このたび、わたしlawofcyclesはopensearch-project/opensearch-hadoopのメンテナに就任しました。
Hadoopエコシステム、中でもSparkとOpenSearchをより良く結べるように努力していく所存です。
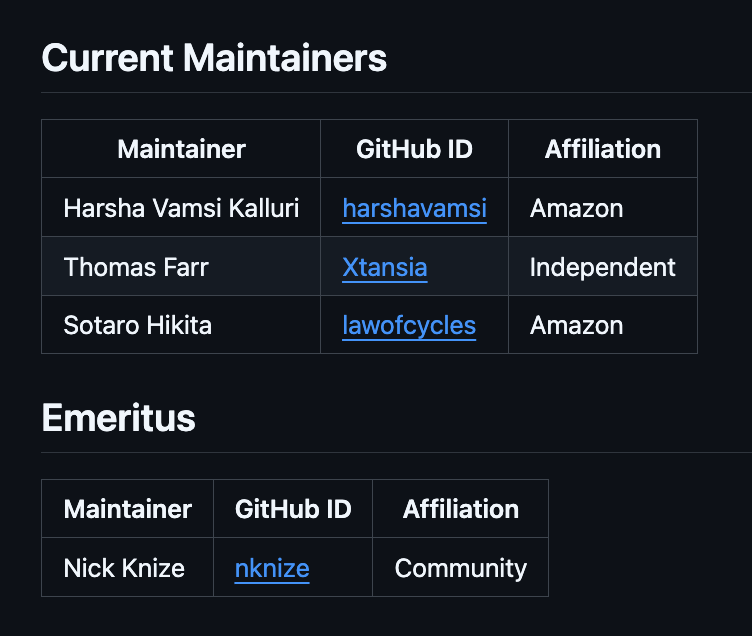
opensearch-hadoop/MAINTAINERS.md at main · opensearch-project/opensearch-hadoop · GitHub
opensearch-hadoopって?
opensearch-hadoopはOpenSearchのエコシステムを構成するコンポーネントの1つです。
OpenSearchプロジェクトはLinux Foundation傘下で運営されている、オープンソース(Apache-2.0 license)の検索・分析スイートです。2021年にElasticsearch 7.10からforkする形で誕生しました。
様々な構造のデータへの全文検索やベクトル検索、集計分析などが可能で、Webサービスの検索バックエンドからデータ分析、オブザーバビリティ、生成AIのナレッジベースまで多様なユースケースで活用できます。
github.com
OpenSearchプロジェクトは100を超える複数のリポジトリ/ソフトウェアの集合体です。
コアとなるopensearch-project/OpenSearchに加えて、indexを管理するopensearch-project/index-managementや、ベクトル検索を実現するopensearch-project/k-NN、Helm Chartを提供するopensearch-project/helm-chartsなど、多彩なリポジトリがあります。
https://github.com/orgs/opensearch-project/repositories?q=sort%3Astars
OpenSearch Hadoopはそんなリポジトリの1つで、Hadoopエコシステム、中でもSparkからOpenSearchへのindexingやsearchを行う際に利用できるクライアントライブラリです。
分散システムであるSparkと、これまた分散システムであるOpenSearch同士を効率的に連携させる仕組みを備えており、大規模なデータをOpenSearchに保存したり、取り出したりといったことが可能になります。
これによって、データレイク / レイクハウスに蓄積された構造化データの活用をSparkで実現している組織が、全文検索やベクトル検索といったユースケースを必要とした場面で、両者の世界を結ぶ役割を果たします。
Issueでの問い合わせを見ていると、AWS GlueやAmazon EMR, DatabricksなどのSpark環境で利用しているユーザーが多いようです。
OpenSearch Hadoopはニッチながらも根強い需要があり、昨今のSparkユーザーの増加や、Icebergなどのレイクハウスの広がり、更にはGenerative AI時代におけるSearchに対する需要の増加といった要素によって、今後更に役割を拡大していくものと信じています。
メンテナって?
OpenSearchプロジェクトに所属するリポジトリはLinux Foundationのポリシーに則ったガバナンスが敷かれており、リポジトリごとにMaintainerと呼ばれる管理者が任命されています。
メンテナの責務は多岐に渡りますが、一言でまとめるならば、「コードの品質とセキュリティを守りつつ、コミュニティと積極的にコミュニケーションし、プロジェクトを健全に前進させる」ことです。
https://github.com/opensearch-project/.github/blob/main/RESPONSIBILITIES.md#maintainer-responsibilities
新たなメンテナは既存メンテナによる推薦と投票で選出されます。
わたしは半年程度にわたってOpenSearch Hadoopの開発に取り組んでおり、先日メンテナへの推薦を打診され、了承しました。
わたしが開発した特に大きな貢献としては、Spark 4系のサポート、OpenSearch Serverlessのサポートなどがあります。
github.com
github.com
数えたところ、これまでに18のPRを送ってきたようです。
フィードバック、ご要望をお待ちしています
OpenSearch Hadoopはレイクハウスの時代において、これからも重要な役割を果たすプロジェクトであると信じています。一方で、まだまだ不完全な点が多いことも事実です。
当面の目標としては、OpenSearch3系の正式サポート、新バージョンのリリース、Spark DataSource v2サポートを目指す予定です。
もし皆さんの中に、MapReduce, Hive, SparkからOpenSearchを操作したい方がいらっしゃれば、ぜひフィードバックや要望をいただけると嬉しいです。リポジトリにissueを立てて頂いても構いませんし、Twitter等でご連絡いただくのもウェルカムです。
