はじめに
こんにちは、レバレジーズテクノロジー戦略室でAIエンジニアをしている安藤です。
今回は最近社内で急速に導入が進んでいるLLMの精度評価の仕組みの構築について記載します。
現状、この分野は知見も少ないので我々も手探り状態ではありますが何か参考になれば嬉しいです。
背景 & 課題
LLM回答精度評価の難しさ
最近のLLMの普及に伴い、レバレジーズでも続々と業務改善やプロダクトにLLMが利用されるようになってきました。LLM導入はもっぱらサードパーティが提供するAPIを利用することで完了するものが多く、技術的に簡単に導入できるため導入数は急激に増えていきました。
一方でLLMの厄介さは導入後の継続的な運用保守にあります。LLMは黎明期であることもあり、頻繁にアップデートや新モデルのリリースがあります。そのため、高い頻度で切り替えが検討されることから、その変更がサービスにどのような影響をもたらすのかを測る仕組みが必要になります。
また、LLMの精度評価において難しいのはLLMのoutputの揺らぎです。LLMは実行の度にoutputが変わるため、"かならずこうなる"と確約できません。評価の仕組みはそれらのLLMの特徴を考慮した上で設計する必要があります。
レバレジーズでのLLM利用ケースの一例
レバレジーズでは様々な企業様から多くの求人案件をお預かりしていますが、当然ながらそれらの記載フォーマットは統一されていません。データとして取り扱いやすい形にするためには、それらの非構造化データを構造化データに変換する必要があります。今まではこの作業を人が手作業で一件ずつ対応していましたが、最終チェックは人が手動で行う前提で、途中の処理をLLMで半自動的に処理できる仕組みが導入されました。
もともと、大量のデータを手動で処理していたこの作業は、LLMの導入によって大幅に効率化されました。その代わりに、継続的な運用のためにはLLMの処理精度(回答精度)が一定以上に保たれているかを常に確認し続ける必要があります。また、モデルのアップデートや差し替えを行った際のデグレーションの有無が検証段階で把握できるようになっていないと継続的な効果は期待できません。
解決策の探索
これらの課題を解消すべく様々なLLM評価ツールを検討しましたが、数多の選択肢がある中で何を採用するか非常に悩みました。
検討の結果、コアの評価機能はこちらの記事で紹介しているpromptfooを利用し、社内システムを構築しました。
システム構成
まずはMVPということで構成は非常にシンプルです。
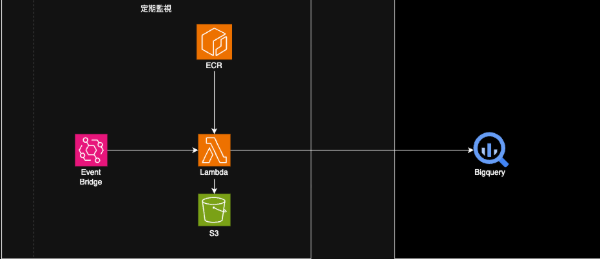
◼︎定期監視機能
- EventBridge:lambdaをtriggerし定期的に評価機構を実行する
- Lambda: 評価機構の本体
- ECR: 評価機構のdocker imageの保存場所
- S3: raw resultの保存場所
- BigQuery: 可視化に適した形式に変換されたresultの保存場所
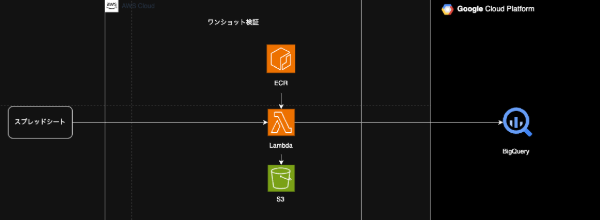
◼︎ワンショット評価機能
- スプレッドシート: ユーザが操作する画面の役割。ボタンを設置しLambdaをtriggerできる
- Lambda: 評価機構の本体
- ECR: 評価機構のdocker imageの保存場所
- S3: raw resultの保存場所
- BigQuery: 可視化に適した形式に変換されたresultの保存場所
できる限りシンプルに実装するため、BigQueryのテーブルに格納されているデータを、データコネクタ機能を使ってSpreadSheetに連携することで、評価結果のビジュアル化を完全にユーザ側に任せるようにしました。
こういう時にGoogle製品の連携は本当に便利だなぁと感じます。
構成はとても簡易的ですが機能としては必要な要件を最低限満たしているので良しとしましょう。今後はMVPを実際に使ってもらいながら、フィードバックをもとにアップデートしたいですね。
苦戦したポイント
実装時に以下2点で苦戦しました。
- 課題:当初API Gatewayを利用してlambdaをトリガーしていたのですが、lambdaでの評価処理は数分かかる場合がありAPI Gatewayの30秒のタイムアウト制限に引っかかりエラーが出るという不具合がありました
- 解決策:Lambda Function URLを利用し、API Gatewayを介さない構成に切り替えエラーを回避しました
2, Lambdaの転送容量制限
- 課題:評価件数が多すぎるとLambdaの転送容量制限引っかかるという不具合がありました
- 解決策:バッチ処理的に処理件数を分散することで転送容量制限を回避しました
今後やっていきたいこと
今回は非構造化データを構造化データにするというLLM評価の中でも比較的難度の低いものでした。他のプロダクトではinput、outputともに非構造化データのものもあるため、それらに対応できる評価方法を確立して高度なLLM評価にも対応できるようにしたいと思います。
