
Introduction
Hello, we are Jun Takahashi and Takuto Sato from the Artificial Intelligence Laboratory at Fujitsu. We participated in the international Agentic AI competition, the AgentX AgentBeats Competition, and won 2nd place. This post introduces our work for the competition.

What Is the AgentX AgentBeats Competition?
The AgentX AgentBeats Competition *1 is an international competition for Agentic AI, organized primarily by UC Berkeley RDI. As of February 2026, over 1,300 teams from around the world are participating in this competition.

In recent years, research on Agentic AI centered on LLMs has rapidly progressed. Agents are no longer limited to single-turn question answering; they can perceive context, plan, and execute multiple actions, which makes them well-suited for real-world deployment. In many conventional benchmarks, task execution, result collection, scoring, and visualization have been done manually or via scripts.
A key feature of this competition is that it uses the AgentBeats platform, which is based on the concept that evaluation agents conduct a consistent process from task presentation through execution management, result collection, to score calculation. AgentBeats connects and manages the Green Agent (which performs evaluation) and Purple Agent (which is being evaluated) on a common open protocol, providing integrated support for evaluation execution, log observability, and visualization of results via leaderboard. This enables standardized, reproducible, and transparent agent evaluation close to real-world operations, independent of differences in agents' internal structures, control methods, or multi-agent configurations.*2

The competition proceeds in these phases:
- Phase 1: Build the evaluation agent (Green Agent)
- Phase 2: Build the evaluated agent (Purple Agent)
We have been building and releasing FieldWorkArena, an Agentic AI benchmark for field-work support. In this competition, we entered the “Multi-agent Evaluation” track in Phase 1 with a FieldWorkArena-based evaluation system.
What Is FieldWorkArena?
FieldWorkArena is an Agentic AI benchmark for field environments such as manufacturing, logistics, and retail. It was developed through a joint research collaboration with Carnegie Mellon University (CMU), and is characterized by evaluation metrics and task design that anticipate real-world deployment of field-work support agents. The background of this initiative is introduced in the following Fujitsu official interview article.
Field-work support agents require multimodal understanding across images, videos, and documents; situational awareness including time and space; and judgment and reporting under ambiguity. FieldWorkArena is designed to evaluate these capabilities. For example, it can evaluate tasks like:
- "Is the safety equipment worn correctly?"
- "If there was a violation of the procedure, when did it happen and what was it?"
- "From what second to what second in the video was a specific action performed?"
These are highly field-oriented tasks. In this competition, we redesigned the Python-based evaluation code of FieldWorkArena as an evaluation agent (the FieldWorkArena Green Agent). More details on FieldWorkArena are available here. *3 *4 *5

FieldWorkArena Green Agent Architecture
System Configuration
The diagram below shows the FieldWorkArena Green Agent. The technical essence of this configuration is the agentified evaluation. The Green Agent is not just a script but a stateful agent. It checks user API keys, retrieves multimodal data from Hugging Face depending on the task, distributes tasks/queries/data to the Purple Agent, obtains and evaluates results, and updates the leaderboard. The interaction between the Green Agent and the Purple Agent uses the open Agent2Agent (A2A) protocol for inter-agent communication.
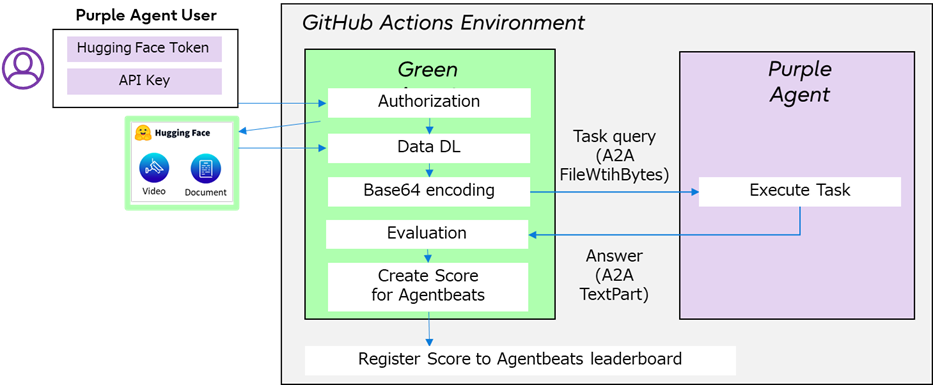
Automated Pipeline Centered on GitHub Actions
We use GitHub Actions as the evaluation execution platform. It builds Docker images for the Green and Purple Agents, runs evaluation tasks automatically, and updates the leaderboard based on each task result. This makes it possible to provide FieldWorkArena evaluation as a system that anyone can run any number of times under the same conditions, rather than relying on manual work.
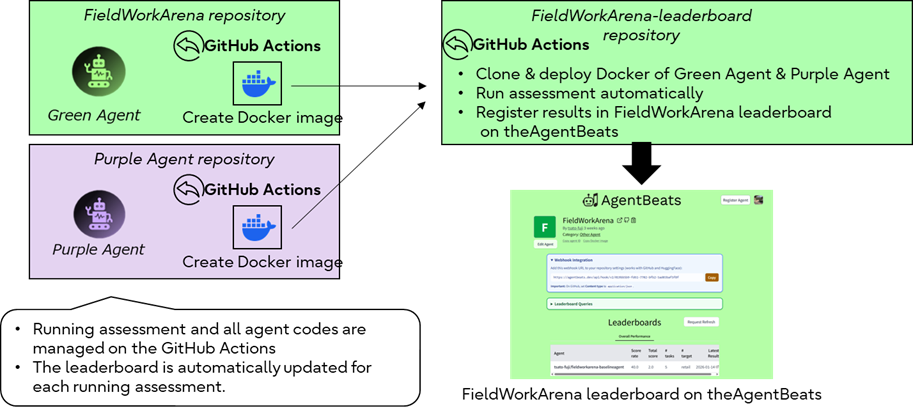
Challenges
FieldWorkArena contains many large multimodal assets, such as videos. Meanwhile, the competition initially did not define clear rules for handling such multimodal data. We therefore worked directly with the organizers to clarify which data could be used and how it should be handled. We later found that the competition environment imposes file size limits for inter-agent communication. Given this limitation, and the limited time and effort available during the competition, we excluded tasks that require large video data and narrowed the evaluation to tasks that could be executed.
In addition, to align with the concept of the competition, we had to build a pipeline that fully automates the process from evaluation runs to leaderboard updates using GitHub Actions. In this process, we also needed to add health checks and retry logic to reliably start and stop the two different agents, and to recover if an agent stopped during evaluation. This was not just experimental code that works, but a robust evaluation foundation for other teams to use, and it required the most time and effort.
Evaluation Criteria and Results
Competition Phase 1 was held from October 16, 2025, to January 31, 2026. Each submitted Green Agent was reviewed on the following dimensions:
- Goal & Novelty / Analysis
- Scope & Scale
- Evaluator Quality
- Validation & Quality Assurance
- Reliability
- Impact & Reusability
Our system was recognized for the real-world, multimodal, task-oriented nature of FieldWorkArena, its broad coverage of capabilities needed for field agents, and the fact that it was implemented as a working Green Agent on AgentBeats with an operational leaderboard. As a result, we achieved 2nd Place in the Multi-agent Evaluation track. The AgentX AgentBeats organizers announced that "while they cannot disclose the number of entries per track, the Multi-agent Evaluation track was among the top 10 most popular tracks by submissions. Being highly evaluated under such circumstances gives us strong confidence.
Of course, there are challenges. The system we submitted is limited in executable tasks due to the constraints of this competition. However, not only must we consider whether tasks can be executed, but we must also consider how to maintain the validity of the evaluation metrics and the value of the benchmark simultaneously. We believe that selecting "which tasks to prioritize for evaluation" should also be taken into account. We view these as areas for improvement and aim for further evolution.
Conclusion
This post introduced how our FieldWorkArena based agent evaluation system won 2nd Place in the AgentX AgentBeats Competition (Phase 1), along with its architecture and the challenges in development. Through this effort, FieldWorkArena evolved from "a dataset in a paper" into a "working evaluation agent". We believe this is an important step for future Agentic AI development in real-world operations.
The FieldWorkArena based Phase 2 competition (building the Purple Agent) will start on March 23, 2026. If you are interested, please give it a try.
