こんにちは、クラウドサインで CRE(Customer Reliability Engineer)をしている藤谷です。
顧客から問い合わせが来るとき、その文面には本当の困りごとが書かれていないことが多いです。対応して答えを返す。でも同じような問い合わせが繰り返される。
問い合わせに答えることと、困りごとを解決することは別の話だからです。
CRE の仕事では、目の前の質問に答えるだけでなく「なぜその問い合わせが生まれたか」まで追いかけます。その起点となるのが、課題整理です。
課題整理の質はばらつきがちです。「WHAT は言えるが WHO が曖昧」「問題は見えていても言語化できない」など、詰まりやすいポイントは人によって異なります。個人の感覚に任せていると、同じ困りごとを前にしても、チームの見立てがばらけます。
今回は、私が CRE として課題整理に使っている考え方と、それを社内ガイドや Agent Skills に展開した話を紹介します。私自身、課題整理が難しいと感じる場面も多いので、あらためて整理してみました。
なおクラウドサインの CRE が Agent Skills を活用している背景については、以下の記事も参照してください。
- 問い合わせ対応の全工程の自動化を AI で実現 - CRE による MCP から Agent Skills 移行の記録
- AI は「答え」ではなく「目」になる — CRE の Agent Skills 設計思想
課題整理の難しさ
例えば、問い合わせ対応完了後の振り返りを考えてみます。
今月、申込画面に関する同種の問い合わせが 5 件来た。対応はすべて完了している。でも「これを改善につなげたい」と思って Jira に起票しようとしたとき、手が止まります。
「問い合わせが多い」とだけ書いても課題にはなりません。この時点では、次のような情報が整理されていないことが多いからです。
- 誰が困っているのか
- 何が起きているのか
- どんな条件で起きるのか
- 放置すると何が困るのか
- その主張を裏づける証拠はあるのか
これが整理されないまま「では画面の文言を直しましょう」と話を進めると、解決策が先行してしまいます。CRE として本当に見たいのは「何を直すか」ではなく「どのギャップが、誰に、どんな影響を与えているか」です。
整理の観点が人によって違うと、同じ問い合わせをもとにしても「文言の問題」と整理するメンバーと「フロー設計の問題」と整理するメンバーが出てきます。どちらも完全な誤りではありませんが、観点を揃えておくと議論がしやすくなります。
課題整理で起きやすい3つの混線

実際に整理していく中で、特に混線しやすいポイントは 3 つありました。
「困りごと」と「解決策」が混ざる
問い合わせの内容をそのまま課題にしてしまうケースがよくあります。
「CSV 一括登録を作ってほしい」という問い合わせが完了した後、Jira に起票するとします。タイトルは「CSV 一括登録を実装する」。やることは明確に見えます。ただ、本当に見たいのは、その手前です。
- 誰が
- どの業務フローで
- どの作業に時間がかかっていて
- 何がつらいのか
解決策から入ると、課題のスコープを狭めてしまいます。「反復的な登録作業が月初業務を圧迫している」ことも「入力ミスが多くて手戻りが発生している」ことも考えられます。
事実と仮説が混ざる
もう 1 つ多いのが「問い合わせが多いのは文言がわかりづらいからだ」といった整理です。
これは、途中までは正しいです。ただし厳密には、次のとおりです。
- 「問い合わせが多い」は事実
- 「文言がわかりづらい」は仮説
この 2 つを混ぜると、議論がぶれます。対策の優先度も、根拠の強さも、曖昧になってしまうからです。
強い主張ほど、強い証拠が必要です。この原則を守るだけでも、課題整理の精度はかなり変わります。
例えば次のように整理できます。
- 事実:「今月、同種問い合わせが 5 件あった」
- 仮説:「文言の曖昧さが誤認を招いている」
このように分けて書くだけで、次に何を確かめるべきかが明確になります。この場合、次に見るべきなのは、問い合わせ原文や該当画面の文言です。
問題と影響が切り離される
「手順が曖昧」「説明が不足」「仕様が複雑」といった表現は、現象としてはわかります。ただ、それだけでは「なぜ重要なのか」が伝わりません。
だから私は、課題タイトルも含めて 「現象 + 影響」 で書くことを重視しています。
例えば次のような違いがあります。
- 悪い例:「エラー通知の不明確さ」
- 良い例:「不明確なエラー通知が原因特定を阻み対応に時間がかかっている」
課題整理は、単に文章を整える作業ではありません。その課題に今向き合う価値があるのかを、チーム全員が瞬時に判断できるよう整える作業だと考えています。
課題整理の考え方
私が課題整理をするときに使っている観点です。
最低限そろえる4つの観点
まず、課題整理の入口では次の 4 つをそろえます。
- WHO:誰が困っているのか
- WHAT:何が起きているのか
- 影響:放置すると何が困るのか
- 発生条件:どこで、いつ、どんな条件で起きるのか
一見すると当たり前ですが、実際にはこれだけでもかなり強いです。特に「発生条件」を入れることで「全ユーザーが常に経験する問題」なのか「特定条件でのみ起きる問題」なのかを切り分けやすくなります。
事実・証拠・仮説・未確認事項を分ける
そのうえで、記述を次の 4 つに分けます。
- 事実
- 証拠
- 仮説
- 未確認事項
優先度も「証拠込み」で判断する
さらに、優先度を決めるときも、感覚ではなく観点をそろえました。
- 影響度
- 頻度
- 回避可能性
- 根拠
例えば、問い合わせ件数が少なくても、業務停止や信頼低下につながるなら優先度は上がります。逆に件数が多くても、軽微で運用回避が容易なら、必ずしも最優先とは限りません。
ここで重要なのは「根拠」も優先度判断に含めることです。証拠が弱いなら、優先度の置き方も慎重であるべきだからです。
例えば、こう整理すると見え方が変わる
先ほどの問い合わせ対応後の振り返りに戻ります。
「CSV 一括登録を作ってほしい」という問い合わせが完了した後、この状況を起票するとします。
入力(問い合わせ原文)
「CSV 一括登録を作ってほしい」
この一文だけでは整理になりません。ここからヒアリングで情報を補います。
ヒアリングで確認した情報
- WHO:ユーザー管理を担当する管理者
- WHAT:月初に新規ユーザーを 1 件ずつ手入力している
- 発生条件:月初のユーザー登録作業時のみ
- 影響:毎月月初の業務が 2 時間程度圧迫されている
- 証拠:担当者ヒアリング(件数・ログは未確認)
整理後
- 問題定義:管理者が月初に新規ユーザーを 1 件ずつ手入力しており、毎月 2 時間程度の定常コストが発生している
- 課題:手作業を前提とした登録フローが管理者の月初業務を恒常的に圧迫している
「問題定義」は起きている事象の記述で「課題」はその構造をテーマ化したものです。問題定義が事実ベースであるのに対し、課題は「なぜ繰り返されるか」という構造的な視点を含みます。

ここまで整理できると、議論の幅が変わります。
- 本当に必要なのは CSV なのか
- 既存機能の組み合わせで回避できないか
- そもそも入力作業そのものを減らせないか
といった話ができるからです。
CRE が見たいのは「ほしい機能」ではなく「解決すべきギャップ」です。
課題整理から改善検討・タスク化まで一貫してつなぐ
課題整理の考え方を整理していくと、課題整理の出力を使い捨てにしないことが大事だと気づきました。課題整理・改善検討・タスク化のそれぞれで書き方が変わっていては、せっかく整理した内容が途中で崩れます。
私は最終的に、課題整理の出力を起点にして、次のような流れでつなげています。
- まず問題定義を作る
- その出力をもとに、改善候補の検討につなげる
- さらにそのまま、必要なタスク化につなげる
つまり「課題整理」と「改善検討」と「タスク化」を別々に文章化しないようにしました。
これをやる前は、同じ内容でも次のように書き方が変わりがちでした。
- 課題整理の場では別の言い方
- 改善を検討するときは別の切り口
- タスク化するときはまた別の書き方
AI に渡すときも同じです。最初に問題定義へ整理してから AI に渡すと、AI は「自由に作文する」のではなく「この枠の中で考える」状態になります。これにより、AI の出力も以前より安定しやすくなりました。
例えば、同じ問い合わせに対して「機能不足」と書く回と「運用の迷い」と書く回が混在していた場面でも、問題定義を通したあとは「誰が」「何に困っているか」を起点に整理されやすくなりました。
そうすると、途中で余計な解釈が増えにくくなり、真因から遠ざかりにくくなります。
これは AI 活用の話であると同時に、チームの認識コストを下げる設計の話でもあります。
Agent Skills として実装した problem-framing
課題整理の考え方を整理した後、私はこれを Agent Skills として実装しました。スキルの名前は problem-framing です。
なぜスキル化したか
課題整理は、慣れている人とそうでない人で質が大きくばらつきます。「WHAT は言えるが WHO が曖昧」「問題は見えていても言語化できない」など、詰まりやすいポイントは人によって異なります。
スキルがやっていることは、このガイドに書いてある「聞くべき問い」を順番に投げて整理を手伝うことに過ぎません。事実を知っているのも、現場の文脈を持っているのも自分自身で、AI が代わりに考えることはできません。ただ「何から聞けばいいかわからない」「整理しようとしたが散らかった」というときに、壁打ち相手として使うのが一番効果的です。
ワークフロー
スキルは次のような流れで動きます。
- 断片的な「困りごと」を受け取る
- 論点を分類(顧客影響 / 社内運用 / 障害再発 / 要望整理)
- WHO / WHAT / 影響 / 発生条件の 4 点が揃うまでヒアリング
- 事実・証拠・仮説・未確認事項を整理
- 浅い点があれば深掘り技法で掘り下げ
- 1 文の Problem Statement を生成
- 課題タイトルを導出
- 構成テンプレートに出力
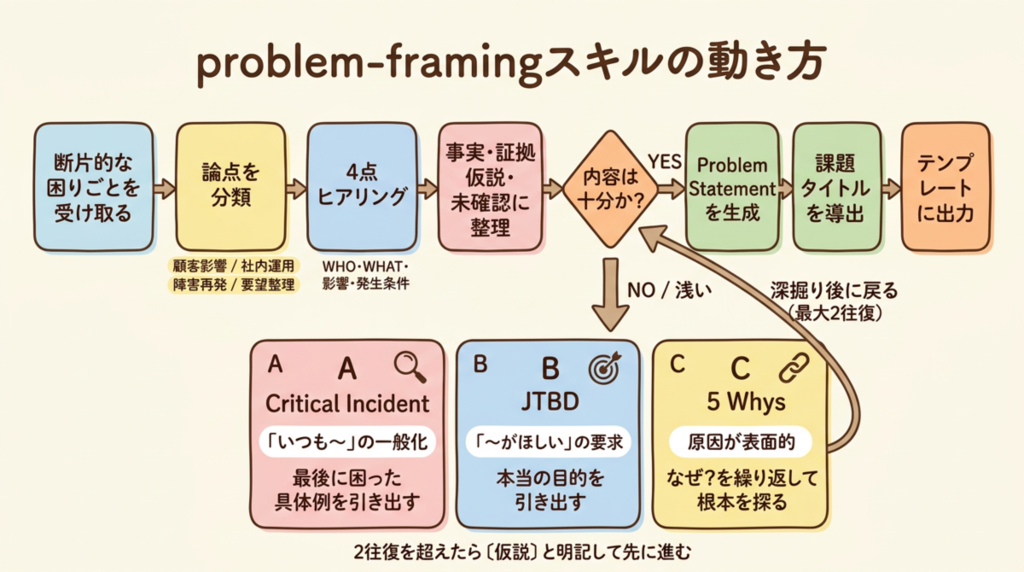
深掘り技法
4 点が揃っていても、内容が浅い場合はそのまま先に進みません。状況に応じた技法で掘り下げます。
Critical Incident —「いつも〜」「よく〜」という一般化に対して、最後に困った具体例を引き出す。
「最近これで実際に困ったのはいつ?そのとき何が起きた?」
JTBD(Jobs To Be Done) —「〜がほしい」という解決策要求から、本当の目的を引き上げる。
「この問題が解決されると、最終的に何が達成できる?」
5 Whys — 原因仮説が表面的なとき、根本原因を見極めるために「なぜ」を繰り返す。
例:「メールが届かない」→「送信元設定が誤っている」→「設定変更時の確認手順がない」
深掘りは最大 2 往復まで。それ以上は「〔仮説〕」と明記して先に進みます。
出力フォーマット
スキルが生成する出力は次の形式です。
## 問題定義
{1文の Problem Statement}
- WHO: {誰が}
- WHAT: {何が起きているか}
- 発生条件: {どこで・いつ・どんな条件で起きるか}
- 影響: {放置するとどうなるか}
- 証拠: {問い合わせ件数 / ログ / 具体例}
- 仮説: {現時点の見立て。断定しない}
---
## 課題
**{課題タイトル}**
- 優先度: {高 / 中 / 低}
- 優先度の理由: {影響度・頻度・回避可能性・根拠}
### 背景(事実)
{今どんな状態か。誰が・いつから・何が起きているか}
### 問題(影響)
{その事実によって何が困るか}
### 課題(取り組むべきこと)
{この問題に対して何に取り組むか。ゴールのイメージ}
### 未確認事項
{追加調査が必要な点。なければ省略}
使い方
「課題をまとめて」「何が問題かわからない」「モヤモヤしている」と話しかけるだけで起動します。断片的な情報でよく、AI が足りない部分を聞いてきます。
課題整理の責任は CRE が持つ
前の記事で書いたとおり、クラウドサインの CRE では問い合わせ対応で AI を活用しており、AI は関連するコンテキストをすべて持っています。AI に任せることは前提です。
ただ、AI に任せているからこそ、CRE 自身が課題を把握していることが重要になります。AI が出した問題定義や課題整理の結果に責任を持つのは CRE 自身だからです。
- どのような問いを立てるか
- どこまでを事実とみなすか
- 仮説をどの粒度で置くか
- 何をもって優先度を上げるか
こういった判断基準を自分が持っているからこそ、AI の出力をジャッジできます。基準がなければ、AI が出した整理がずれていても気づけません。
AI に任せる範囲が広がるほど、CRE 自身の課題把握の質が問われる。私は今回、そのことをあらためて実感しました。
まとめ
最後に、今回の話を 4 つにまとめます。
- 課題整理では「解決策」ではなく「困りごとの構造」から見る
- WHO / WHAT / 影響 / 発生条件に加え、証拠と仮説を分けて書く
- 課題整理からタスク化まで同じ出力でつなぐ
- その考え方を Agent Skills に実装し、AI との壁打ちで誰でも整理できるようにした
問い合わせ対応が完了したとき、それで終わりにするのか、改善につなげるかは、課題を正しく整理できるかどうかにかかっています。CRE として追いかけたいのは「今回の回答」ではなく「次に同じ困りごとが生まれにくい世界」です。
そのために、これからも課題の真因特定と整理の質を磨き続けていきます。
