerous. not exists(Macro m | m.getName() = "strcmp" and m.getAnInvocation().getAnExpandedElement() = this ) and //A buffer access must be reachable (not in dead code) reachable(this) } int bufferSize() { staticBuffer(this.getArrayBase(), _, result) } Variable buffer() { result.getAnAccess() = this.getArrayBase() } }
ようやく、overflowOffsetInLoopメソッドです。ChatGPT によると、overflowOffsetInLoopメソッドは、forループのカウンタ変数が、配列のインデックスとして使われている場合に検出すると、答えが返ってきました。では、詳しく見ていきます。
loop.getStmt().getAChild*() = bufaccess.getEnclosingStmt() は、* があるので、再帰です。右辺の getEnclosingStmtメソッドは、ArrayExpr のメソッドで、対象の式を含む最小の文を取得する、という機能とのことです。つまり、配列に対して、バッファアクセスしている文という意味のようです。つまり、ネストがいくら深くてもいいので、配列の式でバッファアクセスしている文が存在することが条件ということのようです。
loop.limit() >= bufaccess.bufferSize() は、右辺は、バッファサイズで、左辺は、for文のループの上限が配列のサイズを超えている場合(例えば、配列サイズが 10 なのに、for(i = 0; i <= 10; i++) になってる場合)という条件のようです。この条件はかなり厳しいですね、これを満たしているということは、オーバーフローしてる可能性がかなり高いです。逆に言うと、あまり検知されないのでは、とも思います。
loop.counter().getAnAccess() = bufaccess.getArrayOffset() は、右辺は、バッファの配列の添え字のことらしく、左辺は、ループカウンタ変数(例:i)らしいので、配列添え字にループカウンタ変数が使われているという条件のようです。
not upperBound(bufaccess.getArrayOffset().getFullyConverted()) < bufaccess.bufferSize() は、左辺は、upperBoundメソッドは上限を求めてくれるらしく、配列添え字が取り得る上限値ということで、右辺は、バッファサイズです。つまり、否定なので、配列添え字がバッファサイズを超えない、ということはない、となり、配列添え字がバッファサイズを超えてる場合、ということのようです。
not upperBoundMayBeWidened(bufaccess.getArrayOffset().getFullyConverted()) は、upperBoundMayBeWidenedメソッドは、範囲解析で上限が不確定であることを返すようで、配列添え字が取り得る上限値が不確定である、の否定なので、不確定ではない場合、という条件のようです。誤検知を減らすために、上限値が不確定な場合は除外しているようです。
これらを全て満たした場合に、メッセージが設定されます。
predicate overflowOffsetInLoop(BufferAccess bufaccess, string msg) { exists(ClassicForLoop loop | loop.getStmt().getAChild*() = bufaccess.getEnclosingStmt() and loop.limit() >= bufaccess.bufferSize() and loop.counter().getAnAccess() = bufaccess.getArrayOffset() and // Ensure that we don't have an upper bound on the array index that's less than the buffer size. // 配列インデックスの上限が、バッファサイズより小さくならないようにしてください(大きくしてください)。 not upperBound(bufaccess.getArrayOffset().getFullyConverted()) < bufaccess.bufferSize() and // The upper bounds analysis must not have been widended // 上限分析は拡大されてはならない not upperBoundMayBeWidened(bufaccess.getArrayOffset().getFullyConverted()) and msg = "Potential buffer-overflow: counter '" + loop.counter().toString() + "' <= " + loop.limit().toString() + " but '" + bufaccess.buffer().getName() + "' has " + bufaccess.bufferSize().toString() + " elements." ) }
overflowOffsetInLoopメソッドは、forループのカウンタ変数が、配列のインデックスとして使われている場合、と上で言いましたが、forループのカウンタ変数(インデックス)が、ループの上限値を超えていること、さらに、配列の添え字(ループカウンタ変数が使われている)がバッファサイズを超えていること、という条件も含んでいました。この条件で検出することは少なそうと思いました。
wrongBufferSizeメソッド
次は、wrongBufferSizeメソッドです。
wrongBufferSizeメソッドでは、このファイル内で定義されている CallWithBufferSizeクラスが使われており、その特性メソッドでは、bufferAndSizeFunctionメソッドが呼ばれています。よって、まず、bufferAndSizeFunctionメソッドから見ていきます。
bufferAndSizeFunctionメソッドは以下です。
標準ライブラリに定義されているバッファに書き込む関数と、buf と size が条件になっています。これは、それぞれの関数のバッファとサイズの引数の位置を条件にしています(定義しているとも言える)。
predicate bufferAndSizeFunction(Function f, int buf, int size) { f.hasGlobalName("read") and buf = 1 and size = 2 or f.hasGlobalOrStdName("fgets") and buf = 0 and size = 1 or f.hasGlobalOrStdName("strncpy") and buf = 0 and size = 2 or f.hasGlobalOrStdName("strncat") and buf = 0 and size = 2 or f.hasGlobalOrStdName("memcpy") and buf = 0 and size = 2 or f.hasGlobalOrStdName("memmove") and buf = 0 and size = 2 or f.hasGlobalOrStdName("snprintf") and buf = 0 and size = 1 or f.hasGlobalOrStdName("vsnprintf") and buf = 0 and size = 1 }
CallWithBufferSizeクラスは以下です。
まず、コンストラクタ(特性メソッド)です。CodeQL のコンストラクタ(クラス名と同じ名前のメソッド)は、このクラスのインスタンスの条件が書かれるそうです。上の bufferAndSizeFunctionメソッドが使われており、FunctionCallクラスの中でも、8個の関数の呼び出しに絞られます。
bufferメソッドは、上の 8個の関数呼び出しのバッファを指定する引数を取得できます。
statedSizeExprメソッドは、上の 8個の関数呼び出しのサイズを指定する引数を取得できます。
最後は、statedSizeValueメソッドです。コメントの Google翻訳は、「e が解析不可能な場合、upperBound(e) はデフォルトで exprMaxVal(e) になります。そのため、この場合、意味のある結果を得るために、データフローと範囲解析から得られる最小値を選択します。」とのことです。詳細は分かりませんが、上の 8個の関数呼び出しの引数のサイズについて、データフローで解析した値か、型として取り得る上限値のどちらか小さい方を取得できるようです。
upperBound(e) は、式e の上限を返します。upperBound() の公式ヘルプ を見ます。キャストの影響を考慮せずに式の上限を計算するメソッドと記載されてました。また、戻り値は float でした。int型なら、int型が取りうる最大値を返すということだと思います。
minimumメソッドについてです。minimum() の公式のヘルプ を見ます。レシーバと引数の小さい方を返す、と書かれています。こちらも、戻り値は float でした。
statedSizeValueメソッドの戻り値は、int となっています。upperBoundメソッド、minimumメソッドは、どちらも、float を返します。うーん、大丈夫でしょうか。
min( A | B | C ) は、変数A のうち、B の条件を満たしたものを、C として返す、という感じです。変数A は式です。B は、ローカルデータフロー解析で、関数内で、変数A の式から statedSizeExpr(上の 8個の関数呼び出しのサイズの位置の引数)にデータが流れてること、というのが条件です。C は変数A の整数値です。よって、条件を満たしたもののうち、値として一番小さいものを返す、という意味になります。
QL language reference をちゃんと読んでから、ここは書き直します。
class CallWithBufferSize extends FunctionCall { CallWithBufferSize() { bufferAndSizeFunction(this.getTarget(), _, _) } Expr buffer() { exists(int i | bufferAndSizeFunction(this.getTarget(), i, _) and result = this.getArgument(i) ) } Expr statedSizeExpr() { exists(int i | bufferAndSizeFunction(this.getTarget(), _, i) and result = this.getArgument(i) ) } int statedSizeValue() { // `upperBound(e)` defaults to `exprMaxVal(e)` when `e` isn't analyzable. So to get a meaningful // result in this case we pick the minimum value obtainable from dataflow and range analysis. result = upperBound(this.statedSizeExpr()) .minimum(min(Expr statedSizeSrc | DataFlow::localExprFlow(statedSizeSrc, this.statedSizeExpr()) | statedSizeSrc.getValue().toInt() )) } }
ようやく wrongBufferSizeメソッドです。
CallWithBufferSizeクラスが使われています。
staticBuffer(call.buffer(), buf, bufsize) は、上の 8個の関数で使用するバッファであり、それが固定長配列であることが条件になっています。
statedSize = call.statedSizeValue() は、上の 8個の関数で指定するサイズを取得しています。
statedSize > bufsize は、固定長配列サイズより、上の 8個の関数で指定するサイズが超えていることが条件になっています。
error = call.statedSizeExpr() は、上の 8個の関数でサイズを指定している引数を取得しています(error は、表示のために使われる)。
predicate wrongBufferSize(Expr error, string msg) { exists(CallWithBufferSize call, int bufsize, Variable buf, int statedSize | staticBuffer(call.buffer(), buf, bufsize) and statedSize = call.statedSizeValue() and statedSize > bufsize and error = call.statedSizeExpr() and msg = "Potential buffer-overflow: '" + buf.getName() + "' has size " + bufsize.toString() + " not " + statedSize + "." ) }
wrongBufferSizeメソッドは、上の 8個の関数で、固定長配列が使われており、かつ、関数で指定したサイズが、配列サイズを超えている場合に、検出するようです。
outOfBoundsメソッド
outOfBoundsメソッドは以下です。
ここでも、BufferAccessクラスが使われています。BufferAccessクラスは、固定長配列に対して、ArrayExpr(Expr[Expr])の形でアクセスしている式です。
existsメソッドの最初の 2行は、バッファ名、バッファサイズを取得しています。
bufaccess.getArrayOffset().getValue().toInt() = access は、バッファに添え字でアクセスしていて、かつ、その添え字が整数定数である場合(x[10] = 3 とか)に、その値を取得しています。
丸括弧の中では、検出する条件を設定していて、まず、access > size は、バッファサイズより、添え字の整数定数の方が大きい場合に検出します。
もしくは、access = size(バッファサイズと添え字が同じ値)の場合で、以下の 2つの条件は除外します。
not exists(AddressOfExpr addof | bufaccess = addof.getOperand()) の、AddressOfExpr は、CodeQL library for C and C++ によると、& Expr なので、&x[10](実際にアクセスしないため問題ない)とかになってる場合は除外(検知しない)となっています。
not exists(BuiltInOperationBuiltInOffsetOf offsetof | offsetof.getAChild() = bufaccess) は、offsetof関数(構造体の先頭からメンバまでのバイトオフセットを返す標準関数)に、整数定数での添え字アクセスがあった場合は除外するとなっています。例えば、offsetof(struct S, buf[10]) とかで、これも実際にアクセスするわけではないので、問題なしと扱っているようです。
predicate outOfBounds(BufferAccess bufaccess, string msg) { exists(int size, int access, string buf | buf = bufaccess.buffer().getName() and bufaccess.bufferSize() = size and bufaccess.getArrayOffset().getValue().toInt() = access and ( access > size or access = size and not exists(AddressOfExpr addof | bufaccess = addof.getOperand()) and not exists(BuiltInOperationBuiltInOffsetOf offsetof | offsetof.getAChild() = bufaccess) ) and msg = "Potential buffer-overflow: '" + buf + "' has size " + size.toString() + " but '" + buf + "[" + access.toString() + "]' may be accessed here." ) }
outOfBoundsメソッドは、固定長配列に対して、整数定数の添え字によるアクセスで配列サイズを超えているかどうかを検知しているようです。
UnterminatedVarargsCall.ql
CWE-121 のスタックオーバーフローのディレクトリには、このクエリ(UnterminatedVarargsCall.ql)だけが格納されています。こちらを見ていきます。
まず、メタデータです。アラートクエリです。
description の Google翻訳は、「センチネル値なしで可変引数関数を呼び出すと、関数が引数リストを終了するために特定の値を想定している場合にバッファ オーバーフローが発生する可能性があります。」でした。センチネル値は、NULL のような終端の値と考えてよさそうです。
うーん、スタックバッファオーバーフローのクエリということで、かなり期待してたんですが、可変長の引数を持つ関数が対象ということで、かなりレアなクエリみたいなので、少しモチベーションが下がってます(笑)。
/** * @name Unterminated variadic call * @description Calling a variadic function without a sentinel value * may result in a buffer overflow if the function expects * a specific value to terminate the argument list. * @kind problem * @problem.severity warning * @security-severity 8.8 * @precision medium * @id cpp/unterminated-variadic-call * @tags reliability * security * external/cwe/cwe-121 */
次に、from/where/select句を見ます。
select句を見ると、関数呼び出し(FunctionCall)をターゲットにしてるようです。これを見て、使われてるメソッドを追っていきたいと思います。
from VarargsFunction f, FunctionCall fc, string terminator, int cnt, int totalCount where terminator = f.normalTerminator(cnt, totalCount) and fc = f.getACallToThisFunction() and not normalisedExprValue(f.trailingArgumentIn(fc)) = terminator and not f.isWhitelisted() select fc, "Calls to $@ should use the value " + terminator + " as a terminator (" + cnt + " of " + totalCount + " calls do).", f, f.getQualifiedName()
あとは、1つのクラス(VarargsFunctionクラス)がほとんどなので、残りを貼り付けます。
このクラスの特性メソッド(コンストラクタ)を見ると、可変長の引数を持ち、printf系の関数を除いた関数を対象にしているようです。
where句で呼ばれている normalTerminatorメソッドを見ます。これを理解するには、どんどん呼び出し関係をさかのぼる必要があります。trailingArgValueCountメソッドを見ると、trailingArgValueメソッドが呼ばれています。trailingArgValueメソッドを見ると、normalisedExprValueメソッドと、trailingArgumentInメソッドが呼ばれています。
trailingArgumentInメソッドを見ます。getACallToThisFunctionメソッドで、fc が、可変長の引数を持つ関数、つまり、対象の関数と一致しているという条件です。getNumberOfArgumentsメソッドは、引数の数を返します。getArgumentメソッドで、その fc の末尾の引数を取得して返します。
normalisedExprValueメソッドを見ます。getValueメソッドで式の値を取得しています。Expr::getValue() の公式ヘルプ を見ます。この式が定数の場合、その値を取得します、と書かれてます。戻り値が string なので、regexpReplaceAllメソッドを探しましたが見つかりません。C/C++ のメソッドに無いのは変だと思いますが、Java and Kotlin のライブラリにあったので、代わりに参考にします。string::regexpReplaceAll() の公式ヘルプ を見ると、マッチした部分を全て置換するメソッドで、ピリオド+ゼロ+行末を削除することになると思います。normalisedExprValueメソッドは、「-1.0」などを「-1」にして返すメソッドということのようです。つまり、trailingArgumentInメソッドで可変長の引数を持つ関数の末尾の引数が定数の場合に、「.0」を削除して返す、ということになります。
trailingArgValueCountメソッドを見ます。strictcountメソッドは集約関数で、countメソッドと同じ機能ですが、対象がなかった場合に空集合を返すところが違うようです。つまり、引数の value と、可変長の引数を持つ関数の末尾の定数の引数の値が一致した数を返すメソッドのようです。
nonTrailingVarArgValueメソッドを見ます。getNumberOfParametersメソッドは、可変長の引数を持つ関数の引数のうち、固定の引数の個数を返すそうです。引数の index が可変長の引数の位置と一致する場合という条件になります。つまり、引数の index が、可変長引数の開始位置から、末尾の引数を除いた位置までの場合に、その引数を「.0」を除いて返します。
totalCountメソッドを見ます。可変長の引数を持つ関数の個数を返します。
ようやく、normalTerminatorメソッドです。可変長の引数を持つ関数の個数のうち、末尾の定数の引数が、"0" か "-1" のパーセンテージを求めていて、それが 80パーセント以上の場合という条件です。さらに、可変長引数の引数のうち、末尾の引数以外で、"0" か "-1" が使われていないことが条件です。
isWhitelistedメソッドを見ます。対象の関数が、open関数、fcntl関数、ptrace関数、mremap関数だった場合という条件です。where句では not が付いているので、これらの関数以外を対象とするということのようです。
最後に where句を再度見ます。normalTerminatorメソッドの条件を満たす場合に、select句の指摘を出すようです。
import cpp /** * Gets a normalized textual representation of `e`'s value. * The result is the same as `Expr.getValue()`, except if there is a * trailing `".0"` then it is removed. This means that, for example, * the values of `-1` and `-1.0` would be considered the same. */ string normalisedExprValue(Expr e) { result = e.getValue().regexpReplaceAll("\\.0$", "") } /** * A variadic function which is not a formatting function. */ class VarargsFunction extends Function { VarargsFunction() { this.isVarargs() and not this instanceof FormattingFunction } Expr trailingArgumentIn(FunctionCall fc) { fc = this.getACallToThisFunction() and result = fc.getArgument(fc.getNumberOfArguments() - 1) } string trailingArgValue(FunctionCall fc) { result = normalisedExprValue(this.trailingArgumentIn(fc)) } private int trailingArgValueCount(string value) { result = strictcount(FunctionCall fc | this.trailingArgValue(fc) = value) } string nonTrailingVarArgValue(FunctionCall fc, int index) { fc = this.getACallToThisFunction() and index >= this.getNumberOfParameters() and index < fc.getNumberOfArguments() - 1 and result = normalisedExprValue(fc.getArgument(index)) } private int totalCount() { result = strictcount(FunctionCall fc | fc = this.getACallToThisFunction()) } string normalTerminator(int cnt, int totalCount) { // the terminator is 0 or -1 result = ["0", "-1"] and // at least 80% of calls have the terminator cnt = this.trailingArgValueCount(result) and totalCount = this.totalCount() and 100 * cnt / totalCount >= 80 and // terminator value is not used in a non-terminating position not this.nonTrailingVarArgValue(_, _) = result } predicate isWhitelisted() { this.hasGlobalName(["open", "fcntl", "ptrace", "mremap"]) } }
OverflowBuffer.ql
CWE-119 のバッファエラーのディレクトリには、このクエリ(OverflowBuffer.ql)と、OverrunWriteProductFlow.ql(パスクエリ)が格納されています。
まず、メタデータです。アラートクエリです。
description の Google翻訳は、「メモリバッファにアクセスする関数を誤って使用すると、バッファの末尾を超えてデータの読み取りまたは書き込みが行われる可能性があります。」でした。典型的なバッファオーバーフローのクエリのようです。
/** * @name Call to memory access function may overflow buffer * @description Incorrect use of a function that accesses a memory * buffer may read or write data past the end of that * buffer. * @kind problem * @id cpp/overflow-buffer * @problem.severity warning * @security-severity 9.3 * @precision medium * @tags security * external/cwe/cwe-119 * external/cwe/cwe-121 * external/cwe/cwe-122 * external/cwe/cwe-126 */
このクエリは、from/where/select句に、内容が書かれていて、from/where/select句が、ほぼ全体を占めています。
where句で使われている pluralメソッドから見ていきます。bindingset が使われています。bindingset は、CodeQL(静的解析ツール)のクエリの書き方を調べた - Binding behavior(バインディングの動作) に、説明があります。num、singular、plural の 3つの引数について、全て独立にバインド(束縛)しています。つまり、呼び出し元で制限してるので、ここでは、制限しないので、コンパイルエラーにしないでね、という宣言という理解です。
if ... then ... else については、CodeQL(静的解析ツール)のクエリの書き方を調べた - Formulas(数式) に解説があります。普通の条件分岐と思って、読んでいいと思います。
num が 1 の場合は、num + singular を返し、それ以外の場合は、num + plural を返すメソッドです。
bindingset[num, singular, plural] string plural(int num, string singular, string plural) { if num = 1 then result = num + singular else result = num + plural }
それでは、from/where/select句を見ていきます。
全体として、accessType が全体を分けています。accessType は、BufferAccessクラスの getBufferメソッドで決まっていそうです。BufferAccessクラスの公式ヘルプ を見ます。BufferWriteクラスに言及しているので、BufferWriteクラスの公式ヘルプ も見ます。なるほど、BufferWriteクラスは、null を終端とするバッファ書き込み操作(strcpy、strncat、sprintf など)に特化していて、BufferAccessクラスはデータに依存しないバッファの読み取り、書き込み操作を全般的にカバーしているそうです。
BufferAccessクラスの getBufferメソッドの公式ヘルプ を見ます。バッファアクセスの種類 を accessType にセットし、バッファの式を返すようです。accessType の具体的な説明は以下です。bufferDesc はバッファのテキストラベルで、getSize は、バイト単位のバッファのアクセスサイズとのことです。getBufferSizeメソッドは上の VeryLikelyOverrunWrite.ql で出てきていて、バッファサイズをバイト単位で取得します。
- accessType が 1 の場合、バッファの範囲(0、getSize)の全体にアクセスされる(ChatGPT によると書き込みアクセスらしいです)
- accessType が 2 の場合、バッファの範囲(0、getSize)の部分的、または、全体的にアクセスできる(ChatGPT によると読み込みアクセスらしいです)
- accessType が 3 の場合、バッファはオフセット getSize - 1 でアクセスされる(ChatGPT によるとオフセットありのアクセスらしいです)
- accessType が 4 の場合、バッファは、null終端で読み取り保護付きでアクセスされる(アクセスサイズに関係なく、null終端を超えて読み取らない)
if が出現するまでの部分は、accessType が 4 ではなく、バッファサイズより、バッファへのアクセスサイズが大きいか、もしくは、負のインデックスでバッファにアクセスしている場合が該当するという意味になりそうです。
if 以降は、accessType が 1、2、3 のそれぞれについて、メッセージを作成しているだけです。accessType = 1 の場合は、バッファのアクセスサイズが XX だが、バッファサイズは YY である、という内容です。accessType = 2 の場合は、バッファのアクセスサイズが XX かもしれないが、バッファサイズは YY である、という内容で、微妙な違いです。accessType = 3 で、かつ、accessSize > 0 の場合は、アクセスするときのオフセットがバッファサイズを超えているというメッセージで、accessSize <= 0 の場合は、負のインデックスでアクセスしてるとうメッセージのようです。
実際に、このクエリを見てみると、負のインデックスという局所的な条件を、いったん置いておくと、バッファサイズより、バッファのアクセスサイズが大きい場合という条件だけのように見えます。どんなバッファで、どんなアクセス方法なのかといったところが、このファイルだけを見ていても分かりません。BufferAccessクラスを理解しないと、そのあたりが見えてこないんだろうと思います。
from BufferAccess ba, string bufferDesc, int accessSize, int accessType, Element bufferAlloc, int bufferSize, string message where accessType != 4 and accessSize = ba.getSize() and bufferSize = getBufferSize(ba.getBuffer(bufferDesc, accessType), bufferAlloc) and ( accessSize > bufferSize or accessSize <= 0 and accessType = 3 ) and if accessType = 1 then message = "This '" + ba.getName() + "' operation accesses " + plural(accessSize, " byte", " bytes") + " but the $@ is only " + plural(bufferSize, " byte", " bytes") + "." else if accessType = 2 then message = "This '" + ba.getName() + "' operation may access " + plural(accessSize, " byte", " bytes") + " but the $@ is only " + plural(bufferSize, " byte", " bytes") + "." else ( if accessSize > 0 then message = "This array indexing operation accesses byte offset " + (accessSize - 1) + " but the $@ is only " + plural(bufferSize, " byte", " bytes") + "." else message = "This array indexing operation accesses a negative index " + ((accessSize / ba.getActualType().getSize()) - 1) + " on the $@." ) select ba, message, bufferAlloc, bufferDesc
$@ については、CodeQL(静的解析ツール)のクエリの書き方を調べた - Defining the results of a query(クエリの結果の定義) に解説があります。select句の 3、4番目の内容で、リンクを作ってくれるようです。
試しに、負のインデックスでアクセスするように、ソースコードを書き換えて、OverflowBuffer.ql を実行してみました。以下のような指摘になりました。リンクが作成されています。「array」のリンクをクリックすると、指摘対象のバッファの定義位置(char buf[1024];)にジャンプしました。一方、「httpd.c:233:13」をクリックすると、負のインデックスでアクセスしている位置(buf[-1] = '\0';)にジャンプしました。

BadlyBoundedWrite.ql
CWE-120 の古典的バッファオーバーフローのディレクトリには、5つのクエリが含まれていて、このクエリ(BadlyBoundedWrite.ql)は、そのうちの 1つです。
まず、メタデータです。アラートクエリです。
description の Google翻訳は、「長さパラメータが宛先バッファのサイズと一致しないバッファ書き込み操作では、オーバーフローが発生する可能性があります。」でした。
/** * @name Badly bounded write * @description Buffer write operations with a length parameter that * does not match the size of the destination buffer may * overflow. * @kind problem * @problem.severity error * @security-severity 9.3 * @precision high * @id cpp/badly-bounded-write * @tags reliability * security * external/cwe/cwe-120 * external/cwe/cwe-787 * external/cwe/cwe-805 */
とても小さいファイルですので、残り全部を貼り付けます。
ざっくり言うと、書き込みサイズが確定している標準ライブラリを用いていて、バッファのサイズを超えているときに指摘するクエリです。
上の OverflowBuffer.ql で、BufferWriteクラスの公式ヘルプ を見ました。BufferWriteクラスは、null を終端とするバッファ書き込み操作(strcpy、strncat、sprintf など)を対象としているようです。
hasExplicitLimitメソッドは、上の VeryLikelyOverrunWrite.ql で出ていて、オペレーション(C言語のライブラリ関数)が、明確な制限のあるパラメータを持っているかどうかを判定する、ということでした。例えば、strncpy、strncat などです。
次の条件は、getDestメソッドは、同様に、VeryLikelyOverrunWrite.ql で出ていて、書き込み先のバッファのことです。getBufferSizeメソッドで、そのバッファサイズを求めて、maxメソッドは最大値を取り、destSize に格納します。
getExplicitLimitメソッドは、前述のオペレーションの書き込みサイズを取得します。destSize より大きい場合という条件になります。
not から始まる残り 2行は誤検知防止のためのようです。前者は、バッファの型を取得して、解析できない場合は除外しています。後者は、ChatGPT によると、ビルド設定ファイルや、テストファイルを除外しているようです。
このクエリに関しても、BufferWriteクラスを解析しないと、詳しいところは分からないと思いました。
import semmle.code.cpp.security.BufferWrite import semmle.code.cpp.ConfigurationTestFile /* * See CWE-120/UnboundedWrite.ql for a summary of CWE-120 alert cases. */ from BufferWrite bw, int destSize where bw.hasExplicitLimit() and // has an explicit size limit destSize = max(getBufferSize(bw.getDest(), _)) and bw.getExplicitLimit() > destSize and // but it's larger than the destination not bw.getDest().getType().stripType() instanceof ErroneousType and // destSize may be incorrect not bw.getFile() instanceof ConfigurationTestFile // expressions in files generated during configuration are likely false positives select bw, "This '" + bw.getBWDesc() + "' operation is limited to " + bw.getExplicitLimit() + " bytes but the destination is only " + destSize + " bytes."
おわりに
今回は、CodeQL CLI で使われるクエリで、現在の対象のソースコードで指摘を出しているクエリのうち、アラートクエリの実装を見ていきました。2つしか見ていませんが、今後、アラートクエリを見る機会があれば、この記事に追記していこうと思います。
当初の目標だった Use After Free が検知できそうなクエリとして、UseAfterFree.ql がありますが、これはパスクエリでした。
次回は、パスクエリの UseAfterFree.ql を見ていきます。
最後になりましたが、エンジニアグループのランキングに参加中です。
気楽にポチッとよろしくお願いいたします🙇
今回は以上です!
最後までお読みいただき、ありがとうございました。
