
はじめに
こんにちは、人工知能研究所の村田です。入社してまだ1年目の私ですが、若手を対象とした海外研修制度の一環で、2024年12月10日から15日にカナダのバンクーバーで開催された国際会議 NeurIPS 2024(正式名称:Annual Conference on Neural Information Processing System)に聴講参加しました。私以外のメンバーも現地参加・発表をしており、NeurIPS 2024 で得られた知見、発表内容などをまとめた記事について連載で投稿しています。第2回目となる本投稿では、口頭発表セッションが満席となるほどに注目度の高い技術である、AI Agent に関する研究動向について紹介します。
AI Agent 最新研究動向
AI Agentは、人から与えられたゴールを解釈し、ゴールを達成するために必要な処理フローを計画・実行する生成AIの進化形態です。皆さんも一度は AI Agent という言葉を耳にしたことがあるのではないでしょうか?
NeurIPS 2024では、「Agents」をトピックとした口頭発表セッションが用意されており、セッション会場は満席で立見の聴講者もいるほどに盛況した様子でした。2023 年開催のNeurIPSでは「Agents」をトピックとした口頭発表セッションはなく、今年度特に注目されている技術の一つといっても過言ではないでしょう。また、口頭発表セッションで発表された3件の論文のうち、2件がAI Agent の評価やベンチマークに関する論文であり、AI Agent をどのように評価するかという点に注目が集まっている印象を受けました。
そこで、AI Agent 最新研究動向として、口頭発表論文のトピックの中心であった、AI Agent の評価に関する論文を3件紹介します。
Embodied Agent Interface: Benchmarking LLMs for Embodied Decision Making(口頭発表論文)
Manling Li1, 2, Shiyu Zhao1, Qineng Wang1, 2, Kangrui Wang1, 2, Yu Zhou1, Sanjana Srivastava1, Cem Gokmen1, Tony Lee1, Li Erran Li3, Ruohan Zhang1, Weiyu Liu1, Percy Liang1, Li Fei-Fei1, Jiayuan Mao4, Jiajun Wu1 (1 Stanford, 2 Northwestern, 3 Amazon, 4 MIT) https://doi.org/10.48550/arXiv.2410.07166
概要
身体性を持つことを特徴とする AI Agent である Embodied Agent を対象とし、「冷蔵庫を綺麗にして」といった指示に対して、冷蔵庫を綺麗にするまでの処理フローを計画する LLM ベースの AI Agent を評価するためのインターフェースを提案している論文です。
背景
Embodied Agent に対する意思決定を行うツールとしての LLM の有用性を報告する数多くの論文が発表されています。しかし、これらの論文はそれぞれ異なる目的で LLM を利用しており、LLM に与える入力や期待する出力も異なるため、LLM の意思決定ツールとしての性能を統一的に理解することが困難です。
提案インターフェース
そこで筆者らは、LLM に求められる能力や入出力を標準化したインタフェースである「EMBODIED AGENT INTERFACE」を提案しています。

EMBODIED AGENT INTERFACE では、以下の4つの能力について評価されます。
- Goal Interpolation: 初期状態と自然言語による指示から、指示を完遂している状態(ゴール)を推論できる能力
- Subgoal Interpolation: 初期状態とゴールから、そのゴールに至るまでにどのような状態を経ればよいかを計画できる能力
- Action Sequencing: 初期状態とゴールに加えて、ある状態に対してある行動をしたときの状態の遷移を定義づける遷移モデルが与えられた場合に、ゴールを完遂する行動フローを計画できる能力
- Transition Modeling: 初期状態とゴールに加えて、行動のリストが与えられた場合に、各行動を行うための条件と行動による効果をモデル化する能力
また、これら4つの能力を詳細に評価する評価指標も提供されています。例えば、Action Sequencing に対しては、各行動を逐次実行した場合にゴールが完遂されているかを評価する指標に加えて、出力された行動フローが実行可能であるかを評価する指標が定義されています。
実験
論文中では、GPT-4o を含む合計18種類の LLM に対する評価・分析が詳細に行われていました。また、すべての LLM が共通して誤ったケースとして、食事を出すというタスクに対して、チキンを皿の上に置かず、チキンをテーブルの上に直接置くという行動をするように計画したという事例が紹介されていました。筆者らは、"put the chicken on the table”という言い回しが良く使われるためだろうと推察していました。このように、自然言語では誤って表現されたり省略されたりするような一般常識を、どのように知識として LLM に持たせるかという観点が、今後重要になっていくように感じました。
AgentBoard: An Analytical Evaluation Board of Multi-turn LLM Agents(口頭発表論文)
Chang Ma1, Junlei Zhang2, 5, Zhihao Zhu3, Cheng Yang4, Yujiu Yang4, Yaohui Jin3, Zhenzhong Lan5, Lingpeng Kong1, Junxian He6 (1 The University of Hong Kong, 2 Zhejiang University, 3 Shanghai Jiao Tong University, 4 Tsinghua University, 5 Westlake University, 6 HKUST) https://doi.org/10.48550/arXiv.2401.13178
概要
LLM ベースの AI Agent を多様なタスク・環境での詳細な評価・分析を可能とする統一的な評価フレームワーク AgentBoard を提案している論文です。
背景
LLM ベースの AI Agent の研究の促進には、包括的な評価フレームワークが不可欠です。筆者らは、そのような評価フレームワークに必要な要素として、以下の3点を挙げています。
- 評価対象のタスク・環境が多様であること
- 複数回の行動を必要とするシナリオであること
- Agent の環境探索能力を測るために、環境の一部のみが観測可能であること
また、このように複雑なタスクにおける Agent の性能を理解するためには、タスクを正しく遂行できたかのみでなく、タスクを遂行する過程も詳しく分析・評価できるような仕組みが必要です。しかし、このような包括的かつ詳細な評価を可能とするフレームワークはこれまでに提案されていません。
提案フレームワーク
そこで筆者らは、9つのタスクと1,000を超える環境での評価・分析を可能とする評価フレームワーク AgentBoard を提案しています。

AgentBoardには、身体性を持つ Agent としての評価を可能とするようなタスクのみでなく、戦略ゲームをベースとして Agent のプランニング能力を測るタスクや、商品検索といった Web 上での動作を求めるタスク、スプレッドシートといった外部ツールの利用を求めるタスクが含まれています。また、各タスクに対する Agent の性能を、プランニングや記憶能力といった各能力毎に細かく分析することも可能です。
実験
論文中では、GPT-4 を含む合計13種類の LLM に対する評価・分析が AgentBoard によって行われていました。すべてのタスクにおいて、GPT-4 の性能の高さが際立つ結果となっていましたが、サブゴールの数が多かったり目的を達するための条件が多いような難しいタスクについては、まだ GPT-4 も誤ることが多々あるといった印象を受けました。
Constrained Human-AI Cooperation: An Inclusive Embodied Social Intelligence Challenge
Weihua Du1, Qiushi Lyu2, Jiaming Shan3, Zhenting Qi4, Hongxin Zhang5, Sunli Chen5, Andi Peng6, Tianmin Shu7, Kwonjoon Lee8, Behzad Dariush8, Chuang Gan5 (1 Carnegie Mellon University, 2 Peking University, 3 University of California, Santa Barbara, 4 Harvard University, 5 University of Massachusetts Amherst, 6 MIT, 7 Johns Hopkins University, 8 Honda Research Institute USA) https://doi.org/10.48550/arXiv.2411.01796
概要
視覚的情報から人を助けるような行動を取る AI Agent の設計と評価フレームワークを提案している論文です。
背景
人は、何かのタスクの実行を試みて失敗している人を見かけたら、その人を助けるような行動を取ることができます。AI Agent がこのように人を助けるような行動を取るためには、1. 人の行動から目的としているタスクとそのタスクの遂行を妨げる制約を知覚する能力と、2. その人を助けるのに適した行動プランを練る能力が必要です。しかし、このような社会的能力の多寡はこれまでに提案されている評価フレームワークでは測ることが困難です。
提案フレームワーク
そこで筆者らは、AI Agent が人を助けるような行動を取れるかを定量的に評価するフレームワークである、Constrained Human-AI Cooperation (CHAIC) Challenge を提案しています。
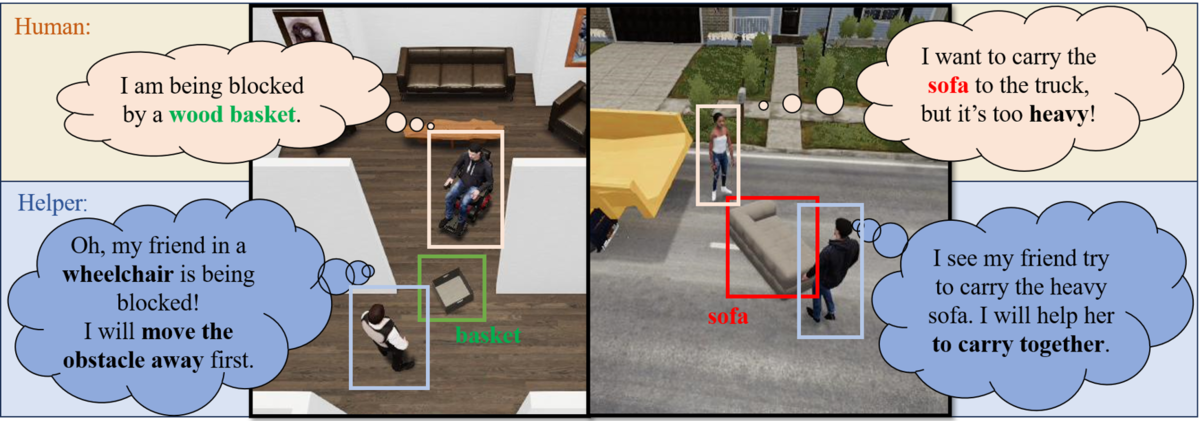
CHAICは、人の意図をくみ取りその意図に応じた行動をとることを AI Agent に要求するようなタスク群によって構成されています。 例えば、重い物を持ち上げることができていない人に対して、その重い物を一緒に持って荷台まで運ぶという行動が取れるかといったタスクが含まれています。 このようなタスク群を用いることで、困っている人を知覚しその助けとなる行動を取れるかという、社会的能力の多寡について AI Agent を評価することが可能となります。
実験
論文中では、VLM や LLM に行動認識結果をテキストとして与えた場合などについて、CHAIC Challenge における性能が評価されていました。視覚的情報を必要とするため、VLM が高い性能を示すことを予想していましたが、ランダムな行動を取るベースラインと同程度以下の結果となる場合があるという点が非常に印象的でした。
おわりに
本稿では、AI Agent 最新研究動向として、AI Agent の評価に関する論文を3件紹介しました。実世界でのシナリオに近いような複雑なタスクについて、詳細な評価を可能とすることが、AI Agent の評価に重要なファクターであるように感じられました。
なお、弊社では AI Agent に関する取り組みの一つとして、映像解析型 AI Agent のための評価環境「FieldWorkArena」を米国の Carnegie Mellon University の監修のもと開発しました。「FieldWorkArena」には、実際の工場現場など得られる40種以上のデータ(映像、作業手順書)と500もの現場固有のタスクが含まれており、実業務に対する AI Agent の性能を評価できます。また、AIが難易度の高い業務を自律的かつ人と協調して推進できるAIサービス「Fujitsu Kozuchi AI Agent」の提供に加えて、企業や公共団体のITシステムにおけるセキュリティ対策を支援するマルチ AI Agent セキュリティ技術や、製造・物流などの現場環境における支援を実現する映像解析型 AI Agent といった、特化型 AI Agent の開発にも取り組んでいます。各技術やサービスの詳細については、以下をご覧ください。
・AIエージェントベンチマークスイート FieldWorkArena
・AIが人と協調して自律的に高度な業務を推進する「Fujitsu Kozuchi AI Agent」を提供開始
・世界初、脆弱性や新たな脅威への事前対策を支援するマルチAIエージェントセキュリティ技術を開発
・作業効率化や安心・安全な現場づくりに向けた改善を自律的に支援する映像解析型AIエージェントを開発
