はじめに
こんにちは、レバレジーズで研究員をしている永安といいます。レバレジーズの研究員は最新の技術をキャッチアップしつつ事業に活かしていくことを目標に活動しています。
私は特にAIの安全性、説明手法をテーマに研究活動を行っています。
さて、みなさんMLモデルを学習した時に、そのモデルの動作を理解するためにSHAPなどを使うことがあると思います。近年、SHAPのような入力特徴量の寄与を超えて、モデルの内部構造を理解しようとするMechanistic Interpreterbilityという分野が発展してきました。今回はMechanistic Interpreterbilityに基づいた可視化ツール、Neuronpediaを紹介したいと思います。
Mechanistic Interpreterbilityとは
Mechanistic Interpretebilityは機械学習の解釈手法に関する分類の一つです。AIの安全性の文脈で近年発展してきました。Mechanistic Interpretebilityのサーベイ論文1によると以下のように定義されています。
Mechanistic Interpretebilityは、特徴・ニューロン・層・接続といったモデルの基本的構成要素を細かく分析することで、その動作メカニズムを深く理解するためのボトムアップ的アプローチである。
この論文では特徴量ベースのSHAPやGradCAMを用いて入力の寄与を測定するアプローチをBehavioral interpretability(完全ブラックボックスモデルへの解釈), Attributional interpretability(勾配情報を用いた入力寄与の測定)と定義し、Mechanistic Interpretebilityをそれらと異なる新しいアイデアに基づいた機械学習解釈手法として扱っています。解釈手法の分類としては以下の表のように分けられます。Mechanistic Interpretebilityは特に、モデル内部の各ニューロンがどのような抽象概念に紐づいているかまで明らかにしようとしている所に特徴があります。これによりLLMがどのような根拠で出力を行っているかを内部から説明することが期待されています。
| 入力寄与度の測定 | 内部構造の利用 | ニューロンレベルの解釈 | |
|---|---|---|---|
| Behavioral interpretability | ⭕️ | ❌ | ❌ |
| Attributional interpretability | ⭕️ | ⭕️ | ❌ |
| Mechanistic Interpretebility | ⭕️ | ⭕️ | ⭕️ |
そんな新興分野であるMechanistic Interpretebilityですが実用レベルのライブラリはまだ確立していないです。例えばSHAPはモデルごとに異なった近似計算が必要でありながら、安定挙動するOSSが存在しますが、Mechanistic Interpretebilityにはまだ個別の研究レベルの実装が大半です。今回は複数のMechanistic Interpretebility手法の可視化に対応したツールであるNeuronpediaを触ってみました。
Neuronpedia
NeuronpediaはMechanistic Interpretebilityの可視化プラットフォームで、ブラウザから利用可能で、 githubからOSSとしての利用も可能です。GoogleやAnthropicのチームも参加しているようでGoogle提供のGemmaの内部構造分析ツールGemma Scopeにも使われています。提供されている解釈手法としては以下の二つです。
Sparse Autoencoder(SAE)2 3: 各層の出力にオートエンコーダを入れてスパースな表現を探すことで解釈する手法
Circuit Tracer4: 中間層がスパースになる近似表現を探すCross Layer Transcoder(CLT)5を利用したAnthropicの最新手法
どちらも全結合層に対する解釈手法になっています。
ブラウザ利用
ブラウザからの利用方法は以下のようになります。
リンク先を開き、上部のメニューバーからCircuit Tracer or Steer or SAE Evalsを選択

(Circuit Tracerを使う場合)画面右上のRemixを押すと以下のような画面が出るのでモデルを選択しプロンプトを記入しStart Generationを押す
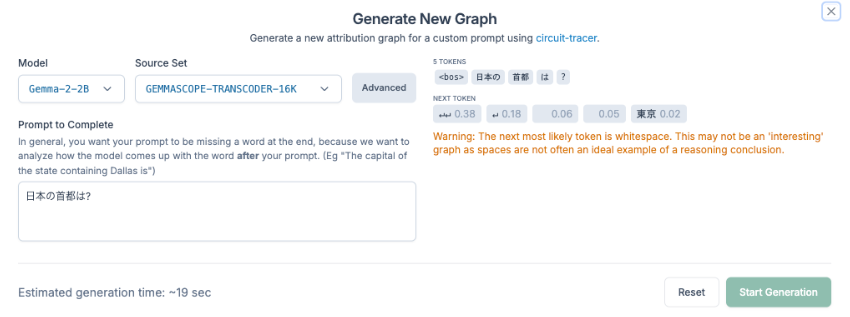
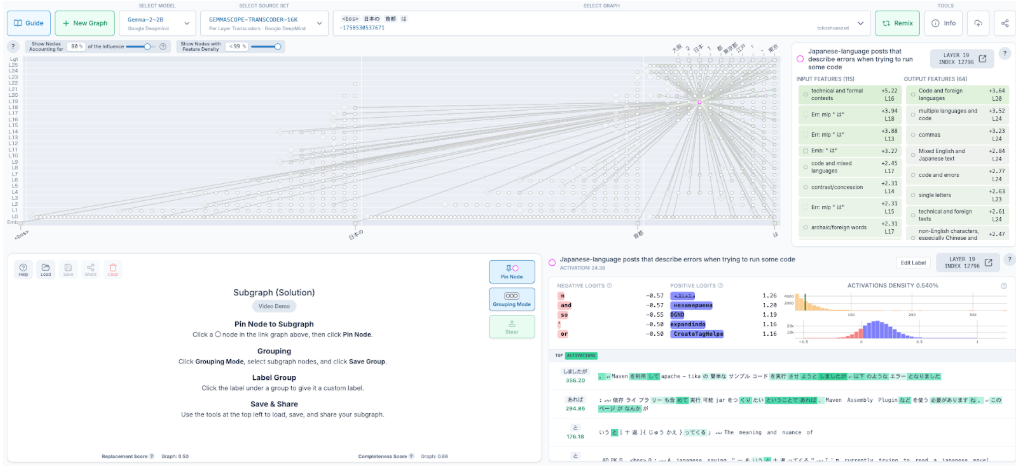
グラフが生成される。グラフ内のノードは各ニューロンの意味に対応しており、クリックすることでニューロンに対する分析が表示される。
API利用
NeuronpediaはgithubでOSSとしても公開されています。また公式のAPI提供もあります。APIの機能として可視化だけでなくSAEやCLTで得られたニューロンの表現に対するLLMによる自動解釈が実装されています。学習済みのSAEがないモデルに適用する場合はSAELensなどの実装を利用する必要があります。APIの利用マニュアルはここにあります。一部の公開APIでないものはプライベートキーが必要になり、公式サイト右上のアイコンをクリックしSetting + APIから取得できます。
まとめ
Mechanistic Interpretebilityに基づいた可視化ツールであるNeuronpediaを触ってみました。Sparse Autoencoder系列の手法であればこのツールで可視化できるので、研究開発を加速させる力があると感じました。ただし、ファインチューニングしたモデルへの適用を考えると、学習の計算コストが必要で入力特徴量ベースの古典的説明手法ほどの手軽さはないように感じました。個人的にMechanistic Interpretebilityは国内でももっと盛り上がってもいいのかなと思っているのでこの記事をきっかけにより多くの人に知ってもらえると嬉しいです。
おわりに
レバレジーズでは、最先端AI技術の調査・研究開発を行う研究員のポジションで一緒に働くメンバーを募集しています。 「専門性を生かして新たなイノベーションを起こしたい」と考えている方は以下の求人もご確認ください!
- Lukas Bereska and Efstratios Gavves. 2024. Mechanistic Interpretability for AI Safety — A Review. Transactions on Machine Learning Research, 2024.↩
- Robert Huben et al. Sparse autoencoders find highly interpretable features in language models. In The Twelfth International Conference on Learning Representations, 2023.↩
- Trenton Bricken et al. Towards monosemanticity: Decomposing language models with dictionary learning. Transformer Circuits Thread, 2023.↩
- Emmanuel Ameisen et al. Circuit tracing: Revealing computational graphs in language models. https://transformer-circuits.pub/2025/attribution-graphs/methods.html, 2025.↩
- Jack Lindsey et al. Sparse crosscoders for cross-layer features and model diffing. Transformer Circuits. https://transformer-circuits.pub/2024/crosscoders/index.html, 2024.↩
