はじめに
Sansan Data IntelligenceのProduct Owner(PO)を務めています猿田 貴之と申します。
本日12月12日、私たちは約4年ぶりとなる新規プロダクト Sansan Data Intelligenceをリリースいたしました。
これは、Sansanが名刺管理サービスから、企業の意思決定を支えるビジネスインフラへと進化するための挑戦の一つになります。
今回のリリースは構想から約半年という短期間で実現しましたが、その背景には10年以上にわたる名寄せ技術の蓄積と、既存のデータベースアーキテクチャをリビルドするSOC v2の開発がありました。名寄せとは、複数のデータベースに登録されている顧客情報から、重複する部分を洗い出し、一つに統合する作業を意味します。例えば、組織名の表記揺れなどで別々に存在するデータが名寄せ(グルーピング)され、組織データの活用価値が向上します。Sansan社は10年以上に渡ってこの名寄せ技術の向上に向き合ってきました。
本記事では、プロダクトが生まれた背景、既存プロダクト Sansan Data Hub との関係性、そしてそれを支える技術的革新についてお話しします。
Sansan Data Intelligenceとは
本題に入る前に、プロダクトの概要について簡単に触れておきます。
Sansan Data Intelligenceは、企業が保有するCRM/SFA(Sales Force Automation)や基幹システム内の取引先データを、当社独自の企業データベースと突合することで、高品質なマスターデータを継続的に構築・維持するデータクオリティマネジメントサービスです。
具体的には、以下の4つの価値を提供します。
- 識別・正規化:表記ゆれや重複を含むデータを、後述するSOC v2を用いて一意に識別して、正しい企業・事業所単位に統合します
- 最新化 :移転や合併、社名変更などの情報を自動検知し、常に最新のマスターデータを維持します
- リッチ化:業種、売上高、従業員数、系列情報など、営業戦略に必要な属性情報を付与します
- ホワイトリスト化:自社データにはない、市場の未接触企業(ホワイトスペース)を可視化し、ターゲティングリストとして提供します
単なる名寄せツールではなく、企業のデータ活用を足元から支えるデータガバナンスのインフラである。これがSansan Data Intelligenceの定義です。
第1章:なぜ今、Sansan Data Intelligenceなのか?
1-1. DXを止めるボトルネック
現在、多くの企業が「2025年の崖」対策や生成AI活用に向けたデータ基盤構築を進めています。しかし、Sansan社が行った調査によると、企業の約8割が「取引先データに重複・表記揺れ・更新漏れなどの経験がある」と回答しており、AI活用に取り組む企業の約9割が「期待通りの精度が出ない」と嘆いています。
Sansan、「企業のデータ管理に関する実態調査」を発表。一社平均6.4億円をシステム統合やデータ整備に投資〜平均23個のシステムを利用。データの重複や更新漏れが課題に〜 | Sansan株式会社
いわゆる「Garbage In, Garbage Out(ゴミが入ればゴミしか出てこない)」の状況です。
SFAやERPを導入しても、そこに入っているデータの品質に問題があれば、正しい経営判断を行うことはできません。
1-2. 現場で起きている負のループ
私たちがヒアリングを重ねる中で見えてきたのは、担当者の努力だけでは難しい構造的な限界でした。
- 入力の属人化:現場の営業担当者が手入力するため、社名が「(株)」だったり「株式会社」だったりバラバラになる。
- 更新の放置:移転や合併があっても、古い情報がそのまま残る。結果、請求書が届かない、与信管理が漏れるといった実害が出る。
- 見えないホワイトスペース:自社のSFAに入っているデータは氷山の一角だが、市場に他にどんな企業(未取引先)がいるのか把握できない。
これまで、これらの課題解決は人海戦術や一時的な名寄せプロジェクトに委ねられてきました。しかし、データは生き物です。一度きれいにしても、翌日にはまた汚れていきます。私たちは、このいたちごっこをシステムで恒久的に終わらせる必要がありました。
第2章:Sansan Data Hubとの関係性:なぜ新製品なのか
Sansan社には既にSansan Data Hub(以下、Data Hub)という顧客データの名寄せを行うオプション機能が存在します。
「なぜData Hubの機能拡張ではなく、Sansan Data Intelligenceという独立したプロダクトなのか?」
この問いに対する答えは、私たちが解決しようとしている課題のスコープの違いにあります。
2-1. 名刺起点からマスター起点へ
Data Hubは、あくまでプロダクト Sansan のオプション機能であり、その主眼は取り込んだ名刺データの名寄せにありました。Salesforce等への連携も行っていますが、それは名刺がある取引先の情報を綺麗にするアプローチです。
しかしながら、企業の情報システム部門やDX推進部門が求めていたのは、名刺の有無に関わらず、正確な企業マスター(ホワイトリスト)を持ちたいというニーズでした。さらに、基幹システムなどに長年所有している取引先データの名寄せのニーズもありました。それがData Hubでできることを知らなかったお客様も多数いました。
「まだ取引はないが、ターゲットとすべき企業」「名刺交換はしていないが、Webから問い合わせがあった企業」。これらを統合的に管理するには、名刺管理サービスの枠を超えた、独立したマスターデータ管理(Master Data Management, MDM)としての基盤が必要だったのです。
2-2. 取引先管理の多様化
Data Hubでも高精度な名寄せは可能ですが、「A社とB社が合併してC社になった」「D社はEグループの傘下に入った」といった複雑な企業間の関係性を表現して、管理することには限界がありました。
Sansan Data Intelligenceでは、後述する新コード体系SOC v2を採用することで、企業の属性だけでなく、資本関係や組織階層といった構造そのものをマスターデータとして提供します。
つまり、Data Hubで培った名寄せ技術という資産を継承しつつ、それを企業全体のデータガバナンス基盤へと昇華させたのがSansan Data Intelligenceです。
コラム:Sansan独自の企業コード「SOC」について
Sansan Data Intelligenceの機能を説明する上で欠かせないのが「SOC(Sansan Organization Code)」です。 SOCとは、Sansanが独自に構築・運用している企業データベースにおいて、企業を一意に識別するために付与されるID(企業コード)です。 このSOCを用いることで、表記の揺らぎや情報の重複を解消し、システムを横断してデータを一元管理することが可能になります。 次章で紹介するプロダクト機能も、このSOCの仕組みを中核として実現されています。
第3章:データクオリティマネジメント
では、具体的にどうやってデータの品質を管理するのか。Sansan Data Intelligenceのホーム画面(ダッシュボード)を例に、そのデータクオリティマネジメントの世界観を説明します。
ログインすると以下のようなホーム画面が提示されます。
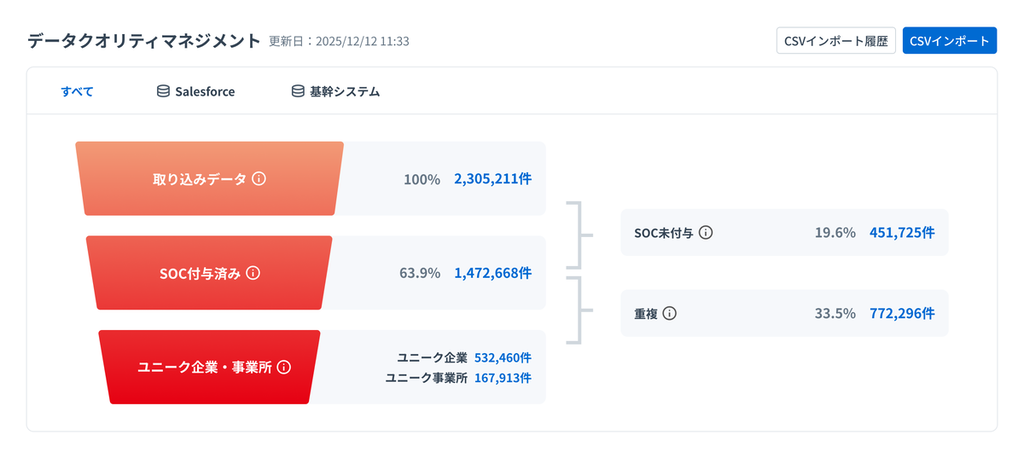
3-1. 取り込みデータとSOC付与
データクオリティマネジメントとしてまず、Salesforceや基幹システムから連携されたデータの総数が表示されます。
次に、Sansan社が保有する800万件超の企業データベースと突合して、一意な企業ID(SOC)が付与された件数が表示されます。逆にSOC未付与として弾かれたデータは、ビジネスリスクとなり得るノイズとして明確に分離されます。
3-2. ユニークデータ
次にユニーク企業・事業所データの数です。
「Sansan株式会社」「Sansan(株)」「サ ン サ ン」といった表記ゆれは、SOC付与によって同一企業として名寄せされます。ダッシュボード上では重複数が表示され、それらを取り除いた真の取引先数が明らかになります。
3-3. 状態のモニタリング
この画面は、一度見て終わりではありません。データは日々変化します。Sansan Data Intelligenceはこのダッシュボードを通じてデータの健全性を常時モニタリングし、重複率が増えてきた、未識別のデータが急増しているといった変化を検知します。これこそが、データクオリティマネジメントの実践です。
第4章:SOC v2の実現
この高度なデータマネジメントを実現している裏側には、SOC v2 (Sansan Organization Code version 2)というコードがあります。
4-1. 技術的課題
従来からSansan社は企業コードとしてSOC、拠点コードとしてSLCを提供していました。また、従来のSOC/SLCシステムではRDBのテーブル構造を採用していましたが、以下のような技術的課題に直面していました
1. 時系列方向に遡れない:スナップショット型のDBでは「2020年4月1日時点の組織図」を即座に再現できませんでした。これにより、過去の時点での与信判断や、組織変更前の契約状況を確認したいといったニーズに応えられません。
2. IDの同一性を保持できない:合併で新会社ができるとIDが変わり、過去のIDとの連続性が断絶してしまう問題があります。これにより、企業の沿革(リネージ)が追えなくなり、継続的な取引履歴の管理や分析が分断されてしまいます。
4-2. SOC v2が採用する時系列グラフモデル
これらを解決するために、SOC v2は時系列グラフモデルを採用しました。
- Entity (Node):企業、事業所などを表す不変の識別子。
- Relationship (Edge):「資本関係」「所属」「所在地(located_at)」などの関係性。
最大の特徴は、すべてのEdgeが有効期間を持っていることです。
移転や合併などの変更は、レコードの上書きではなく、新しいEdgeを追加する更新で表現されます。これによって、過去のいかなる時点の状態も破壊することなく保持し続けることができます。
4-3. SOC v2を支える基盤
この複雑なグラフモデルを、グローバル規模かつ強整合性を持って運用するために、データベースにはGCPのCloud Spannerを選定しました。また、APIにはGraphQLを採用しています。利用プロダクトはある時点(point_in_time)を指定して、必要な「深さ」までRelationshipを辿ってデータを取得できます。
第5章:サービスの拡張:サジェストAPIと 取引先データ診断レポート
この強固な基盤の上で、Sansan Data Intelligenceはさらなる価値を提供します。
5-1. サジェストAPI
「そもそも、汚いデータを入れさせない」。そのための機能がサジェストAPIです。ユーザーがSFA等の入力フォームで社名の一部を入力すると、正規化された正式名称、住所、業種などを瞬時にサジェストします。裏側ではSOC v2の高速な検索インデックスが動いています。
5-2. 取引先データ診断レポート
「自社のデータがどれくらい汚れているかわからない」。そんな声に応えるのが顧客データ診断です。お客様のデータをCSVでお預かりして、名寄せシミュレーションを実施します。重複率、データの鮮度、ホワイトスペース(未取引の優良顧客)を可視化したレポートを提供します。
第6章:ロードマップと未来への展望
6-1. グローバル・データガバナンスへの道
今後のロードマップには、さらなる機能拡張が予定されています。
- データの拡充:役員・管理職情報、リスクチェック、インテントデータなど、営業戦略に直結するデータを順次提供予定です
- API連携の強化:現在のCSV/Salesforce連携に加え、汎用的なAPI連携を強化し、あらゆるシステム(SAP, Oracle, kintoneなど)のマスターデータ基盤として機能することを目指します。
おわりに
Sansan Data IntelligenceとSOC v2は、単なるマスターデータ管理システムではありません。それは、「いつ、誰が、どのような状態で存在したか」を証明するデータ・ガバナンスのインフラです。
Data Hubで培った技術を礎に、この新規プロダクトを得て、Sansanは世界のビジネス構造そのものを記述するプラットフォームへと進化します。
時系列グラフ、分散DB、大規模データパイプライン。技術的難易度の高い課題に挑戦したいエンジニアの方、ぜひ一緒に挑戦しましょう。
Sansan技術本部ではカジュアル面談を実施しています

Sansan技術本部では中途の方向けにカジュアル面談を実施しています。Sansan技術本部での働き方、仕事の魅力について、現役エンジニアの視点からお話しします。「実際に働く人の話を直接聞きたい」「どんな人が働いているのかを事前に知っておきたい」とお考えの方は、ぜひエントリーをご検討ください。
docs.google.com
