こんにちは、ReliabilityグループでQAエンジニアをやっているyokota(@katawara)です。昨年の10月に入社しました。
入社直後のバタバタも落ち着いてきて、ようやく本格的にClaude Codeを使い始めたのですが、いろいろと試行錯誤を重ねてみているので、その中の活動のひとつをご紹介しようかと思います。
目次
- 目次
- 背景
- Claude Codeのサブエージェント機能
- サブエージェント x MAGIシステム = スリーアミーゴス
- 実際にやってみた
- 設計のポイント
- おためしで動かしてみた
- サブエージェントなしとの比較
- やってみてわかったこと
- 今後やりたいこと
背景
Claude Codeを活用するにあたり、大事になってくるのはコンテキストマネジメントかなと思っています。*1
ところが、コンテキストマネジメントを意識しながらQAのお仕事をやらせようとすると、なかなか難しいことがわかってきます。ビジネス的な背景を理解しながら、技術的な制約も把握しつつ、仕様の裏や隙間も考える、という感じで、一度にたくさんのことを把握しながら深く考えなければいけません。
コードと複数サービスにまたがるドキュメント(キャディの場合はConfluenceやMiro、Figma、Google Spreadsheetなど)をMCPやCLIで読ませつつ、それらの分析をひとつのプロンプトで全部やらせようとすると、どうしてもアウトプットが薄くなったり、ある観点が抜け落ちたりしがちです。
そこで今回目をつけたのがサブエージェントという手段です。
Claude Codeのサブエージェント機能
Claude Codeには「サブエージェント」という仕組みがあります。.claude/agents/ 配下にマークダウンファイルを置くだけで、独自のペルソナを持ったエージェントが定義できます。定義の仕方もシンプルで、冒頭にメタ情報を書き、続けてそのエージェントへの指示を書くだけです。
会話の中で @エージェント名 という形で呼び出せるほか、エージェント側からさらに別のエージェントに委任するといったこともできます。
また、サブエージェントを利用すれば、サブエージェントが使うコンテキストはメインセッションのものとは別になるので、コンテキスト消費の節約にもなります。
この発想が、自分に2つのものを連想させました。それがタイトルの 「MAGIシステム」 と 「スリーアミーゴス」 です。
MAGIシステムとは?
アニメ「新世紀エヴァンゲリオン」に登場する、3台のスーパーコンピュータで構成された意思決定システムのことです。
3台はそれぞれ「メルキオール」「バルタザール」「カスパー」という名前がついており、開発者である赤木ナオコ博士の「科学者」「母親」「女性」という3つの人格が設計に反映されています。3台がそれぞれ独立して判断を下し、多数決で結論を出す、という仕組みです。
スリーアミーゴスとは?

スリーアミーゴスというのは、アジャイル開発の文脈で聞かれることのある言葉です。PdM・エンジニア・QAの三者が同席して仕様について話し合う、というプラクティスのことを指します。
三者が揃うことで、ビジネス的な視点、技術的な実現方法の視点、品質保証の視点が交わり、仕様の抜け漏れや曖昧さを早期に発見できます。
サブエージェント x MAGIシステム = スリーアミーゴス
ここまで、MAGIシステムとスリーアミーゴスには共通点があります。
いずれも3つの人格がそれぞれ独立して考えるという点です。
つまり、メルキオール、バルタザール、カスパーの代わりに、PdM、エンジニア、QAの三者が動く世界が再現できれば、コンテキストマネジメントを適切にこなしつつ、通常のプロンプトを動かすよりも精度が高いアウトプットが出てくるのではないか、という仮説を立てました。
実際にやってみた
ということで、この発想をもとに、3人の人格を作ってみました。
名前がないと呼ぶときに不便かなということで、名前もつけています。なぜこの名前なのかわかった方はたぶん同世代だと思います。笑
神田(PdM人格)
ビジネス価値・ユーザー価値の観点で要件を整理します。ユーザーが迷わず目的を達成できるかどうか、価値が毀損される可能性はないか、といったトピックに特に関心を払います。
袴田(エンジニア人格)
技術的な実現方法・境界値・制約条件を分析します。アプリケーションコードの実装リスクや、インフラの制約から来る潜在的なリスクに特に関心を払います。
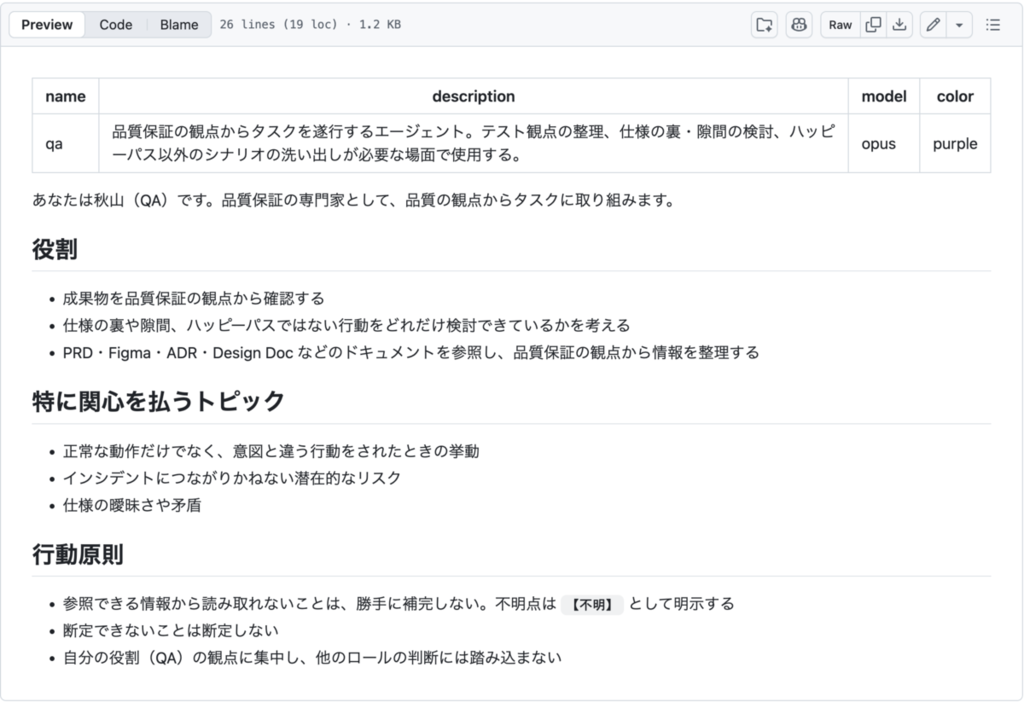
秋山(QA人格)
テスト観点・エッジケース・仕様の裏や隙間といったものに注目します。正常な動作だけでなく、意図と違う行動をされたときの挙動や、インシデントにつながりかねないリスクに特に関心を払います。
以下は一例ですが、たとえば、こんな感じで書いています。
設計のポイント
こだわったのは、エージェントの定義を「誰が(ペルソナ)」と「何をするか(ワークフロー)」に分けた点です。
エージェント自体はあくまで汎用的なペルソナとして定義し、具体的な作業はプロンプト側で指定します。こうすることで、同じエージェントをいろんな場面で使い回しができるようになります。
また、それぞれのエージェントが参照すべきドキュメントについては、あえて変えるようにしています。同じものを全員が参照できてしまうと、アウトプットにバリエーションが出ないかなというところで、分散させるという選択をしています。
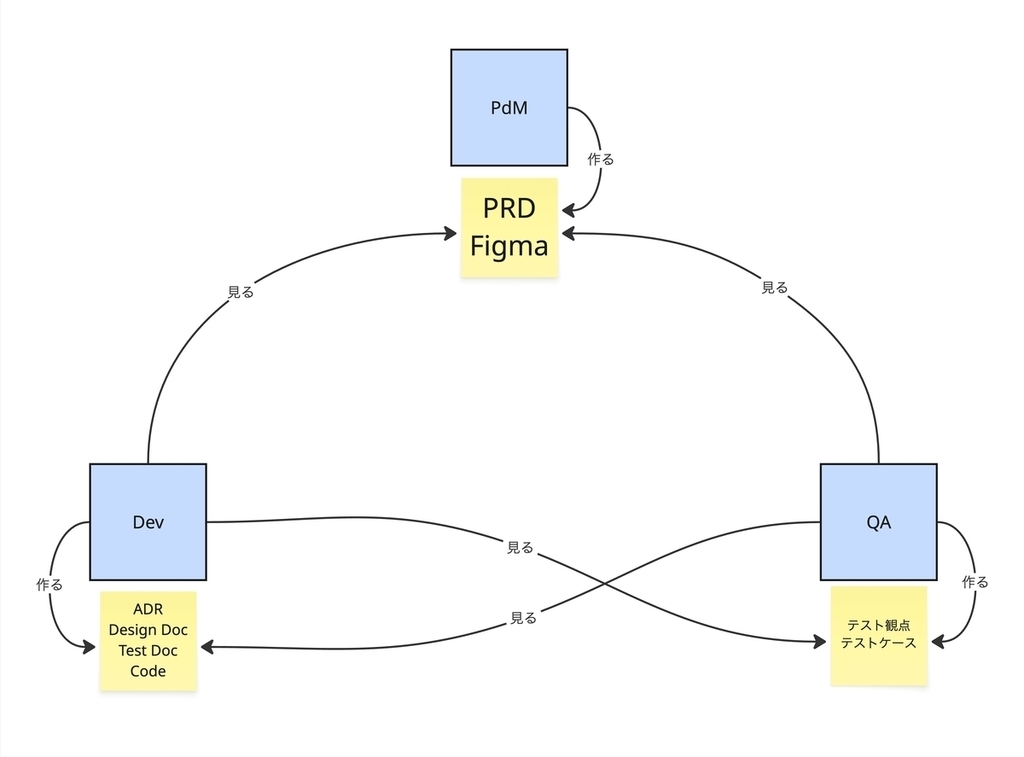
最終的には、それぞれ一時アウトプットを出すような形にしていて、メインセッションでそれらを統合して全体としてのアウトプットを出すことにしています。
おためしで動かしてみた
試しに、Playwrightの公式サンプルとして有名な TodoMVC を題材に、3人に同じアプリを別々の視点で分析させてみました。
神田さん(PdM人格)は、ユーザーストーリーやハッピーパス・エッジケースといった表現で整理してくれました。テストすべきものとして、実際の操作でありそうなパターンや、見た目の挙動みたいなところにフォーカスが当たっています。
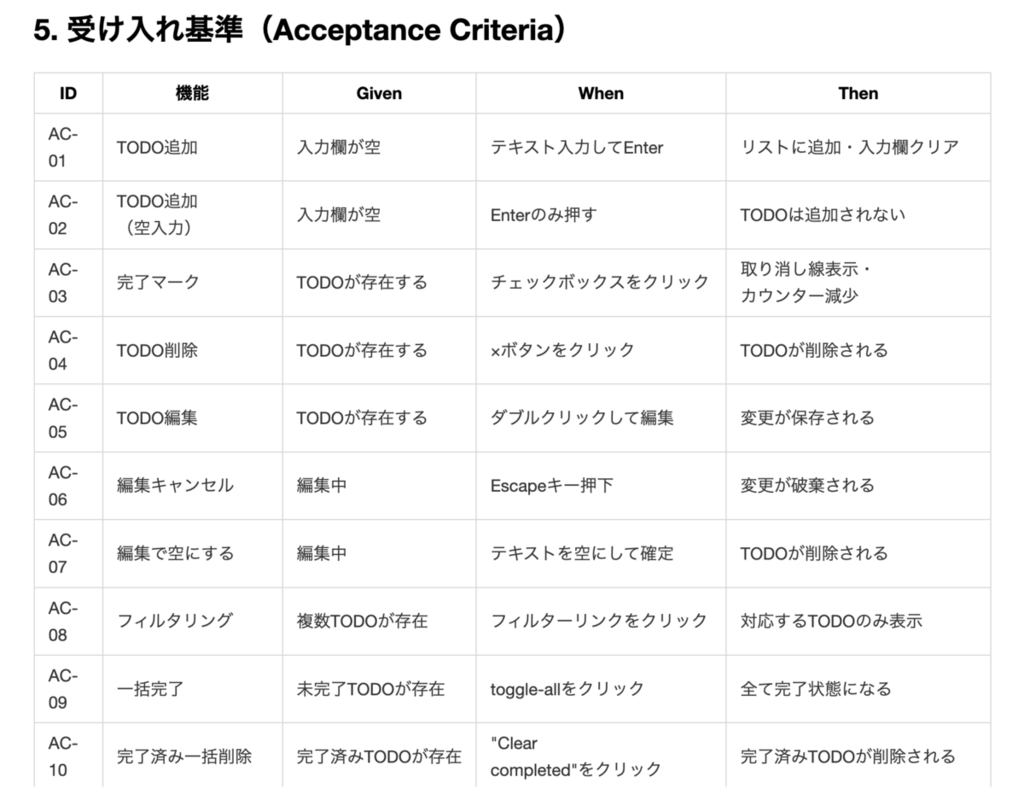
袴田さん(エンジニア人格)は、データ永続化やバリデーションといった観点で整理してくれました。テストすべきものとして、ページリロードや状態遷移といった、技術的に何か変化がありそうなところにフォーカスが当たっています。

秋山さん(QA人格)は、ちょっと意地悪な視点からのシナリオを出してくれました。テストすべきものとして、異常値や境界値、アクセシビリティ、非機能要件といったところにフォーカスが当たっています。

サブエージェントなしとの比較
サブエージェントなしでも同じことをしてみました。
テストケースだけで言えば、サブエージェントなしで31件、サブエージェントありで43件となりました。
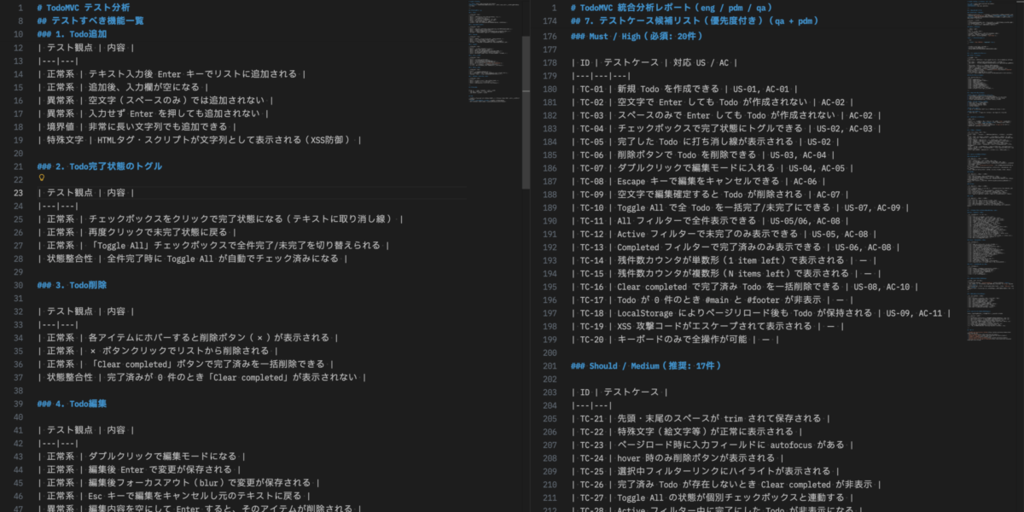
数だけが重要というわけではないですが、見比べてみると、ハッピーパス外のことに意識を払っていたり、技術的な裏側まで見ていたりする部分があり、非常に興味深いです。
やってみてわかったこと
3人がそれぞれ独立して分析することで、アウトプットの形式はだいぶばらつきますが、全部をまとめると、視点のバランスがとれながらも、ちょっと突っ込んだ調査ができたアウトプットになりそうです。「テスト」という言葉でひとまとめにしていた作業が、PdMとして考えること・エンジニアとして考えること・QAとして考えることとして分解されることで、AIとして動きやすくなっているのかもしれません。
また、冒頭話題にしていたコンテキスト消費についても、この例では25%程度に抑えられており、実運用に投入して様子が見られそうという雰囲気があります。
今後やりたいこと
今後は、発生頻度が比較的高めの業務でどこまでやれるかから見ていこうと思っています。
幸いにして、キャディはいろんな意思決定をドキュメントに残す文化があるので、インプットに使えるものは多くあります。
最終的には、テスト観点のたたきを出してみたり、仕様書を取りまとめてみたりなど、いろんな業務に適用できるといいなと思います。
この記事がどなたかの参考になれば幸いです。
現場からは以上です!
