はじめに
こんにちは、レバレジーズ株式会社データ戦略室の丸山です!
今回はGCPのCloud Functionsを使用して学習済みの機械学習モデルを呼び出し、推論を定期実行する際のエンジニアリングのノウハウを共有できればと思います。
機械学習のパイプライン構築にはSageMakerなどの機械学習プラットフォームを用いる方法もありますが、学習データが蓄積されるペースが遅い場合など、より簡易的に実装をしたいケースもあるかと思います。
上記のケースに該当する分析PJを私が担当していたため、その時の作業手順を説明していきます!
アーキテクチャ図

上記の通りです。各フローの設定・実装作業を全て書くとかなりのボリュームになってしまうので、ここからは別のネット記事も参照しながら手順を説明していきます。
手順詳細
1. Cloud FunctionsとPub/Subの設定
2. Cloud Schedulerの設定
上記2つの手順についてはこちらの記事に詳しい手順が記載されているので割愛します。
いずれの設定もGCPの該当サービスの画面に遷移し、求められた入力項目に沿って記入をしていくと設定をすることができます。
3. シークレット情報の設定
まず、事前準備として今回のワークフローを遂行するためのサービスアカウントを作成する必要があります。GCPのサービスアカウントのコンソール画面から「サービスアカウントの作成」を選択します。
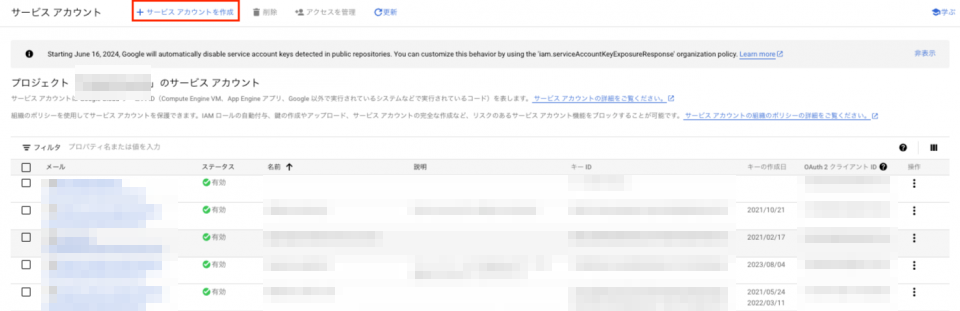
その後の作成画面で、今回のワークフローに必要な権限を付与します(権限については後で不足分も付与することができるので、この段階で網羅しておく必要はないです)。

サービスアカウント作成後、認証に使用するjsonキーを作成します。個別のサービスアカウントの画面に遷移して、「鍵を追加」からキーを作成することができます。
以下の画像は、該当のサービスアカウントを選択した状態のスクリーンショットになります(画像の一番上のモザイクがサービスアカウント名を表しています)。

次に、GCPのSecret Managerを使ってシークレット情報を管理します(Cloud Functionsで実行するPythonファイルから直接jsonを参照するのはセキュリティ上イケてないので、この対応を行います)。
GCPのSecret Managerのコンソール画面から「シークレットを作成」を選択します。
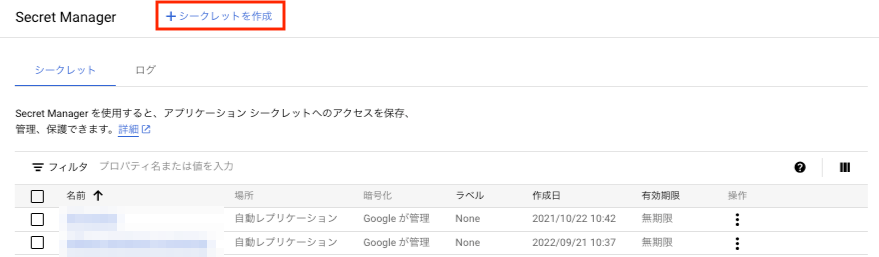
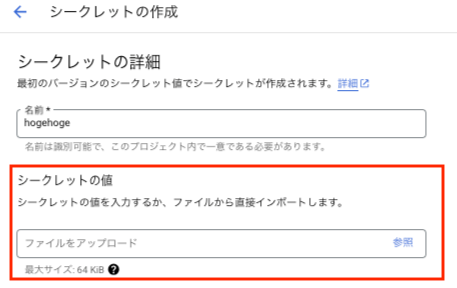
すると、シークレット名およびシークレットの値を入力する欄が出てくるので、前の手順で作成したjsonキーをここで参照するよう設定します。
4. Cloud Functionsによる機械学習の推論コードの実装
手順1.の「Cloud FunctionsとPub/Subの設定」でCloud Functionsの箱はできているので、ここからは中身を実装していく作業を進めていきます。
4.1 シークレット情報の呼び出し
googleの公式ドキュメントにSecret Managerの認証情報を取得するためのサンプルコードが記載されているので、これをそのまま利用します。今回はPythonで機械学習の推論を行いたいので、Pythonのサンプルコードを使います。後述のaccess_secret_version関数を定義した後、以下の情報を引数として入力することで、認証情報を取得することができます。
- シークレットのプロジェクトID
- 手順3.で作成したシークレットの名称
- シークレットのバージョン
4.2 BigQuery経由での特徴量の集計
該当処理に必要なライブラリは以下の通りです。
from google.cloud import secretmanager import google_crc32c from google.cloud import bigquery from google.oauth2 import service_account import pandas as pd
シークレットの認証情報を取得
手順4.1で定義した関数を用いることで、以下の通りbq_keyにシークレットの情報が格納されます。
# 手順4.1で定義した関数を用いて、認証情報を取得 bq_key = access_secret_version('project_id', 'secret_id', 'version') # 引数は手順3.で記載したシークレットの情報をもとに書き換える
BigQueryへのアクセス
続いて以下のコードを実行することで、シークレット情報を使ってBigQueryにアクセスすることができます。
# 認証情報を読み込む credentials = service_account.Credentials.from_service_account_info(bq_key) client = bigquery.Client( credentials=credentials, # GCPのプロジェクト名を指定する project={GCPのプロジェクト名} )
クエリの実行およびデータ抽出
BigQueryへの接続ができたら、以下のexecute_bq_query関数を定義してクエリを実行していきます。
# クエリの実行関数の定義 def execute_bq_query(query): query_job = client.query(query) df = query_job.result().to_dataframe() return df # 関数を用いて推論用のデータフレームを作成 df = execute_bq_query(query=feature_import_query())
なお、execute_bq_query関数で引数としているfeature_import_query()はBigQueryで実行するSQLを格納した関数となっています。
# 実行するSQLは関数化している(サンプル) def feature_import_query(): query = ( """ select hoge ,fuga from piyo """ )
4.3 Google Driveからpickleファイルの読み込み
前提として、今回の機械学習の取り組みでは以下の2つのファイルが必要になります。
本節では、GoogleDriveに格納されている上記のpickleファイルをCloud Functionsで呼び出す手順を説明します。
ここまでに使ってきたライブラリに加えて、以下のライブラリをimportします。
from googleapiclient.discovery import build from googleapiclient.http import MediaIoBaseDownload import pickle
GoogleDriveへのアクセス
手順4.2で作成したcredentialsを用いて、以下のコードによりGoogleDriveにアクセスします。
# GoogleDriveの認証を実施 service = build('drive', 'v3', credentials=credentials) # 特定のフォルダIDを指定してファイルリストを取得 folder_id = 'フォルダID' query = f"'{folder_id}' in parents" # 共有ドライブにアクセスする場合はsupportsAllDrives=Trueとする results = service.files().list(supportsAllDrives=True, includeItemsFromAllDrives=True, q=query, pageSize=10, fields="files(id, name)").execute() # 格納している全てのファイルを取得 items = results.get('files', [])
pickleファイルの読み込み
前のコードで読み込んだitemsというリストには参照先のDriveに保存されている全てのファイルが格納されているので、そのうち使用するもののみを読み込む処理を実装します。 ここでは拡張子を用いて読み込むかどうかを判定しています。
# ファイル読み込みを実施 pickle_dict = {} if not items: print('No files found.') else: for item in items: # ファイルがpickleファイルかどうかをチェック if item['name'].endswith('.pkl') or item['name'].endswith('.pickle'): print(f"Found pickle file: {item['name']} (ID: {item['id']})") # 特定のファイルIDを指定してファイルをダウンロード file_id = item['id'] request = service.files().get_media(fileId=file_id) fh = open(f"{item['name']}", 'wb') downloader = MediaIoBaseDownload(fh, request) done = False while done is False: status, done = downloader.next_chunk() print(f"Download {int(status.progress() * 100)}%.") fh.close() # ダウンロードしたファイルをpickleとして読み込む with open(f"{item['name']}", 'rb') as f: data = pickle.load(f) pickle_dict[item['name']] = data # 当該ファイルがpickleではない場合に処理をスキップする else: print(f"Skipping non-pickle file: {item['name']}")
このコードを実行することで、pickle_dict['model.pickle'], pickle_dict['label_encoder.pickle']に呼び出したいオブジェクトが格納されるので、あとはこれを使用して特徴量の変換やモデルの推論を行います。
4.4 Pythonによるデータの前処理・推論の実施
この記事のメイントピックではないので割愛します。実装してみたいけど知識のない方は機械学習の書籍やブログ記事を読んでインプットしてみてください。
4.5 推論結果をスプレッドシートに出力
ここでは、手順4.4で出力したレコメンド結果をスプレッドシートに出力します(今回はレコメンド結果を活用するのが社員であるため、出力先をスプレッドシートにしました)。
ライブラリとしては以下を追加で使用します。
import gspread
スプレッドシートの認証情報の取得
スプレッドシートの認証を通す際には、後述のスコープを明示する必要があるため、credentialの取得方法に工夫が必要です。
# スプレッドシートのIDと範囲を設定 spreadsheet_url = 'スプレッドシートのURLを入力' sheet_name = '出力先のタブ名を入力' # スコープを追加して認証情報を取得(スプレッドシートの認証時は必要な情報が異なる) scopes = [ 'https://www.googleapis.com/auth/spreadsheets', 'https://www.googleapis.com/auth/drive' ] ss_credentials = service_account.Credentials.from_service_account_info(bq_key, scopes=scopes)
スプレッドシートへの接続とデータの書き込み
直前のコードで取得した認証情報を使ってデータの書き込みを実施します。 冒頭で述べた通り、今回の機械学習モデルでは日次で推論結果を出力する必要があります。 これを実現するために以下のような処理を行いました
# SSへの認証を行う gc = gspread.authorize(ss_credentials) # スプレッドシートを開く spreadsheet = gc.open_by_url(spreadsheet_url) worksheet = spreadsheet.worksheet(sheet_name) # 1. 書き込み先のスプレッドシートのタブを読み込む existing_data = worksheet.get_all_values() # 新しいデータをリスト形式で追加 # output_dfは今回のレコメンドの結果 output_df = output_df.astype(str) # 貼り付け時のエラーを回避するための型変換 new_data = output_df.values.tolist() # 2. 推論結果を1.のデータと結合 if existing_data: updated_data = existing_data + new_data else: updated_data = new_data # 3. 2.のデータを指定したスプレッドシートのタブに書き込む worksheet.update('A1', updated_data) print(f"{len(new_data)} rows appended.")
5. 推論結果の出力
今回は二値分類モデルによる推論を行ったので、予測確率が以下の画像のようにスプレッドシートに出力されます。
モザイクをかけている箇所は社内でのオペレーションに必要な情報です。上述した方法と同じ流れでBigQueryからデータを抽出し、Pythonを使って推論結果と結合をしています。

おわりに
いかがだったでしょうか。
継続的な学習がデータサイズの観点で難しい場合などは上記のようにサクッと実装するアプローチもありなのではと個人的に考えています。
また、今回紹介した内容はPythonで複雑なデータ処理を定期的に行いたい場合に流用できるものだと思うのでぜひ参考にしてみてください!
