OpenSearchCon North America 2024のセッション「Enabling Search on Databases with Data Prepper」を日本語でまとめます。 可能な限り正確に内容を拾えるようにリスニングに努めたつもりですが、もし誤りがあればご指摘ください。
OpenSearchCon とは?
イベントページ
各セッションはYouTubeで視聴可能
Enabling Search on Databases with Data Prepper
セッションリンクは以下.
スピーカー
- Taylor Gray
- Software Development Engineer at AWS
- DataPrepper メンテナ
- Dinu John
- Senior Software Development Engineer at AWS
- DataPrepper メンテナ

セッションまとめ
データベースへの検索の課題

データベースへの検索を行いたいユースケースがしばしばある、例えば、小売アプリケーションで製品情報、製品説明、レビューなどを保存し、それらを検索したい場合や、チケットシステムでテキストを検索したい場合、あるいはEHRアプリケーションで患者レポートなどを検索したい場合など。
RDBMSによる検索には以下の典型的な課題がある。
- 検索は構造化データの完全一致に限定されている。例えば、カラムを選択してID=123などと指定すると、それらのレコードを返すことができる。しかし、大量のテキストデータに対する性能は出づらい。
- 全文検索は遅く、大規模なデータセット用に最適化されていない。全文を保存する場合、通常はCLOBやBLOBデータ型、外部ファイルシステムに保存するが、データセットが大きくなるにつれ性能が悪くなる
- 非構造化データの処理が貧弱で、高度な処理ができない。例えば、トークン化やステミング、ストップワード検出などができない。一部サポートするデータベースもあるが、ドキュメントのサイズが大きくなったり、スケールすると良いパフォーマンスが得られない
- 複雑なクエリの処理が困難である。大規模なデータセットでジョインや集計を行うと、データセットが大きくなるにつれてボトルネックに達し、うまくスケールしない
- 関連性に基づく結果を提供することができない。重み付けされた結果や関連性に基づいた結果の返却ができない.
OpenSearchでできること

一方、OpenSearchは大規模なデータセットに対する低レイテンシーな高速ルックアップに最適化されている。内部的には転置インデックスを使用し、より速くデータを検索できる。クエリの書き換えも行われ、より速く結果を返すことができる。
全文検索に最適化されており、ステミング、ストップワード検出、トークン化を行い、インデックスに書き込むことができる。その上に関連性に基づく検索の仕組みがあり、非構造化データ全体で効率的に結果を提供できる。
加えて、TF-IDFやコサイン類似度などの異なる関連性ランキングアルゴリズムを設定でき、単に挿入されたレコードをそのまま返すだけではなく、コンテキストに基づいた結果を返却できる。
加えて高度なクエリ機能もあり、フィルタリング、集計、地理空間検索、あいまい検索などができるなど、非構造化データをインデックス化して、シームレスな検索を可能にする。これがOpenSearchの利点である。
Data Prepperについて
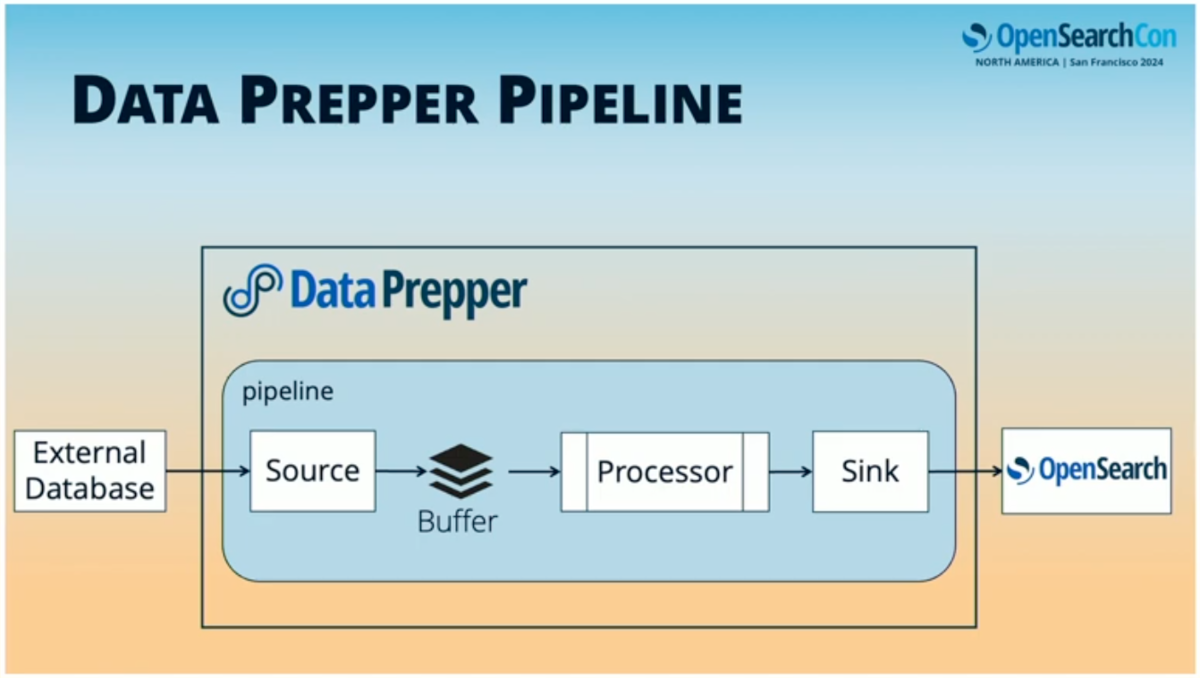
Data PrepperはOpenSearchプロジェクトのオープンソース取り込みパイプラインアプリケーションであり、多くの場所からOpenSearchにデータを取り込むことができる。
Data Prepperパイプラインを構成するコンポーネントは以下の通り。
- ソース: 検索機能を持たない様々なデータベース
- バッファ: OpenSearchに送信する前にデータを一時的に保持するメモリないしストレージ層
- プロセッサ: インライン強化、インライン変換、集計など、データベースからのデータをOpenSearchに送信する前に変更したい処理を実行する
- シンク: データの送信先。主にOpenSearchだが、プラガブルで、S3など他の送信先を持つこともできる
設定例

このYAMLでは、サンプルとなるデータソースに対してデータベース名、認証用のユーザー名、パスワードを設定している。プロセッサは日付プロセッサと不要なフィールドを削除するためのdeleteEntriesを使用し、OpenSearchインデックスパターンで使用可能な形式のタイムスタンプを追加している。
最後にシンクコンポーネントが設定されており、この場合はOpenSearchで、OpenSearchエンドポイント、送信先のインデックス、ユーザー名とパスワード、または必要な他の認証情報を入力する。
これがパイプラインを設定する際の簡単な例である。
Data Prepperのソースについて

Data Prepperに新しいデータベースソースを作成する際のポイントは以下の通り。
- プラガブルなデザインになっており、新しい統合を作成するためにOpenSearchについて詳しく知る必要はない。すでにOpenSearchシンクプラグインがあり、Data Prepper内にはすべてのプロセッサがあるので、データベースからデータを取得する方法だけを定義すれば良い
- スケーラブルである。水平にスケールし、異なる作業パーティションを多くのData Prepperコンテナ間で分散できるようになっている
- データベース統合のための共通パターンがある。一度のエクスポートの後にストリームを行う仕組みになっている。最初にデータベースのスナップショットを一度取得し、それをOpenSearch向けに処理し、その後何らかのCDCにつなぎ、ストリームを行う流れになっている。データベース内のアイテムへの新しい挿入、更新、削除はOpenSearchに直接複製され、これはほとんどの場合1対1のマッピングとなる
- Data Prepperが現在サポートしているデータベースソースには、DynamoDB、MongoDB、DocumentDBなどがあり、クラスター移行のユースケースのためのOpenSearchもソースとしてサポートしている
エクスポートとストリームパターンの流れ
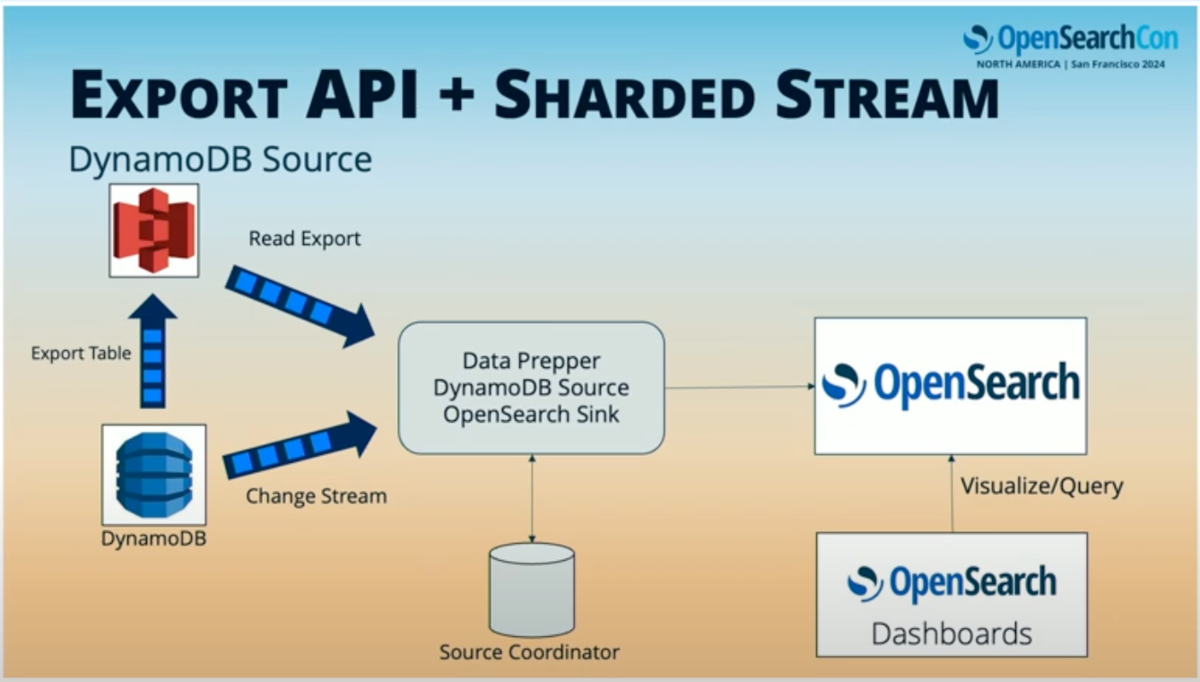
エクスポートとストリームのパターンを説明する。DynamoDBソースの場合、エクスポートAPIを使用できる。DynamoDBには、テーブルをS3にエクスポートするAPIがある。エクスポートが完了し、データファイルをS3に配置したら、Data Prepperはそれらのデータファイルを読み取り、各コンテナ間で分散処理する。
すべてのデータファイルが処理され、エクスポートが完了した後、DynamoDBのチェンジストリームに接続する。これらはシャード化されたストリームなので、シャードを異なるData Prepperコンテナ間で分散して、プロセスを並列化できる。その後、DynamoDBテーブルへの更新、削除、挿入はすべてOpenSearchに複製される。
エクスポートAPIが使用できないデータソースの場合
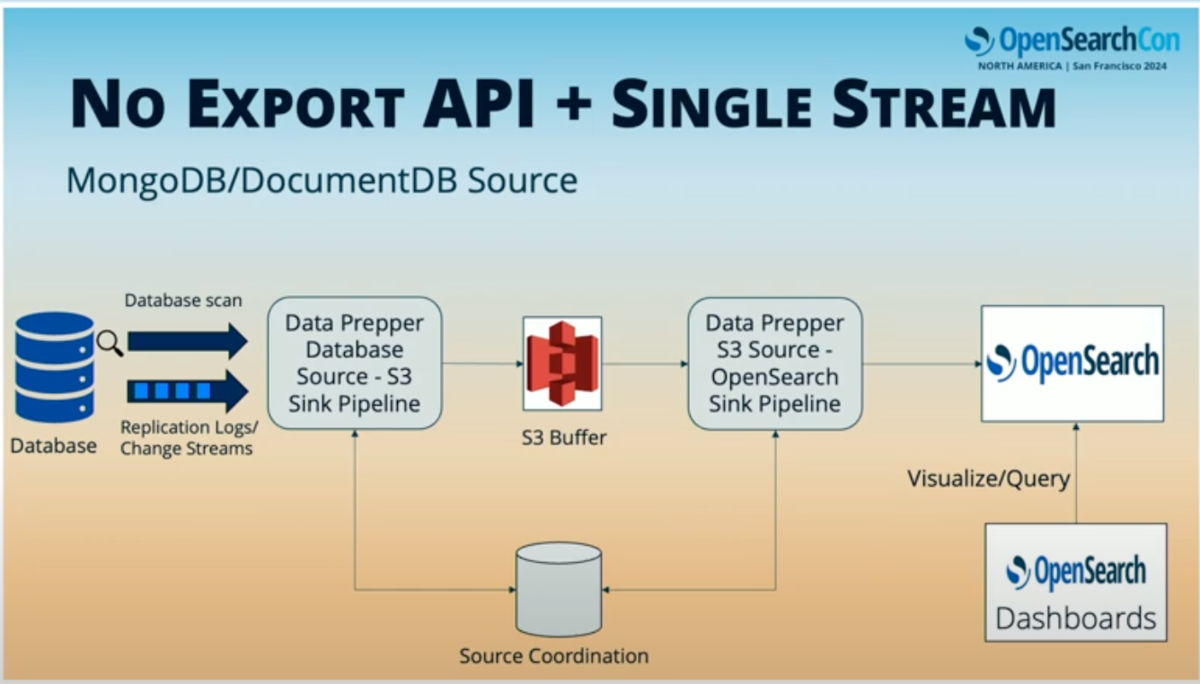
DynamoDBの場合、S3へのスナップショットの書き込みをサポートしているが、そういったスナップショットのエクスポートや、シャード化された並列読み取りをサポートしていないデータソースもある。
この場合、シーケンシャルにチェンジストリームを読み取る必要があり、二つのData Prepperパイプラインを使用する形になる。
最初のData Prepperパイプラインはデータベースをソースとし、S3をシンクとして使用し、データをS3に書き込み、バッファとして機能する。
二つ目のパイプラインはS3から読み取り、OpenSearchに書き込む。後に説明するSource Coordinatorを使用して、異なるワーカーの読み取り方法を調整し、パイプラインをスケールさせる。
このケースでは、リーダーが選出され、データベースをスキャンしてレコード数を見つけ、Source Coordinator内にパーティションを作成する。例えば、1000レコードがあれば10パーティションを作成し、各パーティションが100レコードずつ読み取る責任を持つ。
テーブルをスキャンし、最初のパイプラインに書き込みを行う。Data PrepperワーカーはSource Coordinatorからそのパーティションの所有権を取得し、スキャンを実行してS3バッファに書き込む。二つ目のパイプラインはS3バッファから読み取り、再びSource Coordinatorを使用してOpenSearchに書き込む。
スキャンが完了すると、レプリケーションログに接続する。DynamoDB、DocumentDBの場合、シャード化されていないため、最初のパイプラインはデータをシーケンシャルに読み取る。
スキャンとチェンジストリームの両方の場合、プライマリキーと一貫したハッシュを使用してS3に書き込みを行う。各パーティション用に別々のサブフォルダを作成し、すべてのプライマリキーが同じパーティションで扱われるようになる。
二つ目のData Prepperパイプラインはそのパーティションの所有権を取得し、順序通りに処理し、順序どおりでない書き込みの問題も解決する。そしてOpenSearchへの書き込みを行う。
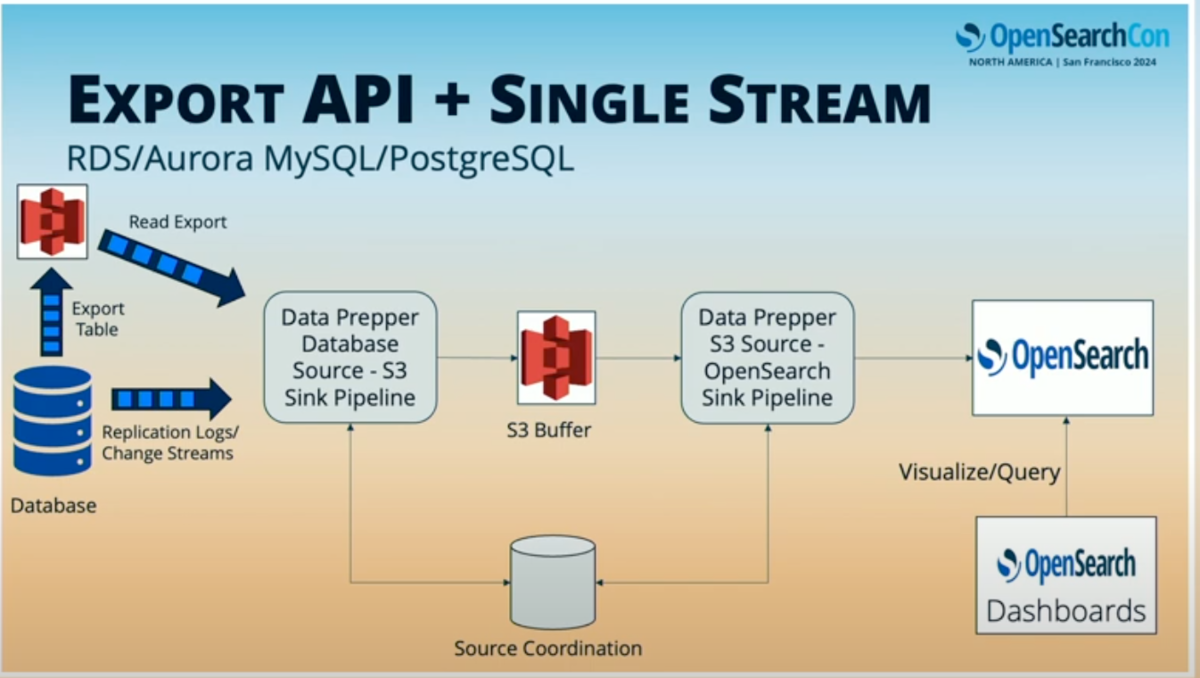
もう一つのパターンとして、RDS、Aurora、MySQL、PostgreSQLなど、S3へのエクスポートや特定時点でのスナップショットを取得するAPIがあるが、レプリケーションログはシャード化されていないケースもある。
この場合もDynamoDBと同様のアプローチをとり、エクスポートをトリガーし、エクスポートデータを読み取り、完了したらレプリケーションログに接続してOpenSearchに送信する形になる。
Source Coordinationについて
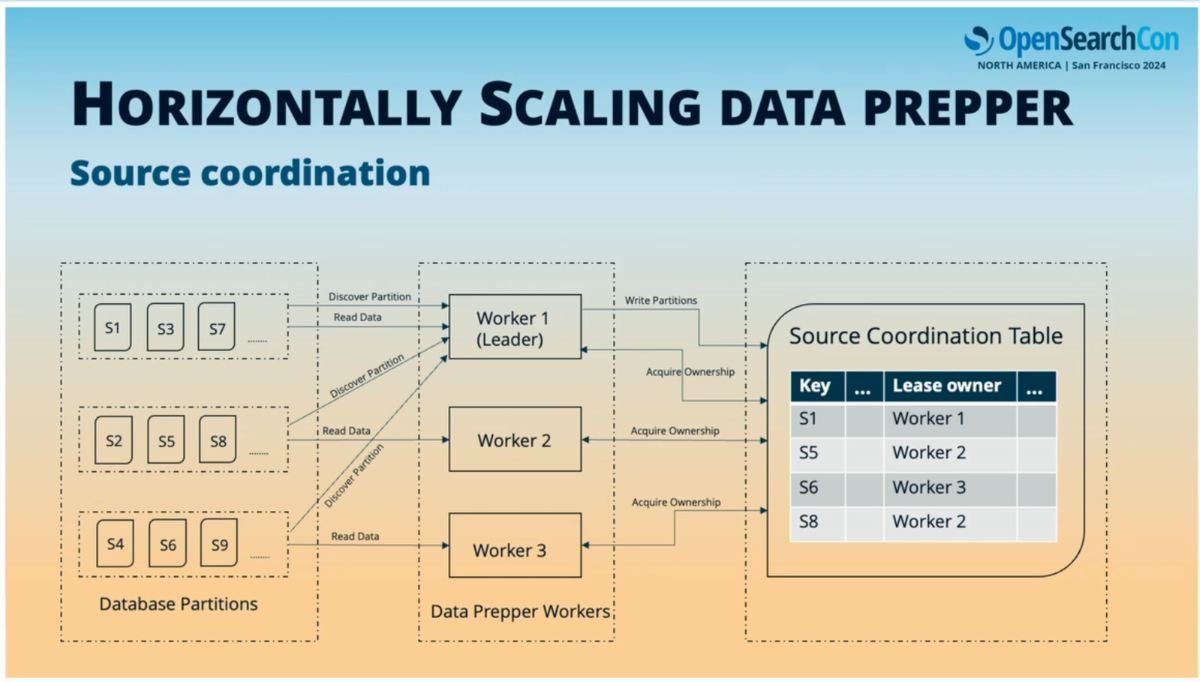
Source CoordinationはData Prepperを水平にスケールして、作業パーティションを多くの異なるData Prepperコンテナ間で分割できるようにする。
DynamoDBの例では、エクスポート中の異なるパーティションはS3データファイルであり、それらはData Prepperコンテナ間で分散される。
DynamoDBストリーム中は、すべてのシャードをData Prepperコンテナ間で分割する。
RDBの場合は、データベース全体をスキャンし、一貫したハッシュを使用して独自のパーティションを作成し、それらをData Prepperコンテナ間で分散する。
Source Coordinationテーブルとは、イメージとしてはKinesis Client Libraryのlease tableを独自に実装したものである。すべてのData Prepperコンテナ間で共有される外部ストアであり、すべてのコンテナがそれを指し、テーブル内の個々のアイテムであるこれらのパーティションを取得し、それらの所有権を取得しようとする。これによりData Prepperコンテナ間で作業が分散される。
また、リーダーを管理する概念もある。Source Coordinationに関して、これはテーブル内の別の単一アイテムであり、各Data Prepperコンテナがその所有権を取得しようとし、このリーダーパーティションの所有権を取得した者がパーティション発見の責務を割り当てられる。
例えばMongoDBの場合、これはデータベース全体をスキャンし、一貫したハッシュを使用してデータベースを異なるパーティションに分割し、異なるS3フォルダに書き込むことを意味する。
最後にSource Coordinationを使用するのは、データの耐久性のためでもある。Data Prepperコンテナが作業パーティションの所有権を取得すると、所有権タイムアウトが設定される。何らかの理由でそのData Prepperコンテナがクラッシュした場合、一定時間後に所有権タイムアウトが期限切れになり、別のData Prepperコンテナが代わりに所有権を取得し、中断された箇所から再開する。これにより、異なるデータパーティションが欠落することがないようにする。
Source Coordinationの設定

Data Prepperを実行するには二つの異なる設定がある。先ほど紹介したパイプラインと呼ばれるものと、Data Prepper設定ファイルと呼ばれるもの。
これにはData Prepperを管理・実行するために必要なものがすべて含まれている。Data Prepperサーバーの管理、メトリクス設定などがあり、Source Coordination設定も含まれている。
Source Coordinationテーブルはマルチテナントであり、多くの異なるData Prepperパイプラインが同じストアを指すことができる。それらが分離され、自分のアイテムだけを気にする方法が、二行目のパーティションプレフィックスである。
一つのData Prepperパイプラインを実行する場合、異なるパイプライン識別子を与えるだけで、アイテムを分離し、自分のアイテムだけに焦点を当てることができる。そのため、たくさんの異なるパイプラインを実行している場合、多くの異なるテーブルを持つ必要はない。
二つ目のポイントとして、ストア自体もプラガブルな設計になっているが、現在はDynamoDB Storeのみが実装されていル。他のオプションとしてはApache ZooKeeperなども検討中している。
Data Prepperが起動すると、このストアがすでに存在するかどうかをチェックし、存在しない場合は自動的に作成される。
実装の紹介

最後にData Prepperに新しいデータベースソースを作る人に向けて実装を紹介する。実際にはストアについて何も知る必要はない。
実装の観点では、高レベルでは、Source Coordinationテーブル内のアイテムとの相互作用を抽象化する単一のインターフェースが定義されている。
必要なパーティションの作成、これらのパーティションの所有権の取得、完了としてマークするなど、すべてが高レベルでの単一インターフェースで提供される。
この例は、パーティションがいくつかの単純なデータベースファイルである仮想的なデータベースを示している。データベースファイルをすべてのData Prepperコンテナ間で分散する。そのための最初のステップとしてリーダーを割り当てる。この場合、createPartitionの呼び出しを行い、これはSource Coordinationテーブルに単一のアイテムを作成する。
次のステップとして現在のData Prepperコンテナがすでにリーダーであるかどうかをチェックする。そうでない場合、実際にリーダーになろうとする。これは、リーダーが死んでしまった場合など、フォールトトレランスを処理するためのもの。
最後にSource Coordinatorを呼び出して、リーダーパーティションタイプを渡して利用可能なパーティションを取得している。何かが返ってくればリーダーとなり、パーティション発見の責務を持つことになる。

MongoDBのようにデータベース全体のスキャンを行う場合、全コンテナがそれを行う必要はなく、一つだけがそれを行う。あるコンテナが今リーダーであれば、パーティション発見を行うことになる。このコードの仮想的な例では、データベースに行って処理する必要があるすべてのファイルを取得し、それらをリストアップしている。その後、発見したそれぞれについて、Source Coordinationテーブルに新しいアイテムを作成する。これらにデータベースファイルパーティションのようなタイプを与える。これらが共通のストアに作成されると、すべてのData Prepperコンテナがそれを指し、そこから取得できるようになる。

その後、データベースファイルパーティションの所有権を取得する。ここでは処理する必要があるデータベースファイルを取得している。
処理対象のデータがあれば、それをメモリに読み込み、Data Prepperバッファに書き込む。それが終わったら、完了としてマークする呼び出しを行う。Source Coordinationテーブルでは、完了としてマークされ、再処理されることはない。
まとめ

まとめると、Data Prepper検索の課題について話し、典型的なデータベースのいくつかの制限をOpenSearchがどのように解決できるかについて話した。
そして、エクスポートとストリームの既存のパターンと、Source Coordinationでどのようにスケールするかについて話し、仮想的なデータベースの例を紹介した。

GitHub上のData Prepperリポジトリで最近見られた提案には、MySQLやPostgreSQLなどのデータベースソースやAmazon Neptuneグラフデータベースの統合の要望があった。
新しいデータベースソースの提案やアイデアがある場合は、Data Prepperリポジトリに行ってGitHub issueやフォーラム投稿を作成して欲しい。コミュニティとData Prepperメンテナーは質問に答え、手助けし、話し合うことを楽しみにしている。
また、同僚のDavid Vinalが別途、特にData Prepperへの貢献に焦点を当てた講演を行う予定である。
