はじめに
技術本部 Sansan Engineering Unit 名刺メーカー Dev グループで 1 ヶ月のインターンをしていた三富佑人です。*1
Sansan 名刺メーカーは、企業が社員の名刺を Web 上でデザイン・発注できるサービスです。バックエンドは Node.js(TypeScript)で実装されています。名刺のデザインや支給管理だけでなく、名刺を社員に支給するタイミングで名刺データを Sansan に連携する機能も備えています。
インターンでは新機能の開発ではなく、既存の非同期処理基盤の信頼性向上に取り組みました。4 月は多くの企業で新入社員の入社や人事異動が集中する時期です。入社にあわせて名刺を一括支給する企業が多いため、名刺メーカーではこの時期にリクエストが急増する傾向があります。この繁忙期にも耐えられるよう、アーキテクチャを見直す必要がありました。
具体的なテーマは、名刺連携機能の流量制限です。名刺メーカーでは名刺を一括支給すると、その支給をトリガーとして Sansan への連携処理が非同期で走ります。大量の名刺を一括支給したときに連携処理が集中してしまうため、Sansan API のレート制限に対して安全に処理を流せるよう設計を見直す、というのが取り組みの方向性でした。
非同期処理の基盤をどう改善するかについては、すでに ADR(Architecture Decision Record)で方針が整理されていました。今回のインターンでは、その ADR をもとに実際の移行 PR を作成するところから担当しています。移行を進める中でステージング環境で想定外のエラーが発生し、ADR の方針をさらに発展させた設計の見直しを行い、技術選定・調査・実装・リリース計画を一貫して担当しました。この記事では、名刺連携機能の概要に触れたうえで、そのエラーをきっかけにファンアウト(1 つのイベントから複数のタスクを一斉に生成する処理)の設計を見直した経緯を中心に紹介します。
名刺連携機能の概要と、もともと起きていた問題
Sansan への名刺連携は、単純な「1 API リクエストを投げて終わり」の処理ではありません。一括支給をトリガーに連携ジョブが開始され、Start(開始)→ Reserve(各名刺ごとの連携予約)→ Check(完了確認)という 3 段階のイベントがPub/Subを介して非同期に連なっていく、イベント駆動のワークフローになっています。
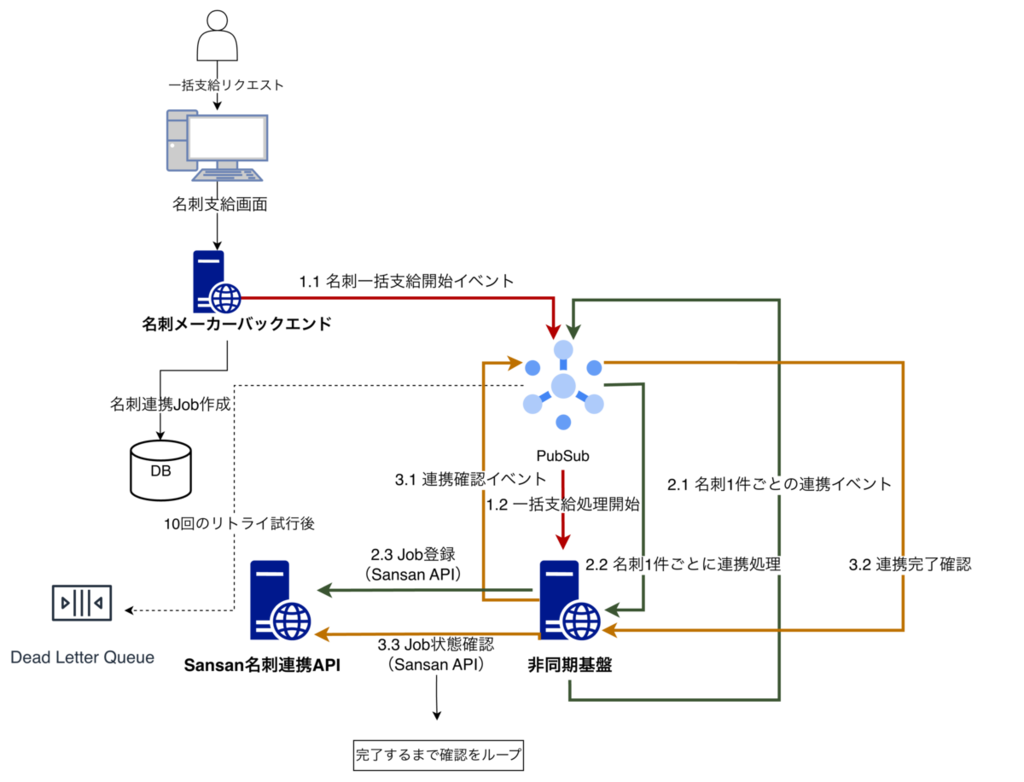
この設計自体は、ジョブ全体を細かいステップに分けられるため自然なものでした。一方で、運用上は「どの段階でどれだけ処理を流すか」を制御する必要があります。特に Reserve ステップは Sansan API への外部呼び出しを含むため、大量の支給をトリガーとして連携処理が一斉に走る場合、リクエスト速度の制御が重要になります。
そこで当時の ADR では、Pub/Sub ベースの実行から Cloud Tasks ベースの実行へ移す方針が整理されていました。Cloud Tasks を使えばキュー側で配信レートと同時実行数を明示的に制御でき、Sansan API のレート制限に合わせてリクエスト量を抑えられると考えました。
この方針に沿って、インフラ・アプリケーション双方で Cloud Tasks への移行を進めました。
名刺支給ジョブの開始はすばやく受け付けつつ、その先の実処理はキューに流し、連携 API 側の制約に合わせてゆっくり消化する、という役割分担です。
ただし、この段階で主に検討していたのは「キューがどれくらいの速度で実行するか」でした。そのひとつ手前の「キューにどうやって大量のタスクを積むか」という観点については、十分に検討できていませんでした。ステージング環境での障害は、この部分に起因するものでした。
ステージング環境で起きた想定外のエラー
Cloud Tasks への移行後、ステージング環境で最大 3,000 件の名刺一括連携をテストしたところ、別の問題が発生しました。
Start ハンドラが Reserve 用のタスクを大量に作成するタイミングで、次のエラーが出ました。
Error: 8 RESOURCE_EXHAUSTED: Bandwidth exhausted or memory limit exceeded createTask is failed. queueId: integration-sansan-bizcard-supply code: 8 note: 'Exception occurred in retry method that was not classified as transient'
このエラーが問題だったのは、単発で失敗して終わるのではなく、リトライによって被害が拡大する構造になっていた点です。
Cloud Tasks のタスク作成 API は内部で gRPC を使っていますが、このエラー(ステータスコード 8: RESOURCE_EXHAUSTED)はクライアントライブラリが自動リトライ対象としていないステータスコードでした。そのため、例外がそのまま上位に伝播して Start ハンドラ全体が失敗しました。
すると Cloud Tasks は「Start タスク自体が失敗した」と判断し、Startタスクを再試行します。再実行されるとその中でまた大量のタスク作成リクエストが走ります。結果として、失敗した 1 回の処理が丸ごと再実行され続け、ステージング環境では約 9 回のリトライでタスク作成の試行数が累計約 30,000 件に達し、処理時間も約 9 倍に膨れ上がりました。
この時点で、「Cloud Tasks に移したのに、Cloud Tasks 自体への投入で詰まる」という問題の構造が見えてきました。
ファンアウトの設計を見直した流れ
原因の調査にあたり、まず Start ハンドラの実装を確認しました。ここでは対象の名刺 N 件に対して Promise.all で全件同時にタスク作成 API を呼び出していました。
await Promise.all( jobItems.map(async (jobItem) => { await cloudTasks.createTask({ ... }); }), );
キュー側に配信レートと同時実行数の制限を設定しているため、流量制限は効いているように見えます。実際、キューから実行先へ配信されるタスク自体はその制限の中で処理されます。
しかし、ここで効いているのはあくまで「キューから実行先に配信する段階」の制限です。今回詰まっていたのは、その前段階の「Cloud Tasks API にタスクを登録する段階」でした。
Cloud Tasks のタスク作成 API は、内部的には 1 回の呼び出しが 1 つの gRPC リクエスト、すなわち 1 本の HTTP/2 ストリームに対応します。N 件を Promise.all で投げると、N 本のストリームを同時に開こうとします。gRPC(HTTP/2)の同時ストリーム数にはデフォルトで約 100 本という上限があり、また Node.js はシングルスレッドであるため、3,000 件のタスク作成がすべて同一の TCP コネクション上で同時に開かれようとします。RESOURCE_EXHAUSTED が出たのは、この同時ストリーム数が上限を大幅に超えたためだと考えられます。
根本原因は「同時に開く gRPC ストリーム数が多すぎること」です。ここから、ファンアウトの方式そのものを見直すことにしました。
検討した選択肢
チャンク分割やプロセス内の並列数制御など、アプリケーションコード側で対処する方法も検討しました。それぞれ短期的には有効ですが、複数ハンドラが同時に走るケースやリードタイムへの影響を考えると根本解決にはなりません。
選択肢を並べて比較した結果、「キューの実行制御」と「ファンアウト時の投入制御」は別の問題であり、後者はアプリケーションコードではなくインフラ側で解決すべきだと判断しました。
Pub/Sub × BufferTask にした理由
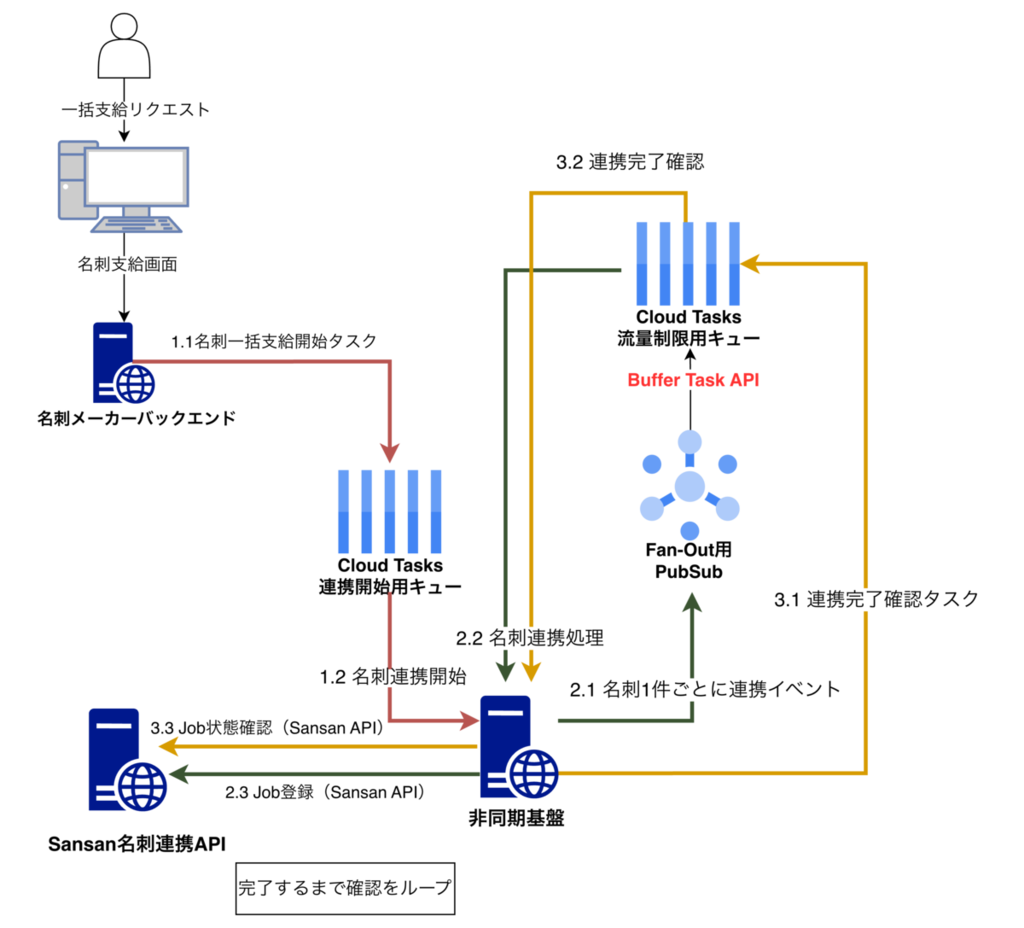
最終的に、ファンアウト部分だけを Pub/Sub × BufferTask × Cloud Tasks のハイブリッド構成にする方針を選びました。
まず BufferTask API について説明します。BufferTask は Cloud Tasks が提供する HTTP エンドポイントで、呼び出し元が通常の HTTP リクエストを送るだけで、Cloud Tasks 側がそのリクエストを HTTP タスクにラップしてキューに投入してくれる仕組みです(公式ドキュメント)。gRPC のタスク作成 API を直接呼ぶ必要がなくなるため、クライアント側の gRPC ストリーム管理から解放されます。
この構成の流れは次のとおりです。
- Startタスク は従来どおり起動する
- ただし Start の中でタスク作成 API を N 回呼ぶことはしない
- N 件のメッセージを Pub/Sub に publish する
- Pub/Sub push subscription の配信先を Cloud Tasks の BufferTask API にする
- BufferTask 経由で、実際の処理キューにタスクが積まれる
この構成を選んだ理由は、大きく 3 つあります。
1. Pub/Sub はファンアウト時の gRPC ストリーム数を大幅に抑えられる
Pub/Sub の Node.js クライアント SDK は、publish 時に内部でメッセージをバッチ化します。デフォルトでは 100 件単位でまとめて 1 つの gRPC ストリームに乗せるため、N=3,000 でも必要な gRPC ストリーム数はおよそ 30 本で済みます。
一方、Cloud Tasks のタスク作成 API を 3,000 回呼ぶと、そのまま 3,000 本のストリームが同時に開かれます。
今回の問題は「実行先の流量制限」だけではなく、「ファンアウト時にどれだけ細かい RPC を発行するか」にもありました。Pub/Sub のバッチ化によってこの問題を解消できることが、この構成を選んだ最も大きな理由です。
2. BufferTask は HTTP REST なので、gRPC ストリーム問題を回避できる
Cloud Tasks への投入方法を gRPC のタスク作成 API から Pub/Sub push → BufferTask API に変えることで、アプリケーションが大量の gRPC ストリームを一気に開く構造から抜けられます。
また、BufferTask 側が 429 を返した場合には Pub/Sub の自動バックオフ・リトライが働くため、流量制御の責務をプラットフォーム側に寄せることができます。アプリケーション側で細かいリミッターを作り込む必要がなくなります。
3. 実行側のレート制限は引き続き Cloud Tasks に任せられる
今回 Cloud Tasks を完全に置き換えたわけではありません。ファンアウトの通信路だけを Pub/Sub に戻し、その先の実処理は引き続き Cloud Tasks のキューで制御しています。
つまり、
- ファンアウト時のバーストは Pub/Subで吸収する
- 実際の API 呼び出しレート制御は Cloud Tasks に任せる
という役割分担です。それぞれの得意な部分を使い分ける構成になっています。
本番リリースで考慮したこと
ステージング環境で構成を検証したあとも、本番環境への移行では追加の考慮が必要でした。
特に慎重に扱ったのは、旧 Pub/Sub subscription の削除タイミングです。新しいファンアウト用の subscription を先に作成し、旧 subscription と並走させる形を取りましたが、この並走期間をどこで終わらせるかが問題でした。すぐ削除するとメッセージの取りこぼしが起こりうる一方で、並走を続けると二重処理のリスクが出ます。旧 subscription の未配送メッセージがゼロになったことを確認してから削除する、という二段階の手順を取ることで、安全に切り替えました。
おわりに
今回、1 ヶ月のインターン期間において、名刺連携機能の流量制限に関する技術選定・設計・実装・リリース計画を一貫して担当しました。Cloud Tasks に移行したあとに RESOURCE_EXHAUSTED が発生したことで、キューのレート制限だけでなく、ファンアウト時の投入経路まで含めた設計の見直しが必要になりました。この問題を自ら調査・提案し、最終的に Pub/Sub × BufferTask × Cloud Tasks のハイブリッド構成を採用しました。
インターンを通じて学んだことは多くありますが、特に印象に残っているのは以下の点です。
- 複数の手法を比較するときは、「動くか」だけでなくトレードオフまで含めて考える必要がある
- 変更はローカルで動くだけでは不十分で、安全にリリースできて初めて完了と言える
- ADR や設計レビューは、結論を残すためだけでなく、なぜその判断をしたかを共有するためにある
設計判断からリリース計画まで一貫して関わることができ、充実した 1 ヶ月間でした。
Sansan技術本部ではカジュアル面談を実施しています

Sansan技術本部では中途の方向けにカジュアル面談を実施しています。Sansan技術本部での働き方、仕事の魅力について、現役エンジニアの視点からお話しします。「実際に働く人の話を直接聞きたい」「どんな人が働いているのかを事前に知っておきたい」とお考えの方は、ぜひエントリーをご検討ください。
*1:本記事は、執筆者本人の了承を得て、代理で投稿しています。
