G-gen の神谷です。本記事では、Google Cloud のスケーラブルでサーバレスなデータ管理ツールである Dataplex を徹底解説します。

Dataplex の概要
Dataplex とは
Dataplex は Google Cloud(旧称 GCP)で提供されている、分散されたデータの統合・管理を自動化するためのサービスです。以下のことが実現できます。
- 組織内の複数の Google Cloud プロジェクトにまたがるデータを統合してデータメッシュ(後述)を構築する
- データの権限管理を一元化する
- メタデータを付けることでデータをカタログ化し、検索しやすくする
- データの品質やライフサイクルを管理する
Dataplex はフルマネージドサービスであり、インフラの管理は一切必要ありません。また、使用されたリソース量や保存データ量に応じた従量課金であり、一般的には安価に利用することができます。
- 参考 : Dataplex の概要
Dataplex Universal Catalog
Dataplex には、Dataplex Universal Catalog(旧称 Dataplex Catalog)というサービスも内包されています。Dataplex Universal Catalog は、BigQuery や Cloud Storage など、Google Cloud 環境にあるデータのメタデータを管理し、カタログ化するフルマネージドサービスです。
当記事では Dataplex Universal Catalog の詳細には触れません。詳細は、以下の記事を参照してください。
メリット
Dataplex を使うことにより、組織内の散らばったデータを一箇所に集約せずに、そのままの状態で統合管理できます。データの移動やコピーは必要ありません。
具体的には、Cloud Storage や BigQuery に入っているデータがさまざまなプロジェクト、バケット、データセットに分散していても、統合管理をすることができるようになります。
「統合管理」にはデータの検索性のほか、データ品質の自動的なチェックやセキュリティ設定も含まれています。
Dataplex が管理対象にできるデータは、BigQuery、Cloud Storage、Dataproc Metastore などの Google Cloud サービスのほか、Apache Spark や Presto との統合も可能です。
データメッシュとは
Dataplex は「ドメイン」を中心とした「データメッシュ」を提供するプロダクトです。
組織内で、各部署やシステムごとに個別にデータを持ってしまい、かつどこにデータがあるか分からないためにデータの活用ができない状態はデータのサイロ化と呼ばれ、組織のデータの課題として有名です。これを回避するために、従来は単一のデータ基盤にデータを収集することでこれを解決しようとしてきました。
しかしこのアプローチは、データの移動(コピー)が必要になります。この実現には複雑なデータパイプラインの構築が必要なことに加え、コンピュートやストレージリソース、そしてそれらを管理する人のリソースも必要となります。
このような中央集権的な方式とは一線を画する解決策がデータメッシュです。論理的な管理レイヤで仮想的にデータをグルーピングすることで、データを分散配置したままで統合管理を可能にするアプローチです。これにより、データのコピーは不要でありながら、データのサイロ化を回避して、また認証・認可やデータ品質のモニタリングなどを実現できます。
Dataplex で実現するデータメッシュを理解するには、併せて以下の用語も把握してください。
| 用語 | 説明 |
|---|---|
| ドメイン | ・特定のビジネス分野や領域を表す概念 ・企業内で共通の言語やルールで情報を管理するための基盤となる ・例えば「セールス」「小売」「財務経理」など |
また、以下は、データメッシュにおける登場人物に関する用語です。
| 用語 | 説明 |
|---|---|
| データプロダクトオーナー | データプロデューサーとも呼ばれる。データを生み出す人またはチームであり、ビジネスやデータのドメインに最も詳しい。売上や受発注データに詳しい販売部門、EC サイトのアクセスログや顧客情報に詳しいマーケティング部門等にそれぞれデータプロダクトオーナーが存在する |
| データコンシューマー | データアナリストやデータサイエンティスト、あるいはビジネス部門の従業員といった データを消費 (利用) する人またはチーム |
| データスチュワード | 組織全体のデータ基盤を管理する人またはチーム。データの管理人であり、データ品質やガバナンス、権限管理、機密情報のマスキングなどを司る |
これらの登場人物が、ドメインごとにデータを生成・管理し、利用可能にする組織アーキテクチャがデータメッシュです。Dataplex はそのデータメッシュを実現するためのプロダクトであると言えます。

構成とオブジェクト
Dataplex の主要オブジェクトは以下のとおりです。前述の用語は組織や概念に関するものでしたが、ここからは実際に Dataplex を触るとシステム的に登場します。
- 参考 : 用語
| 名称 | 説明 |
|---|---|
| レイク | データの論理的なまとまり。ドメインごとにレイクを持つことが想定されている |
| ゾーン | レイクの中に存在するサブドメイン。データレイク、DWH、データマートのような段階を表現したり、給与や人事情報といった機密性の度合いで分類する。ゾーンには以下の2タイプが存在する。 ・Raw zone : 無加工・未チェックの生データ ・Curated zone : データクレンジング済みでいつでも分析できるデータ。Parquet や Avro などの構造化データ、BigQuery テーブルなどのアセットを含む |
| アセット | 実データであり、実体は Cloud Storage バケットや BigQuery データセット。実データが異なる Google Cloud プロジェクトに所属していても、単一ゾーンに所属することができる |
| エンティティ | 非構造化・半構造化・構造化データに対するメタデータ |
上記のオブジェクトは、以下のように階層構造を構成します。

従来だとデータは、Google Cloud プロジェクトでグルーピングし、BigQuery のデータセット名や Cloud Storage のバケット名などの命名規則で管理していました。
しかし Dataplex では Google Cloud プロジェクトが何であろうと、リソース名が何であろうと、レイクで階層化することで統合管理 できます。
レイクは複数のゾーンを含めることができますが、ゾーンは1つのレイクにしか所属できないため、ゾーンをドメインに対するタグのように扱うことはできません。また、ゾーンの下位リソースであるアセットも、1つのゾーンにしか所属できません。
アクセス制御機能
認証・認可(IAM)
IAM の基本的な理解
当項目の内容を理解するには、以下の記事をお読みになり、Google Cloud の IAM の基礎的な理解をしていただくことが前提となります。Amazon Web Services(AWS)の IAM 等とは概念が異なりますため、以下の記事をぜひご参照ください。
アセットと IAM
Dataplex では、Cloud Storage や BigQuery といった Dataplex アセットの上に仮想化階層を追加し、そこに対してユーザやサービスアカウントの IAM 権限を付与することで権限を管理します。
Dataplex でデータへのアクセス権限を管理するメリットとして、以下のようなものが挙げられます。
- 様々なプロジェクトに分散したデータの権限管理を集約
- ユーザーにとって意味のある単位(レイク、ゾーン等)で権限を付与できる
レイクの IAM ポリシーはゾーンに伝播(継承)され、さらにはゾーンが保持するアセットに伝播されます。Dataplex 経由の IAM ポリシーは、リソースにもともとついている通常の IAM ポリシーとは別で管理されます。プロジェクトレベルでロールを管理しなくて良くなり、リソースレベルの IAM 管理になるため、最小権限の原則が守りつつ、管理工数を削減することができます。
- 参考 : IAM を使用したアクセス制御
なお、ある Google アカウントが例えば BigQuery データセットに IAM ロールを持っており、同時に Dataplex でも権限を持っている場合、どちらかで権限が付与されていればアクセスが可能です。つまり、通常の IAM と Dataplex のアクセス制御は、OR で評価されます。運用上は、どちらかに権限管理を寄せるのが理想的です。
プロジェクトをまたぐ権限管理
管理対象のアセットが Dataplex とは別の Google Cloud プロジェクトに存在している場合は、Dataplex のプロジェクトの「Dataplex サービスアカウント(サービスエージェント)」に対して、アセットが存在するプロジェクトの IAM 権限(Cloud Storage 管理者ロールや BigQuery 管理者ロール)を付与する必要があります。
Dataplex サービスアカウントは service-${プロジェクト番号}@gcp-sa-dataplex.iam.gserviceaccount.com という名称で、Dataplex のプロジェクトに存在しています。
このように、Dataplex サービスアカウントに IAM 権限を委任することで、Dataplex は仮想的な権限レイヤを実現できるのです。
権限管理の詳細
Dataplex による権限管理の仕組みは、以下の記事でサンプルアーキテクチャを用いて解説しています。
権限管理手法や、運用のイメージをつけたい場合にご参照ください。
VPC Service Controls
VPC Service Controls を使って Dataplex に追加のアクセス制御層を作り、データ流出のリスクを軽減することができます。
VPC Service Controls は Google Cloud API へのアクセス制御を行うための独立した Google Cloud サービスです。以下の記事をご参照ください。
また以下の公式ドキュメントもご参照ください。
データの品質チェック
Dataplex におけるデータ品質の検証
Dataplex にはデータの品質チェック機能があり、以下の3種類の機能が用意されています。
- 自動データ品質
- データ品質タスク
- データプロファイリング
自動データ品質
自動データ品質とは
自動データ品質機能は、事前に定義したデータ品質に基づいてデータの品質をチェックし、品質要件を満たしていない場合にアラートを発報できる機能です。
ルールは以下の方法で定義できます。
- Dataplex からサジェストされる推奨事項を利用
- 事前定義ルール
- カスタム SQL ルール
自動データ品質チェックをすることで、品質定義を自動化・簡素化することができ、また品質を満たしていない場合の初動対応も迅速に行うことができるようになります。
- 参考 : 自動データ品質の概要
データ品質タスク
Dataplex データ品質タスクは、ユーザが独自にカスタマイズ可能なデータ品質チェックの機能です。BigQuery と Cloud Storage に対して実行できます。
データパイプラインに組み込んでデータ検証に用いたり、あるいは定期的なデータ品質チェックに用いることができます。
ルールは YAML で定義します。定義したルールは SQL に変換され、BigQuery 上で処理されるため、インフラ設定は不要です。また、スケジュールに基づいてチェックを実行できるほか、API 経由で呼び出し可能なため、既存のデータパイプラインに組み込むこともできます。
バックエンドではオープンソースのデータ品質エンジンである CloudDQ が使われています。CloudDQ は BigQuery 用のデータ品質検証コマンドラインツールであり、クラウドネイティブ、宣言型、スケーラブルといった特性を持ちます。
- 参考 : データ品質タスクの概要
データプロファイリング
データプロファイリングは、BigQuery テーブルの列の統計的特性をレポーティングする機能です。
テーブルの各列の「値の分布」「null の数」「ユニークな値の数(概算)」「最大値・最小値・平均値・標準偏差・近似中央値」などを出すことができます。
スキャンの対象テーブルを指定し、スケジュール実行することもできますし、結果を別の BigQuery テーブルにエクスポートすることもできます。
- 参考 : データ プロファイリングについて
データリネージ
データリネージとは
Dataplex のデータリネージ機能とは、ある BigQuery テーブルのデータがどこから来て、どこに渡されているかなど、データの出自を特定できる機能です。
「リネージ(lineage)」とは、血統、系統などを指す英単語です。データの家系図のようなものを連想させます。
有効化すると、テーブルごとにグラフが生成され、BigQuery のコンソール画面(BigQuery Studio)からデータの流れをグラフィカルに確認することができます。INSERT SELECT や CREATE TABLE AS SELECT などのジョブが追跡され、以下の画像のようなリネージグラフとして表示可能になります。

- 参考 : データリネージについて
- 参考 : BigQuery テーブルのリネージを追跡する
有効化
データリネージを有効化するには、プロジェクトで以下の3つの API を有効化するだけです。API 有効化後、リネージ情報の取得が開始されます。そのため、有効化前のリネージは確認できないことに注意が必要です。有効化すると、Dataplex 料金が発生することに留意してください。
- Dataplex API
- BigQuery API
- Data lineage API
追跡可能な情報
データリネージは、BigQuery の以下の情報を自動的に記録します。
- COPY ジョブ(テーブルの複製)
- Cloud Storage からの LOAD ジョブ
- 以下の QUERY ジョブ(DDL)
- CREATE TABLE
- CREATE TABLE AS SELECT
- CREATE TABLE COPY
- CREATE TABLE CLONE
- CREATE TABLE FUNCTION
- CREATE TABLE LIKE
- CREATE VIEW
- CREATE MATERIALIZED VIEW
- 以下の QUERY ジョブ(DML)
- SELECT(ビュー、マテリアライズドビュー、外部テーブル)
- INSERT SELECT
- MERGE
- UPDATE
- DELETE
BigQuery Data Transfer Service による定期的な LOAD ジョブは自動記録されないので注意が必要です。
また、データリネージは他にも Cloud Data Fusion、Cloud Composer、Dataproc、Vertex AI に対応しています。
さらに、対応していないソースでも、Data Lineage API 経由で記録させることが可能です。
保持期間
リネージ情報の保持期間は30日間です。
なお、BigQuery テーブルなどを削除したとしても、リネージ情報は30日間は残り続けます。
- 参考 : 制限事項
Dataplex Discovery
Dataplex Discovery とは
Dataplex Discovery は、データレイク内のデータからメタデータを自動でスキャンして抽出し、メタデータ化して Dataproc Metastore、BigQuery、Dataplex Universal Catalog に登録して利用可能にする機能です。
新しいゾーンやアセットを作成すると、自動で Dataplex Discovery が有効になりますが、オプショナルで無効にすることもできます。
Discovery が有効になっている Dataplex アセット(Cloud Storage バケット等)では、画像ファイルのような非構造化データや、Parquet / Avro / ORC / JSONL / CSV などの構造化ファイルが 自動でスキャンされます。テーブル名、スキーマ、パーティション定義などのテクニカルメタデータが収集され、Dataproc Metastore に Hive-style テーブルとして、また BigQuery では外部テーブルとして登録されるため、自動的にデータがクエリ可能になります。
これによって、組織内で管理されるデータソースが増えた場合に、わざわざ BigQuery にロードまたは外部テーブル定義したり、Jupyter Notebook で読み込める形に整形加工したりといった作業をせずとも、すぐさまこれらのツールで分析ができます。
- 参考 : データを検出します
Discovery Action
データのスキャン中に問題が検出されると、Discovery Action(検出操作)と呼ばれるアラートが上がります。以下のような問題が検出されたときに、Discovery Action が起票されます。
- 無効なデータ形式
- 互換性のないスキーマ
- 無効なパーティション定義
- データの欠損
機能名的に誤解を招きそうですが、Discovery Action はあくまで問題のアラートを上げるだけで、実際の改善アクションはユーザが行う必要があります。
- 参考 : 検出操作
異なるシステムのインターフェースをつなぐデータパイプラインでは、関係者内であらかじめ設計・合意されたスキーマのデータソースが流れていくはずです。
前述のようなデータ不正は想定外の恒久的エラーであるケースが多く、クラウドリソースの枯渇のような一時的エラーとは異なります。システムの自動リトライによって回避できるものではないため、迅速に検知して人が対処する必要があります。Discovery Action はそのような事態の迅速な検知に役立ちます。
ロギングとモニタリング
ロギング
Dataplex のログは Cloud Logging に自動的に出力されます。アセットを検出したり、スケジューリングされたタスクが実行されると、Cloud Logging にログが出力されます。
また監査ログ(「誰が、いつ、どこで、何をしたか」)も同様に、Cloud Logging に出力されます。
- 参考 : Dataplex のログをモニタリングする
- 参考 : 監査ログの管理
モニタリング
Dataplex は Cloud Monitoring と統合されており「アセットの合計サイズ」「ファイルセットの数」「テーブルの数」などに加え、未解決の管理アクションの有無などもメトリクスとして閲覧できます。
また、アプリケーションのパフォーマンスや稼働状況を視覚的に把握できます。Dataplex から収集した指標やメタデータを Cloud Monitoring のダッシュボードやグラフで表示し、詳細な分析情報を提供します。
これらの指標は自動的に有効化され、直感的にアクセスできます。
料金
Dataplex の料金は Dataplex が使った「コンピュートリソース」「ストレージ」によって課金されます。
コンピュート課金には Standard と Premium の2ティアがあり、例えば Dataplex Discovery 機能は Standard ティアの単価で課金され、データリネージやデータ品質タスクは Premium ティアの単価で課金されます。
どの機能にどの課金が適用されるか、詳細は以下をご参照ください。
- 参考 : Dataplex pricing
その他の機能
メタデータのインポート(マネージド接続)
マネージド接続(Managed connectivity)機能を利用すると、サードパーティのソースからメタデータを Dataplex にインポートできます。
コネクタを開発することで、MySQL、SQL Server、Oracle、Snowflake、Databricks などのソースからメタデータを抽出できます。
コネクタは、Dataproc Serverless で実行できる Artifact Registry イメージとして、PySpark 等で開発する必要があります。
- 参考 : マネージド接続の概要
- 参考 : メタデータのインポート用にカスタム コネクタを開発する
ビジネス用語集
ビジネス用語集(Business glossaries)は、組織全体でビジネス関連の用語を定義して一元管理する機能です。
用語はカテゴリ分け・階層化することができ、また用語間の関係を定義することもできます。その用語の管理者を明記しておくことも可能です。
さらに定義された用語は、データエントリのカラムにアタッチすることができるため、メタデータ管理の際に表記の揺れを防ぐことにも繋がります。
Gemini in Dataplex(分析情報)
Dataplex では、Google の生成 AI モデル Gemini を利用して、BigQuery テーブルや外部テーブル、ビューのデータ分析情報(data insights)を生成することができます。
この機能では、BigQuery テーブルに付与されたメタデータを使用して、テーブルとクエリに関する自然言語の質問を生成したり、その質問に回答するための SQL を生成できます。これにより、テーブルのデータから、パターンの検出、データ品質の評価、統計分析を行うことが可能です。
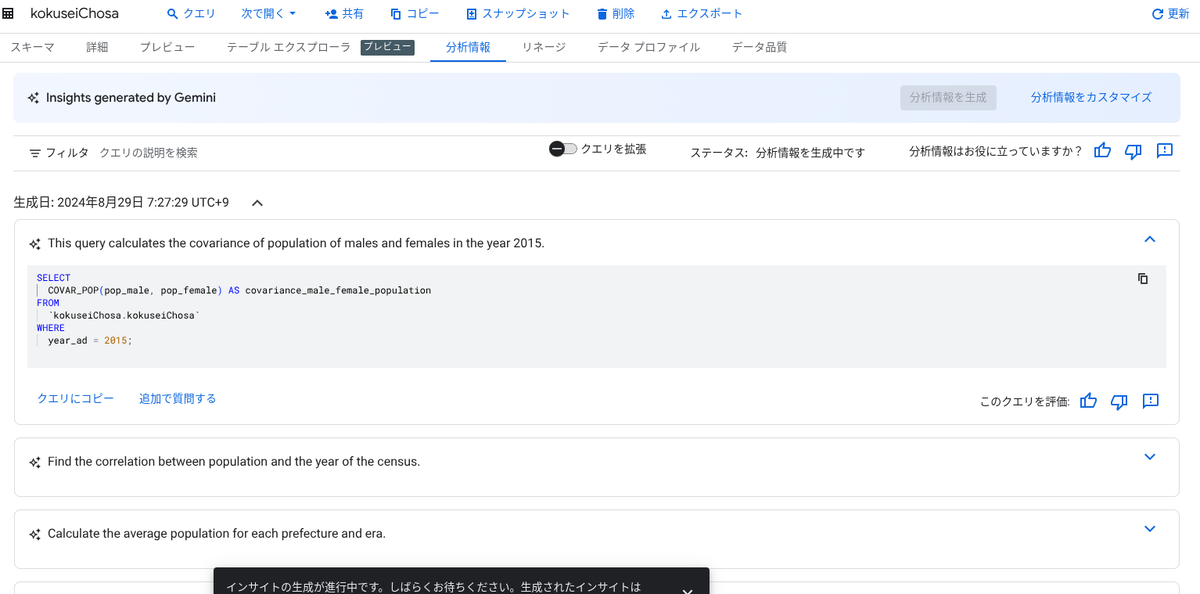
データ分析情報は、Gemini in BigQuery の機能です。Gemini in BigQuery については、以下も参照してください。
神谷 乗治 (記事一覧)
クラウドソリューション部
クラウドエンジニア。2017 年頃から Google Cloud を用いたデータ基盤構築や ML エンジニアリング、データ分析に従事。クラウドエース株式会社システム開発部マネージャーを経て現職。Google Cloud Partner Top Engineer 2023,2024、Google Cloud Champion Innovators(Database)、
