OpenSearchCon North America 2025のセッション「Using OpenSearch as a Database With DataFusion」をまとめます。

スピーカー

このセッションは、OpenSearchコアメンテナーであるAWSのMark氏と、同じくOpenSearchコアメンテナーでLuceneコミッターでもあるUberのMichael Froh氏によって行われました。
Mark氏はセグメントレプリケーションやリーダー/ライター分離の開発に携わった人物で、Michael氏は検索パイプラインとワイルドカード・フィールド・タイプの実装を担当しています。
本セッションでは、OpenSearchにLuceneと並行して実行するベクトル化されたクエリエンジンであるDataFusionを導入する試みについて発表します。
要素技術の説明
Apache Arrow

Apache Arrowはインメモリのデータフォーマットです。
ネットワーク上も非常にうまく機能しますが、ストレージに永続化する形式としてはあまり意図されておらず、Arrowでディスクに書き込むことは一般的にはありません。DataFusionがRustで書かれており、OpenSearchがJavaで書かれているという状況において、言語に依存しないArrowの特性により、データをコピーすることなくシームレスに統合できます。これはゼロコピー形式として機能します。
そしてもう一つの重要な要素として、Arrowは列指向のデータ形式です。
列指向の利点
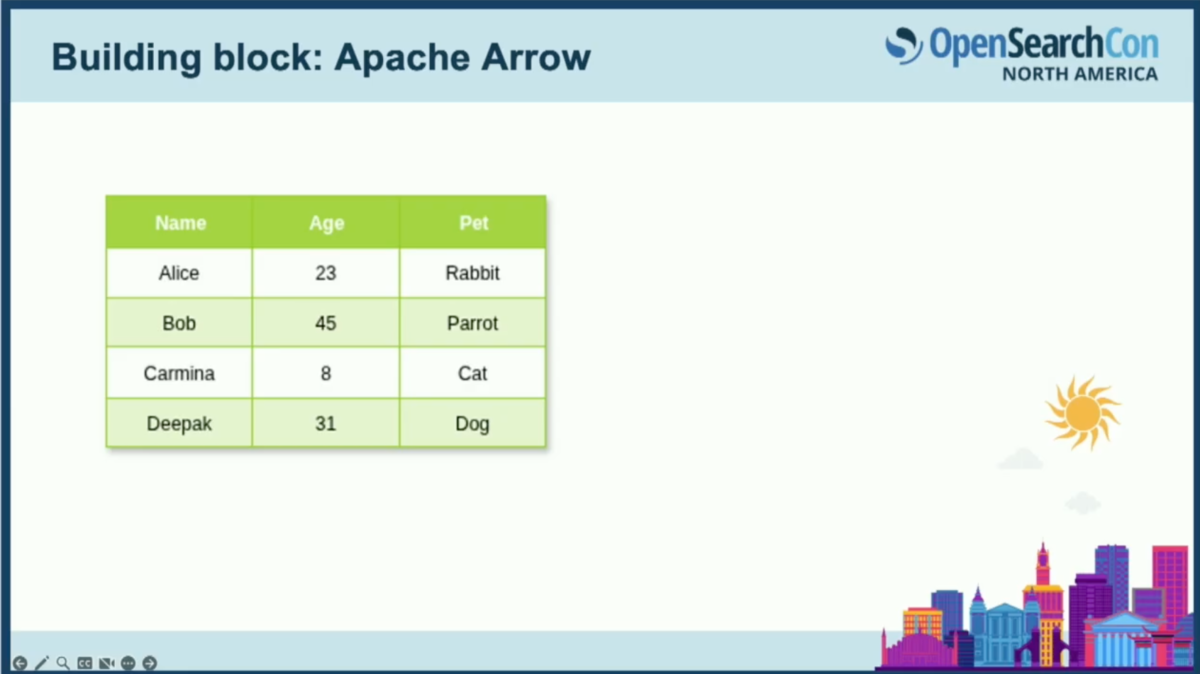
列指向とはどういう意味でしょうか。テーブル形式のデータを書き込む自然な方法は行ごとに書くことです。なぜなら、それがデータを挿入する一般的な方法だからです。しかし、Arrowは物事をカラムに分解します。名前カラム、次に年齢カラム、そして最後にペットカラムという形で格納します。
これが便利な理由は、多くの処理がカラムに対して行われるからです。where句やフィルターがある場合、通常は特定のカラムやフィールドでフィルターしています。例えば年齢フィールドに対して範囲クエリを実行する場合、これらの値は連続して格納されているため、複数の年齢値をCPUレジスタにロードし、SIMD(単一命令複数データ)命令を使用して、単一の操作で複数の整数をフィルターできます。最新のCPUはこの処理を非常に高速に実行します。
LuceneとArrowの列指向の違い

Luceneを知っている人なら「Luceneはすでに列指向ではないのか」と疑問に思うかもしれません。
たしかにLuceneは少なくともLuceneセグメント内では完全に列指向です。Luceneでdoc valuesを書き込むとき、フィールドがあり、そのフィールドのすべての値があり、次に次のフィールドとそのすべての値へと進みます。
一方、Arrowはデータをレコードのバッチに分解します。Parquetに詳しい方ならこれをRow Groupと呼ぶかもしれません。デフォルトでは、Arrowは1つのレコードバッチに8,192行を使用します。Parquetと比較すると、Parquetのデフォルトは1つのRow Groupに100万行だったと思います。
Arrowにおける列指向の価値は、データのカラムの処理と別のカラムのフィルターを交互に行いたい場合に現れます。Luceneの場合、複数のポインタをdoc valuesファイル内の非常に遠い場所を指すようにする必要があります。
一方、Arrowではレコードバッチ内に一連の行があるため、複数のカラムでフィルターする必要がある場合でも、あまり遠くに行かずに実行できます。
このデータ局所性は、CPUキャッシュラインに関してはそれほど違いを生まないかもしれませんが、データがリモートストレージに保存されている場合、Luceneではファイルの異なる部分からチャンクを読み取る必要があるのに対し、Arrowではレコードバッチ内にすべてがあるという利点があります。
ArrowとOpenSearchへのArrowの統合に関する詳細については、セッション「Accelerating OpenSearch With Streaming: Apache Arrow, Flight, DataFusion and gRPC」をぜひチェックしてください。
www.youtube.com
Apache DataFusion

DataFusionはRustで書かれた拡張可能なクエリエンジンで、インメモリ形式としてArrowを使用しています。数年前にArrowプロジェクトから生まれました。
これはすぐに使えるクエリエンジンでありつつ、各レイヤーをカスタマイズできるようになっています。現在、新しいデータベースを構築するためのツールボックスとして使用されており、DataFusionを使えば車輪の再発明を避けられます。また、既存のクエリエンジンを効果的に取り除き、Apache DataFusionに置き換えるクエリアクセラレータとしても使用されています。SparkアクセラレータのCometがその例です。
OpenSearchにはすでにLuceneあり、私たちはLuceneを愛しています。Luceneを置き換えるつもりはありません。
その代わりに、Luceneと並行して動作する補完的なものとしてDataFusionを導入しようとしています。DataFusionは、Parquetのようなデータソースをサポートしており、ローカルおよびネットワーク上のオブジェクトストアの両方で利用できます。
言語のフロントエンド、SQLパーサー、そしてクエリをプログラムで構築できる優れたデータフレームAPIも付属しています。クエリエンジンであるため、プランナー、オプティマイザ、およびエンジン自体が付属しています。
OpenSearchとの統合の観点で重要なのは、データソースに関してどのように拡張可能かという点です。
DataFusionの拡張性
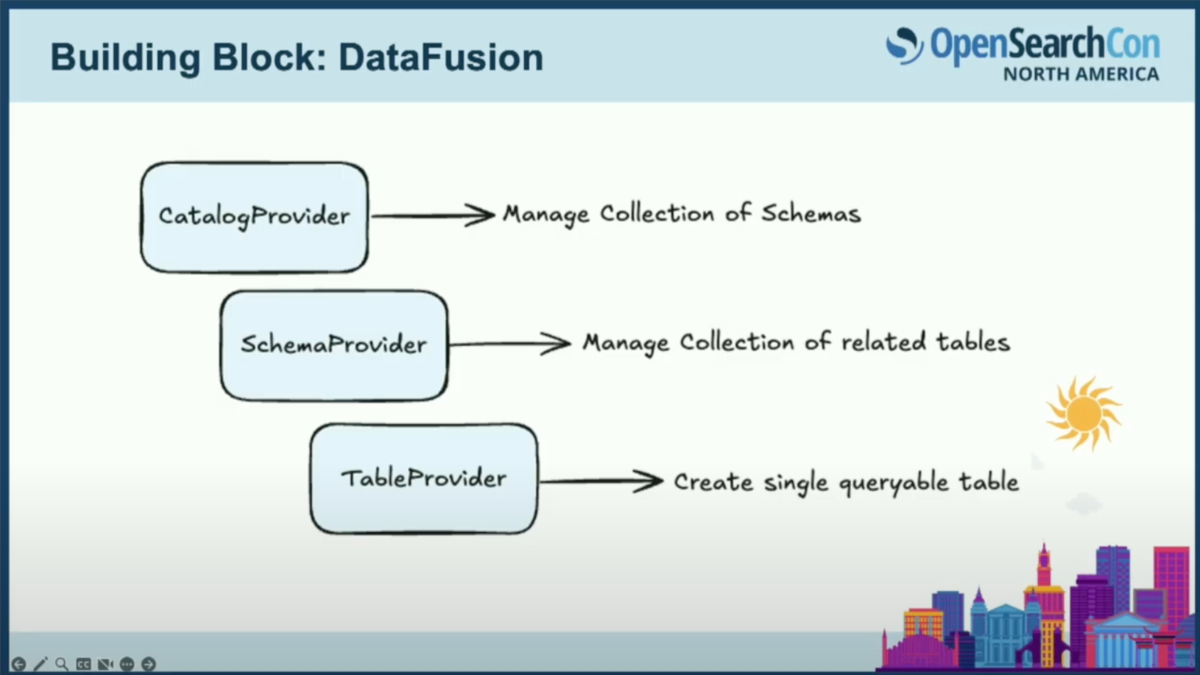
DataFusionには、単一のクエリ可能なテーブルを定義するためのRustのインターフェース、つまりトレイトであるテーブルプロバイダーが付属しています。これらをスキーマにまとめ、次にカタログにまとめることができます。これは一般的なデータベースの用語と似ています。
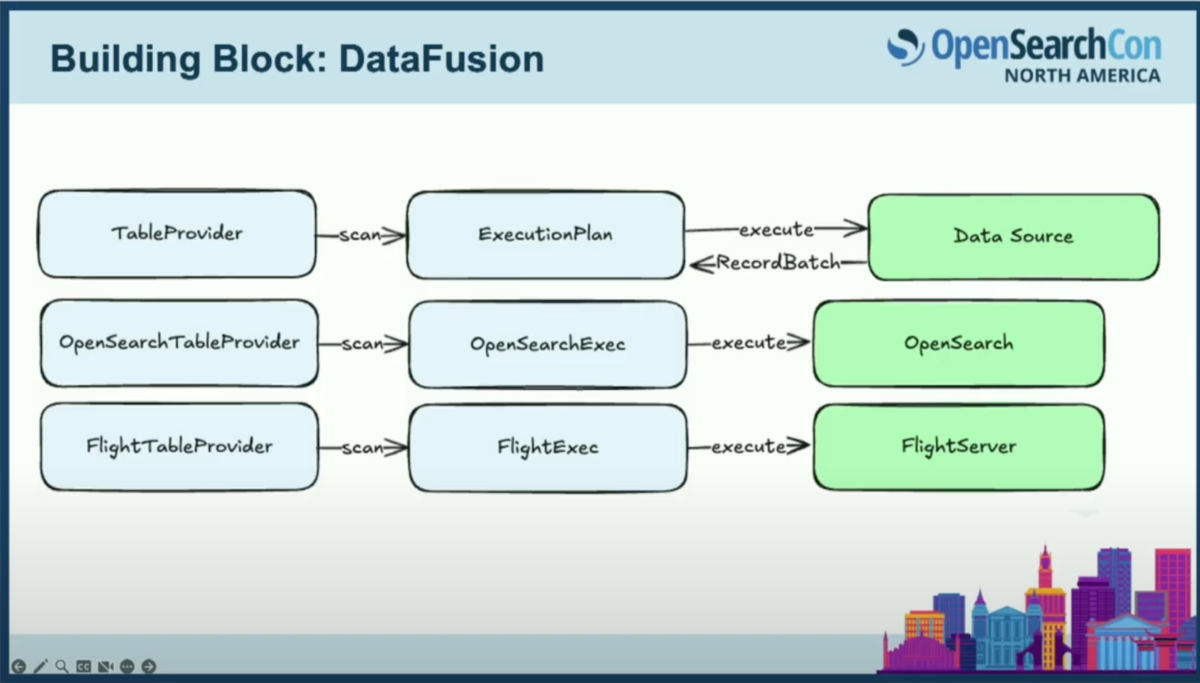
プロバイダー自体を定義し、そのスキャンメソッドで、ソースからデータをフェッチするための物理的な計画、つまり実行計画を返す必要があります。
私たちの検証では、OpenSearchからデータをフェッチするための独自のテーブルプロバイダーを定義しました。また、集約については、ネットワーク経由でデータをフェッチするために、コミュニティが構築したフライトテーブルプロバイダーを使用しています。
現在のOpenSearchにおける集約処理
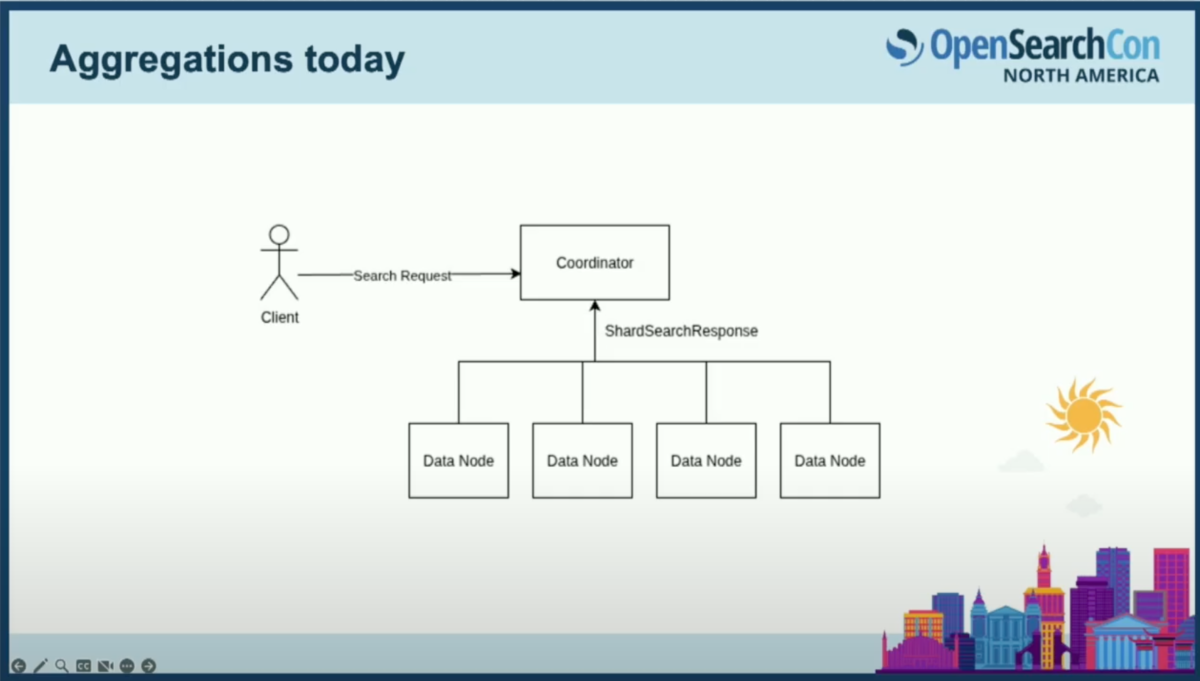
集約にDataFusionをどのように適用するかを説明する前に、まず今日のOpenSearchでの集約がどのように機能するかを見ていきます。
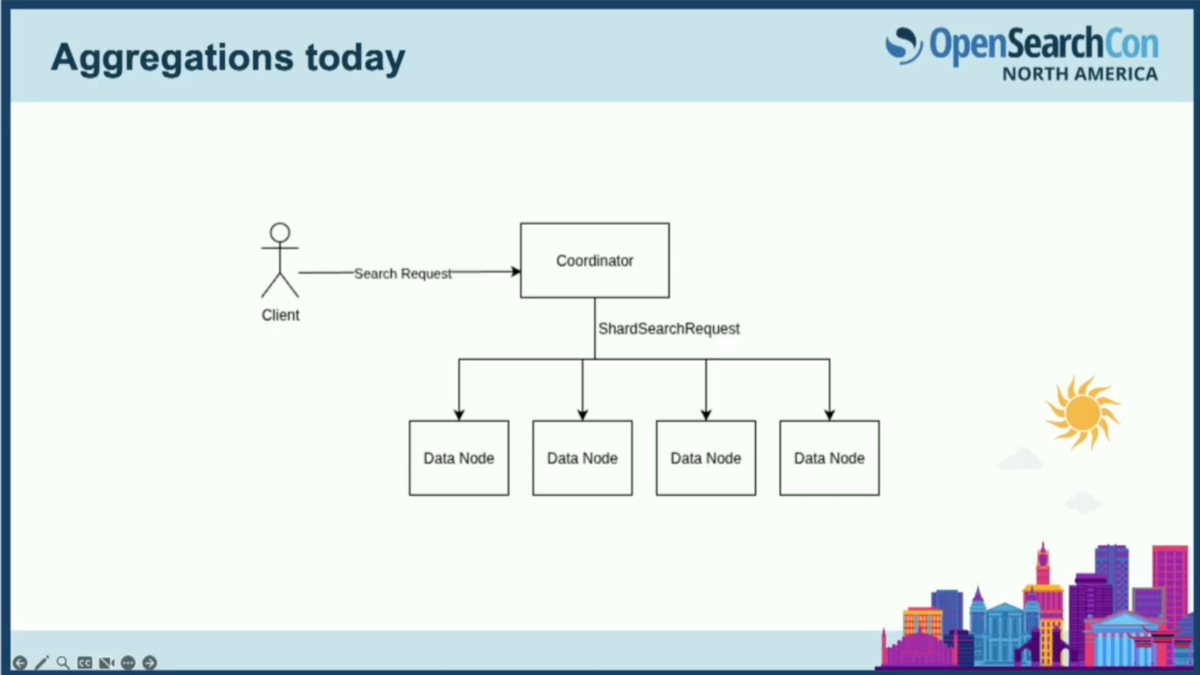
OpenSearchでの一般的な検索リクエストの流れから説明します。クライアントがノードに検索リクエストを送信すると、この検索リクエストの目的のために、そのノードがコーディネーターの役割を担います。
コーディネーターは検索リクエストを調整し、データノードのシャードにファンアウトすることによって処理を行います。
その後、各データノードが実際の集約処理を行い、シャード検索応答を返します。それをコーディネーターが単一の検索応答にまとめ、クライアントに返送します。
ここで、コーディネーターがシャードに呼び出すフェーズが複数ある場合もあります。ドキュメントを検索している場合、最初にシャードにファンアウトし、一致するドキュメントIDを取得します。reduceフェーズでそれらを照合し、上位のドキュメントを取得し、その後ドキュメント自体をフェッチしに戻る場合もあるためです。
しかし、集約について話している今回の議論では、通常は単一のフェーズ、つまりクエリフェーズですべてが処理されます。
ここでの説明のポイントは、コーディネーターはあまり多くのことをしないということです。シャード検索リクエストを送信した後、ほとんど待機しているだけです。そして、最終的なreduceフェーズの計算コストは非常に安価です。
データノードでの集約処理

データノードで実行される集約の例を見てみましょう。
18歳から35歳までの人々を対象とした集約リクエストを検討します。彼らがどのようなペットを飼っているかを集約して、この年齢層で最も人気のあるペットを見てみましょう。
まず、クエリを実行し、年齢フィールドでフィルタリングします。この範囲クエリがフィールドに適用され、範囲クエリがビットセットを返します。これにより、一致するドキュメントIDが得られます。
これらのドキュメントIDに基づいて、ドキュメントを段階的に収集していくと、アグリゲーターがPetフィールドを読み取ります。これらの数字はペットの種類としては非常に奇妙に見えるかもしれませんが、実際には、インデックス時に構築された辞書への序数にすぎません。
この辞書から最大序数が6であることを知り、真のプログラマーなので0から数えるため、サイズ7の配列を割り当てます。そしてドキュメントを段階的に処理しながら、これらの値を読み取り、バケットの数を増やしていくことで集約します。
最後に、リクエストの応答をコーディネーターに送り返す前に、辞書のルックアップを行う必要があります。これらの序数はシャードに固有です。厳密には序数はLuceneセグメント固有ですが、シャード内にはグローバル序数と呼ばれるものがあり、セグメントごとのすべての序数が1つの大きな辞書にマージされます。
データノードのメモリの課題

データノードがすべての作業を行い、重い処理を行うことの欠点は何でしょうか。集約に使用される配列はJavaヒープに割り当てられます。先ほどの例はサイズ7の小さな配列でしたが、フィールドのカーディナリティが非常に高い場合、より大きな配列を割り当てる必要があります。
ほとんどの人は、1つのリクエストにつき1つの集約だけを行うわけではありません。多くの場合、複数のネストされた集約を行っています。バケットの数は潜在的に非常に大きくなる可能性があります。集約をネストすると、通常はバケットの積集合、つまりカルテシアン積を行います。そのため、バケットの数が非常に大きくなり、集約はOpenSearchのヒープ使用量の主要な要因となっています。
Lucene自体は、検索時にヒープをほとんど使用しません。インデックス作成時にはヒープを使用しますが、検索時にはLuceneはほとんどヒープを使用せず、非常に効率的です。
より大きなヒープを割り当てることは、JVMがそのメモリをオペレーティングシステムから奪うことになり、オペレーティングシステムがファイルをキャッシュするために利用できるメモリが少なくなります。ファイルをキャッシュしない場合、ディスクからファイルを読み取る必要があり、非常に遅くなります。これが解決しようとしている問題の概要です。
OpenSearchのメモリ使用量、ヒープの割り当て量、ガベージコレクションがヒープに与える影響についての詳細は、セッション「Digging Into OpenSearch’s Memory: Lucene and JVM Garbage Collection Under the Microscope」をチェックしてください。
www.youtube.com
OpenSearchTableProviderの実装
DataFusionのテーブルプロバイダーの議論に戻り、OpenSearchでどのように使用されるかを見てみましょう。
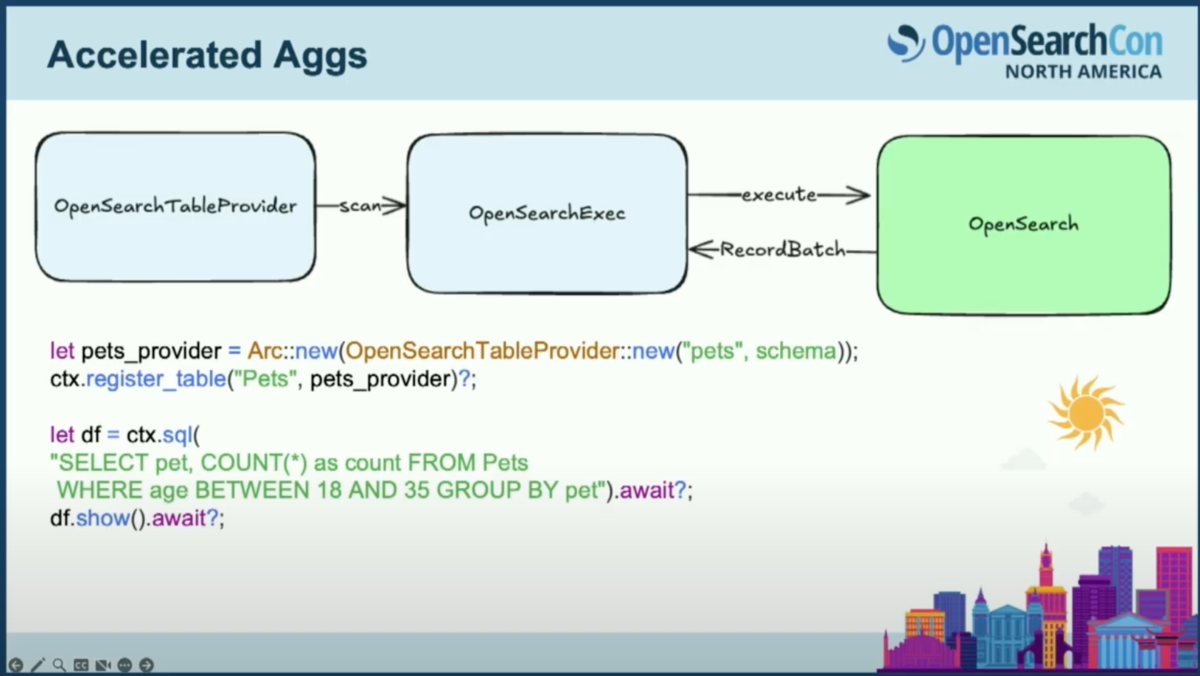
OpenSearchにクエリを実行し、Arrow形式で値を取得する実行計画を定義します。
そして、セッションコンテキストに登録します。これはクエリの実行と構成の定義のエントリポイントです。ここにpetsインデックスがあり、スキーマを渡していることに注目してください。そして、それに対してクエリを実行できるようになっています。
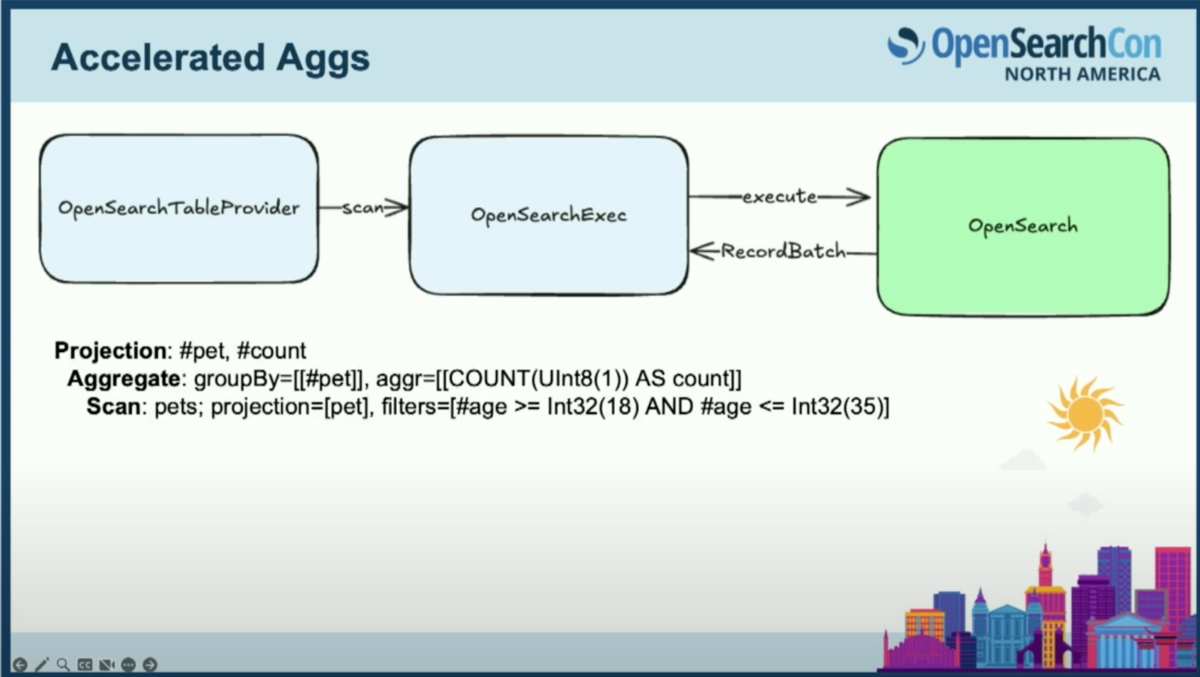
クエリが実行されると、ロジカルプランが作成されます。スキャンノードに注目してもらいたいのですが、ここでは、その実行中にLuceneクエリ、またはOpenSearchへのクエリに変換されるフィルターとプロジェクションをプッシュダウンしています。
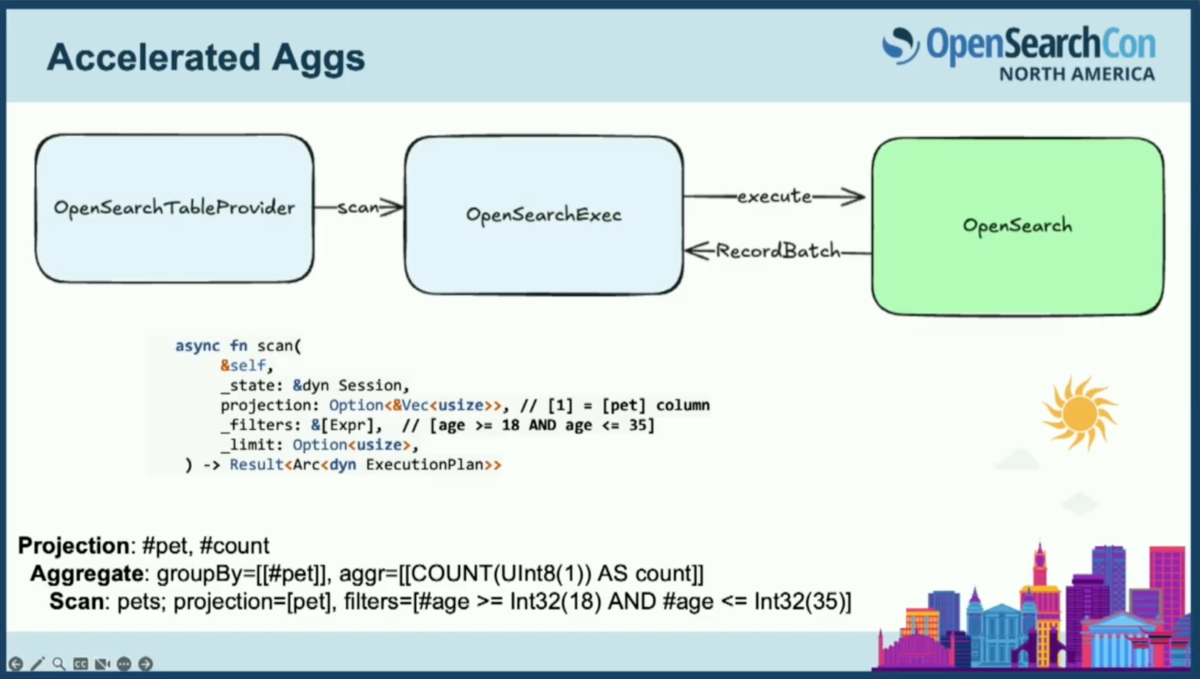
この例では、年齢が18歳から35歳までの範囲フィルターと、ペットカラムのみに関心があるというプロジェクションが見えます。
エグゼキュータの詳細
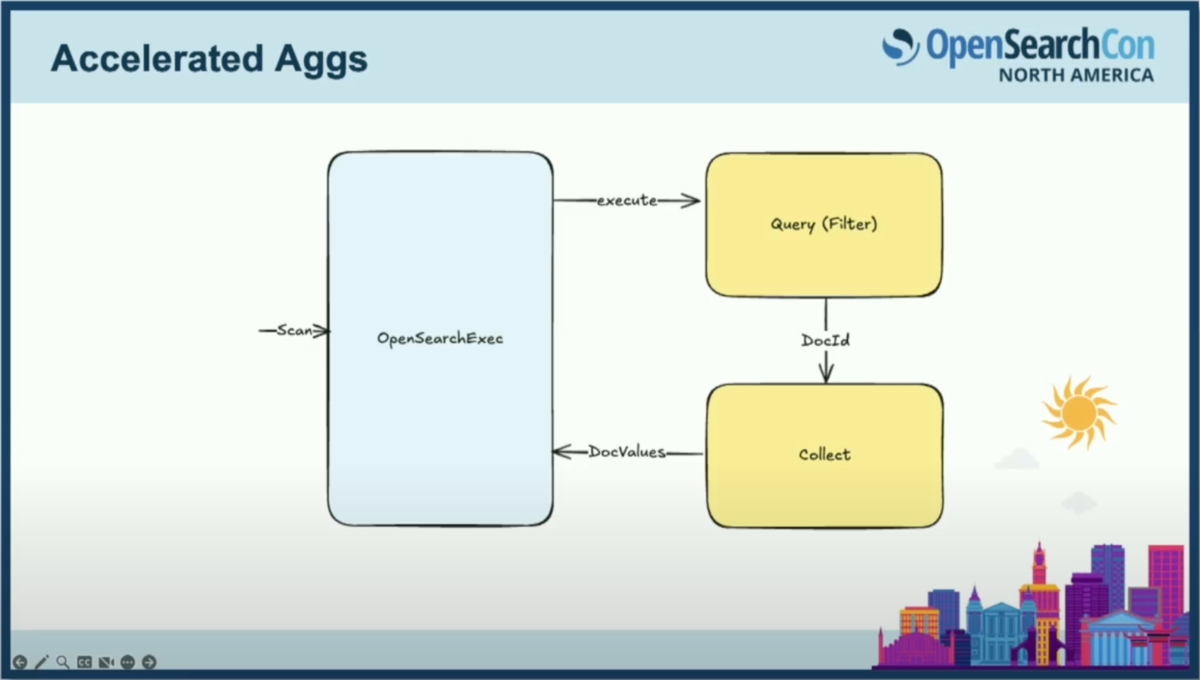
エグゼキュータ側をもう少し詳しく見てみましょう。実行中にJNI境界を越えてOpenSearchにコールバックするような仕組みを想定しています。クエリの形式がSQLの場合、実際にはDSLに変換して、Luceneクエリとして実行する必要があります。
今日行っていることは、各ドキュメントIDに対してコレクターでcollectを呼び出すことです。今後は、それらのドキュメントIDをすべて配列に効率的に収集し、バッチが完了したら、実際のドキュメント値の検索をフィールドごとに行い、それらを個別のベクトルに書き込んでDataFusionに送り返すような実装を考えています。
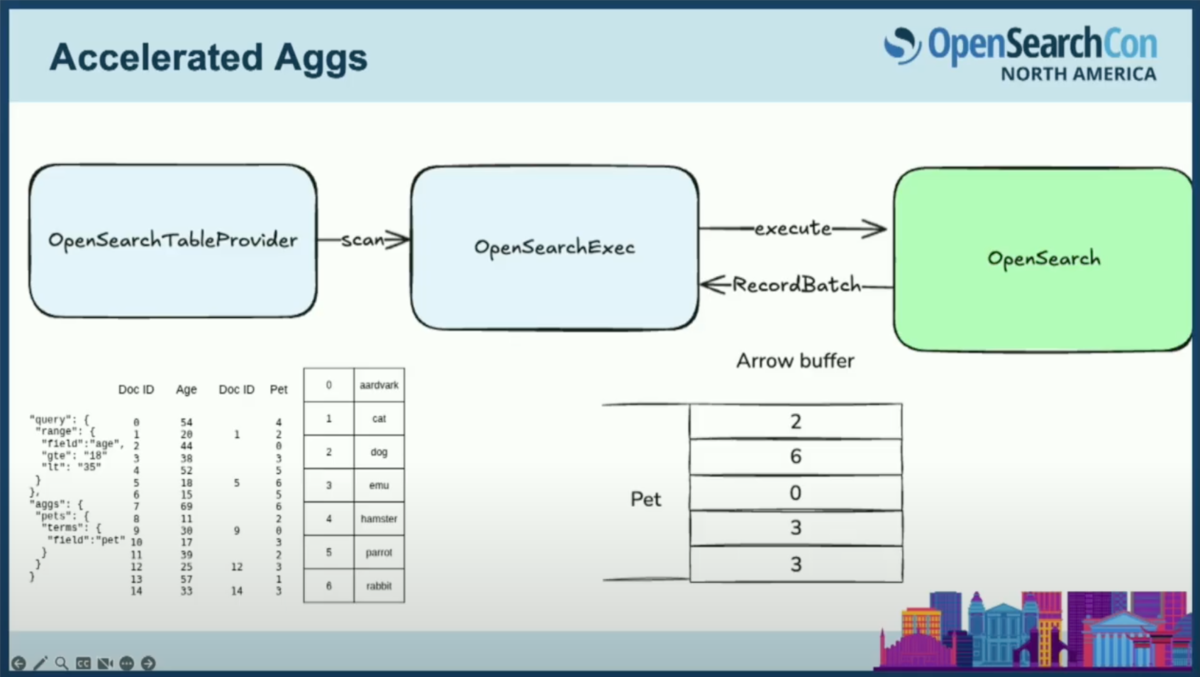
これはArrowバッファを受け取ったときに実際にどのように見えるかを示しています。
先ほどの説明の序数をイメージすると良いでしょう。コレクターでベクトルスキーマを定義するときに、同じ辞書を定義できます。そうすれば、DataFusionは集約のすべてのバケットを計算した後、それらを自動的に変換することを認識します。
クラスター全体での挙動と実験結果
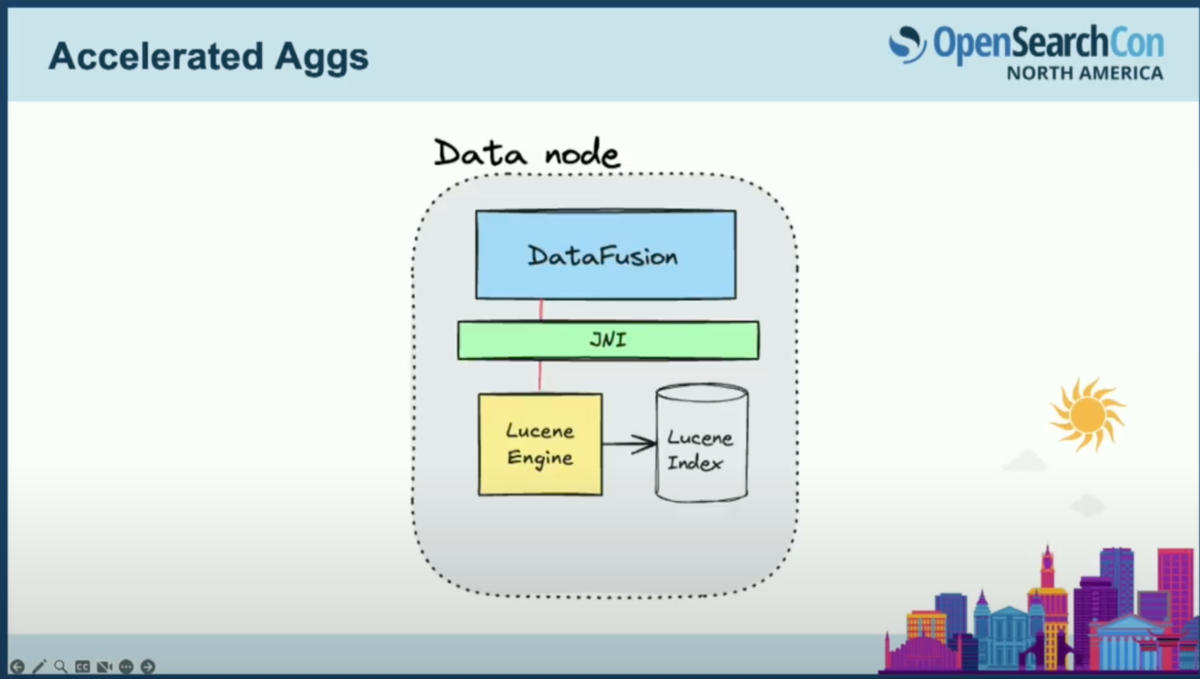
では少し引いて、データノードでこれが実際にどのように機能するかを見てみましょう。エントリーポイントはDataFusion実行エンジンになります。
データノードでの実装を見ると、エントリーポイントはDataFusionの実行エンジンになります。JNI境界を越えてLuceneに入り、クエリを実行し、ドキュメント値をArrowで直接取得し、ゼロコピーで返します。
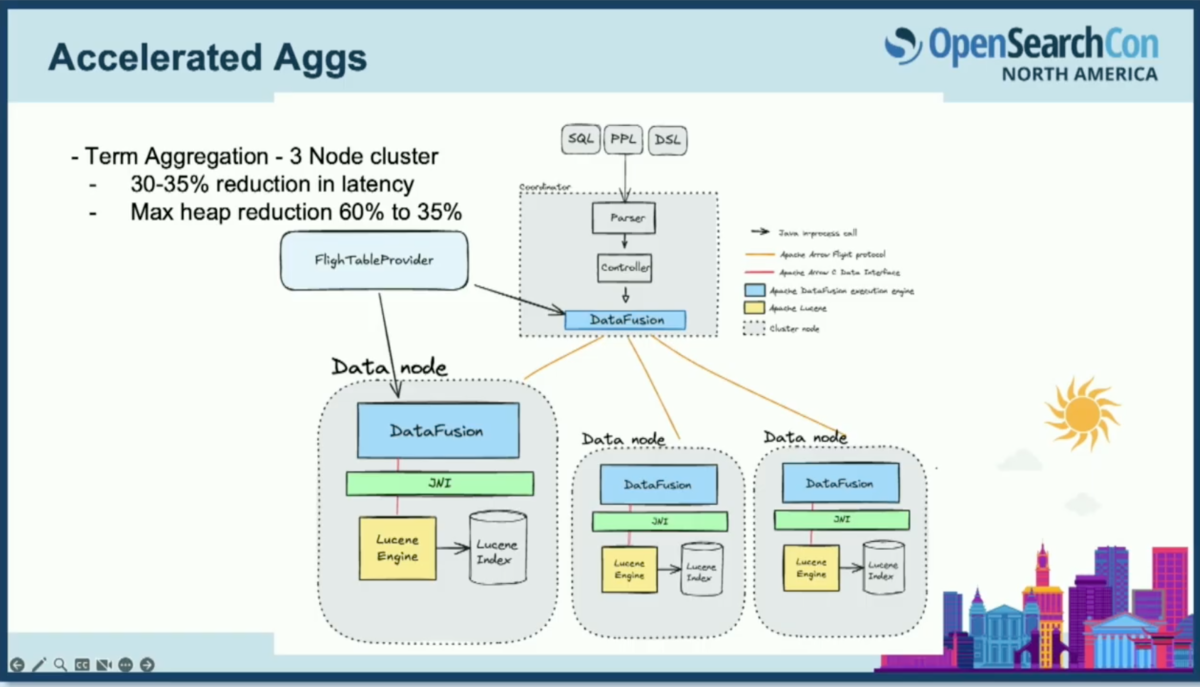
クラスター全体でこれを見ると、データノードから作業の一部をコーディネーターで実行するように引き剥がすことが目標です。
フライトテーブルプロバイダーを使用し、実験では、クエリしていたインデックスの各シャードを個別のパーティションとして扱いました。
実験の結果、Big 5で実行していたターム集約のレイテンシーが約30〜35%削減されました。また、P100のヒープ使用量が60%から35%に大幅に減少しました。
これは3ノードクラスターでの結果です。ヒープサイズを調整して、データノードのヒープサイズを減らし、OSファイルキャッシュの機能を増やすこともできますが、これは純粋にデフォルト設定での結果です。
このアイデアのRFCにリンクを貼っておきます。
github.com
Joinへの対応
まだ議論の段階ですが、理論的にはDataFusionでJoinも効率化できます。
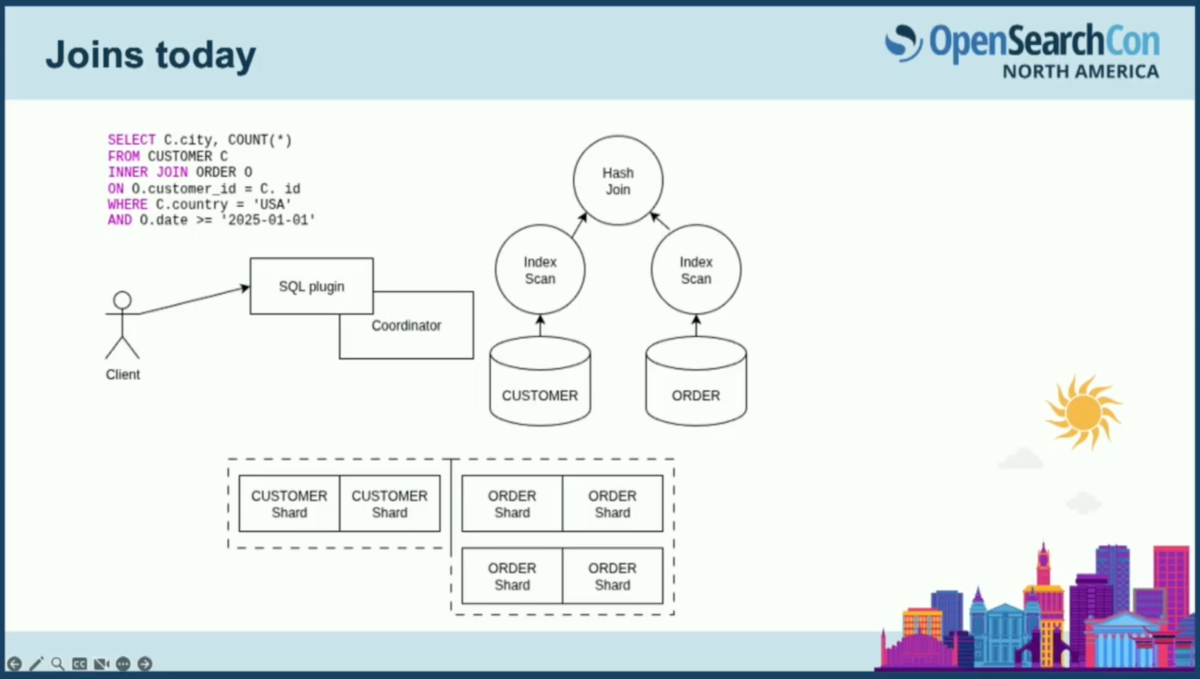
まず、OpenSearchで現在joinsがどのように機能するかを見てみましょう。一般的にはSQLプラグインが必要になります。
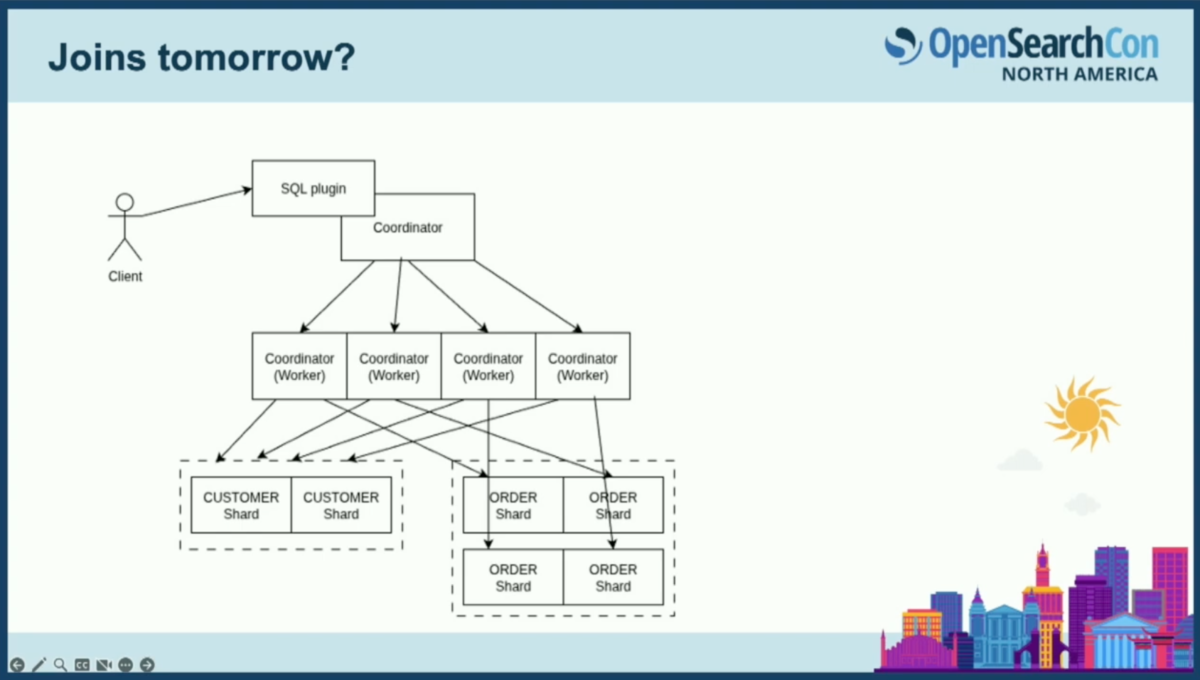
クライアント、コーディネーター、データノードの構成で、異なるインデックスからのシャードを結合する必要があるため、特定のシャードを図示しています。
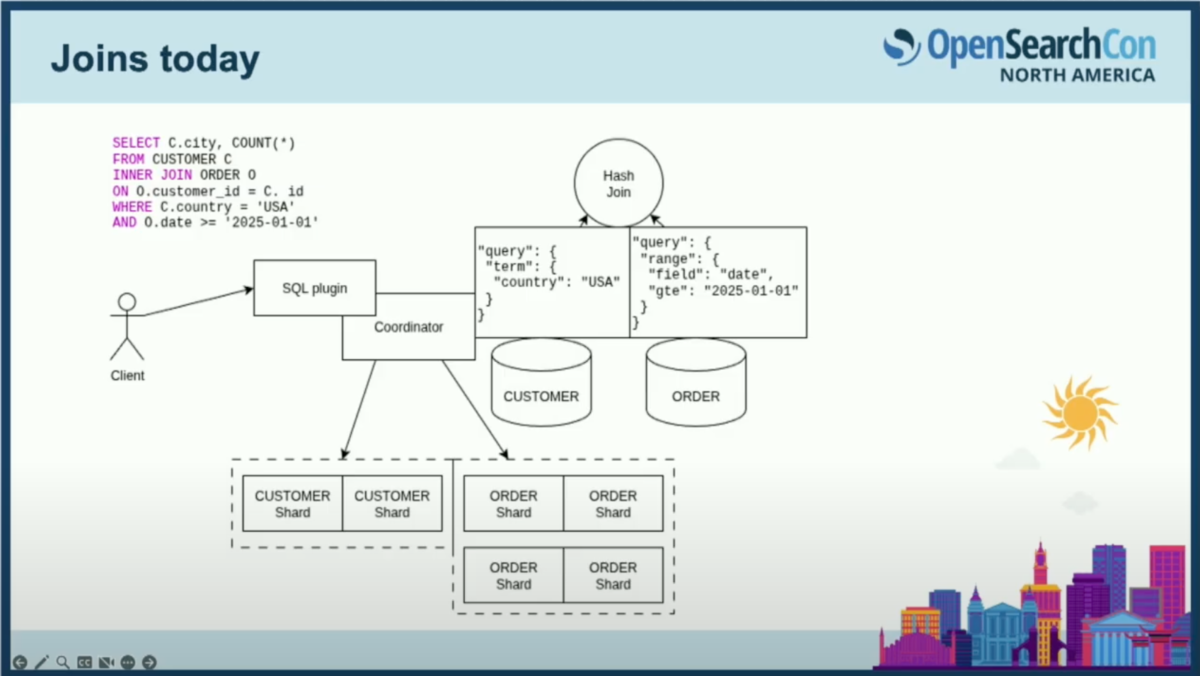
クライアントがSQLプラグインにSQLクエリを送信します。顧客と注文の間の簡単な結合を行う標準的なSQL結合の例です。顧客と注文の両方でフィルタリングしています。SQLプラグインはクエリ文字列を受け取り、実行計画に変換します。顧客と注文の両方のインデックスでインデックススキャンを行い、最終的に結果のドキュメントに対してハッシュ結合を行います。
インデックススキャンでは、特定のインデックスに限定されたwhere句を適用でき、それらをDSLクエリに変換してプッシュダウンします。SQLプラグインがこの処理を行い、2つのインデックスに対してクエリを実行します。
ここで、ハッシュ結合はコーディネーターで実行され、ハッシュテーブルのサイズが非常に大きくなる可能性があります。これが、重いSQLクエリの一部をSparkクラスターにオフロードする仕組みが存在する理由の一つです。ただし、別途Sparkクラスターをセットアップする必要があるという欠点があります。
DataFusionを使った分散結合の構想
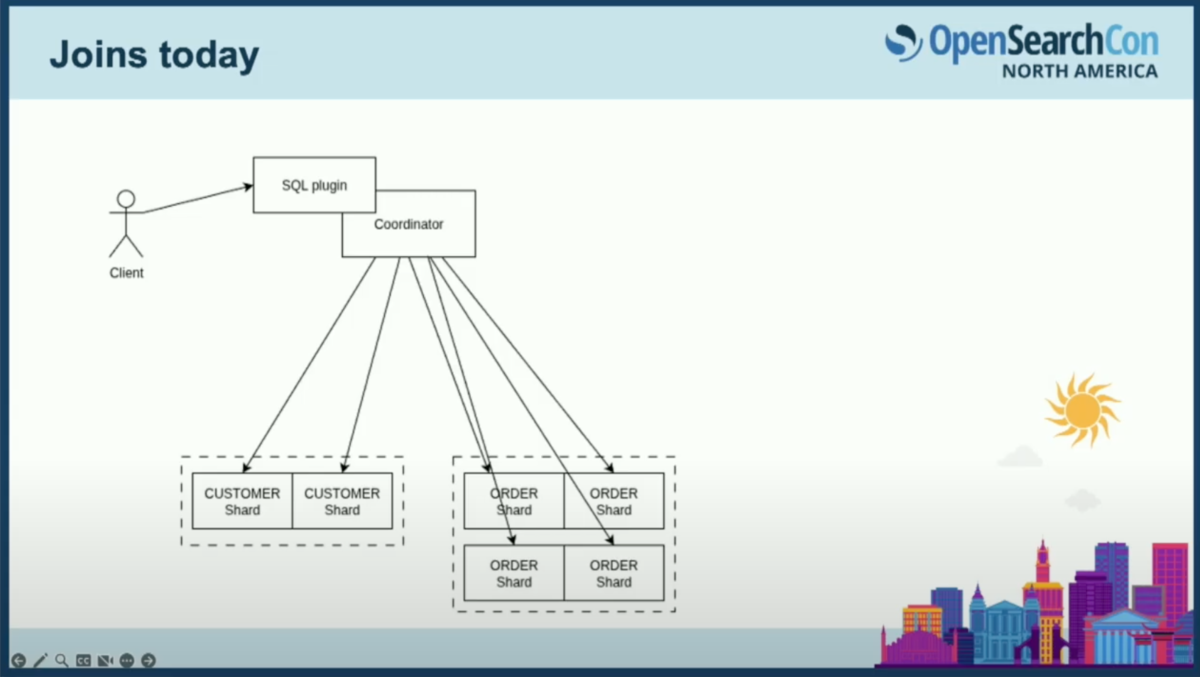
コーディネーターが2つのインデックスにアクセスする際、インデックスはシャードで構成されていることを思い出してください。顧客インデックスを注文インデックスと結合する場合、図では顧客インデックスに2つのシャード、注文インデックスに4つのシャードがあることを想定しています。実際にはもっと多くのシャードがありますが、スライドに1000個のシャードを収めるのは困難です。最終的にコーディネーターは、すべての顧客シャードをすべての注文シャードと結合することになり、この例では8つのミニ結合が実行されることになります。
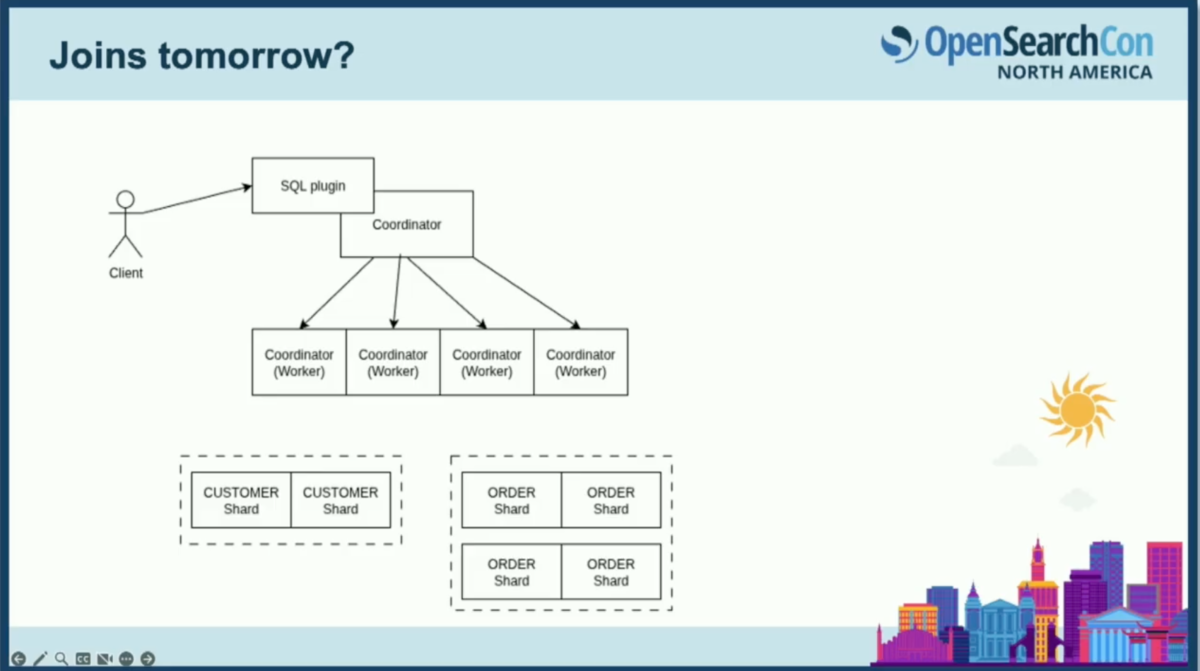
ここで、データを持たない純粋な計算ノードとしての、追加のコーディネーターノードを導入するアイデアを考えます。各ワーカーは注文シャードの1つを取り、それを2つの顧客シャードと結合するでしょう。ちなみに、実は講演の前に散歩に出かけた際、逆の順序で実行すべきだと気づきました。主キーで結合しているため、顧客シャードを1つだけ取ればハッシュ空間を半分に減らすことが保証されるからです。
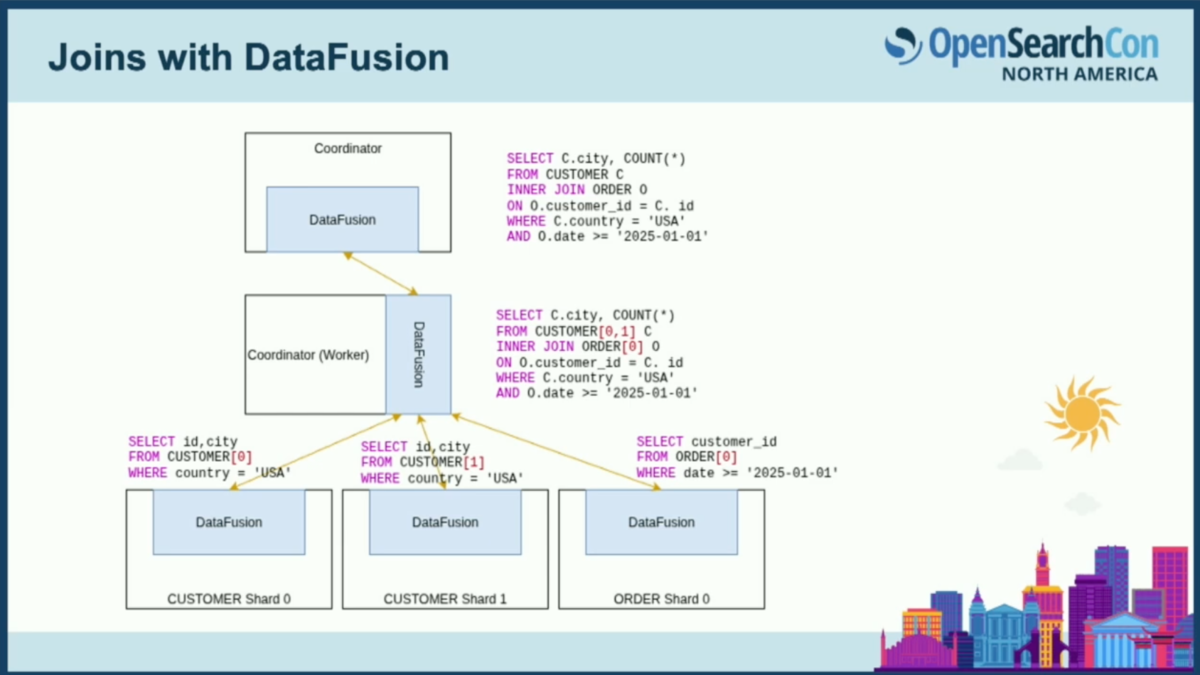
DataFusionでこれがどのように見えるか想像してみましょう。コーディネーターがSQLプラグインを保持し、引き続きSQLクエリを受け取ります。SQLプラグインはDataFusionを意識したプランを構築します。トップレベルのクエリを受け取り、ワーカーの1つに対して、どのシャードがヒットしているかを示すクエリをプッシュダウンします。ワーカーが顧客シャードと単一の注文シャードの両方をヒットしていると想像してみましょう。そのワーカーは個々のデータノードに作業をプッシュダウンし、個々のシャードに対してフィルタリングされたインデックススキャンを実行します。
ノード間のすべての通信は、フライトプロバイダーを使用します。データノードでは、OpenSearchテーブルプロバイダーを使用してシャードレベルのクエリを実行し、フライトストリーム経由で結果をストリームバックし、ワーカーでミニ結合を行います。すべてのワーカーがミニ結合を完了すると、部分的な結果をトップレベルのコーディネーターに渡し、コーディネーターはそれらをマージします。作業を分割できるわけです。
まだ実装していませんが、理論的にはDataFusionがあればかなり簡単になるはずです。OpenSearchでJavaでこのようなものを実装することはできますが、多くのコードを書く必要があります。DataFusionがそれを提供してくれます。これが私たちのビジョンです。
今後の展望
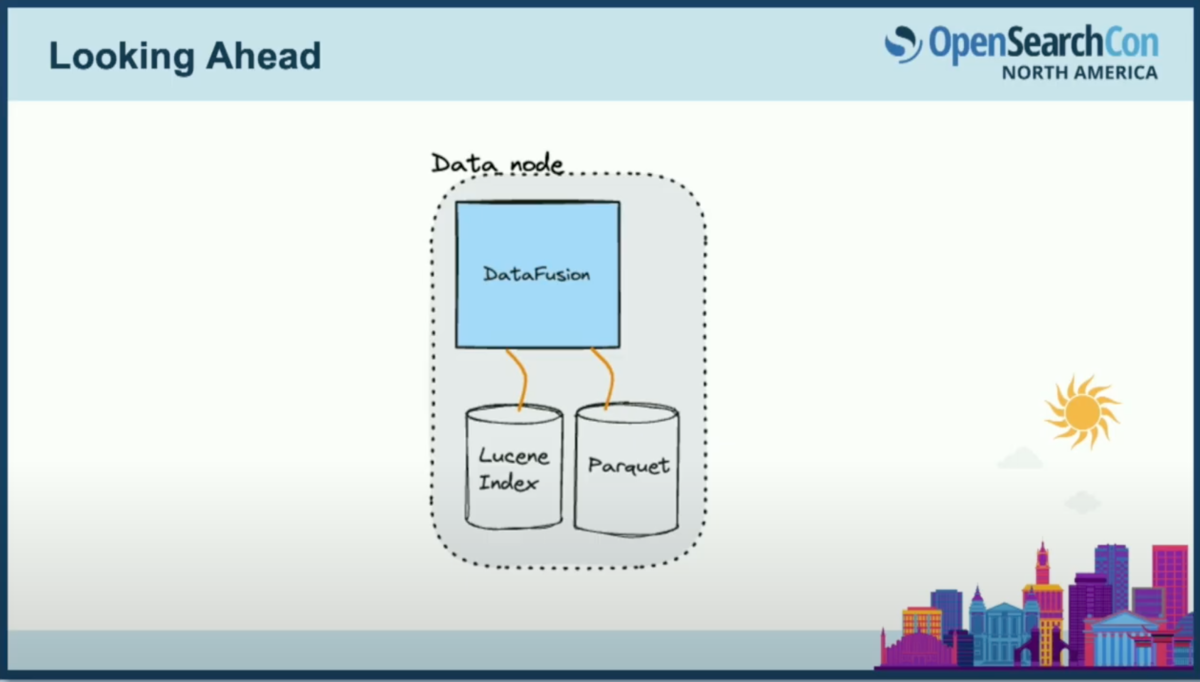
集約と結合のユースケースについて説明してきましたが、これでさらに多くのことができると考えています。コスト効率のために、Luceneインデックスの隣のデータノードにParquetファイルでデータを保存している場合、理論的にはLuceneからドキュメントIDを取得してそのParquetファイルと結合できます。あるいは、ファイルがオブジェクトストレージにある場合や、全く異なるデータシステムにある場合でも対応できます。これにより非常に興味深いユースケースが実現できると考えています。
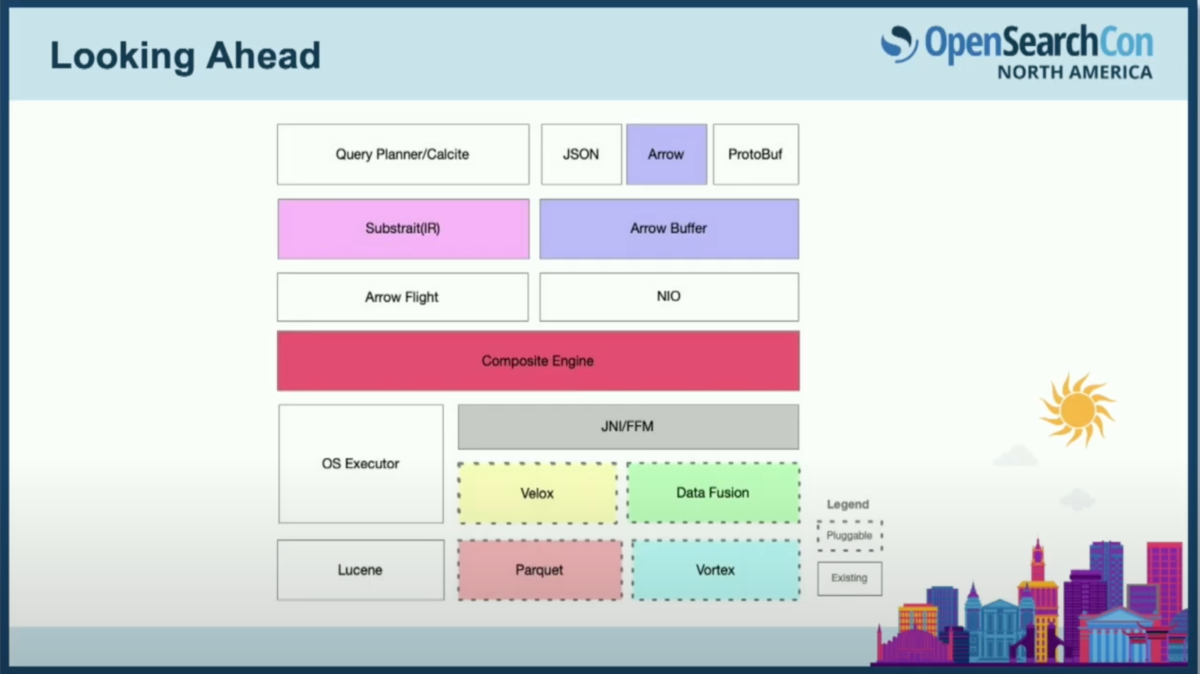
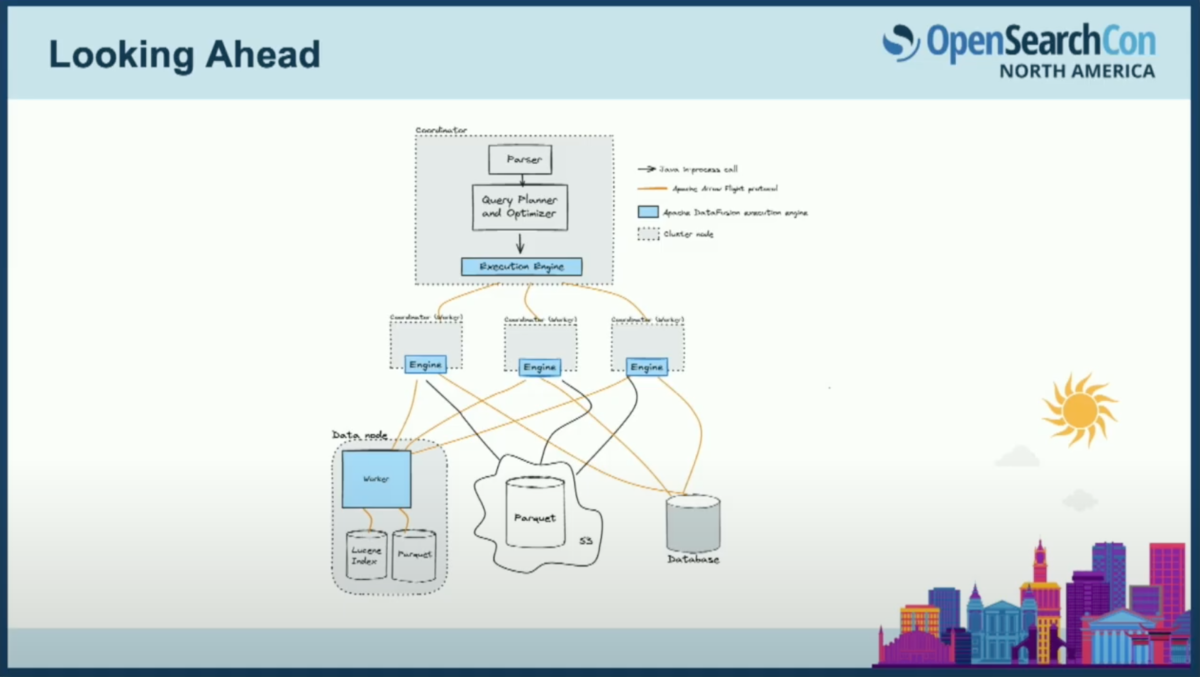
しかし、これをOpenSearchに導入するためには多くの作業が必要です。同僚から借用したこのスライドは、OpenSearchに導入しようとしている新しいコンポーネントの量を示しています。今日はCalciteを使ったクエリプランニングについては触れませんでしたが、SQLプラグインのPengと協力してCalciteを実装する作業が進められています。一般的なビジョンは、それを使用して論理プランをポータブルなIR形式に変換し、事実上どのエンジンにも渡せるようにすることです。今日はDataFusionについて多く話しましたが、理論的にはそれらのプランを読み取り、Arrow上で動作するならば、将来的に別の実行エンジンを代用または追加することもできます。
複合エンジンのコンセプトで導入を検討しています。インデックス構成に基づいて、クエリを実行する場所を把握します。それが今日のようなLuceneであるか、既成のエンジンであるかを判断します。これを導入し稼働させるには多くの作業が必要です。重要な点は、OpenSearchが今日Luceneと密接に結合していることです。当然のことで、Luceneは素晴らしいですが、それはどこにでもあります。それをすべてカプセル化し、新しいエンジンに交換するのは困難で時間がかかります。
他にも課題があります。タイプをどのように構成するのか、インデックスマッピングをArrowスキーマからDataFusionのスキーマにどのように接続するのか、DataFusionから返されるArrowベクトルを今日ユーザーが慣れ親しんでいるJSON応答にどのように変換するのか。特に結合の場合、計画の分割、つまり分散計画をどのように実装して、異なるデータノードでフラグメントを実行するのかという問題もあります。
まだ多くのことが残っており、皆様のご参加とご協力をお願いしたいと思います。2つのRFCをリンクしています。参加にご興味があれば、左側はよりハイレベルなアイデアで、右側は検索パスをもう少し詳しく説明しており、計画と実行について言及した具体的なエンジン実装までのアイデアが記載されています。
github.com
github.com
Q&Aセッション
質問1:SQLプラグインとの関係について
回答:これがSQLプラグインを強化する機会になると考えています。理想的にはユーザーには意識されない内部実装となります。DataFusionがすべてのノードで実行されるようになれば、SQLプラグインは計画と実行の一部としてDataFusionに作業をオフロードできるようになります。DataFusionの価値は、SIMD操作をArrowデータに対してネイティブに実行できる点にあります。Javaでこれを実装するのは非常に困難ですが、Rustで書かれたDataFusionはSIMD組み込み関数で実現できます。また、ツールボックスとして提供されるため、すべてをJavaで再実装する必要がありません。なお、SQLプラグインのパーサーなどをDataFusionに置き換える予定はなく、既存のものをそのまま使います。
質問2:これはオープンソースですか?
回答:はい、これはすべてオープンソースのOpenSearchプロジェクトの一部です。
質問3:DataFusionを分析に使うということですか?
回答:はい、それがDataFusionが得意とすることです。DataFusion自体は非常に強力で、TPCHベンチマークのような標準的なOLAPベンチマークで優れた結果を出しています。Parquetに保存されたデータがあれば、DataFusionで効率的に処理できます。DataFusionはクエリエンジンであり、データの永続化は行いません。理論的には、その上に独自のマテリアライズドビューのような概念を追加することは可能です。
質問4:JNI呼び出しのコストについて
回答:DataFusionとJava間のJNI呼び出しのコストは問題にならないレベルでした。以前、k-NN実装でも同様の懸念がありましたが、最近のJNIは非常に優れており、マイクロ秒単位のレイテンシーです。多くのケースでは、LuceneがインデックスをクエリしてArrowに供給し、それがDataFusionに渡されます。Parquetデータがある場合、DataFusionはネイティブに処理するため、余分なJNIホップを避けることができます。
質問5:実装の課題について
回答:最大の課題の一つは、どこにフックするかを正確に特定することです。OpenSearchは現在、これが自然に適合するような柔軟性をあまり提供していません。異なるノード間APIを作るか、既存のトランスポートアクションから離れてDataFusion同士で通信する仕組みを作るかなど、様々な選択肢を議論しています。これをプラグイン可能でオプトインにすることも課題です。リポジトリには、クエリプランナーの追加、結合、複数のデータソースのサポートなど、この件に関する3〜4つのRFCが公開されています。
質問6:ストリーミング集約のPRとの関連について
回答:関連しています。それは純粋なJava実装で、DataFusionなしでArrowだけで最小限のことを実現しようとするものです。明日の「Accelerating OpenSearch With Streaming: Apache Arrow, Flight, DataFusion and gRPC」で詳しく説明される予定です。
www.youtube.com
