この記事は、Sansan Data Intelligence 開発Unit ブログリレーの記念すべき第1弾です!!

こんにちは、技術本部 Data Intelligence Engineering Unitの江川です。
前回の記事でお伝えしたとおり、Sansan Data Intelligenceのブログリレーを開始します!
Vol.01となる本記事では、Sansan Data Intelligenceのプロダクト立ち上げにおけるアーキテクチャの概要と技術選定についてご紹介したいと思います。
目次
Sansan Data Intelligenceが解決する課題
Sansan Data Intelligenceに関する概要は、前回の記事でご紹介しましたので、そちらをご覧ください。
多くの企業では、SFA/CRMや基幹システムに蓄積された取引先データの品質に課題を抱えています。
- 表記揺れやデータの抜け漏れ、重複データの存在
- 企業情報の陳腐化(合併・移転・統合等への追従など)
- システム間でのデータ不一致・不整合
Sansan Data Intelligenceでは、Sansanが保有する独自の企業データベースと連携し、これらの課題を解決しています。
アーキテクチャ全体像
システムコンテキスト
C4モデルのSystem Context図を用いて、Sansan Data Intelligence(以下SDI)を取り巻くシステム全体像を俯瞰します。
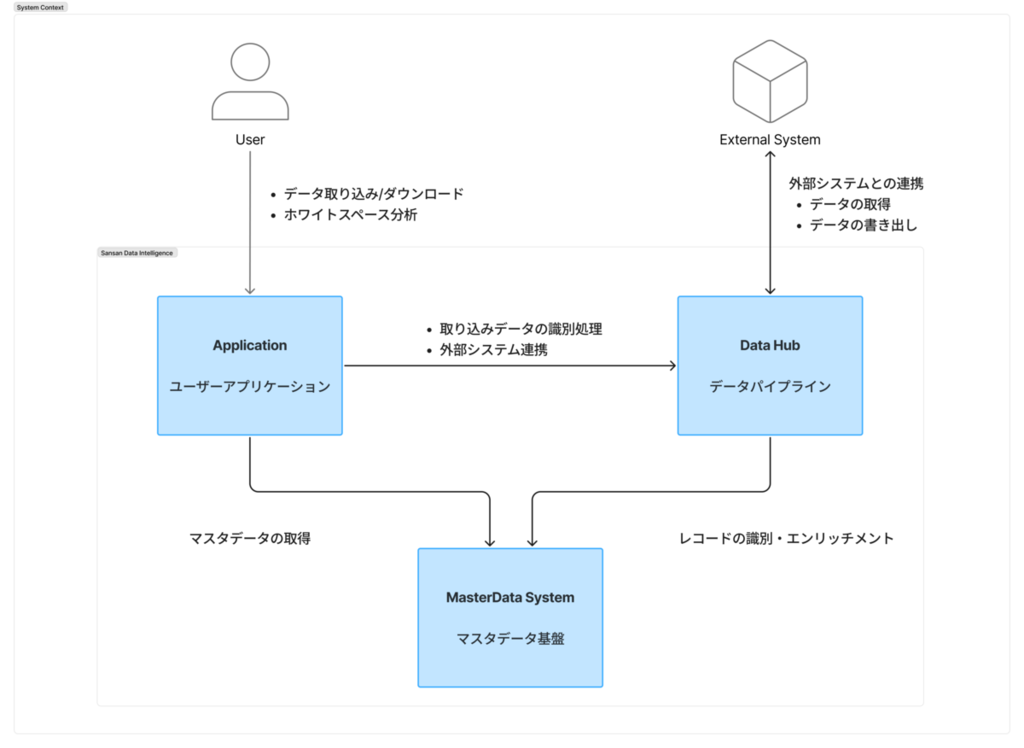
SDIは大きく Application、Data Hub、MasterData Systemの3つのシステムで構成されています。
- Application: ユーザー向けのユースケースを提供するフロントエンド+バックエンドマイクロサービス
- Data Hub: データの識別・統合処理を行うデータパイプライン
- MasterData System: 組織と組織間の関係性を表す時系列グラフモデルによるマスタデータ基盤
Application → Data Hub
Applicationは、データの識別・統合処理をデータパイプラインであるData Hubに委譲します。
- 識別処理の実行: ユーザーが取り込んだレコードに対して、企業の名寄せ・識別を実行
- 外部システムとの連携: SFA/CRMや基幹システムとのデータ連携を仲介
Application / Data Hub → MasterData System
MasterData Systemでは、Sansan独自の企業データベースにおいて、企業を一意に識別するために付与されるID「SOC(Sansan Organization Code)」を用いることで、表記の揺らぎや情報の重複を解消し、システムを横断してデータを一元管理することが可能になっています。ApplicationやData Hubでは、こうしたマスタデータを用いることで、データの識別・統合処理を行います。
- マスタデータの取得: 800万件以上の企業・拠点データや、時系列のグラフモデルによる組織間の関係性データ、合併・移転・社名変更といった組織変遷の履歴を取得
- レコードの識別: ユーザーデータの識別(マスタデータとのマッチング)の実施
Data Hubとの統合
SDIの開発において大きな設計判断の一つが、Data Hubとの統合でした。
当初 ApplicationのバックエンドとData Hubを完全に別のコードベースとしてシステム間連携を行うという案もありましたが、最終的に「SDIのバックエンドの一部としてData Hubを捉える」という結論に至りました。 この決定の背景は、明日ブログリレーのVol.02として公開予定の横山の記事でご紹介します。
これにより、データ統合に関わる処理はData Hub側が担い、Applicationはユーザー向けのユースケースに集中できる構成となりました。
技術選定の判断軸
SDIではSimple, Stupid, Secureという原則を掲げています。 過度な先読み設計を避け、シンプルに保つことを重視し、セキュリティは設計の最初から組み込む。こうした原則がSDIの開発における判断軸になっています。
また、技術選定などの意思決定プロセスにおいては、DBやアーキテクチャなど後戻りが困難な決定(One-Way Door)には慎重な検討を、内部実装の詳細など変更可能な決定(Two-Way Door)には素早い決定を心がけています。
主要な技術選定
Backend: Go
バックエンドにはGoを採用しました。
SDIが連携するData HubやSOC v2も同様にGoで実装されており、チーム間でのコードレビューやライブラリ共有、人材の流動性等を考慮して統一の判断を行っています。 また、SDIではデータパイプラインにおいて大量のレコードを並行処理する場面が多く、goroutineによる軽量な並行処理との相性が良いと考えています。
Frontend: Next.js (App Router) + TypeScript
フロントエンドにはNext.js (App Router)を採用しました。 SDIでは、Next.jsをフロントエンドアプリケーション+BFFとして利用することとしています。
SDIのバックエンドはマイクロサービスで構成されており、複数のマイクロサービスからデータを集約して取得したいような場合でもReact Server Components (RSC)によりシンプルにコンポーネントに関連するデータフェッチロジックを実装できるというのが大きな理由です。
また、これらのマイクロサービスはGKE上に構成されており、Next.jsも同一クラスタに配置することでデータフェッチのレイテンシを削減することもできます1。
API: Connect
クライアントとサーバーサイド間のAPIにはConnectを採用しました。
大きな理由はProtobufによる開発体験です。Protobufのシンプルなスキーマ記述からGo/TypeScript双方のコードを自動生成でき、スキーマから型安全な開発ができます。 また、Webアプリケーションとしては、gRPC-webと異なりEnvoy等のプロキシが不要であり、シンプルな構成を保てるという点でSDIのスタックに合致していました2。
他にはOpenAPIやGraphQL等も検討しましたが、Protobufによる開発体験の良さ・Next.jsとの相性を考慮しConnectを採用しました。 また、バックエンドの一部であるData Hubではマイクロサービス間通信にConnectを採用しており、コード生成やテストの仕組みを揃えられるという点もポジティブでした。
DB: Cloud Spanner
データベースにはCloud Spannerを採用しています。 候補としてはAlloyDBやCloud SQLも挙がりましたが、以下の理由からSpannerを採用しています。
- 高い可用性と強整合性: SDIはマルチテナントSaaSであり、テナントにおける大規模な取引先データの取り込み/書き出しを高速に実施しています。Spannerはノード追加による水平スケーリングが可能でありながら、強整合性が保証されており、大規模なデータパイプラインにも適しています。
- メンテナンス性の良さ: Spannerではソフトウェアの更新やメンテナンスがある場合でも、ダウンタイムなくメンテナンスを行うことができます。
他にもData BoostによるBigQuery連携のサポート、全文検索のサポートなど、将来的なユースケースにも対応できるという点もポジティブでした。
Infra: GKE (Orbit)
インフラ基盤には、Sansan社内の共通コンテナ基盤であるOrbit3を採用しています。
Orbitは、GKE Autopilotをベースとしたアプリケーション開発プラットフォームです。 従来、各プロダクトごとに個別対応していたインフラやCI/CDパイプラインを共通化・標準化し、開発チームがプロダクトの価値向上に集中できる環境が提供されています。具体的にはアプリケーションテンプレート、Terraformによるインフラコード、ベストプラクティスが組み込まれたKubernetesマニフェストなどが標準で提供されており、アプリケーションの構築からデプロイフローの構築が容易になります。
また、プロダクトの認証機能には全社共通基盤であるAuth One4を利用することで、認証周りの実装を高速に行うことができました。
その他、インフラ周辺の技術スタックは以下のとおりです。
- Object Storage: Cloud Storage
- Messaging: Cloud Pub/Sub
- Observability: Google Cloud Logging, Cloud Monitoring, Cloud Trace
- IaC: Terraform
- CI/CD: GitHub Actions + Argo CD
その他
アプリケーションアーキテクチャ
SDIでは、DDDの考え方に基づいたアプリケーションアーキテクチャを採用しています。 具体的には、Bounded Context(BC)ごとにマイクロサービスを分割し、それぞれのマイクロサービスは独立した業務ドメインを持つようにしています。
また、各マイクロサービスはLayered Architectureで構成されており、各集約ごとの実装をある程度パターン化することでScaffolding Toolによるコードの自動生成を行い、開発速度の向上を試みています。
AIツールの活用
Claude CodeやCursorをはじめ、様々なツールを利用して設計から実装、レビューまでを効率化しています。 実際にどう活用しているのかについてはブログリレーの中でご紹介しますので、ぜひご覧ください!
さいごに
ここまでご覧いただきありがとうございました!
今回の記事だけでは話しきれなかったこともたくさんありますが、今回の新プロダクトの立ち上げが短期間で成功したのには、先行するData Hubリニューアルプロジェクトの開発基盤や全社Platformチームによる共通基盤、あとは何より「良いプロダクトを作るぞ!」という強い意思をもったチームの力が大きいと思っています。
以降のブログリレーでも、こうしたSansanの新プロダクト立ち上げの裏側をお伝えしていきますので、ぜひご覧ください!
Sansan技術本部ではカジュアル面談を実施しています

