こんにちは!広告事業本部でリードアプリケーションエンジニアをしている半田です。
花粉症がつらい季節ですね。今年は特にひどく、薬を飲まないと仕事にならなかったため、舌下免疫療法を始めることを決心しました…。
さて、今回はGoogle Cloudの料金削減について取り組んだ内容をご紹介します。
背景
私たちのチームはMediaAnalyzerシリーズ(以下MA)で利用するデータ基盤を構築しており、できるだけコストを抑えた構成で運用していました。しかし、データ量の増加に伴い料金も増加し、隔週で行われている振り返り会でもコスト増加が議題に上がるようになりました。このままではまずいと感じ、何らかの対策を講じる必要があると考えました。
MAのデータ基盤は速度重視で開発を進めていたため、コスト管理やデータ最適化への配慮が不足し、料金が想定以上に膨らむ原因となっていました。そこで、業務の合間を縫って料金削減に取り組むことにしました。
MAについては以下のリリースをご覧ください。
データ基盤については以下のブログをご覧ください。
料金削減の流れ
料金削減にあたり、以下の手順で進めました。
- 現状把握
- コストの可視化
- 削減方法の検討
- 実施
- 効果測定
現状のコスト把握
料金を削減するには、どのサービスにどれくらいのコストがかかっているかを把握する必要があります。
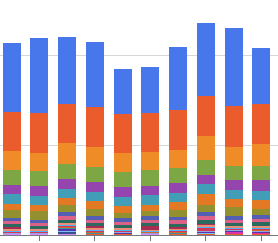
Google Cloudの請求レポートを使用すると、グラフでコスト状況を視覚的に確認できます。
以下はとある期間のグラフですが、青(BigQuery)とオレンジ(Cloud Storage)が突出して大きいことがわかります。これらのサービスにアプローチし、コスト削減に取り組むことにしました。
BigQueryの料金削減に向けた可視化
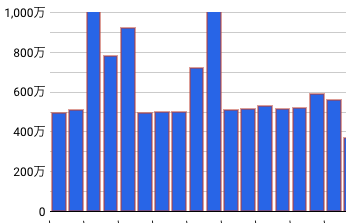
BigQueryの料金削減に向け、まずはどのテーブルやクエリがどれくらいのコストをかけているかを把握しました。
スケジュールされたクエリの設定
毎日定期実行されるスケジュールクエリを設定し、前日分の課金されたクエリとそのクエリによる課金バイト数を取得しました。
各カラムについてはBigQuery リファレンスをご確認ください。
SELECT job_id, job_type, user_email, TIMESTAMP_ADD(creation_time, INTERVAL 9 hour) AS creation_time, TIMESTAMP_ADD(end_time, INTERVAL 9 hour) AS end_time, total_bytes_processed / (1024 * 1024) AS total_mb_processed, total_bytes_billed / (1024 * 1024) AS total_mb_billed, (end_time - creation_time) AS duration, query FROM `region-asia-northeast1`.INFORMATION_SCHEMA.JOBS WHERE DATE(end_time) = CURRENT_DATE('Asia/Tokyo') -1
Looker Studioで可視化
取得したデータを保存したテーブルを基に、Looker Studioを使用して可視化しました。これにより、日々のコストを一目で把握できるようになりました。
縦軸はtotal_mb_billed、横軸はDATE(end_time)になります。
施策1 不要なカラムの更新処理やデータ取得の停止
最初に取り組んだのは、不要なカラムの更新処理やデータ取得の停止です。
具体的には、データレイクからデータウェアハウスに対して SELECT * FROM hoge のように全カラムを取得するクエリが多く見られました。運用が安定した今、不要なカラムを精査し、取得を停止しました。
特に文字列データはサイズが大きくなるため、取得を停止することで数百GB/日を削減し、クエリ実行コストを大幅に削減できました。
before
SELECT started_at, ended_at, data.customer.id AS customer_id, data.campaign.id AS campaign_id, data.segments.*, data.metrics.* FROM campaign_report, UNNEST(response.body.results) AS data
after
SELECT started_at, ended_at, data.customer.id AS customer_id, data.campaign.id AS campaign_id, data.segments.device, -- `*` で取得していたカラムを個別のカラム名に展開 data.segments.date, data.metrics.impressions, data.metrics.clicks, data.metrics.conversions, FROM campaign_report, UNNEST(response.body.results) AS data
施策2 増分更新を行う
Dataformでテーブル作成をする際、更新の度に全更新するか増分更新するかが選択できます。
特に日々増え続けるレポート系のデータに関してはデータウェアハウスでの増分更新も有効です。
本システムでは日々の更新系も含めすべてのテーブルで増分更新に変更しました。
config {
type: "incremental", -- type を table から incremental に変更
uniqueKey: [
"customer_id",
"campaign_id",
"date",
]
}
SELECT
started_at,
ended_at,
data.customer.id AS customer_id,
data.campaign.id AS campaign_id,
data.segments.device,
data.segments.date,
data.metrics.impressions,
data.metrics.clicks,
data.metrics.conversions,
FROM
campaign_report,
UNNEST(response.body.results) AS data ${when(incremental(), `WHERE DATE(started_at) = CURRENT_DATE("Asia/Tokyo")`)} -- 増分更新の条件を追加
施策3 パーティションの追加
本来ならはじめの段階でやるべきですが…。
主に手動でレポート系のテーブルへクエリを実行する際に、日付期間指定で実行する機会が多かったので日付カラムのパーティションを追加しました。
日付パーティションを追加するためには、テーブルを一度削除し、新たにパーティションを設定したテーブルを作成する必要がありますが、将来的な効率化を考えた結果、このタイミングで実施することにしました。
以下のように書き換えました。
config {
type: "incremental",
uniqueKey: [
"customer_id",
"campaign_id",
"date",
],
bigquery: {
partitionBy: "date" -- bigquery partitionBy の追加
}
}
SELECT
started_at,
ended_at,
data.customer.id AS customer_id,
data.campaign.id AS campaign_id,
data.segments.device,
data.segments.date,
data.metrics.impressions,
data.metrics.clicks,
data.metrics.conversions,
FROM
campaign_report,
UNNEST(response.body.results) AS data ${when(incremental(), `WHERE DATE(started_at) = CURRENT_DATE("Asia/Tokyo")`)}
施策4 増分テーブルで全体をスキャンしないようにする
増分テーブルを更新すると、過去データと現在データを比較する必要があるため、全レコードのスキャンが実行されます。
全件スキャンすることはテーブルの容量が増えるにつれて、かなりのコストがかかります。そのため、必要なデータのみをスキャンするように工夫する必要があります。
ここで役立つのが、DataformのupdatePartitionFilterです。これを設定することで、スキャン範囲を最適化し、効率的なデータ処理が可能になります。具体的には、更新対象のレコードに対してのみフィルタを適用することで、全体をスキャンすることなく、必要な部分だけを処理できます。
config {
type: "incremental",
uniqueKey: [
"customer_id",
"campaign_id",
"date",
],
bigquery: {
partitionBy: "date"
updatePartitionFilter: "date >= DATE_SUB(CURRENT_DATE('Asia/Tokyo'), INTERVAL 30 DAY)" -- updatePartitionFilter で30日分のレポートデータの更新
}
}
SELECT
started_at,
ended_at,
data.customer.id AS customer_id,
data.campaign.id AS campaign_id,
data.segments.device,
data.segments.date,
data.metrics.impressions,
data.metrics.clicks,
data.metrics.conversions,
FROM
campaign_report,
UNNEST(response.body.results) AS data ${when(incremental(), `WHERE DATE(started_at) = CURRENT_DATE("Asia/Tokyo")`)}
施策5 GCSの保存ファイル削減
これまではBigQueryに対するアプローチでしたが、GCSの料金削減の実施内容も紹介します。
GCSにはAPIで取得したraw dataを保存していましたが、一度BigQueryにインポートしたあとはバックアップ目的で保存していました。このバックアップ目的のデータ量が増加し、コストが膨らむ要因になっていました。
ストレージクラスの変更(Autoclassやライフサイクル管理)も検討していましたが、アクセス回数がほぼないことと、ファイル数が膨大だったので、月単位でまとめてZIP化し元データは削除する方法に変更しました。
ZIP化は、WorkflowsからCloud Run Jobを呼び出し、自動で定期実行するようにしました。
# requirements.txt google-cloud-storage
# main.py import os import io import zipfile from google.cloud import storage SOURCE_BUCKET_NAME = os.environ["SOURCE_BUCKET_NAME"] DESTINATION_BUCKET_NAME = os.environ["DESTINATION_BUCKET_NAME"] SOURCE_PATH_NAME = os.environ["SOURCE_PATH_NAME"] DESTINATION_ZIP_NAME = os.environ["DESTINATION_ZIP_NAME"] def main(): client = storage.Client() # ZIP化する元ファイルのバケット名を指定 bucket = client.bucket(SOURCE_BUCKET_NAME) # ZIPファイルを保存するバケット名を指定 destination_bucket = client.bucket(DESTINATION_BUCKET_NAME) zip_buffer = io.BytesIO() # ZIP化対象のpathを指定(ワイルドカード対応) blobs = bucket.list_blobs(match_glob=SOURCE_PATH_NAME) with zipfile.ZipFile(zip_buffer, 'w') as zipf: for blob in blobs: with zipf.open(blob.name, 'w') as zf: blob.download_to_file(zf) zip_buffer.seek(0) # ZIP化したファイルを指定のファイル名で保存 zip_blob = destination_bucket.blob(DESTINATION_ZIP_NAME) zip_blob.upload_from_file(zip_buffer, content_type='application/zip') return
ZIP化が終わったファイルの削除は別のJobで作成しました。
# requirements.txt google-cloud-storage
# main.py import os from google.cloud import storage BUCKET_NAME = os.environ["BUCKET_NAME"] DIR_NAME = os.environ["DIR_NAME"] def main(): client = storage.Client() # 削除対象のバケット名を指定 bucket = client.bucket(BUCKET_NAME) print(f"Deleting files in {BUCKET_NAME}/{DIR_NAME}") # 削除対象のpathを指定(ワイルドカード対応) blobs = list(bucket.list_blobs(match_glob=DIR_NAME)) bucket.delete_blobs(blobs) return
施策6 その他細かい削減
- 不要なテーブルは削除。
- 似たような処理をやっているテーブルは削除し1テーブルに統一しました。
- 過去に「もしかしたら使うかも」で作ったテーブルはすべて削除しました。
- 不要なCloud Monitoringの削除。
- Cloud Monitoringでアラートに対する課金が開始されます。(2025年1月から2026年4月に延期されました)
- これを機にアラートを吟味し30個ほど削除しました。
実施後
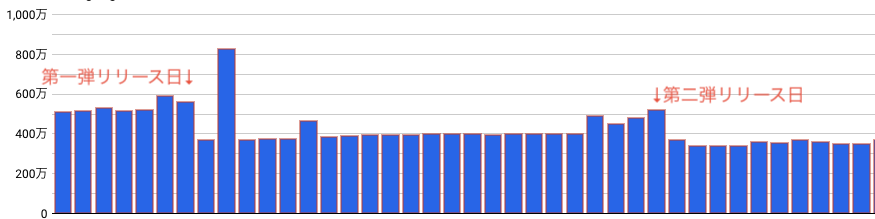
実施後、LookerStudioで効果量を計測したところ、下記のようになりました。
やはりリリース日はリソースを使ってしまいますが、リリース前後でだいたい1/4程度削減できたでしょうか。
具体的には1日5.6TBから3.6TB程度まで削減できましたので、効果としては約36%削減できました!
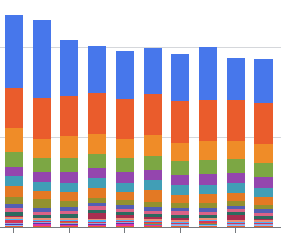
また、実施後の請求レポートでも、BigQueryの料金が下がっていることが確認できました! (GCSの削減は実施前なので反映されていません)
おわりに
今回の料金削減施策を実施してみて、個々の処理は大変なものではなかったものの、全テーブルを精査し対応するのは非常に手間のかかる作業でした。日々コスト意識を持って運用しておけばよかったなと痛感しました。
また、今回実施した施策以外にも、料金削減の方法はさまざまなものが存在します。これからも新たな削減方法を取り入れ、コスト削減していきたいと思います。
最後までお読みいただき、ありがとうございました。今後の運用に役立てていただければ幸いです。
