Sansan株式会社 研究開発部Architect GroupでMLOps/Platformエンジニアをしている伊藤です。
今回は、GENIACに採択され、AWS上にSlurmによるGPUクラスタを構築した経験から、事前に知っておきたかったポイントをまとめます。構築中に遭遇した課題と、そのときの判断を具体的に書いているので、これからGENIACへの応募を検討している事業者やGENIACに採択された事業者の方が「ここは先に設計しておこう」と見積もれる材料になれば幸いです。
目次
GENIAC とは
GENIAC(Generative AI Accelerator Challenge)は、経済産業省とNEDO(国立研究開発法人新エネルギー・産業技術総合開発機構)が実施する、国内の生成AIの開発力強化を目的としたプロジェクトです。
GENIACでは、主に生成AIのコア技術である基盤モデルの開発に対する計算資源の提供や、データやAIの利活用に向けた実証調査の支援などが行われます。計算資源の提供については、採択事業者は自らGPUリソースを調達し、その費用の一部について補助を受けてAIモデルの開発します。
私たちは「視覚接地した文書特化型視覚言語基盤モデルの構築」というテーマで採択され(プレスリリース)、インフラ担当1名・MLエンジニア4名の体制でAWS ParallelCluster(Slurm)によるGPUクラスタを構築しました。
技術選定: なぜスケジューラを使い、なぜ Slurm を選んだか
まず、スケジューラを使わないという選択肢もありました。しかしODCR(On-Demand Capacity Reservation)によりGPUインスタンスのキャパシティが事前に確保されており、利用の有無にかかわらず課金が発生するため、夜間も休日もできるだけGPUをアイドル状態にしたくありません。これは事前学習フェーズだけでなく、fine-tuningのような短時間ジョブのフェーズでも同様です。4名のMLエンジニアが非同期にジョブを投入し、空いたGPUから順に処理される仕組みが必要だったため、スケジューラの採用は必須と判断しました。
スケジューラの選定はSlurmとKubernetesの二択でした。Slurmを選んだ理由は次の4点です。
- MLエンジニアの多くが大学や研究機関でSlurm(やそれに準ずるJobスケジューラ)を使った経験があり、srunで対話的にGPUを確保できるUXも含めて学習コストが低い
- Kubernetesは思想上Podを使い捨て可能な単位として扱うため、数日〜数週間走る事前学習のような長時間ジョブではEviction対策などの追加設計が必要になる
- 組織でK8sでのJob管理はしておらず、初期構築の負担がSlurmの方が低い
- プロジェクトが期間限定であり、組織としてSlurmが採用されていなくても属人化や採用面の負荷などの長期的な負債にならない
以上の判断のもと、普段はEKSをフルに活用して推論基盤を運用していますが、このプロジェクトではSlurmをあえて採用しました。Slurmクラスタの構築にはAWS ParallelClusterを利用しています。SageMaker HyperPodのような追加料金がなく、手軽にAWS上でSlurmクラスタを構築できるのが採用理由です。
構築タイムライン
当初インフラ1人で1週間の見積もりでしたが、結果として3週間かかりました。
| 週 | 期間 | 作業内容 |
|---|---|---|
| 1週目 | 8/5〜 | Terraformセットアップ、VPC/IAM設計、クロスアカウントアクセス(SSM)、ParallelCluster基盤構築 |
| 2週目 | 8/12〜 | カスタムAMIビルド、マルチユーザー設定、cgroupsによるGPU分離の試行錯誤→断念、GPUリソース配分の再設計 |
| 3週目 | 8/20〜 | ユーザーへの環境提供開始、監視ダッシュボード構築、GPUメトリクス収集、SIEM連携、アラート設定 |
「クラスタを立てる」だけなら1週間で終わります。しかし、マルチユーザー運用・監視・セキュリティまで含めると倍以上かかりました。この記事では、その過程で遭遇した課題と判断を共有します。
全体アーキテクチャ

構成の概要は次の通りです。
| 項目 | 値 |
|---|---|
| HeadNode | m6i.2xlarge (8 vCPU, 32 GiB) |
| ComputeNode | p5.48xlarge (NVIDIA H100 x8, 80GB HBM3 each) |
| OS | Ubuntu 24.04 |
| Scheduler | Slurm |
| ネットワーク | EFA 有効、PlacementGroup 有効 |
| GPU キャパシティ | ODCR(GENIAC 経由で自動設定) |
| ストレージ | EBS + NFS export1、S3、GCS |
| IaC | Terraform |
全ノードはPrivate Subnetに配置し、SSM Session Manager経由でアクセスする構成としました。
クラスタ構築編
GPU ヘルスチェックによる srun の遅延
クラスタを立てて最初にsrunを実行したとき、ジョブがなかなか開始されませんでした。コマンドを打ってから実際にノードに入れるまで、約5分の遅延が発生していました。
原因はParallelClusterがデフォルトで有効にしているGPUヘルスチェックです。ParallelClusterはDCGM(NVIDIA Data Center GPU Manager)によるLevel 2ヘルスチェックをジョブ開始前に実行します。このヘルスチェックはGPUのメモリ帯域やコンピュート性能をテストするもので、p5.48xlargeのようなH100 x8構成ではNVSwitch / NVLinkの接続検証に時間がかかります。
ドキュメントには「8GPUノードで3分以下」と記載されていますが、実際には約5分かかりました。AWSサポートに問い合わせたところ、P5のような複雑なGPUトポロジーではDCGMの診断プロセスが長期化するという既知の問題であるとの回答でした。ParallelClusterのGitHub Wikiにも記載されています。
ノードの規模が小規模だったためヘルスチェックは不要と判断し、無効化しました。
ComputeResources: - Name: p5-compute InstanceType: p5.48xlarge HealthChecks: Gpu: Enabled: false
数十〜数百ノードの大規模クラスタではGPU故障検知の観点から別の判断になりうるため、構成に応じて検討してください。
別AWSアカウントが払い出される前提での設計
本プロジェクトでは、クラスメソッド株式会社から別のAWSアカウントが払い出されて提供される形でした。リソース提供の約1週間前にアカウントが届き、その間に環境を準備する流れが基本となります。ODCRに関してはアカウント配布の時点で自動設定されており、特別な作業は不要です。
ここで重要なのは、このアカウントは自社のAWS Organizations管理アカウントからの払い出しではないという点です。そのため、IAM Identity Center(旧AWS SSO)は使えません。これはすべての採択事業者に共通する前提条件なので、アクセス経路の設計は事前に考えておく必要があります。
アカウントが届く前に、インフラ環境をTerraformやCloudFormationでコード化しておくのがおすすめです。アカウントIDが決まった瞬間にapplyできる状態にしておけば、限られた準備期間で速やかに立ち上げられますし、万が一の障害時にも環境を再構築できます。
自社セキュリティ基準への対応(私たちのケース)
以下は私たちが自社のセキュリティ基準に適合させるために追加で構築した内容です。GENIAC側からの要件ではないため、すべての採択事業者に同じ対応が求められるわけではありません。自社のセキュリティポリシーとの差分を事前に確認し、必要に応じて準備してください。
- アクセス経路としてクロスアカウントIAMロールとSSM Session Managerを組み合わせました。全ノードがPrivate Subnetにあるため、VPC Endpoints(SSM / SSM Messages / EC2 Messages)を経由してセッションを確立する構成です。
- 監視面ではOAM(Observability Access Manager)を使い、GENIACアカウント側のCloudWatchメトリクスを管理アカウントに共有することで、既存のダッシュボードに統合しました。
- セキュリティについてはGuardDuty / CloudTrail / VPC Flow Logsを有効化し、ログをS3に集約したうえで、S3レプリケーションで管理アカウント側のSIEMに連携しています。
マルチユーザー運用編
GPU の排他制御: cgroups 断念から Slurm gres へ
特にfine-tuningのフェーズでは、1つのノード内の複数のGPUを複数のMLエンジニアが共有するため、GPUの排他的な割り当てが必要でした。
最初のアプローチ: cgroups で完璧な分離を目指す
最初に試みたのは、cgroups v2 + デバイスコントローラーによるカーネルレベルのGPU分離でした。GRUBでcgroups v2を有効化し、GPUデバイスを検出してcgroupsデバイスコントローラーに登録し、それをsystemdサービスとして管理する構成です。Slurm側でもcgroup.confにConstrainDevices=yesなどを設定して、ジョブごとにGPUデバイスへのアクセスを制限しようとしました。
結果は失敗でした。ParallelClusterがSlurmのcgroups設定を独自に管理しており、ユーザースクリプトと競合したためです。
そこで方針を変え、自前のcgroups設定をすべて取り除き、ConstrainDevices=yesの追記だけに簡素化してみました。しかし今度はジョブ自体が走らなくなり、最終的にはスクリプトごと完全に削除しました。8/15に作り始めて8/18に全削除と、3日ほどの試行錯誤期間がありました。
現実解: Slurm の gres + 運用ルール
最終的に採用したのは、Slurmの--gres=gpu:NオプションによるCUDA_VISIBLE_DEVICESの自動設定と、GPU枚数に比例したCPU / メモリ配分の運用ルールです。
| GPU 枚数 | CPU | メモリ | エイリアス |
|---|---|---|---|
| 1 | 16 | 150G | gpu1 |
| 2 | 32 | 300G | gpu2 |
| 4 | 64 | 600G | gpu4 |
| 8 | 128 | 1200G | gpu8 |
ユーザーには次のようなカスタムエイリアスを提供し、対話的にGPUジョブを起動できるようにしました。
alias gpu1='srun --gres=gpu:1 --mem=150G --cpus-per-task=16 --pty bash' alias gpu2='srun --gres=gpu:2 --mem=300G --cpus-per-task=32 --pty bash' alias gpu4='srun --gres=gpu:4 --mem=600G --cpus-per-task=64 --pty bash' alias gpu8='srun --gres=gpu:8 --mem=1200G --cpus-per-task=128 --pty bash'
カーネルレベルの厳密な分離ではありませんが、SlurmがCUDA_VISIBLE_DEVICESを自動設定してくれるため、実用上は十分な排他制御が実現できました。プロジェクト初期にMLエンジニア側が誤ってCUDA_VISIBLE_DEVICESをジョブ側で設定してしまい、排他制御が機能しないことがありましたが、シングルテナントであればコミュニケーションで十分解決できるため、妥当な割り切りだと考えています。
ParallelCluster の Slurm 設定カスタマイズの壁
ParallelClusterはSlurmクラスタの構築を大幅に簡略化してくれますが、細かいカスタマイズが必要になると壁にぶつかります。
やりたかったこと
私たちのケースでは、計算ノード上でキャッシュプロキシを動かしています(キャッシュプロキシについては「GCS→S3キャッシュプロキシで大規模ML学習のデータ転送コストを削減した話」で紹介しています)。プロキシが使うCPU・メモリをSlurmの管理対象から除外できれば、ジョブスケジューラが「実際にジョブに使える量」を正確に把握でき、安心です。SlurmにはCpuSpecList / MemSpecLimitというまさにこの用途のパラメータがあるので、設定すれば済むはずと考えました。
なぜうまくいかなかったか
ParallelClusterではSlurmの設定をカスタマイズする手段が2つあります。
| 手段 | 概要 |
|---|---|
CustomSlurmSettings |
ノード定義行の末尾にパラメータを追記する(SlurmSettings / Queue / ComputeResource の3レベルで指定可能) |
CustomSlurmSettingsIncludeFile |
任意の設定ファイルをincludeで読み込む(SlurmSettingsレベルのみ) |
一見どちらかで書けそうですが、私たちのアプローチではどちらも期待通りに動きませんでした。
アプローチ1: CustomSlurmSettingsIncludeFile でNodeName行を丸ごと上書き
最初に試したのは、CustomSlurmSettingsIncludeFileで次のようなincludeファイルを読み込む方法です。
NodeName=gpu-queue-st-p5-compute-1 CPUs=176 CpuSpecList=0-15 DefCpuPerGPU=16 DefMemPerGPU=150000
DefCpuPerGPU / DefMemPerGPUなどのグローバル設定は問題なく反映されます。しかし、NodeNameの上書きはうまくいきませんでした。ParallelClusterがslurm_parallelcluster.confでノード定義を先に生成し、includeファイルはその後に読み込まれます。Slurmは同じノード名に対する最初の定義を優先するため、後からincludeされたNodeName行は無視されます。
アプローチ2: ComputeResource.CustomSlurmSettings で追記
次に、ComputeResourceレベルのCustomSlurmSettingsを使う方法を検討しました。こちらはParallelClusterが自動生成するNodeName行の末尾にパラメータを追記してくれるため、CpuSpecListの追加自体は可能です。
しかし、私たちはCpuSpecListと同時にCPU数の調整(192→176)も行いたいと考えていました。ここで問題になるのが、ComputeResourceレベルのdeny list(slurm_settings_validator.py)です。
"ComputeResource": { "Global": ["cpus", "gres", "nodeaddr", "nodehostname", "nodename", "state", "weight"], },
cpusがdeny listに含まれているため、ComputeResourceレベルのCustomSlurmSettingsではCPU数を変更できません。CpuSpecListとCPU数調整をセットで行えないことが分かり、このアプローチも断念しました。
結論
最終的には、p5.48xlargeは192 vCPU・2 TiBメモリと十分に余裕があるため、プロキシ程度のリソース消費であれば実用上問題にならないと判断し、Slurm管理からの除外は諦めてそのまま運用しました。なお、記事公開に当たり改めて調査したところ、CpuSpecList単体であればdeny listに該当せず、ComputeResourceレベルのCustomSlurmSettingsで設定可能だった可能性があります(詳細は脚注2を参照)。
ParallelClusterのSlurm設定カスタマイズは、ドキュメントだけでは「何が書けて、何が実際に反映されるか」を判断しづらい部分があります。deny listの内容や排他制約のスコープなど、細かい挙動はParallelClusterのソースコードを読むのが確実なので、カスタマイズ前に一度目を通しておくのがおすすめです。
監視編
GPU 利用率の収集パイプライン
プロジェクト期間中は計算リソースの適正な利用を確認するため、プロジェクトのKPIとともにGPUの利用率を報告する必要がありました。
運営側からW&B(Weights & Biases)の利用が案内されるのですが、私たちのケースでは自社のセキュリティ基準上W&Bを利用できなかったため、自前で構築しました。
本来はDCGM(NVIDIA Data Center GPU Manager)による詳細なモニタリングを行い、PCIe/NVLinkの帯域利用率など分散学習のボトルネック分析に使えるメトリクスを収集したいところでした。しかし、有期プロジェクトかつ比較的小規模な学習だったため、そこまでの投資は不要と判断しました。結果として、HeadNodeからsrun経由で計算ノード上のnvidia-smiを実行し、CloudWatchに送信するシンプルな構成を採用しています。当初は計算ノード上のSystemd Timerから直接実行する構成を試みましたが、nvidia-smiのPATHが通らない・IAM認証が失敗するといった問題が発生しました。インフラ担当1名の体制で、監視の仕組みよりもクラスタの機能整備を優先すべきフェーズだったため、原因の深追いはせずHeadNodeからsrun経由で収集するworkaroundを採用しました。srun経由であればSlurmが環境変数を適切に引き継いでくれるため、PATHの問題を回避できます3。
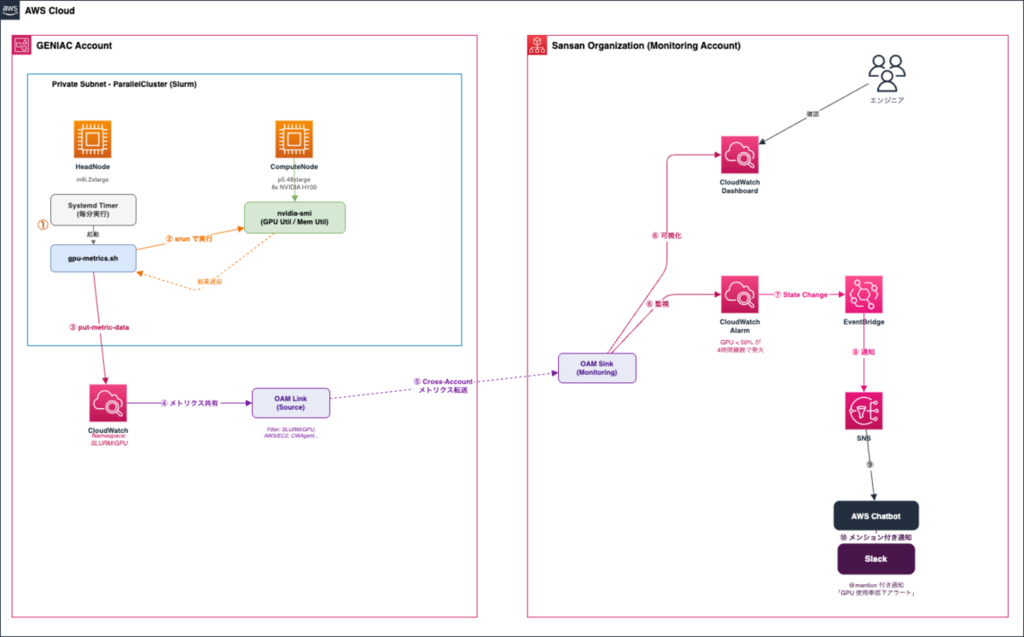
具体的には、Systemd Timerで1分ごとに次のスクリプトを実行しています。
SLURM_OUTPUT=$(srun --mem=1G --time=00:01:00 --job-name=gpu-metrics bash -c '
GPU_UTIL=$(nvidia-smi --query-gpu=utilization.gpu --format=csv,noheader,nounits | \
awk "{sum+=\$1; count++} END {if(count>0) print sum/count; else print 0}")
MEM_UTIL=$(nvidia-smi --query-gpu=memory.used,memory.total --format=csv,noheader,nounits | \
awk -F", " "{used+=\$1; total+=\$2} END {if(total>0) print (used/total)*100; else print 0}")
echo "GPU_UTIL:$GPU_UTIL"
echo "MEM_UTIL:$MEM_UTIL"
' 2>&1)
収集した値はCloudWatchカスタムメトリクス(Namespace: SLURM/GPU)に送信しています。GENIACアカウントのコンソールに都度アクセスするのは自社のセキュリティ基準上難しかったため、OAM(Observability Access Manager)を使って管理アカウント側のCloudWatch Dashboardにメトリクスを統合し、普段使っている環境から確認できるようにしました。
さらに、GPUが十分に活用されていない状態を早期に検知するため、CloudWatch Alarmも設定しました。GPU利用率が一定期間低い状態が続くと、SNS経由でSlackにメンション付きの通知が飛ぶ仕組みです。ここでも1つハマりポイントがあり、カスタムメトリクスに対するアラートは通常のAlarm形式ではうまく動作せず、Terraformでmetric_query形式に書き直す必要がありました。
まとめ
GENIACにおける機械学習インフラの構築で押さえておくべきポイントを振り返ります。
- ヘルスチェック設定: 大型GPUインスタンスを使う場合は最初に確認する。デフォルトのままだとジョブ開始に数分の遅延が発生する
- インフラのコード化: TerraformやCloudFormationで事前にコード化しておき、アカウントIDが決まった瞬間にapplyできる状態にしておく
- GPUの排他制御: cgroupsを自前で制御しようとせず、Slurmのgres機能と運用ルールに委ねるのが現実解
- Slurm設定のカスタマイズ: ParallelCluster経由だとドキュメントだけでは制約を把握しきれないことがある。細かいカスタマイズが必要な場合はソースコードにも目を通しておくのがおすすめ
- GPU利用率の監視: 報告への対応だけでなくGPUの無駄遣い防止にも役立つので、早めに構築しておく。W&Bが利用可能であればそちらが手軽
振り返り: 次回やるなら
次に同様のプロジェクトがあれば、EKSを選ぶことを検討しています。Slurmは研究者にとって馴染みのあるUXを低い学習コストで提供できましたが、マルチテナントやセキュリティの要件に対応しようとするとcgroupsやOSレベルの設定で頑張ることになります。Kubernetesであれば、Namespaceによるテナント分離、RBAC、Pod Security Standardsなど、他のプロジェクトでも再利用可能なポータブルなスキルセットで同じ課題に対応できます。組織として標準外のスキルスタックに投資するよりも、すでに蓄積のあるKubernetesエコシステムに乗せる方が長期的には合理的だと感じました。
Sansan技術本部ではカジュアル面談を実施しています

Sansan技術本部では中途の方向けにカジュアル面談を実施しています。Sansan技術本部での働き方、仕事の魅力について、現役エンジニアの視点からお話しします。「実際に働く人の話を直接聞きたい」「どんな人が働いているのかを事前に知っておきたい」とお考えの方は、ぜひエントリーをご検討ください。
- HeadNodeにアタッチしたEBSボリュームをNFSで計算ノードに共有する構成でParallelClusterを利用する場合に自動で設定されます。FSx for Lustreは数十ノード以上の規模で共有ストレージに高スループットが求められる場合に有効ですが、今回の規模では過剰と判断しました。↩
-
記事公開に当たりParallelClusterのソースコードを改めて調査したところ、
CPUsを明示的に減らす必要はなかった可能性があります。Slurmの仕様上、CpuSpecListを設定すると指定したCPUは自動的にジョブ割り当て対象から除外されるため、CPUs=192のままCpuSpecList=0-15を追記すればSlurmは176 CPUをジョブに割り当て可能と認識します。CpuSpecListだけであればdeny listに該当せず、ComputeResourceレベルのCustomSlurmSettingsで設定可能でした。また、CustomSlurmSettingsとCustomSlurmSettingsIncludeFileの排他制約はSlurmSettingsレベル同士にのみ適用されるため、SlurmSettingsレベルとComputeResourceレベルのCustomSlurmSettingsは併用可能です。↩ -
問題の本質は、ParallelClusterのbootstrapスクリプト(
user_data.sh)で設定されるPATHやプロキシ設定がsystemdサービスのコンテキストには引き継がれない点にあったと考えています。計算ノード上のsystemdサービスからnvidia-smiやAWS CLIを呼ぶにはPATHを明示的に設定する必要があります。↩
