G-gen の杉村です。Google Cloud のメタデータ管理ツールである Dataplex Universal Catalog(旧称 Dataplex Catalog)を解説します。
- 概要
- データカタログとメタデータ
- データ検索機能
- メタデータの取り込み
- Dataplex Universal Catalog のリソース
- データの自動登録(Discovery)
- Data products
- 料金
- アクセス制御(IAM)
- 監査ログ

概要
Dataplex Universal Catalog とは
Dataplex Universal Catalog(旧称 Dataplex Catalog)とは Google Cloud のメタデータ管理サービスです。フルマネージドであり、インフラの管理は全く必要ありません。
Dataplex Universal Catalog では、BigQuery のテーブルや Cloud Storage バケット内の非構造化データなど、Google Cloud 上のデータにメタデータを付与してデータカタログ化し、ユーザーが検索できるようになります。BigQuery や Spanner、Bigtable、Dataproc、Pub/Sub など、多くの Google Cloud サービスのデータは何もしなくても自動的にカタログに登録されるほか、Cloud SQL 上のデータも、明示的に有効化することで登録できます。
さらに、Google Cloud リソース以外にも、オンプレミスのデータベースや Snowflake、Databricks など、サードパーティのメタデータも、カスタムコネクタを開発することで管理対象にできます。
なお Dataplex Universal Catalog は、Google Cloud のデータマネジメントサービスである Dataplex の一部です。Dataplex についての詳細は、以下の記事をご参照ください。
過去に存在した Data Catalog
過去には、Google Cloud に Data Catalog というプロダクトが存在していました。Data Catalog はサービス終了が発表されており、2026年1月30日にシャットダウン予定です。
Data Catalog の利用者は、Dataplex Universal Catalog に移行する必要があります。BigQuery などのリソースのメタデータは自動的に Dataplex Universal Catalog に登録されますが、その他の Data Catalog リソースは、以下のドキュメントを参考に、移行を行う必要があります。
Dataplex Universal Catalog と Data Catalog の機能は非常に類似しています。詳細な相違点については、以下のドキュメントを参照してください。
改名
Dataplex Universal Catalog は、かつて Dataplex Catalog という名称でした。2025年4月に米国ラスベガスで開催された Google Cloud Next '25 において、Dataplex Catalog という名称から BigQuery universal catalog への改名が発表されたあと、さらに現在の名称である Dataplex Universal Catalog に変更されました。
現在では、各種ドキュメントで Dataplex Universal Catalog という名称が使用されています。
データカタログとメタデータ
データカタログとは
データカタログとは、メタデータをカタログ化し、利用者が必要なデータを探し出しやすくするためのツールです。データカタログは Google Cloud に特有の概念ではなく、メタデータを管理するためのツール全般を指す一般的な用語です。当記事で紹介する Dataplex Universal Catalog は、Google Cloud がフルマネージドで提供するデータカタログサービスであるとお考えください。
データカタログが無いと、従業員はデータが必要になったときに、BigQuery や Cloud Storage の専門知識を使って一つ一つの Google Cloud プロジェクトを開いてテーブル名やファイル名を確認し、設計書を漁ったり、システム管理者に質問して回る必要があります。
データカタログでメタデータを集約管理することで、このような無駄なコミュニケーションを節約し、組織(企業や官公庁)の従業員は、必要なデータを探し出しやすくなります。
メタデータとは
そもそもメタデータとは何でしょうか。以下のようなテキストデータがあったとします。
[Data] 吾輩は猫である。名前はまだ無い。どこで生れたかとんと見当が......
このデータに、メタデータを付与すると以下のようになります。
[Metadata] Title: 吾輩は猫である Author: 夏目漱石 Page count: 380 [Data] 吾輩は猫である。名前はまだ無い。どこで生れたかとんと見当が......
ここでは、小説の本文をデータとして、タイトルや著者名、ページ数などをメタデータとしました。一般的にメタデータは「データ本体を説明するためのデータ」といえます。
データ分析基盤を構築しても、メタデータなしには、利用者が必要なデータを探し出すことは容易ではありません。メタデータがあるからこそ、データは活用されます。
現実世界の例でいうと、他に以下のようなものが挙げられます。
| 名前 | データ | メタデータ |
|---|---|---|
| PC 上のファイル | ファイルの中身 | ファイル名、サイズ、作成日時、更新日時、アクセス権限 |
| データベースのテーブル | レコード | テーブル名、列名、テーブルや列に関する説明 |
ビジネスメタデータとテクニカルメタデータ
メタデータは、ビジネスメタデータとテクニカルメタデータに分類されることがあります。
ビジネスメタデータとは、メタデータのうち、業務に関連するものを指します。そのデータの所有者、部門、業務上の意味、カラムの説明、利用上の注意などです。
テクニカルメタデータとは、メタデータのうち、より技術的な意味合いのものを指します。スキーマ定義、アクセス権限、パーティショニングやクラスタリングなどのテーブル属性などです。
なお、ここまで説明した「メタデータ」「テクニカルメタデータ」「ビジネスメタデータ」は、書籍や製品などによって独自の呼び方をしていることがありますのでご注意ください。
データ検索機能
検索方法
データに対する検索は、Google Cloud コンソール、あるいは API 経由で行うことができます。
Google Cloud コンソールは、Dataplex の画面と統合されています。Dataplex 画面で「検索」を選択するか、Web コンソール上部の検索ボックスに Catalog search と入力して表示されるサジェストをクリックすることでも、検索画面に遷移できます。

検索可能な範囲は、検索を実行者の Google アカウントが持つ IAM 権限に応じて決まります。データそのものにアクセス権がなくても、メタデータへのアクセス権があれば検索結果として表示されます。また、複数のプロジェクトを横断した検索が可能です。ただし、検索結果に表示されるのは、同じ Google Cloud 組織内のリソースだけです。
権限があれば、BigQuery、Pub/Sub、Cloud Storage、Spanner など、Dataplex Universal Catalog でカタログ化された全てのデータが対象となって検索されます。テーブル名、列名、Description など広い属性が検索対象になるため、ある程度あいまいな語でもデータに辿り着くことが可能です。
また検索対象のサービスや、リソースのタイプ、Dataplex のレイク、ゾーン、Google Cloud プロジェクトなどで、検索対象をフィルタすることが可能です。
自然言語検索(セマンティック検索)
Dataplex Universal Catalog では、キーワード検索ができることに加えて、自然言語での検索も可能です。この機能では AI が検索をサポートし、自然言語(人間が普段使う言葉)で検索を行うことができます。
自然言語で入力した検索語句は意味として解釈され、セマンティック検索(意味論検索)が行われます。
検索結果の表示
以下のスクリーンショットは、検索結果に表示された BigQuery テーブルの詳細画面の例です。
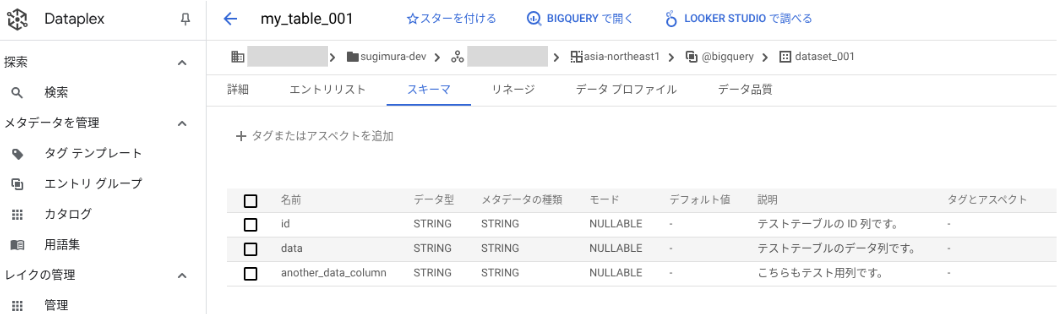
スクリーンショットでは「スキーマ」タブを表示しています。テーブルの所属データセット、プロジェクトや、スキーマ、そのスキーマに設定された説明(Description)などが表示されます。BigQuery のコンソール画面(BigQuery Studio)等でテーブルや列に設定した説明(Description)は、自動的に反映されて表示されます。
「詳細」タブには、Dataplex で設定したアスペクト(後述)なども表示されます。
その他のタブで、Dataplex によって作成されたデータリネージや、データ品質、データプロファイリングの結果も閲覧できます。
クエリの構文
Dataplex Universal Catalog では、単純に語を入れて検索することもできますし、記号を使った様々な構文も利用できます。
例えば name:foo とすると、エントリの名称に foo を含むエンティティを検索します。: は部分一致ですが、= だと完全一致になります。他にも column label location updatetime など、検索対象とする属性を指定することが可能です。
以下は、例です。
| 検索クエリ | 意味 |
|---|---|
| location=asia-northeast1 name:my-entry | 東京リージョンにある、名称に my-entry を含むエントリ |
| updatetime>=2025-04-04T06:00:00 | 2025-04-04T06:00:00 (GMT) 以降に更新されたエントリ (タイムゾーンは GMT のみサポート。+9時間で日本時間) |
詳細は以下の記事も参考にしてください。
メタデータの取り込み
メタデータの自動収集
Dataplex Universal Catalog は、以下の Google Cloud プロダクトのメタデータを自動的に取り込み、検索可能にします。カタログ化されたメタデータは、すぐに Dataplex Universal Catalog の UI や API 経由で検索可能です。
| プロダクト名 | 対象リソース |
|---|---|
| BigQuery | ・データセット ・テーブル ・BigQuery ML モデル ・ルーチン(ストアドプロシージャ、ユーザー定義関数、テーブル関数) ・接続 (Connections) ・リンクされたデータセット |
| AlloyDB for PostgreSQL | ・クラスタ、インスタンス(デフォルトで有効化) ・データベース、スキーマ、テーブル、ビュー(要有効化) |
| Analytics Hub | ・エクスチェンジ ・リスティング |
| Bigtable | ・インスタンス ・クラスタ ・テーブル |
| Dataform | ・リポジトリ ・コードアセット |
| Cloud SQL | ・インスタンス(デフォルトで有効化) ・データベース、テーブル、ビュー(要有効化) |
| Pub/Sub | ・トピック |
| Dataproc Metastore | ・サービス ・データベース ・テーブル |
| Spanner | ・インスタンス ・データベース ・テーブル ・ビュー |
| Vertex AI | ・モデル ・データセット ・特徴グループ ・特徴ビュー ・オンラインストアインスタンス |
- 参考 : サポート対象のソース
テクニカルメタデータの自動収集
前述の対応プロダクトのリソースのテクニカルメタデータは、自動的に収集されます。
BigQuery テーブルのテーブル名、カラム名、カラムの型や説明(description)など、リソースに付与されたテクニカルメタデータは、ユーザーが何もしなくても**自動的に収集され、すぐに検索可能です。
サードパーティのメタデータ
Dataplex Universal Catalog では、前述の Google Cloud サービス以外にも、カスタムエントリ(後述)を作成することで、オンプレミスや他クラウドのデータのメタデータを登録することが可能です。
また、サードパーティのデータソースから Dataplex にメタデータを継続的、自動的にインポートするには、マネージド接続(Managed connectivity)機能を使います。これには独自のカスタムコネクタの開発が必要です。カスタムコネクタは、PySpark 等を用いて、Dataproc Serverless で実行できる Artifact Registry イメージとして作成する必要があります。
- 参考 : マネージド接続の概要
- 参考 : メタデータのインポート用にカスタム コネクタを開発する
マネージド接続用のカスタムコネクタとして、コミュニティによって開発されたコネクタを利用することもできます。これらのコネクタは Google によって公式にサポートされるものではありませんが、PostgreSQL、SQL Server、Oracle、Snowflake などに向けたコネクタが公開されています。
Dataplex Universal Catalog のリソース
エントリ、エントリグループ、エントリタイプ
エントリとは、BigQuery データセットやテーブル、Pub/Sub トピックなど、1つ1つのリソースを指します。メタデータは、エントリ内のアスペクト(後述)に記述されます。
エントリグループは、エントリをグルーピングする管理単位です。@bigquery や @pubsub などの Google Cloud リソースのエントリグループが、Dataplex Universal Catalog によって自動的に作成されます。
エントリタイプは、エントリのテンプレート(雛形)です。Dataplex Universal Catalog によって定義済みのエントリタイプはシステムエントリタイプといい、例として BigQuery テーブルや Pub/Sub トピックなど、自動で登録されるエントリには、システムエントリタイプが適用されます。
ユーザー側で、カスタムエントリやカスタムエントリグループ、カスタムエントリタイプを作成することもできます。これにより、Dataplex Universal Catalog が自動的に取り込まないリソースのメタデータや、Google Cloud 外のデータのメタデータも、Dataplex Universal Catalog に登録することができます。
アスペクト、アスペクトタイプ
エントリ内にはアスペクトと呼ばれるフィールドがあり、メタデータはここに記述されます。
アスペクトには、キー(名前)とバリュー(値)を登録できます。これにより、ビジネスメタデータや、追加のテクニカルメタデータを記述できます。
アスペクトタイプとは、複数のアスペクトのプリセットです。例えば、あらかじめ Data Governance というアスペクトタイプを定義しておき、その中にはデータの管理者や所有者の連絡先、機密レベル、保持期限などのエントリの名前を登録しておきます。アスペクトタイプは再利用できるので、統一したフォーマットでエントリにメタデータを登録することができます。
以下は、Data Governance というアスペクトタイプを BigQuery データセットに適用して、値を入力した例です。
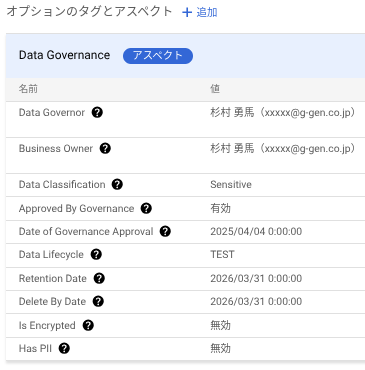
BigQuery の場合、テーブル全体にアスペクトを付与することもできますし、カラムに付与することもできます。
ユーザーで定義したアスペクトタイプは、組織内で公開できます。これにより、メタデータのフォーマットを統一できます。運用上は、組織でデータガバナンスルールを定義し、どのようなメタデータを必須として付与すべきかを定義することが望ましいといえます。
- 参考 : アスペクトを管理してメタデータを拡充する
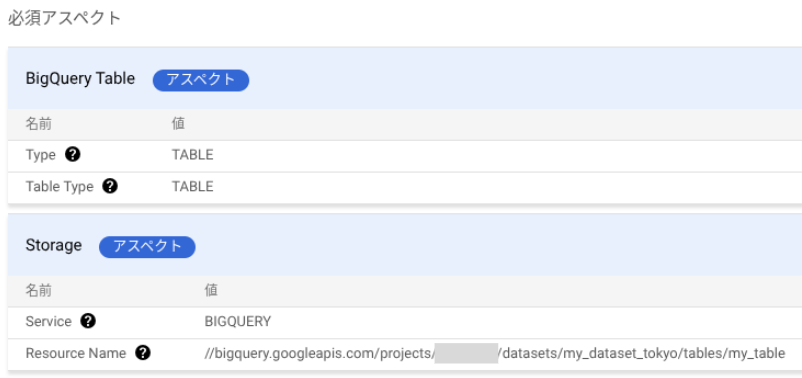
必須アスペクト
例えば BigQuery テーブルのエントリには、Dataplex Universal Catalog によって予め「BigQuery Table」と「Storage」という必須アスペクトが付与され、値が自動的に登録されます。
データの自動登録(Discovery)
Dataplex Discovery は、Dataplex にアセットとして登録されているデータレイク内のデータから、メタデータを自動でスキャンして抽出し、Dataproc Metastore、BigQuery、Dataplex Universal Catalog に登録して利用可能にする機能です。
Dataplex の機能の一部として提供されているので、詳細は以下の記事をご参照ください。
Data products
Data products(データ製品)は、データの提供者が、組織内の利用者向けにデータアセット(BigQueryデータセットやテーブル)をパッケージして、キュレーションするための機能です。権限管理の運用もシンプルにすることができます。
1つの Data product は論理的なオブジェクトであり、中に BigQuery データセット、テーブル、ビューといったアセットを含むことができます。Data product にはアクセスグループとして Google グループを設定でき、データへのアクセス管理を行うことができます。
- 参考 : About data products
料金
Dataplex Universal Catalog の料金として、メタデータストレージの料金が発生します。2025年11月現在、メタデータストレージ料金の単価は、$2/GiB/月です。
また、Dataplex のデータリネージ機能の保存データも、このストレージ料金として加算されます。データリネージについては、以下を参照してください。
アクセス制御(IAM)
IAM の基本
メタデータの検索、エントリへのタグ付け、データリネージの閲覧などは、全て IAM(Identity and Access Management)によってアクセス制御されます。
「メタデータは検索可能で、リソース名称やメタデータまでは表示させて良いが、データそのものにはアクセスさせない」といった権限管理も可能です。
Google Cloud の IAM では、Amazon Web Services(AWS)と異なり、リソースに対して、誰が、何をできるかを設定します(IAM ポリシーをリソースが持ちます)。Google Cloud の IAM の基本は、以下の記事をご参照ください。
メタデータの検索
Dataplex Universal Catalog を使って検索を行う Google アカウントは、検索を実行するプロジェクトに対して、Dataplex Catalog 閲覧者(roles/dataplex.catalogViewer)ロール等を持っている必要があります。
ただし、検索結果に出てくるリソースは、検索を実行したアカウントがメタデータへのアクセス権限を持っているリソースだけです。
逆に、メタデータへのアクセス権限を持っていれば、検索を実行したプロジェクト以外のプロジェクトのリソースも、検索結果に表示されます(ただし、同じ Google Cloud 組織内のリソースのみ)。つまり、Dataplex Universal Catalog では、複数のプロジェクトを横断した検索が可能です。
カタログの管理
Dataplex Universal Catalog のリソース(エントリやアスペクト等)の管理を行うには、操作者の Google アカウントがプロジェクト等に対して管理に関するロールを持っている必要があります。
プロジェクトレベルでオーナー(roles/owner)や編集者(roles/editor)を持っていれば、Dataplex Universal Catalog リソースの管理が可能です。また、Dataplex Catalog 管理者(roles/dataplex.catalogAdmin)、Dataplex Catalog 編集者(roles/dataplex.catalogEditor)などの事前定義ロールが用意されています。
- 参考 : Dataplex IAM ロール
Dataplex による権限管理
Dataplex による権限管理と、カタログの検索権限に関するイメージは、以下の記事をご参照ください。
監査ログ
Dataplex Universal Catalog では、Cloud Audit Logs により、監査ログ(誰が、いつ、どこで、何をしたか)が Cloud Logging に記録されます。
デフォルトでは、カスタムアスペクトの作成や編集といった、管理アクティビティログが記録されます。
- 参考 : Dataplex 監査ロギング
Cloud Audit Logs についての詳細は以下の記事をご参照ください。
杉村 勇馬 (記事一覧)
執行役員 CTO
元警察官という経歴を持つ IT エンジニア。クラウド管理・運用やネットワークに知見。AWS 認定資格および Google Cloud 認定資格はすべて取得。X(旧 Twitter)では Google Cloud や Google Workspace のアップデート情報をつぶやいています。
Follow @y_sugi_it