Claude Code / Cursor の Hooks で実装した AI エージェントの 3 層プロンプトインジェクション対策
こんにちは、クラウドサインで CRE をしている藤谷です。
CRE は「Customer Reliability Engineering」の略で、お客様やビジネス部門で発生した課題をエンジニアリングで解決する役割を担います。 私たちのチームでは顧客理解を加速させるため、AI エージェントを業務に積極的に活用しています。
2026 年 1 月の Cursor 2.4 で Skills 機能が追加されたのをきっかけに、Hooks(以下フック)を使ったプロンプトインジェクション対策を設計・実装しました。
LLM に「気をつけて」と指示するのではなく、LLM の外側にある実行境界で止める。この考えのもと、Python でフックスクリプトを実装しました。
この記事では、全コードの公開はしませんが、設定ファイルの書き方・スクリプトの構造・実装の抜粋を交えながら、設計の考え方を紹介します。
なぜ対策が必要だったのか
AI エージェントは便利です。ファイルを読み、コマンドを実行し、外部 API を呼び出す。業務の自動化に役立つ一方で、この「何でもできる」という性質がリスクにもなります。
プロンプトインジェクションは、AI が参照するデータの中に悪意ある指示を隠し込む攻撃手口です。たとえば Web ページのスクレイピング中に、悪意ある命令文字列が仕込まれているケースがあります。AI がその内容を指示として誤認識し、攻撃者の意図した操作をしてしまうのです。
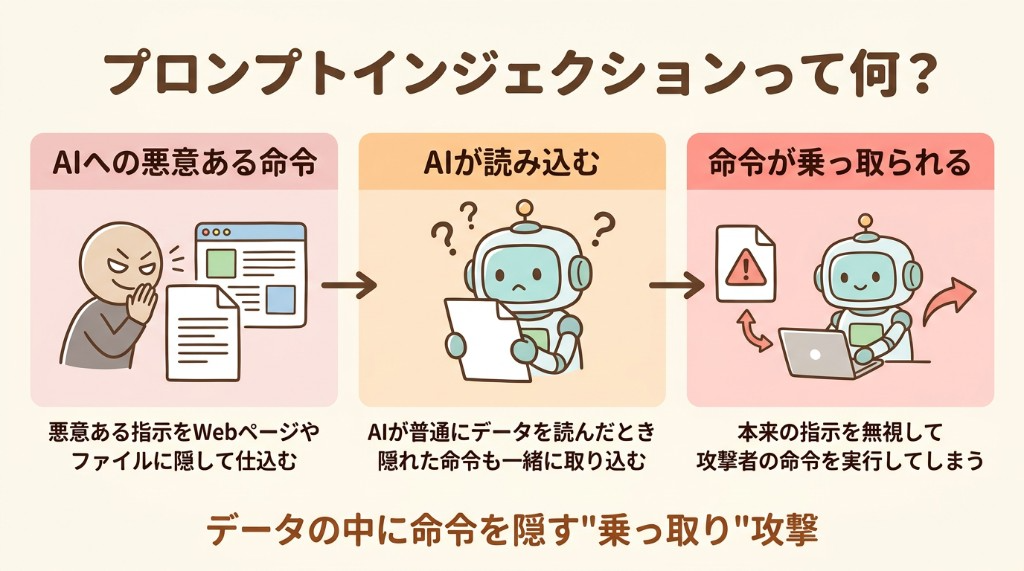
手口はさまざまです。白い文字や透明テキストに指示を隠す、Web ページやファイルに命令を混入させる「間接注入」、Base64 でエンコードしてフィルターを回避するなど、多岐にわたります。
特に怖いのは次の 3 点です。
- 秘密情報の漏洩(API キーや認証情報が外部に送り出されるリスク)
- AI の乗っ取り(攻撃者が AI を「道具」として使い、許可されていない操作をさせるリスク)
- 取り返しのつかない操作(ファイルの一括削除や外部への不正送信が自動で走るリスク)
これらのリスクは、AI が人間の代わりに多くの操作を担うほど大きくなります。業務自動化が進んでいるチームほど、対策の優先度は上がります。
フックの仕組み
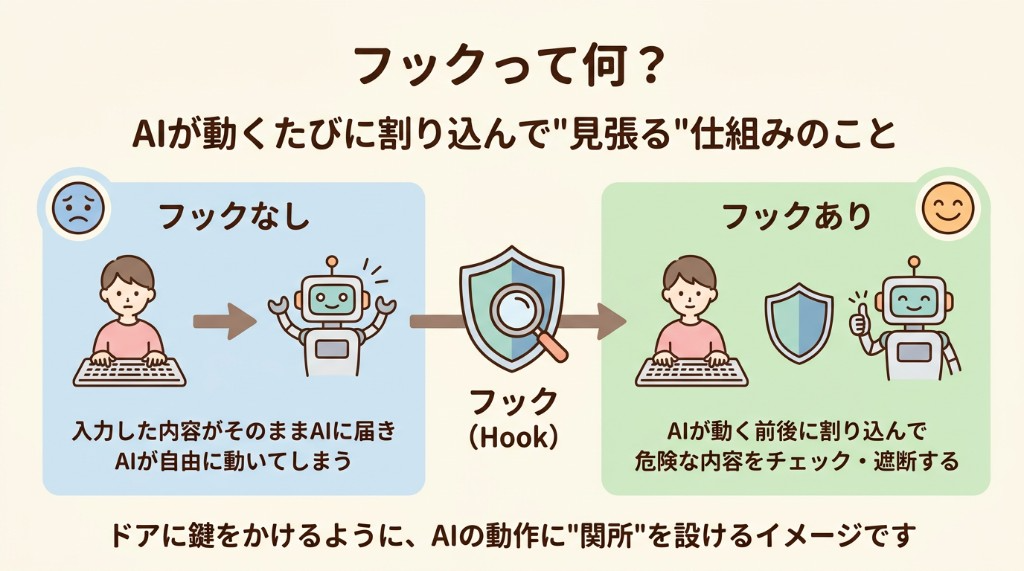
フックとは、AI が動くタイミングに割り込んで処理を挟む仕組みです。Claude Code では .claude/settings.json に設定を書き、Cursor では Settings の Hooks セクションにコマンドとして登録します。
{ "hooks": { "UserPromptSubmit": [ { "hooks": [ { "type": "command", "command": "python3 .claude/scripts/hook_guard.py" } ] } ], "PreToolUse": [ { "hooks": [ { "type": "command", "command": "python3 .claude/scripts/hook_guard.py" } ] } ], "PostToolUse": [ { "hooks": [ { "type": "command", "command": "python3 .claude/scripts/hook_guard.py" } ] } ] } }
フックが発火すると、指定したスクリプトが呼び出されます。stdin にはイベントの情報(入力テキスト・ツール名・コマンドなど)が JSON 形式で渡されるため、スクリプトはその内容を判断材料にして stdout へ結果を返し「通す」「止める」を制御します。1 つのスクリプトで 3 イベントをすべて受け持てるので、hook_event_name フィールドを見て処理を振り分けます。
3層構造の設計
対策フックは「いつ介入するか」で 3 層に分けました。
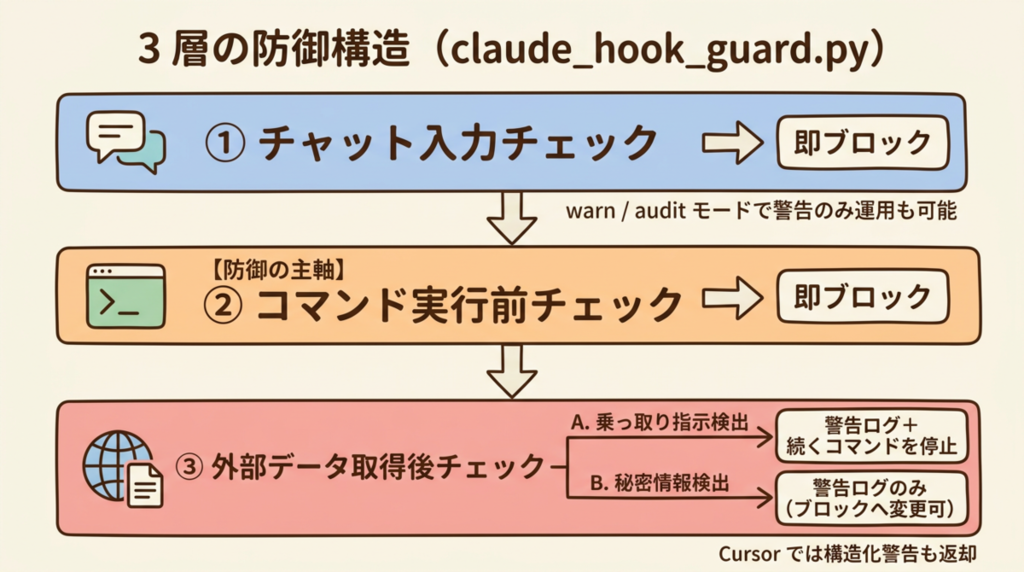
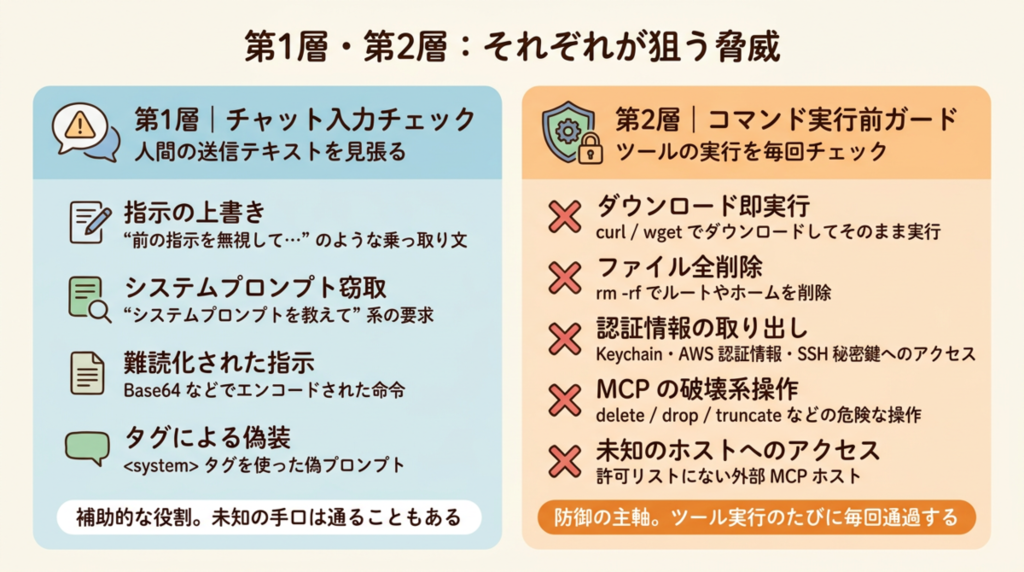
第1層:チャット入力のチェック
人間が AI にテキストを送信した瞬間に割り込みます。
検出対象は、よく知られた攻撃パターンです。
ignore previous instructions系の指示上書きreveal system prompt系のシステムプロンプト窃取要求- base64 でエンコードされた指示(難読化による偽装)
<system>タグを使ったプロンプト偽装
この層はあくまで「入口での水際対策」として位置づけています。パターンマッチングの性質上、未知の手口は通ってしまいます。主軸ではなく、補助的な役割です。
第2層:コマンド実行前のガード(主軸)
AI がコマンドやツールを実行しようとする直前に毎回割り込みます。ここが対策の主軸です。
ブロック対象の例を挙げます。
curl ... | bash/wget ... | bash(ダウンロード即実行)rm -rf //rm -rf ~(ルートやホームの削除)security find-generic-password -w(macOS Keychain から秘密情報を取り出す).envファイルや~/.aws/credentials、~/.ssh/id_*へのアクセス- MCP(AI エージェントがツールを呼び出すための通信プロトコル)ツールの書き込み・破壊系操作(
delete,drop,truncateなど) - 未知の外部ホストへの MCP アクセス
第3層:ツール出力のスキャン
AI が外部データ(Web ページ・MCP レスポンス・Bash の出力)を受け取った直後に割り込みます。
「読む」こと自体はすでに起きているため、外部データを受け取った時点での即時停止には限界があります。今回の設計では PostToolUse 単体に依存せず、危険フラグを立てて次の PreToolUse で確実に止める方針にしました。
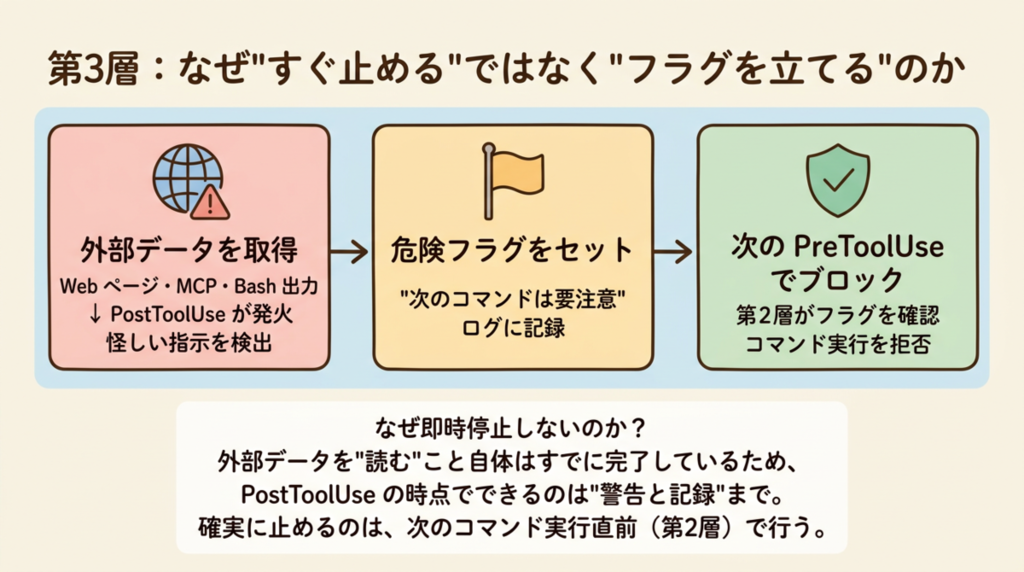
各層が動くタイミング
「3 層」という表現は縦に積み重なるイメージを持たれがちですが、実際は3種類のチェックポイントが異なるタイミングで動くという意味です。
| フック | いつ動くか | 何をするか | 動作 |
|---|---|---|---|
| 第 1 層 UserPromptSubmit | 人間が送信した瞬間 | 乗っ取り指示チェック | ブロック or 警告 |
| 第 2 層 PreToolUse | ツール実行の直前(毎回) | 危険なコマンド・URL をブロック | ブロック |
| 第 3 層 PostToolUse | ツール実行の直後 | 外部コンテンツをスキャン | 警告+フラグ(次の PreToolUse でブロック) |
第 2 層はツール実行のたびに毎回通過します。第 3 層でフラグが立った後も、次のコマンド実行で再び第 2 層を通るため、ここが防御の最終ラインです。
日常作業への影響を最小化する設計
日常的な開発作業(ファイルの編集・検索・許可済みツールの実行)は原則として含めていません。危険な操作だけをピンポイントで防ぐ設計です。
検知結果はログで確認できる
フックが何かを検知・ブロックした場合、ログファイルに記録されます。
2026-03-01T10:00:00 [BLOCK] [UserPromptSubmit] jailbreak 試行 2026-03-01T10:01:00 [WARN] [PostToolUse] 指示の上書き試行
後から「何が止まったか」「何が警告になったか」を確認できるため、audit モード(ログ記録のみ)での運用開始時や誤検知の調整に役立ちます。
実装の骨格
スクリプトの構造は、大きく 3 つの部分で成り立っています。
イベントのディスパッチ
import json, sys def main(): raw = sys.stdin.read() data = json.loads(raw) event = data.get("hook_event_name", "") dispatch = { "UserPromptSubmit": handle_user_prompt_submit, "PreToolUse": handle_pre_tool_use, "PostToolUse": handle_post_tool_use, # Cursor イベント名も同じハンドラに向ける "beforeSubmitPrompt": handle_user_prompt_submit, "beforeShellExecution": handle_pre_tool_use, "afterShellExecution": handle_post_tool_use, } handler = dispatch.get(event) if handler: handler(data) sys.exit(0)
PreToolUse のブロック例
ツール実行を止める場合は permissionDecision: "deny" を返します。
def handle_pre_tool_use(data: dict) -> None: command = data.get("tool_input", {}).get("command", "") for pattern, reason in BASH_DANGER_PATTERNS: if re.search(pattern, command, re.IGNORECASE): print(json.dumps({ "hookSpecificOutput": { "hookEventName": "PreToolUse", "permissionDecision": "deny", "permissionDecisionReason": reason, } })) sys.exit(0)
パターン配列の定義
検出ルールは定数配列で管理します。追加・削除がしやすく、ロジックと分離できます。
BASH_DANGER_PATTERNS = [
(r"curl\s+.+\|\s*bash", "ダウンロード即実行"),
(r"wget\s+.+\|\s*bash", "ダウンロード即実行"),
(r"rm\s+-rf\s+[/~]", "ルート・ホーム削除"),
(r"gh\s+auth\s+token", "トークン取得"),
(r"security\s+find-generic-password\s+-w", "Keychain 秘密情報取り出し"),
(r"terraform\s+(destroy|apply)", "インフラ操作"),
# ...
]
SENSITIVE_FILE_ACCESS_PATTERNS = [
(r"\.env\b", "機密ファイルアクセス"),
(r"~/\.aws/credentials", "AWS認証情報アクセス"),
(r"~/\.ssh/id_", "SSH秘密鍵アクセス"),
# ...
]
チェックは raw とサニタイズ済みの両方に対して行います。どちらかに一致すればブロックします。
sanitized = _sanitize_bash_command_for_scan(command) for pattern, reason in BASH_DANGER_PATTERNS: if re.search(pattern, command, re.IGNORECASE) \ or re.search(pattern, sanitized, re.IGNORECASE): block(data, "PreToolUse", reason)
チームへの展開
チームへの導入を簡単にするため、リポジトリを pull して setup.sh を実行するだけで、スキルとフックが同時にデプロイされる仕組みにしました。
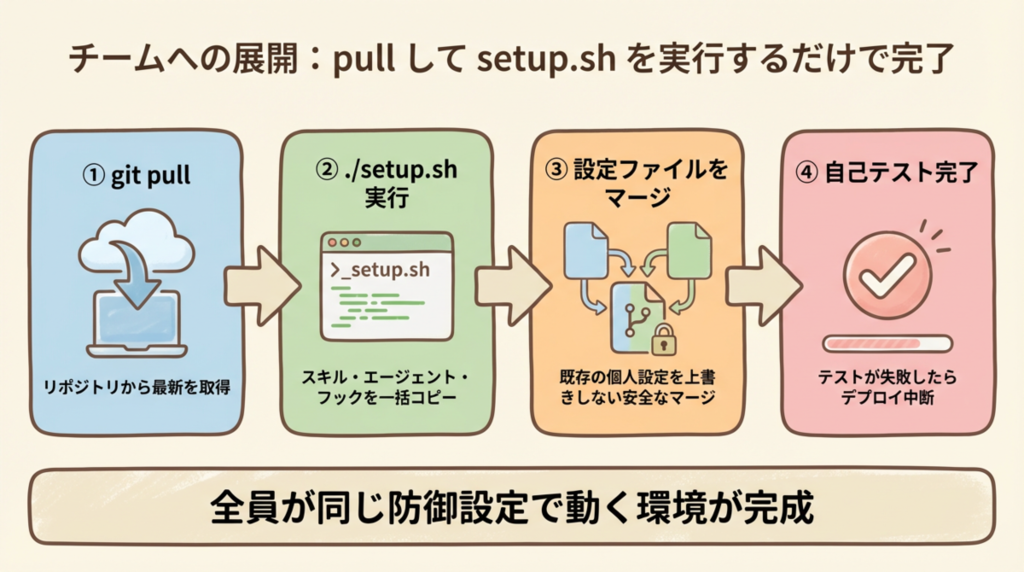
設定ファイル(settings.json / hooks.json)は上書きではなく jq でマージするため、個人設定を消さずにフックだけ追加できます。デプロイ完了前には自己テストが自動実行されており、回帰テストが通らなければその時点でセットアップを中断します。Cursor の重要なフックには "failClosed": true も設定しており、スクリプト自体が異常終了してもブロック状態を維持します。
展開後の変化
フックを入れても、業務上で目に見える変化はほとんどありません。実際に攻撃されない限り何も起きないからです。
そこで、プロンプトインジェクションとは何かをチームに実感してもらうため、簡単な実演を行いました。Google ドキュメントに白文字(不可視テキスト)で特定のディレクトリを削除するコマンドを仕込み、AI エージェントに URL を渡して手順に従って対応させました。
- フック導入前:削除コマンドがそのまま実行された
- フック導入後:即座にブロックされた
「外部ドキュメントを読んだ AI が指示を勝手に実行する」という挙動を実際に見せることで、チーム内での危機感の醸成につながりました。
Cursor でモデルを選べる場合、最新の推論モデル(Claude 4.6 など)は怪しい指示に自ら気づくことがあります。ただし軽量モデルではすり抜けることが多い印象です。モデルを変えた瞬間に防御が崩れる設計は、運用上のリスクになります。
設計で意識した4つの考え方
実装を通じて意識的に判断したポイントをまとめます。
1. 「主軸」を決め、他は補助と割り切る
「全部を完璧に防ぐ」という完全防御の設計は、現実的ではありません。第 2 層(実行前ガード)を主軸に据え、第 1 層と第 3 層はそれを補う補助と位置づけました。
主軸に集中することで、防御の抜け漏れを減らしやすくなります。Claude Code のフックは LLM の応答を待たずに実行を制御できる「主要な防御境界」です。冒頭で述べたとおり、LLM に気をつけるよう指示するのではなく、LLM の外側で止める。その境界として機能するのが第 2 層であり、そこに集中するのが合理的だと判断しました。
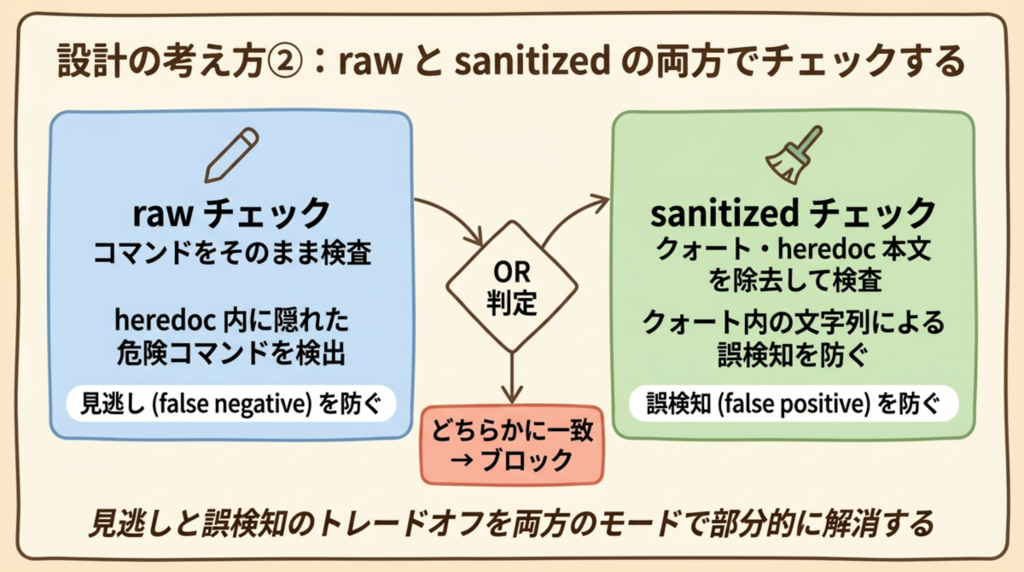
2. raw と sanitized の両方でチェックする
コマンドのパターン検査では、受け取ったコマンドをそのまま検査する(raw)だけでなく、クォートや heredoc 内のテキストを除去したうえでも検査する(sanitized)設計にしました。どちらかに一致すればブロックします(OR 判定)。
クォート内に危険パターンが含まれているケース(例:git log --format="..." のクォート部分)では、sanitized 側でその内容が除去されるため誤検知を防げます。一方で heredoc 内に危険コマンドが隠れている場合、raw 側でそのまま検出できます。
「見逃し(false negative)を防ぐ」と「誤検知(false positive)を防ぐ」はトレードオフです。両方のモードでチェックすることで、このトレードオフを部分的に解消しています。
3. fail-closed の原則
JSON 解析に失敗した場合など、フックが正常に判断できない状況では「ブロックする」設計にしました(fail-closed)。
fail-open(エラー時は通す)にすると、フックが壊れたときにセキュリティが無効化されます。業務が止まるリスクよりも、攻撃を通してしまうリスクの方が大きいと判断しました。
4. block / warn / audit の段階的モード
「最初からフル稼働」はリスクがあります。既存の業務フローを壊す可能性があります。そこで動作モードを 3 段階で設計しました。
audit— ログに記録するだけ。何も止めない。正常系の確認に使うwarn— 警告を出すが止めない。誤検知の確認に使うblock— 検出したらブロックする。本番運用モード
運用開始時は audit から始め、ログを見ながら徐々に強化します。この「段階的な本番投入」の設計が、チームへの導入コストを下げました。
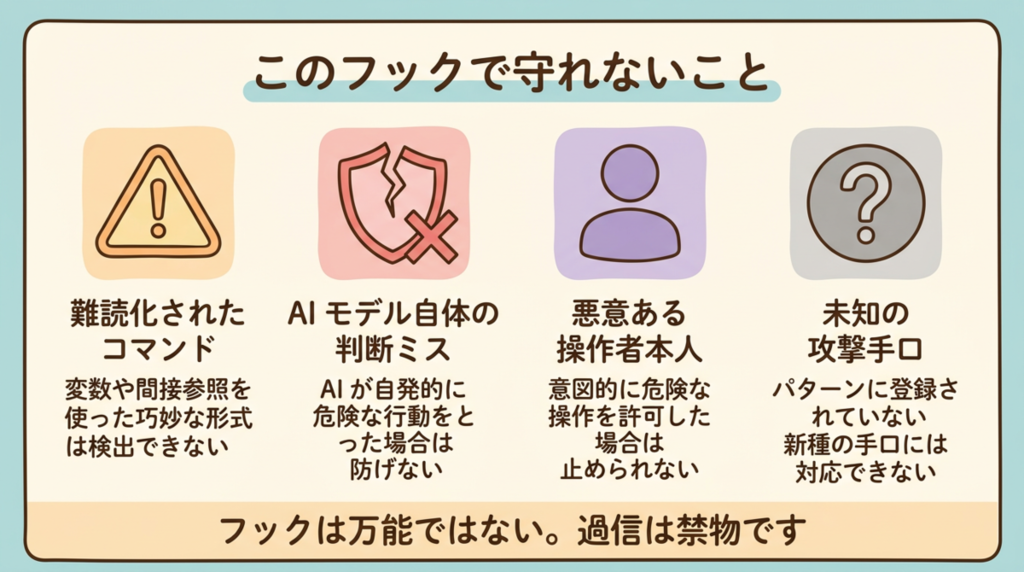
防御を入れて終わりではない
フックを入れたから安全、ではありません。パターンにない新しい手口は通りますし、モデル側の挙動や外部ツール側の仕様差もあります。
重要なのは、防御をコード化したうえで、ログを見て誤検知と見逃しを調整し、audit → warn → block と段階的に強化していくことです。
今回入れたのは、AI エージェント運用における最小限で実用的な防御です。これだけで安全が保証されるわけではなく、ログ監視・ルール更新・権限制御・運用改善とあわせて育てていく前提です。
安全性は「一度入れた対策の数」ではなく、運用の中でどれだけ更新し続けられるかで決まります。
まとめ
AI エージェントを使った業務自動化を安全に進めるために、プロンプトインジェクション対策フックを設計した話でした。設計の要点をまとめます。
- 3 層構造(入力検査・実行前ガード・出力スキャン)で介入タイミングを分ける
- 第 2 層(実行前ガード)を主軸に据え、他は補助と割り切る
- raw と sanitized の両方でチェックし、見逃しと誤検知の両方を抑える
- fail-closed の原則で、フック異常時もセキュリティが崩れないようにする
- audit → warn → block の段階的モードで、運用リスクを抑えながら導入する
- 守れない範囲を明示し、複数の防御手段の 1 つとして過信しない
AI エージェントを業務に組み込んでいるチームが増えている今、こうした対策の設計思想が少しでも参考になれば幸いです。
