\(N\le999999\) で解きました 理論値ですよ ほめてください 本番 AC できてないのでダメですよ はい……
本番では \(-1\) だと思って \(N\gt HW\) のときに終了していました(???????)
考えた道筋
\(0\) を \(K\) 個、\(1\) を \(HW-K\) 個入れるとします。
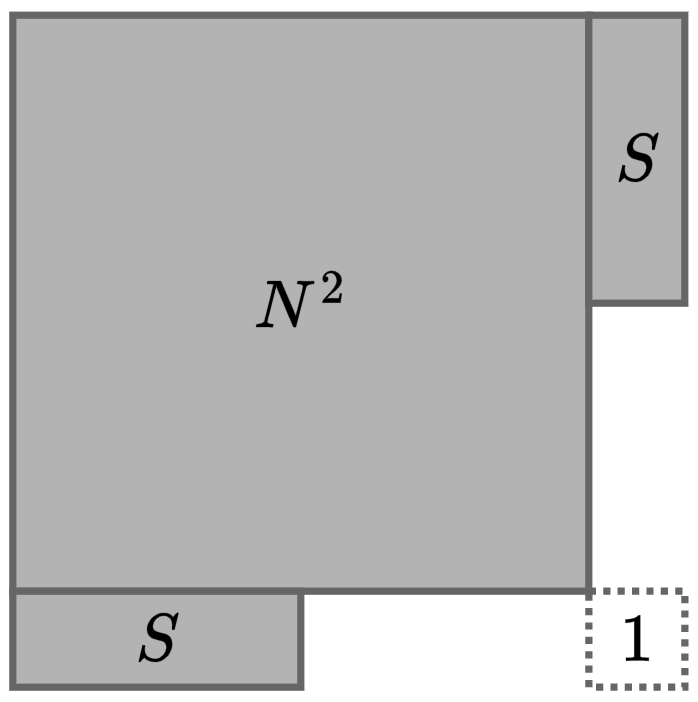
\(N=0\) を構成する必要があるので、\(00000\ldots0011111\ldots1=0 ^ K1 ^ {HW-K}\) とできます。 \(N=1\) を構成する必要があるので、\(00000\ldots0101111\ldots1=0 ^ {K-1}101 ^ {HW-K-1}\) とできます。 市松模様に塗ることで、\(K\) が奇数である必要があることがわかります。 余談ですけど、\(N=1000000\) が実現できないこともわかります(最大で \(K(HW-K)\) なので)。 \(K=999\) としましょう。
列を反転することで、\(999999-N\) が作れます。 先頭が \(0\) であるような列を cyclic shift することで \(N+1001\) が作れます。 よって、偶数 \(k\ (0\le k\le1000)\) に対する \(00000\ldots01111\ldots1011111\ldots1=0 ^ {K-1}1 ^ k01 ^ {HW-K-k}\) をすべて作れれば十分です。
これは、左右にわけてみるとだいたいできることがわかります。
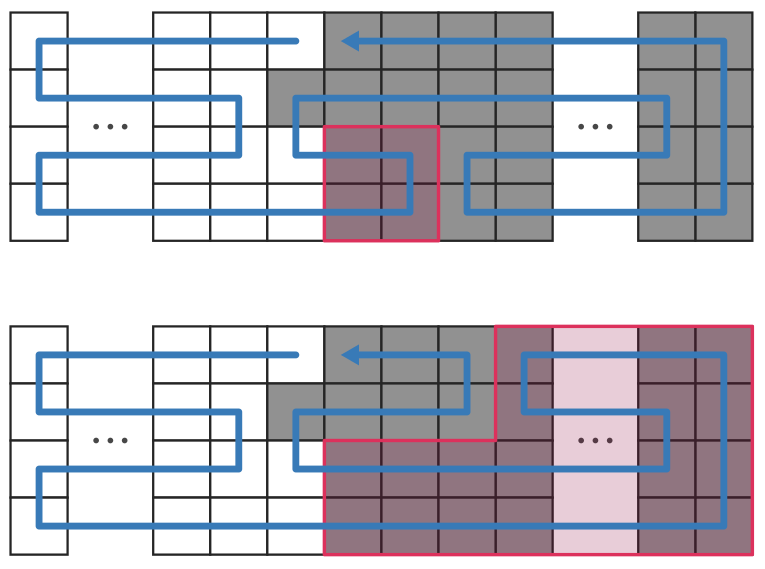
ダメなときが \(2\) つだけあり、\(k=498,502\) です。

ad-hoc 開始! このときだけちょっと変えてあげるといいですね。 \(00000\ldots01111\ldots1011111\ldots1=0 ^ {K-2}1 ^ {k/2}0 ^ 21 ^ {HW-K-k/2}\) とすると、次のようにできます。
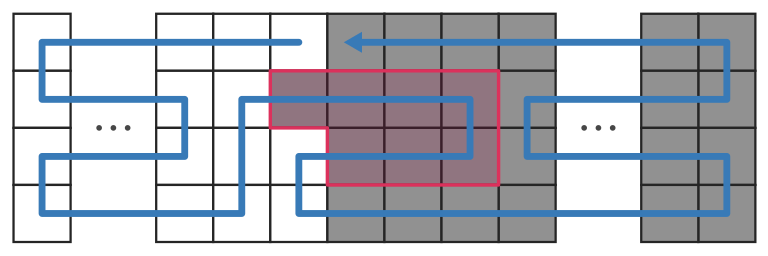
文字列の構造を変えたので cyclic shift の回数が減ってしまいました。 cyclic shift が最後の \(1\) つだけできないので、\(N=499,503,999496,999500\) ができません。
スーパー ad-hoc タイム開始! このときだけ個別に解いてあげるといいですね。 cyclic shift ができなくてもよいので、どうとでもなります。
おわり
コードはこんなかんじ。
#include <bits/extc++.h> int main() { using namespace std; unsigned H, W, Q; cin >> H >> W >> Q; for (unsigned i{}; i < H; ++i) cout << string(W / 2 - (i == 1), '0') << string(W / 2 + (i == 1), '1') << '\n'; cout << flush; const auto solve_even{[](const auto N) { if (N == 498 || N == 502) { vector<pair<unsigned, unsigned>> ret; ranges::copy(views::zip(views::repeat(1, 250), views::iota(1, 251)) | views::reverse, back_inserter(ret)); ranges::copy(views::zip(views::repeat(2, 250), views::iota(1, 249)), back_inserter(ret)); ranges::copy(views::zip(views::repeat(3, 250), views::iota(1, 249)) | views::reverse, back_inserter(ret)); ranges::copy(views::zip(views::repeat(4, 250), views::iota(1, 250)), back_inserter(ret)); ret.emplace_back(3, 249); ret.emplace_back(2, 249); ranges::copy(views::zip(views::repeat(2, 250), views::iota(250U, 251 + N / 4)), back_inserter(ret)); ranges::copy(views::zip(views::repeat(3, 250), views::iota(250U, 251 + N / 4)) | views::reverse, back_inserter(ret)); ranges::copy(views::zip(views::repeat(4, 251), views::iota(250, 501)), back_inserter(ret)); ranges::copy(views::zip(views::repeat(3, 250), views::iota(251 + N / 4, 501U)) | views::reverse, back_inserter(ret)); ranges::copy(views::zip(views::repeat(2, 250), views::iota(251 + N / 4, 501U)), back_inserter(ret)); ranges::copy(views::zip(views::repeat(1, 250), views::iota(251, 501)) | views::reverse, back_inserter(ret)); return ret; } vector<pair<unsigned, unsigned>> ret; ranges::copy(views::zip(views::repeat(1, 250), views::iota(1, 251)) | views::reverse, back_inserter(ret)); ranges::copy(views::zip(views::repeat(2, 250), views::iota(1, 250)), back_inserter(ret)); ranges::copy(views::zip(views::repeat(3, 250), views::iota(1, 250)) | views::reverse, back_inserter(ret)); ranges::copy(views::zip(views::repeat(4, 250), views::iota(1, 251)), back_inserter(ret)); const auto vertical_position{N <= 500 ? 251 + N / 2 : 751 - N / 2}; if (N <= 500) { ranges::copy(views::zip(views::repeat(4, 250), views::iota(251U, vertical_position)), back_inserter(ret)); ranges::copy(views::zip(views::repeat(3, 250), views::iota(251U, vertical_position)) | views::reverse, back_inserter(ret)); } else { ranges::copy(views::zip(views::repeat(4, 250), views::iota(251, 501)), back_inserter(ret)); ret.emplace_back(3, 500); ret.emplace_back(2, 500); ranges::copy(views::zip(views::repeat(1, 250), views::iota(vertical_position, 501U)) | views::reverse, back_inserter(ret)); ranges::copy(views::zip(views::repeat(2, 250), views::iota(vertical_position, 500U)), back_inserter(ret)); ranges::copy(views::zip(views::repeat(3, 250), views::iota(251, 500)) | views::reverse, back_inserter(ret)); } ret.emplace_back(3, 250); ret.emplace_back(2, 250); if (N < 500) { ranges::copy(views::zip(views::repeat(2, 250), views::iota(251, 500)), back_inserter(ret)); ranges::copy(views::zip(views::repeat(3, 250), views::iota(vertical_position, 500U)) | views::reverse, back_inserter(ret)); ranges::copy(views::zip(views::repeat(4, 250), views::iota(vertical_position, 501U)), back_inserter(ret)); ret.emplace_back(3, 500); ret.emplace_back(2, 500); ranges::copy(views::zip(views::repeat(1, 250), views::iota(251, 501)) | views::reverse, back_inserter(ret)); } else { ranges::copy(views::zip(views::repeat(2, 250), views::iota(251U, vertical_position)), back_inserter(ret)); ranges::copy(views::zip(views::repeat(1, 250), views::iota(251U, vertical_position)) | views::reverse, back_inserter(ret)); } return ret; }}; const auto solve_499{[] { vector<pair<unsigned, unsigned>> ret; ranges::copy(views::zip(views::repeat(4, 500), views::iota(1, 251)) | views::reverse, back_inserter(ret)); ret.emplace_back(3, 1); ret.emplace_back(2, 1); ranges::copy(views::zip(views::repeat(1, 500), views::iota(1, 250)), back_inserter(ret)); ranges::copy(views::zip(views::repeat(2, 500), views::iota(2, 250)) | views::reverse, back_inserter(ret)); ranges::copy(views::zip(views::repeat(3, 500), views::iota(2, 500)), back_inserter(ret)); ranges::copy(views::zip(views::repeat(2, 500), views::iota(250, 500)) | views::reverse, back_inserter(ret)); ranges::copy(views::zip(views::repeat(1, 500), views::iota(250, 501)), back_inserter(ret)); ret.emplace_back(2, 500); ret.emplace_back(3, 500); ranges::copy(views::zip(views::repeat(4, 500), views::iota(251, 501)) | views::reverse, back_inserter(ret)); ranges::reverse(ret); return ret; }}; const auto solve_503{[] { vector<pair<unsigned, unsigned>> ret; ranges::copy(views::zip(views::repeat(4, 500), views::iota(1, 251)) | views::reverse, back_inserter(ret)); ret.emplace_back(3, 1); ret.emplace_back(2, 1); ranges::copy(views::zip(views::repeat(1, 500), views::iota(1, 250)), back_inserter(ret)); ranges::copy(views::zip(views::repeat(2, 500), views::iota(2, 250)) | views::reverse, back_inserter(ret)); ranges::copy(views::zip(views::repeat(3, 500), views::iota(2, 251)), back_inserter(ret)); ret.emplace_back(3, 251); ret.emplace_back(4, 251); ret.emplace_back(4, 252); ret.emplace_back(3, 252); ret.emplace_back(3, 253); ret.emplace_back(4, 253); ret.emplace_back(4, 254); ret.emplace_back(3, 254); ranges::copy(views::zip(views::repeat(3, 500), views::iota(255, 500)), back_inserter(ret)); ranges::copy(views::zip(views::repeat(2, 500), views::iota(250, 500)) | views::reverse, back_inserter(ret)); ranges::copy(views::zip(views::repeat(1, 500), views::iota(250, 501)), back_inserter(ret)); ret.emplace_back(2, 500); ret.emplace_back(3, 500); ranges::copy(views::zip(views::repeat(4, 500), views::iota(255, 501)) | views::reverse, back_inserter(ret)); ranges::reverse(ret); return ret; }}; for (unsigned i{}; i < Q; ++i) { unsigned N; cin >> N; unsigned M{N}; if ((N % 1001) & 1) M = 999999 - N; auto result{M == 999500 ? solve_499() : M == 999496 ? solve_503() : solve_even(M % 1001)}; if (M != 999500 && M != 999496) ranges::rotate(result, begin(result) + M / 1001); if ((N % 1001) & 1) ranges::reverse(result); for (const auto &[x, y] : result) cout << x << " " << y << "\n"; cout << flush; } return 0; }