こんにちは、キャディで Quote というアプリケーションを開発している plant こと石田 (@plant_ja) です。
Claude Code はあくまでツールであって、使い方によって大きくパフォーマンスが左右されるように感じています。
今回はコンテキストという観点から Claude Code の動作原理を紐解きながら、我々が期待するコードを安定して出力してもらうためのコンテキストマネジメントの理論と実践について思いを馳せてみようと思います。
想定読者
- Claude Code を日々使っているが、AI があまり賢くないように感じる人
- Claude Code を使い始めたばかりの人
- 日々の開発で Plan Mode を活用しているが「なんで Plan Mode だとうまくいくんだろう」って思っている人
- チームメンバーにコンテキストマネジメントの重要性を説明したい人
この記事のゴールと意図
ゴールは、読んでくれているあなたの Claude Code の使い方に少しでも変容を起こすことです。出来るだけ設定が不要で、シュッと実務で使えるということを重要視した構成になっています。
この記事は本のように長いわけではないですが、理論→実践 という章立てになっています。
Claude Code ないし、AIエージェントの進化は凄まじいスピードなので、新機能が出てきた時に自身で良し悪しや使い所をちゃんと評価できるようになるためには、理論を押さえておくことが重要だと考えています。
理論パートはちょっと退屈に感じるかもしれませんが、Claude Code の気持ちを理解するパートとして読んでもらえると嬉しいです。
理論
コンテキストって何?
よく「コンテキストエンジニアリング」って聞きますよね。まずはコンテキストについての理解を深めていきましょう。
Claude Code は下記のような情報を全てコンテキストとして保持しています。
| 要素 | 説明 |
|---|---|
| 会話履歴 | ユーザーとのやり取りすべて |
| 利用できるツール群 | 利用できるスキルやサブエージェント、MCP の概要 |
| ツール呼び出し結果 | ファイル読み込み・コマンド実行の出力 |
| システムプロンプト | Claude Code の役割を明記しているプロンプト こういうやつ |
LLM には「コンテキストウィンドウ」と呼ばれる処理できるトークン数の上限があります。
この記事を書いている段階での最新モデルである Sonnet 4.6, Opus 4.6 のコンテキストウィンドウは 200,000 トークンです。(尚、β版として 1,000,000 トークンバージョンも提供されています)
LLM の根幹として Self-Attention という機構があります。これは、入力として受け取ったトークン群(= コンテキスト)の中のトークン同士の関連性を計算するもので、この仕組みがあるからこそ Claude Code (ないし LLM) は、多少曖昧な指示でも文脈を踏まえてレスポンスを返してくれています。
ここで重要なのは、LLM にはモダンなプログラミング言語のようなガベージコレクションが存在しないことです。つまり、話題が切り替わった時に「不要になった」と判断してコンテキストを空けることができないのです。
前述の Self-Attention の仕組みは、トークン量を n とした時に計算量が O(n^2) で増加するため、コンテキストが大きくなるとレスポンスも遅くなります。しかし、それ以上に重要なのは品質面への影響です。トークンが増えるほど各トークンへの注意(attention)が分散し、本当に重要な情報を正しく参照する精度が下がっていきます。
このような性質から、コンテキストウィンドウ内のトークン量が増えるにつれ、モデルのパフォーマンスは劣化していく傾向があります。また、推論が必要なタスクについては、その傾向がより顕著になるとされています。さらに、関連しそうだけど間違っている情報に影響を受けやすくなるという報告もあります。
上記は Context Rot というタイトルが付けられたレポート (2025/07) の結果に基づいたものです。Opus 4 や Sonnet 4 での実験結果になっていますが、Opus 4.6 や Sonnet 4.6 も Transformer アーキテクチャなので、多少劣化しにくいとはいえ同じ性質を持つと考えられます。
LLM は毎回同じ結果を返すわけではないので「パフォーマンスが劣化する」というのは、「人間が与えたタスクを成功する確率が下がっていく」と解釈することができます。成功する時もあるけど、成功確率としては下がっていくということです。
尚、一般的な用語ではないのですが、一部の界隈で目安としてコンテキストウィンドウの ~40% までを Smart zone、それ以降を Dumb zone と呼んでいて、わかりやすくて僕は好きです。以降の説明でも使います。
AIエージェントを使った開発は確率と常に隣り合わせです。
AIエージェントの犯した過ちを「AI の性能がもっと良くなれば解決する」と考えるのではなく、「こういう状況下でも過ちを犯すのか」と自分の感覚値にフィードバックした上で、どのようなアプローチでその確率値を変えていけるかということを考えることが大事だと思っています。
Claude Code でのコーディングにおけるコンテキストの重要性
この性質を基に Claude Code でのコーディングを考えてみましょう。
Claude Code の “コーディング能力” を ドキュメントや調査結果から得られた「求められているコードの書き方」に沿ってコードを書く能力 と定義づけたとして、次のことが言えそうです。
- 一回のセッションが長くなるほど、コーディング能力が落ちていく可能性がある
- かつ、一回のセッションの中に複数種別の指示があると、それがより顕著になる
- 参照するドキュメントを増やしても、必ずしもコーディング能力が上がるとは限らない
- むしろ、タスクに関係ないドキュメントの読み込みは、コンテキストウィンドウを圧迫するのでコーディング能力を下げることに繋がる
また、コーディング能力だけでなく、決められたルールに沿って開発を進める能力も同様に劣化していく傾向があります。
このような劣化は Opus のような推論能力の高いモデルだと相対的に起きにくいので、「Sonnet は変なコードを書くけど、Opus はちゃんとしたコードを書く!」という感覚につながるのだと思います。
では、この性質を基に理想的な Claude Code の使い方を考えてみるとどうなるでしょうか?
- 1つのセッションでは1つのタスクに集中させることで、モデルの性能が発揮しやすい ~40% (Smart zone) のコンテキストでタスクを終わらせる
- もしくは1つのタスクを小さくする
- タスク遂行に最小限必要な情報 ”だけ” を与える
- 指示を明確にすることで、できるだけ推論しないで作業できるようにしてパフォーマンスの劣化を受けにくくする
「Plan Mode を使う」というのが1つのプラクティスになっているのは、特に意識せずに使っても上記のポイントを押さえやすくなるからだと考えています。
Plan Mode 無しでの開発プロセスだと、色々な調査を行った上で実装に入ったり、途中で Claude に軌道修正させたりすることになるので、Smart zone 内で実装を完了させることが難しくなります。(トークン量はざっくりとしたイメージです)
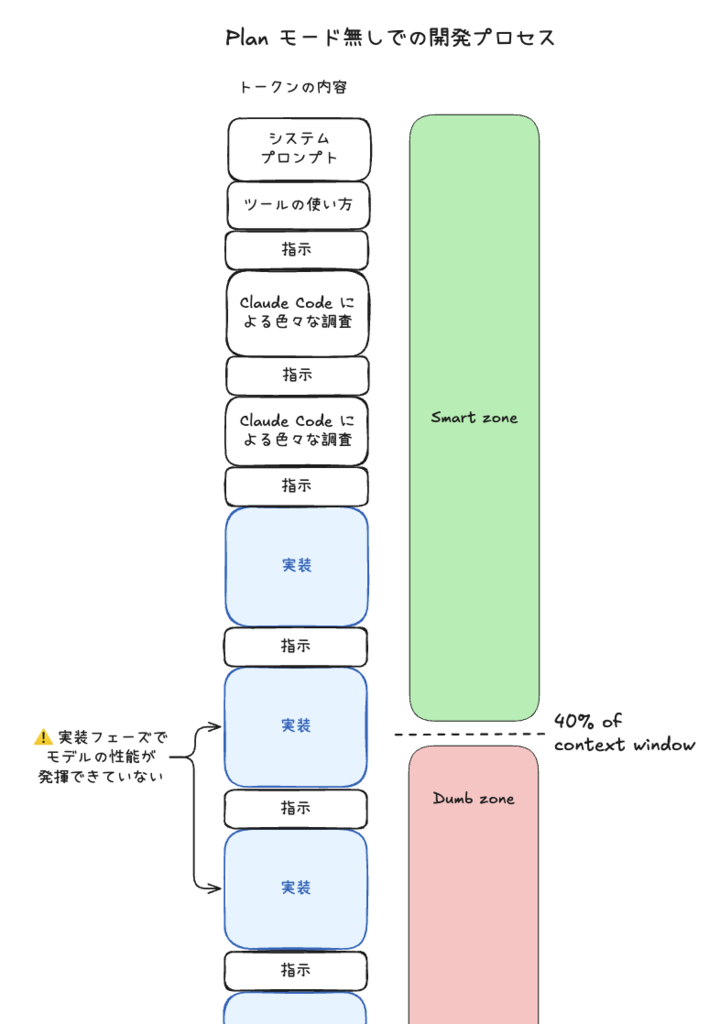
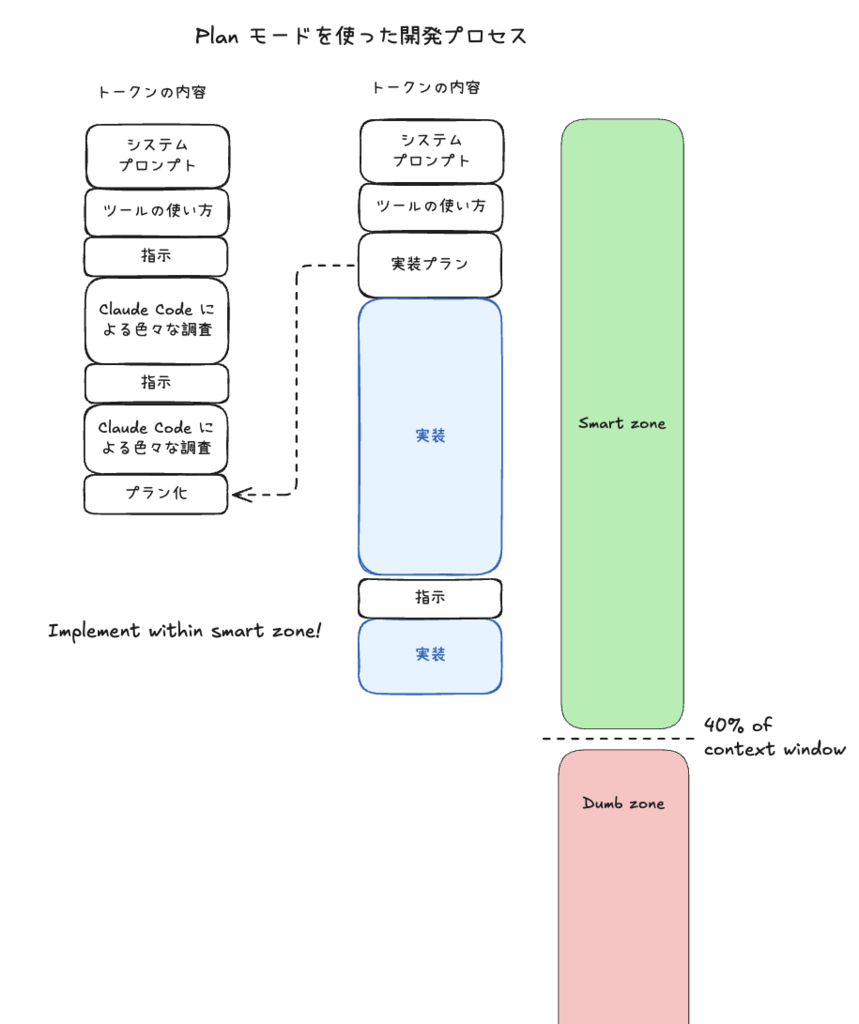
しかし、Plan Mode を使うと、実装プランを立てるセッションと実装するセッションを分けることができます。新しい綺麗なコンテキストウィンドウで、具体的な実装計画を基に実装することでモデルの一番性能の良い部分を実装フェーズに充てることができるようになります。
独立したコンテキストウィンドウを持つサブエージェントを活用することも、タスクの細分化ないし Smart zone の活用と考えることができますね。
例えば、ちょっと前のバージョンから、Claude Code が調査を行う時に自動的に下記のように Explore サブエージェントが調査を行うようになりました。
⏺ Explore(XXX の調査) ⎿ Done (24 tool uses · 48.2k tokens · 1m 29s)
これは、コードベースの調査というトークンを消費するタスクを別のコンテキストウィンドウに押し込むことによって、「調査の結果」だけをメインのセッションで得ることができて、性能劣化を回避しつつ後続のタスクを実施できるんだな、と理解することができるわけです。
参考
少し前の記事ですが、もう少し掘り下げて知りたい人は下記の記事がおすすめです。
Effective context engineering for AI agents \ Anthropic
実践
さて、やっと実践パートです。ここからは Claude Code などのツールの変化によって変わりやすい部分ではありますが、2026/03 時点でのプラクティスとして記載しておきます。
ここでは「すぐに実務で使える」ことを優先するために、設定などが不要な TIPS を紹介します。使い慣れている人にとっては当たり前のことしか書いていないかもしれないですが、ご了承ください。
TIPS 一覧
- Plan Mode を使おう
- Plan ファイルに進捗を記載しよう
- ステータスラインに現在のコンテキスト利用量を表示しよう
- 結果が気に入らなかったら、rewind で巻き戻して再度指示しよう
- /context で何にトークンを使っているかを見てみよう
- CLAUDE.md をスリムにしよう
- ファイルの指定方法を知ろう
- /insights コマンドで Claude Code に改善点を教えてもらおう
Plan Mode を使おう
Claude Code を立ち上げて、Shift+Tab を2回押すと Plan Mode になります。/plan でも動きます。あとは適当に指示をすると、Claude Code が自律的に影響範囲を調査したり、ユーザーに質問したりした上で実装計画を作成してくれます。
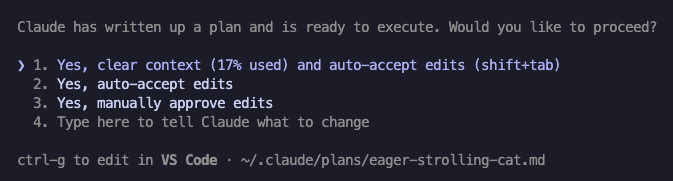
また、clear context (N% used) and auto-accept edits を実行すると、まっさらな綺麗なコンテキストで “必要最小限の” 実装計画に基づいて作業を進めてくれます。コンテキストの重要性を理解していると、これがどれほど有効かが実感できるかと思います。また、コンテキストをクリアしない 2. の auto-accept edits が、性能劣化したモデルに実装を任せることになりかねないことにも気づけるのではないでしょうか。
Plan ファイルの出力先は設定で変えられたりするので、.gitignore の設定に追加してレポジトリ内に置いておいてアクセスしやすくするのもおすすめです。
Plan ファイルに進捗を記載しよう
Plan Mode を使っても実装量が減るわけではないので、まっさらな綺麗なコンテキストで実装を開始したとしてもコンテキストウィンドウの30~40%を超えてしまうことがあると思います。そんな時は、Plan Mode で生成した Plan ファイルに進捗を記載することで、コンテキストをクリアしつつ別コンテキストから作業を引き継げるようにしてみましょう。
下記のように指示すれば、Plan ファイルを更新してくれます。
❯ 実装のキリが良いタイミングで Plan ファイルの実装進捗を更新してください。Plan ファイルは `Bash(ls -t -1 ~/.claude/plans/*.md | head -n 1)` で取得できます。
(Claude Code 2.1.50 だと、Plan Mode で実装を開始しても該当の Plan ファイルの存在は認知していないような挙動だったため、ここでは path を明示的に指定しています)
Plan ファイルの更新が完了したら、別の Claude Code セッションを立ち上げて下記のように指示すると Plan ファイルを読み込んで続きから作業してくれます。
> Plan ファイルを読み込んで、作業計画と作業進捗を把握してください。`Bash(ls -t -1 ~/.claude/plans/*.md | head -n 1)` を実行して、一番直近の Plan ファイルを対象とすること。
こういった指示を毎回コピペするのが面倒になってきたら、Skills とかにちょろっと登録しておくと /resume-plan とか任意のコマンドとして呼び出せるようになります。それも Claude Code に 下記の指示を毎回打つのがめんどくさいので、Skills にして。(以下、コマンド) と指示すれば ok です。
作業の計画・進捗はエージェントや我々にとって重要な資産です。これを揮発しやすい “コンテキスト” という概念として管理するのは勿体無いと感じているため、外部ファイルに何かしらの形として書き出すのが 2026-03 時点での自分の好みです。compact 先として外部ファイルを指定できるようになれば問題ないのかもしれませんが。
尚、この記事とは少し趣旨が違うため詳細は省きますが、自分は日々の開発では Plan Mode を使わずに自前で定義したフォーマットで計画・進捗を管理しています。
ステータスラインに現在のコンテキスト利用量を表示しよう
~/.claude/settings.json に下記を追加することで、Claude Code を立ち上げている最中に常にコンテキスト利用量が見えるようになります。(jq がインストールされている必要があります)
"statusLine": {
"type": "command",
"command": "jq -r '(.model.display_name // \"Claude\") + \" | Context: \" + (.context_window.used_percentage // 0 | tostring) + \"% used\"'"
}
これで、ぱっと見でコンテキストウィンドウの何割を使っているかが分かるようになります。/statusline コマンドからも色々設定が行えるので、興味がある人は試してみてください。
結果が気に入らなかったら、rewind で巻き戻して再度指示しよう
指示をした時に、思う通りに Claude Code が動いてくれないことがあると思います。
そんな時は rewind という機能でやり取りを無かったことにして、再度指示を出しましょう。Esc を2回押下 (もしくは /rewind) すると、過去のやり取りが表示され、選択すると巻き戻しの選択肢が表示されます。
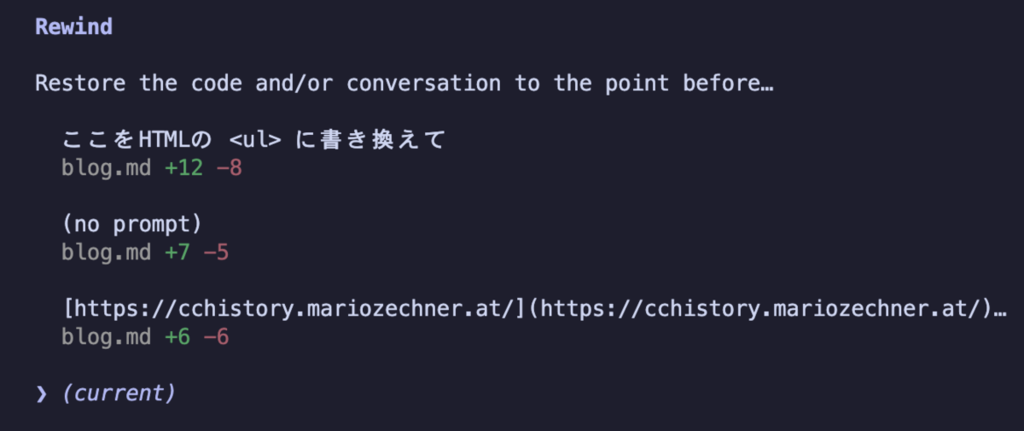

Restore conversation を実行すると、コンテキストウィンドウ内のトークンが巻き戻されます。修正指示を積み重ねると、モデルの性能が落ちてしまうので、クリーンな状態からやり直せるのは想像以上に便利です。Restore code を実行すると、コードの修正も巻き戻せます。
また、Summarize from here をすると、要約した情報だけを持ち帰ることもできる (参考) ので、色々活用してみてください。
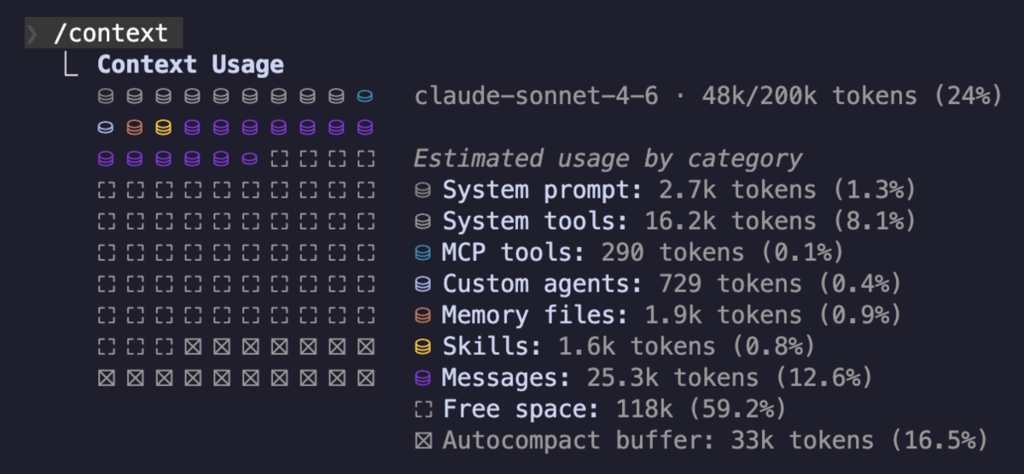
/context でトークンを何に使っているかを見てみよう
コンテキストウィンドウの使用量が見えるようになると、何にトークンを使っているのかが気になるようになってきます。そんな時は /context を実行すると、下図のように利用割合が分かります。MCP ツールなどは予想以上にトークンを使っていたりするので、そういったことに気づくことができます。
CLAUDE.md をスリムにしよう
CLAUDE.md は、あくまでインデックスとして扱いましょう。ありとあらゆるルールや実装方法を詰め込むと、コンテキストウィンドウの逼迫による性能劣化や、CLAUDE.md の内容が無視されるといった挙動につながることがあります。
輪郭と地図があれば、Claude Code はタスクの内容に応じて自律的にコードベースを探索することができます。(このような段階的な探索、情報収集は Progressive disclosure と呼ばれています)
参考: Writing a good CLAUDE.md | HumanLayer Blog 効果的なCLAUDE.mdの書き方
ファイルの指定方法を知ろう
Progressive disclosure 的な話の派生系としては、@を使ったファイル指定と、そうでないファイル指定などもうまく使い分けることをおすすめします。
| 観点 | @ あり | @ なし |
|---|---|---|
| ファイル読み込みタイミング | メッセージ送信時(即時) | Claude が判断して Read ツール実行 |
| 確実性 | 必ずコンテキストに含まれる | Claude が読まないこともある |
| コンテキスト消費 | 常にトークンを消費 | 必要な場合のみ |
| ユーザーの制御 | 明示的 | Claude に委ねる |
@ でのファイル指定は、指定したファイルが即座にコンテキストに展開されます。しかし、私はあまり使いません。Claude Code が自律的に見にいくことで、必要なタイミングで必要な情報を取りに行かせることができますし、メインセッションのコンテキストを消費せず、サブエージェントの中で参照してもらえば良いケースもあるからです。
/insights コマンドで Claude Code に改善点を教えてもらおう
/insights コマンドを打つと、過去のセッション情報に基づいて小綺麗なレポートが生成されます。面白いのでぜひ試してみてください。
終わりに
この記事では、コンテキストエンジニアリングについての理論と実践を紹介しました。今回はあくまで「コンテキストエンジニアリング」についての記事でしたが、これ以外にも Claude Code の活用方法は様々です。もし、これを読んで興味が湧いたら、Skills/Subagents/Rules/Hooks などのキーワードで色々と調べてみてください。
手前味噌ですが 図で考える AI コーディングの最適化 - CADDi Tech Blog にも概念チックなことを色々書いているので、もし興味があればそちらも読んでみていただけると嬉しいです。
また、キャディでは一緒に働く仲間を大募集中なので、興味があれば下記もぜひご覧ください。
リンク集
cchistory - Claude Code Version History
Context Rot: How Increasing Input Tokens Impacts LLM Performance | Chroma Research
Effective context engineering for AI agents \ Anthropic
Writing a good CLAUDE.md | HumanLayer Blog
効果的なCLAUDE.mdの書き方
図で考える AI コーディングの最適化 - CADDi Tech Blog
